In-Context Learning(ICL)
1.介绍
自GPT-3首次提出了In-Context Learning(ICL)的概念而来,ICL目前已经变成了一种经典的LLMs使用方法。
2.思路
ICL主要思路是,给出少量的标注样本,设计任务相关的指令形成提示模板,用于指导待测试样本生成相应的结果。
ICL的过程,并不涉及到梯度的更新,因为整个过程不属于fine-tuning范畴。而是将一些带有标签的样本拼接起来,作为prompt的一部分,引导模型在新的测试数据输入上生成预测结果。
ICL方法的表现大幅度超越了Zero-Shot-Learning,为少样本学习提供了新的研究思路。
3.定义
3.1 形式化定义
给出少量任务相关的模型输入输出示例(demonstration),如 k k k个示例 D k = f ( x 1 , y 1 ) , . . . , f ( x k , y k ) D_k={f(x_1,y_1),...,f(x_k,y_k)} Dk=f(x1,y1),...,f(xk,yk),其中 f ( x k , y k ) f(x_k,y_k) f(xk,yk)是一个预定义的关于Prompt的函数(文本格式),用于将 k k k个任务相关的示例,转换成自然语言Prompt。
给出任务定义
I
I
I,示例
D
k
D_k
Dk,以及一个新的输入
x
k
+
1
x_{k+1}
xk+1,我们的目的是通过LLM生成输出
y
^
k
+
1
\hat{y}_k+1
y^k+1。公式化为:
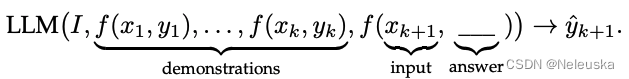
3.2 实例理解
以一个分类任务进行举例,从训练集中抽取了 k = 3 k=3 k=3个包含输入输出的实例,使用换行符"\n"来区分输入和输出。
在预测是,可以更换测试样本输入(绿色部分),并在末尾留出空间让LLM生成。

4.示例设计(Demonstration Design)
4.1 示例选择
ICL的性能,在不同的示例中,会有很大差异。即同一个测试样本,在选择不同的示例下,得到的结果可能会不一样。为了使得LLM产出更高准确率的结果,我们需要选取合适的示例。目前有两类方法:
(1) 启发式方法
《What Makes Good In-Context Examples for GPT-3?
