Atos: A Task-Parallel GPU Scheduler for Graph Analytics
Atos: 用于图分析的任务并行 GPU 调度程序 [Paper] [Slides]
ICPP’22
摘要
提出了 Atos, 一个特别针对动态不规则应用的任务并行 GPU 动态调度框架.
- 支持消除依赖关系的应用的任务并行公式来暴露额外的并发性
- 除了数据并行负载平衡之外, 提供隐式任务并行负载均衡
- 允许用户控制内核策略和任务并行粒度来适配不同用例
1 介绍
批量同步并行(Bulk-synchronous parallel, BSP)编程非常适合静态调度的、规则的问题; 而一些不规则的问题自然要使用基于任务的编程模型.
本文考虑非常细粒度的任务分配问题, 聚合一组相似的应用级别的任务来构成数据并行的 GPU 任务.
Gunrock 等类似 GPU 框架, 图遍历时的每个边界结点(frontier)在 BSP 模型中都作为的单独 GPU 内核启动; 可能导致并行性不足、完成时间不均匀、小边界结点集造成的过大内核启动开销.
为解决上述问题, 本文提出了 Atos, 一个 GPU 任务调度框架:
- 通过提供持续和非持续任务调度程序来支持开销不同的边.
持续调度程序(persistent scheduler): 一个持续运行的 GPU 内核, 以最小化启动开销 - 允许用户通过选择 worker 大小(每个 worker 中的 GPU 线程数)和每个任务中的项目数来权衡任务和数据并行性
- 使用单个共享任务队列
- 支持跨边界结点集的异步执行, 以最大化可用的并行性; 同时尽可能保留跨边界结点集的顺序, 从而最小化过度工作.
文章贡献:
- 开发了一个通用 GPU 任务并行框架
- 展示了混合任务和数据并行对细粒度并行应用的益处
- 将可消除同步的应用识别为 GPU 任务并行框架加速的有力候选者
- 对应用程序性能的详细分析
2 动态、不规则的应用模式

内部循环可被展开, 同时可以放宽外部循环迭代.
应用程序表现的动态、不规则并行性:
- 在外部循环边界结点集上的任务数量不同
- 每个内部循环任务的开销可能不同
- 总工作量可能不同
不特定于图算法.
2.1 动态、不规则问题的性能挑战
小边界结点集问题:
- 固定开销(全局同步屏障的开销加上内核启动开销)主导了整个处理开销; GPU 花费大量时间配置或等待计算, 而非执行计算.
- 小边界结点集不足以让 GPU 充满工作, 而使处理单元闲置
负载不均:
由于工作负载是动态产生的, 因此静态计算工作分配不可行.
最佳的负载均衡技术与问题相关, 对于一个固定问题也可能与输入相关.
并发机会的缺失:
放宽跨边界结点集顺序:
- 公式为嵌套循环的问题, 但其计算可以在 BSP 迭代中重新排序.
- 推测在后续迭代的工作不依赖于先前迭代的工作, 并在推测不正确时修复错误或重新计算.
3 我们的任务并行编程模型和设计空间
- worker: 一个或一组 GPU 线程
- 任务(task): 在系统中作为单元进行调度的一项或多项工作
- 应用程序函数(application function) f ( ) f() f(): 处理每个任务的代码