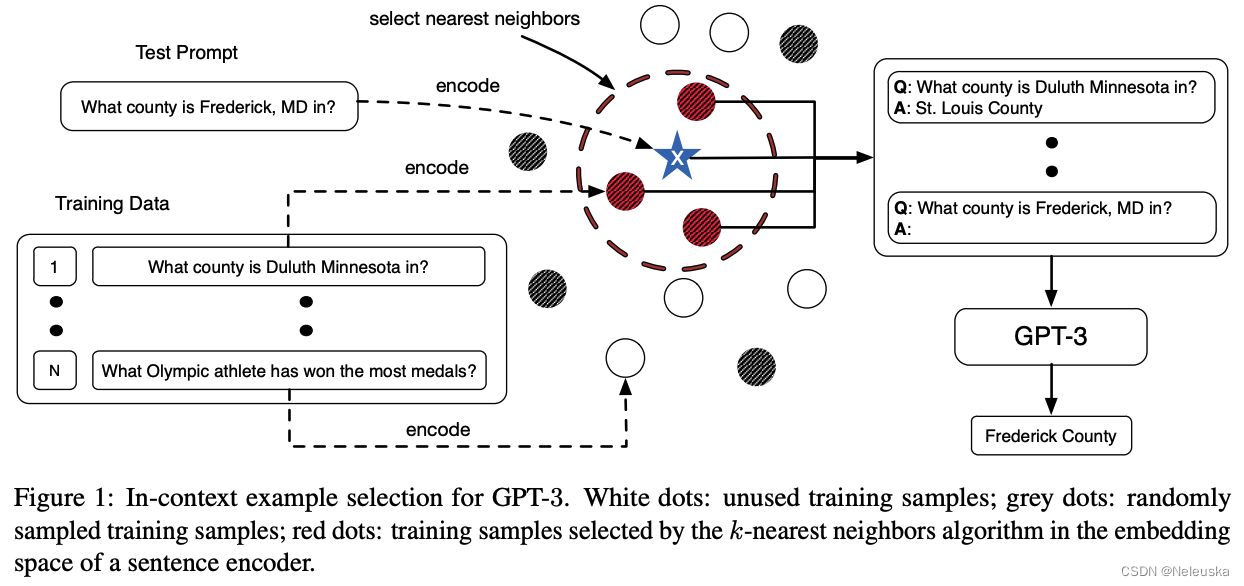
我们很容易能有这样一个想法:如果demonstration与测试样本输入在语义上相近的话,是否效果会更好?论文《What Makes Good In-Context Examples for GPT-3?》给出了肯定的答案。
作者使用RoBERTa-large模型作作为编码器,选取了其CLS embedding的输出向量作为训练样本的文本表征。使用K-近邻算法以及欧式距离方法,选取与当前test sentence语义最近的10个训练个样本,作为demonstration。
实验效果表明,该方法比随机抽取训练样本作为demonstration效果更好。
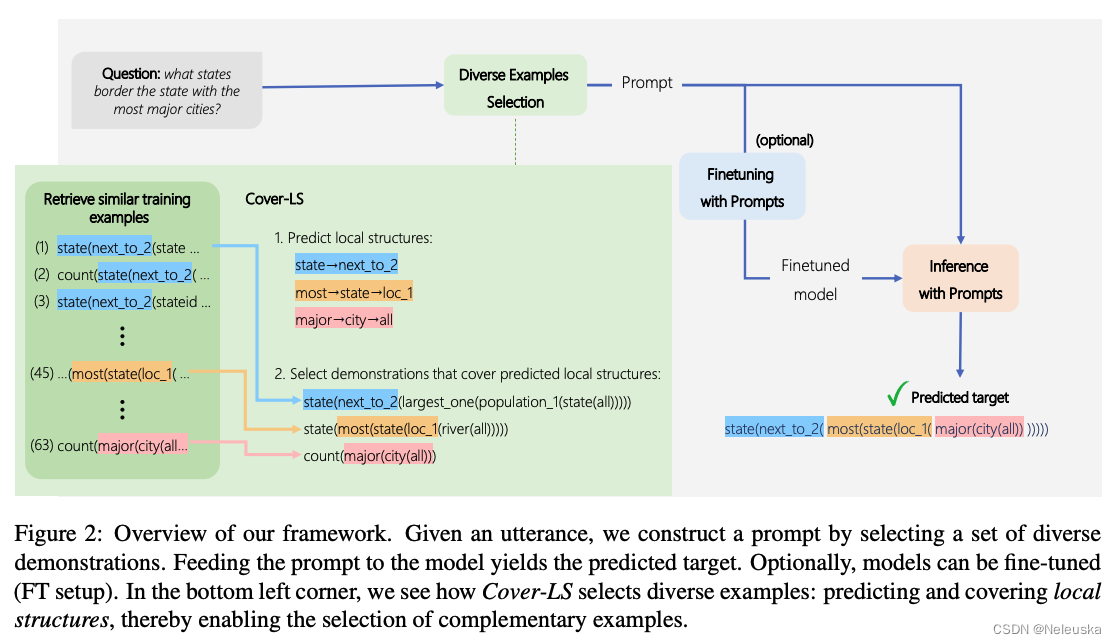
《Diverse demonstrations improve in-context compositional generalization》
用来挑选demostration的训练数据和测试数据有时候可能会存在较大的分布差异,这个时候很难通过KNN等基于相似方法来挑选合适的demostration。论文《Diverse demonstrations improve in-context compositional generalization》从多样性的角度去挑选demostration,目的在于尽可能地覆盖所有可能的输出,提高模型在新场景的泛化能力。
具体做法是,在原有相似度的基础上,考虑不同demostration之间的差异性。当两个demostration高度语义相似时,剔除其中一个。
(2) LLM-based方法
除了启发式方法以外,还有研究者使用LLMs来直接生成demostrations。
《Learning To Retrieve Prompts for In-Context Learning》
作者认为demostrations的好坏,不应该由人来决定,而应该由模型来判定。
对于一条测试数据
(
x
,
y
)
(x,y)
(x,y),作者将训练集中每一个样本数据都当作示例
e
e
e,将
(
e
,
x
)
(e,x)
(e,x)输入模型,通过模型生成
y
y
y的概率
P
r
o
b
g
^
(
y
∣
e
,
x
)
Prob_{\hat g}(y|e,x)
Probg^(y∣e,x),来评估当前示例的好坏。
为了减少由于训练集过大,而导致计算开销成本高。作者使用了 B M 25 BM25 BM25、 S B E R T SBERT SBERT等方法,预先对所有训练集进行召回,筛选出候选示例集,再对其每一条示例进行评估,选取最高分的k条示例作为正例集,最低分k条作为负例集,使用对比学习的方法,训练retrever,同时生成一个针对输入编码的Utterance encoder和针对示例编码的prompt encoder。
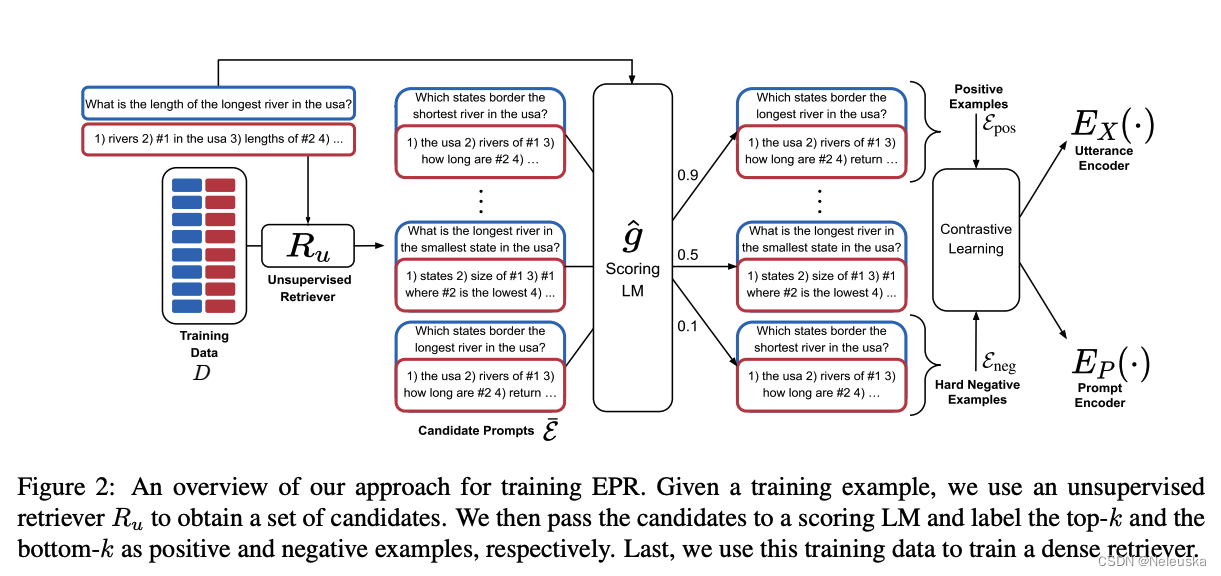
基于训练好的retrever,结合Faiss相似度计算框架,找出输入input对应最佳的demostrations。
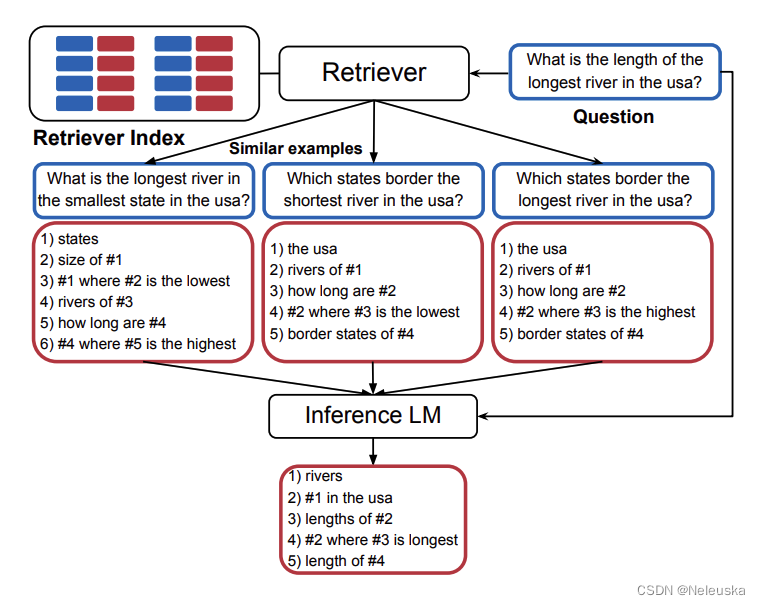
《Active Example Selection for In-Context Learning》
示例选择的问题,类似于主动学习,从样本库中选择适合的样本,提供给标注者标注。放在示例选择问题,则是选择适合的示例,提供给prompt,以使测试样本得到较高的准确率。
由于demostrations的可选空间,与样本库(一般是训练集)呈指数关系。因此要枚举所有的demostrations组合,并不现实。因此,作者将示例选择看作是一个序列决策问题,这样就可以基于马尔可夫决策过程(MDP),使用强化学习(RL)的方法去解决。
我们知道一个经典的MDP模型,有3个基本定义(状态state、动作action、奖励reward)。文章将state定义为当前时刻的demostrations,即 ( x i , y i ) (x_i,y_i) (xi,yi),action定义为样本库中所有的样本和一个停止信号标识(┴),reward定义为LLMs利用state与当前action构成的demostrations,在验证集中的准确率。即,prompt是由state+action构造成的demostrations,加上验证集中的样本输入一起组成,验证集中的标签与LLMs输出,可计算准确率。
定义好MDP的各个关键部分后,作者基于off-policy的方式,使用CQL(Q-learning的一个变种,用于缓解Q-Learning对于Q值估计过高的问题),构造一个三层MLP层的Q网络,用于学习最优策略。
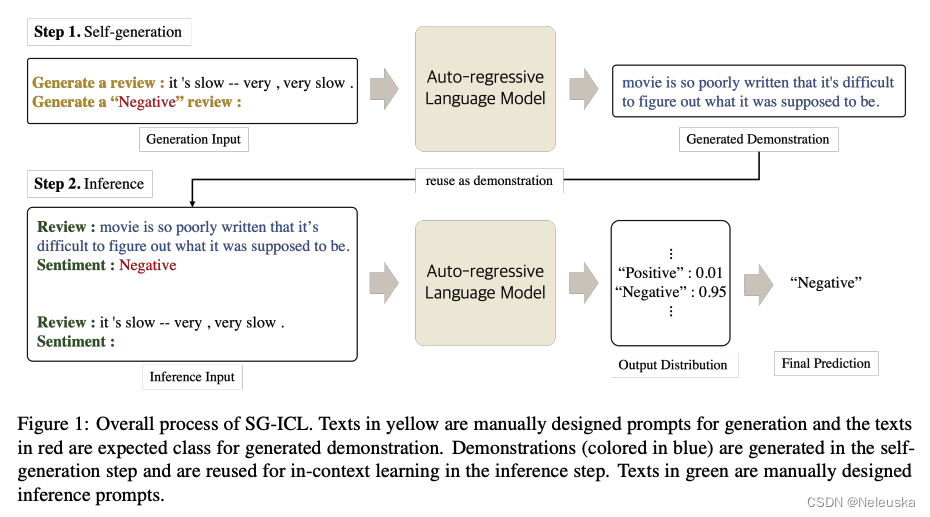
《Self-generated in-context learning: Leveraging auto-regressive language models as a demonstration generator》
前面提及的方法,都是从样本库中挑选出合适的demonstration,而本论文方法是利用LLMs自身的能力,生成合适的demonstration。目的是最小化对外部样本库的依赖。
整个过程分为两个阶段:
- 1.借助预先设计的prompt,让LLMs生成k个合适的示例
- 2.在原来输入的基础上,加入第一阶段生成的示例,让LLMs预测最终结果
实验结显示,当使用Self-generated的方式生成8个demonstration作为in-context sample,相对在样本库中抽取5个demonstration作为in-context sample的效果相当。
4.2 示例格式
在完成demonstrations的选择后,下一步就是将demonstrations整合成一个自然语言Prompt里。
《Cross-task generalization via natural language crowdsourcing instructions》
这篇论文提出了一个新的跨任务instruction数据集。他们使用总包的方式,按照规定的instruction格式,对多个开源数据集进行改造。
针对每一个promt,其格式包含:
- title: 包含一个high-level的任务描述,以及其相关技能,如question generation,answer generation等
- prompt: 单独的文本命令,一般出现在输入示例之前。
- definition: 指令的补充内容,更加详细地描述指令的具体执行细节。
- things to avoid: 包含模型应该避免的内容,或规则。
- emphasis and caution: 强调在众包过程中,警告或反对的内容
- positive examples: 提供一个类似系统期望的输入、输出例子,使得众包人员更好地理解任务。
- negative examples:提供一个类似系统期望的输入、输出的负例,让众包人员尽量避免。
- reason: 解释为什么例子是positive或negative。
- suggestion: 包含一些建议,主要用于指导如何将负例改成正例。
模型在经过上述instruction数据集微调后,能在unseen样本上,达到较好的生成效果。在新样本推断时,将demonstrations加入到task instances即可。

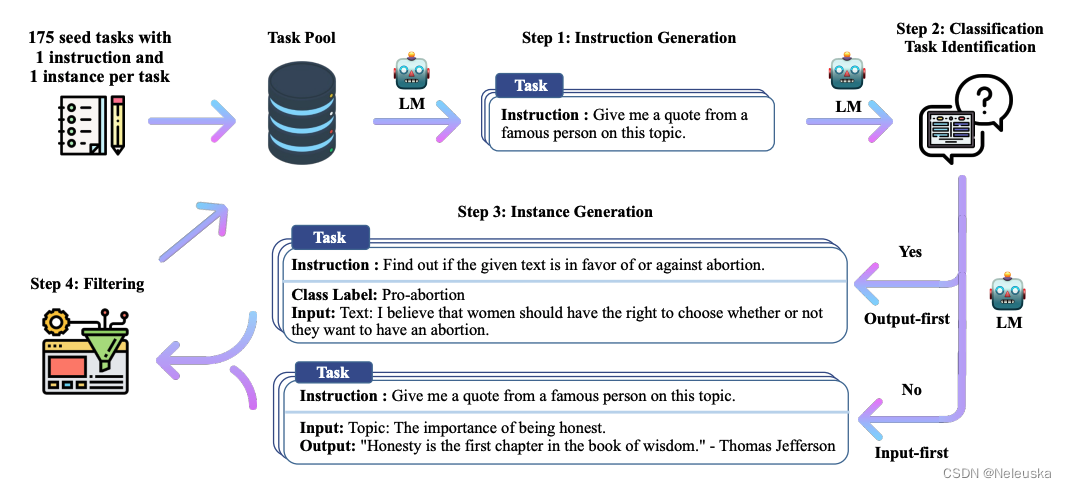
《SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions》
本论文提出了一种半自动化self-instruction过程,使用少量人工标注的数据,生成大量能用于instruction的数据。并开源了一个基于GPT3的52K self-instruct数据集。
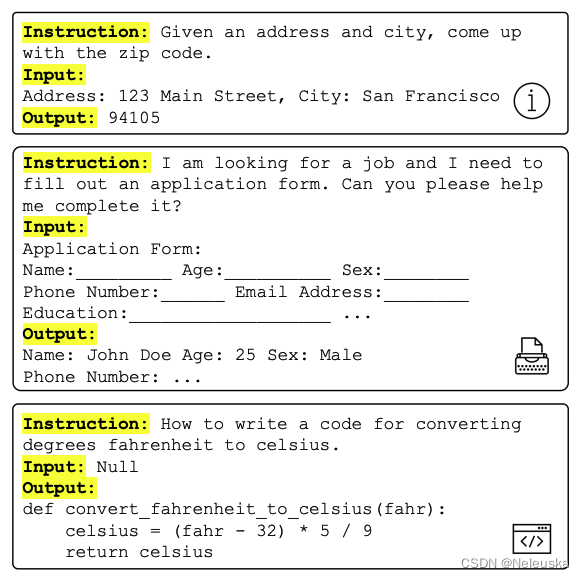
一般来说,instruction数据集,会包含两/三个部分:(指令、输入、输出)或(指令、输出)。如
本论文提出的方法包含几个步骤:
1.人工设计175个不同任务的启动任务池,且给每个任务编写一个instruction和一个实例。
2.使用LLMs生成新的指令。生成指令的prompt由6个人工编写的instruction和从模型生成结果中抽取2个instruction,按照指定模板公式组合后,输入模型,并输出一个新的指令
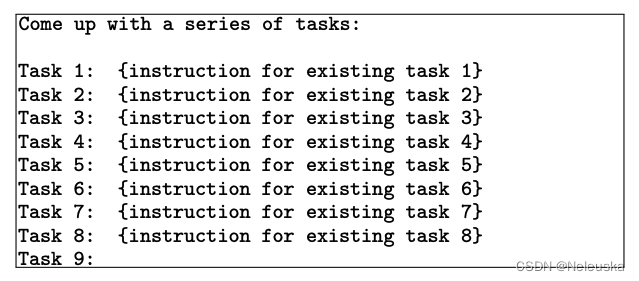
3.判断指令是否属于分类任务。由于分类任务和非分类任务用的prompt模板不同,故需要进行分开识别。分别从任务池中抽取分类instruction和非分类instruction,再加上新生成的指令,输入模型,模型输出是否为分类任务
4.生成实例。分为两种策略:
- (1)先生成输入,在生成输出。适用于非分类任务。
- (2)先生成输出,再生成输入。适用于分类任务,缓解生成结果单一化问题。
5.结果过滤。对于新生成的instruction,比较其与任务池中的instruction的ROUGE-L值,当小于0.7时才会加入任务池。(ROUGE-L越大,说明instruction越相似)
《Automatic chain of thought prompting in large language models》
LLMs通过生成中间推理步骤的方式可以做复杂任务推理。在prompt示例(demonstration)中引入这些推理步骤的方法称为chain-of-thought(CoT) prompting,即:思维链prompting。
传统的CoT分为两种范式:
1.Zero-Shot-CoT: 在LLMs中添加一个简单的prompt即可,如"Let’s think step by step"。以促进在回答问题之前一步步地思考。
2.Manual-CoT: 加入多个由人工设计的prompt,包含问题、推理链和答案。
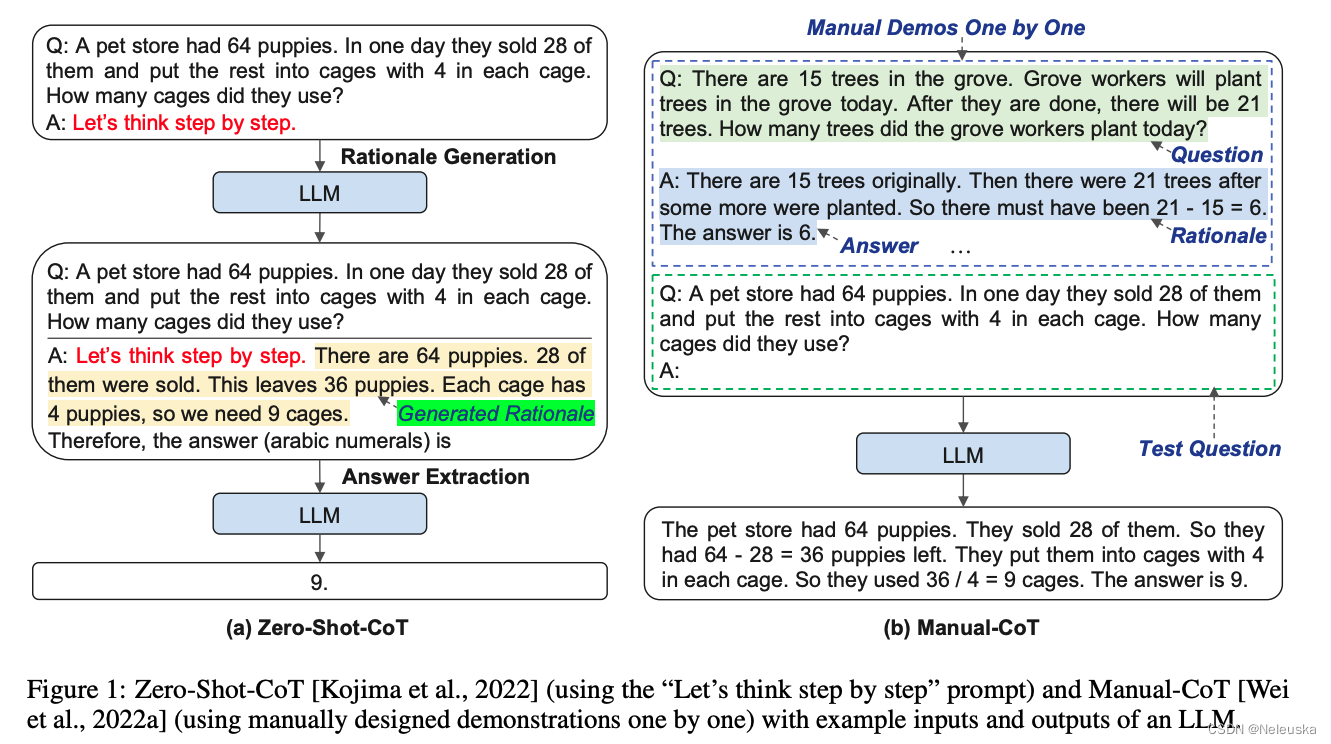
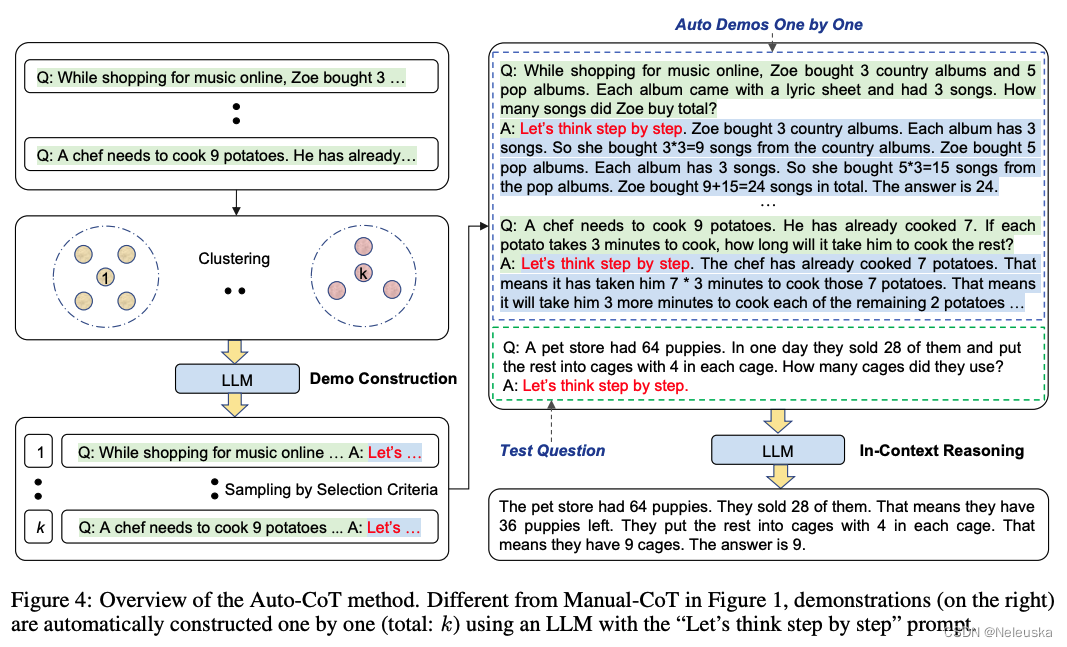
由于Zero-Shot-CoT方法存在不稳定性,而Manual-Cot方法需要大量人工成本投入。作者提出了一种基于Auto-CoT的方法,自动构建包含问题和推理链的说明样例(demonstrations)。
整个过程分了两个阶段:
1.question cluster: 目的是将数据集中的question划分到不同簇中。
- 使用Sentence-Bert计算每个question的向量表示;
- 使用k-means方法将question记性簇划分;
- 最后对每个簇中的question,根据距离中心点距离,升序排序。
2.demostration sampling: 目的是从每个簇中选取一个代表性的question,基于LLMs,使用Zero-Shot-CoT生成推理链。
-
对于每一个簇 i i i里的每一个问题 q j ( i ) q^{(i)}_j qj(i),使用Zero-Shot-CoT的方法,将 [ Q : q j ( i ) , A : [ P ] ] [Q:q^{(i)}_j,A:[P]] [Q:qj(i),A:[P]](其中 [ P ] [P] [P]表示"Let’s think step by step")输入到LLMs,LLMs生成该问题的推理链 r j ( i ) r^{(i)}_j rj(i)和答案 a j ( i ) a^{(i)}_j aj(i);
-
若问题 q j ( i ) q^{(i)}_j qj(i)不超过60个tokens,且推理链 r j ( i ) r^{(i)}_j rj(i)不超过5个推理步骤,则将问题+推理链+答案,加入到demostrations列表中: [ Q : q j ( i ) , A : r j ( i ) 。 a j ( i ) ] [Q:q^{(i)}_j,A:r^{(i)}_j。a^{(i)}_j] [Q:qj(i),A:rj(i)。aj(i)];
-
遍历完所有簇,将得到k个demostrations,将其拼接上测试question,构造成新的Prompt,输入LLMs便可得到生成结果。
值得一提的是,Auto-CoT在多个开源推理任务的数据集上,效果与Manual-CoT相当,甚至某些任务表现得更好。
《Least-to-Most Prompting Enables Complex Reasoning in Large Language Models》
虽然CoT在很多自然语言推理任务上效果显著,但是当问题比prompt里的demostrations更难时,LLMs的表现往往会很糟糕。于是作者提出了Least-to-Most Prompting的策略思想,将问题分解成一个个小问题,结合使用COT,那么模型就能把问题解出来了。
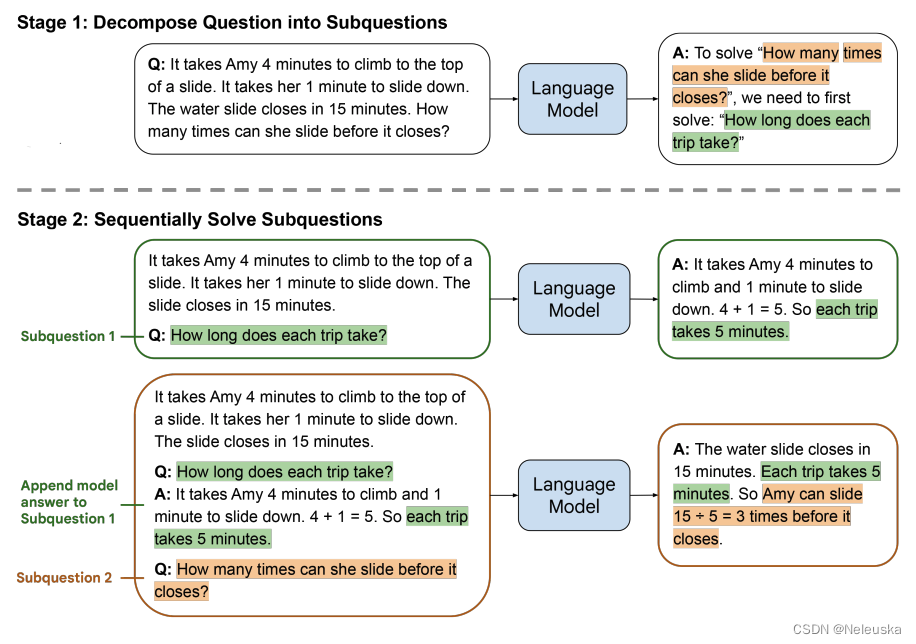
整个过程分为两个阶段:
1.将原问题分解为一系列子问题。
- 要求LLMs根据输入和提示"To solve xx, we need to solve xx",生成子问题。
2.依次解决子问题,最后解决原始问题。
- 将原始context,加上阶段1中生成的子问题进行组合,通过LLMs依次生成每个子问题的思维链和答案。
- 当生成完所有子问题的答案后,再拼接上原始问题,通过LLMs输出生成结果。
4.3 示例排序
我们知道,demostrations一般是由多个示例组成,而不同的示例排序会不会对模型在新样本中的表现产生影响?
论文《Calibrate before use: Improving few-shot performance of language models》给出了肯定的答案。作者指出,在一个正常的prompt+demostrations+新样本的输入中,LLMs会更加倾向于将新样本对应的标签,预测为demostrations最后一个示例对应的标签,成为Recency Bias。因此demostrations的排序,对LLMs的表现也是有相当大的影响。
4.3.1 启发式方法
《What Makes Good In-Context Examples for GPT-3?》
我们在选择那一节有介绍过该论文,思路是使用k-nearest neighbors+欧式距离的方法,根据与测试样本的相似度,对demostrations进行排序,与测试样本越相似,排序越后。
4.3.2 基于熵的方法
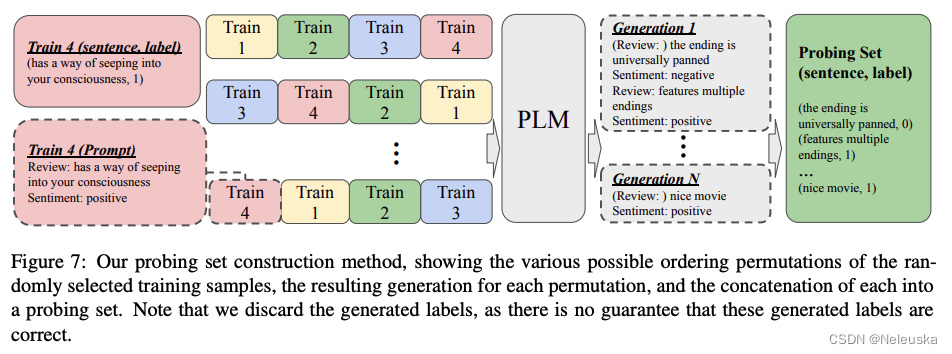
《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》
作者提出了一种基于Global Entropy和Loacl Entropy的方法对demostrations进行排序,取得了比随机排序更优的效果。
该过程分为两个步骤:
1.生成用来验证的无标注数据集。
- 将demostrations按照不同的顺序排列,输入LLMs,让其生成不同带标签的伪数据。
2.确定评价指标来评估demostrations的展示顺序优劣。
- 作者观察到大多数使模型失效的demostrations顺序,会让模型的标签分布相对极端,从而导致标签分布的熵值较低。
- 设计了两种基于熵的指标(Global Entropy和Loacl Entropy),来评估当前demostrations排序的结果质量。
5.总结
从上述论文可知,对于In-Context Learning而言,demonstration的选择、格式、以及排序,都会对测试样本的效果产生影响。在实际应用时,可以根据自己的场景选择适合的ICL方法。
6.Reference
What Makes Good In-Context Examples for GPT-3?
Diverse demonstrations improve in-context compositional generalization
Learning To Retrieve Prompts for In-Context Learning
Active Example Selection for In-Context Learning
Self-generated in-context learning: Leveraging auto-regressive language models as a demonstration generator
Cross-task generalization via natural language crowdsourcing instructions
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
Automatic chain of thought prompting in large language models
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Calibrate before use: Improving few-shot performance of language models
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity






![[论文笔记] Atos: A Task-Parallel GPU Scheduler for Graph Analytics](https://img-blog.csdnimg.cn/68206d5564ea415f8f1b2cbd07d2f33d.png)