- 一次内核调用, 避免多次启动小内核
- 任务并行是隐式负载均衡的, 因为 worker 可以运行独立的任务并保存忙碌即使任务需要不同的工作量.
- 没有全局同步, 而由编程者控制工作调度, 这允许更灵活的依赖关系并带来更多并发机会.
管理任务依赖关系
Atos 编程模型中: 任务(运行在一个 worker 中)同步执行, 不同任务(跨 worker)异步执行.
只有任务的依赖关系满足时, 任务才被添加到任务队列.
给编程者带来负担, 但总体优势时支持动态生成的基于任务的计算.
四个关键设计选择:
- 消除屏障(relaxing barrier)
- worker 大小
- 数据并行 vs 任务并行
- 内核策略
3.1 消除屏障
消除屏障并放宽外部循环的依赖关系, 同时计算出正确结果的方法:
- 推测两个任务可同时计算或不分先后完成, 且不改变计算正确性.
推测正确则暴露更多并发性; 推测错误则需要开销或大或小的修正. - 问题的公式在乱序计算项目时具有鲁棒性. Dijkstra 的问题不关心不确定性(Dijkstra’s don’t care non-determinism).
如果消除全局屏障而增加的并发性带来的性能提升超过产生的额外开销(错误推测、修复错误推测), 就可实现性能提升.
Atos 允许即使违反了依赖关系的计算提交, 并只在之后修复错误.
3.2 Worker 大小
假依赖(false dependency): 数据项的所有依赖都已满足, 但因为同一任务中的另一数据项具有未满足的依赖而不能处理的情况.
通过将大任务分解为许多较小任务暴露更多并行性来减少这种假依赖.
worker 应该更小.
Atos 提供线程大小、warp 大小以及 CTA(Cooperative Thread Arrays, 协作线程组) 大小的 worker, 以支持不同大小和同步要求的任务.
3.3 数据与任务之间的平衡
Atos 中 worker 不直接相互同步, 允许 worker 在可用时立即处理可用的工作项(“隐式任务并行负载均衡”).
Atos 支持两个大于线程的 worker 大小(warp 和 CTA), 并为编程者提供了在每个 warp 大小或 CTA 大小的任务中利用数据并行的能力.
不同 worker 异步执行任务, 单个 worker 自身同步执行.
3.4 内核策略
持续内核(persistent kernel): 解耦数据大小和启动的 CTA. 仅启动足够的 CTA 来填充 GPU, 这些 CTA 驻留在内核中并运行映射到任务并行模型的循环.
持续内核的优点: 减少内核启动开销和 CPU/GPU 通信; 减少了 CPU 的参与, 理由编程者编写 GPU 逻辑.
持久内核的缺点: GPU worker 并发地从共享队列中取任务, 需要原子操作; 比独立内核(discrete kernel)更高的寄存器使用(需要额外的寄存器维护队列循环).
如果独立内核遭受巨大内核开销(小边界结点集问题), 则持续内核可能是首选; 否则, 选择独立内核会更好更简单.
4 框架 API

launch*: 启动重复从任务队列拿取任务的 worker
f1: 每个 worker 应用于拿取的任务的函数f2: worker 拿取任务失败时运行的函数numThread * numBlock不能超过基于应用的寄存器和共享内存使用可以并发驻留在 GPU 上的最大线程数(默认设置为最大值, 可被用户覆盖)launchCTA的numThread决定任务和数据并行之间的权衡FETCH_SIZE: 构成由 worker 从队列拿取的一个任务的数据项的数量.
增加(减少)FETCH_SIZE将减少(增加)其他 worker 的可用任务数量, 但会增加(减少)自身数据并行性.
warp 粒度的推测 BFS 示例:

5 三个案例研究
5.1 广度优先搜索


推测 BFS 算法 :
- 消除了外部循环的屏障约束
- 有一个动态的边界结点集; 许多独立的 CUDA worker 异步地向边界结点集中放入或拿取结点.
- 由于乱序迭代可能需要多次访问结点才能找到最短路径, 因此可能增加额外工作
5.2 PageRank

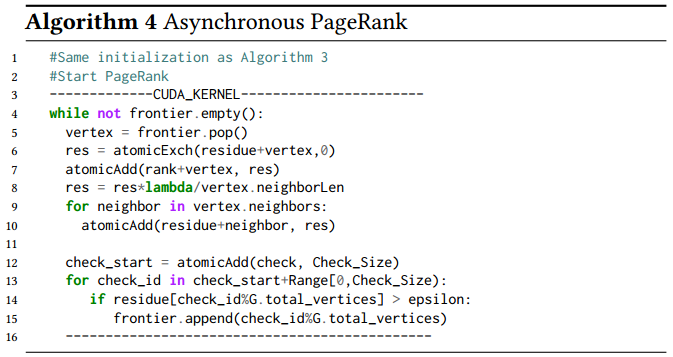
异步 PageRank 算法:
- 移除了全局同步, 并将两个内核融合
- CUDA worker 异步地从队列中拿取结点
5.3 图着色


异步推测图着色算法:
- 融合了两个内核
- 使用结点 ID 的符号区分颜色分配任务和冲突检测任务
- 在两个内核之间没有强制执行全局屏障
6 实验与分析
性能: Table 1
![]](https://img-blog.csdnimg.cn/68206d5564ea415f8f1b2cbd07d2f33d.png)
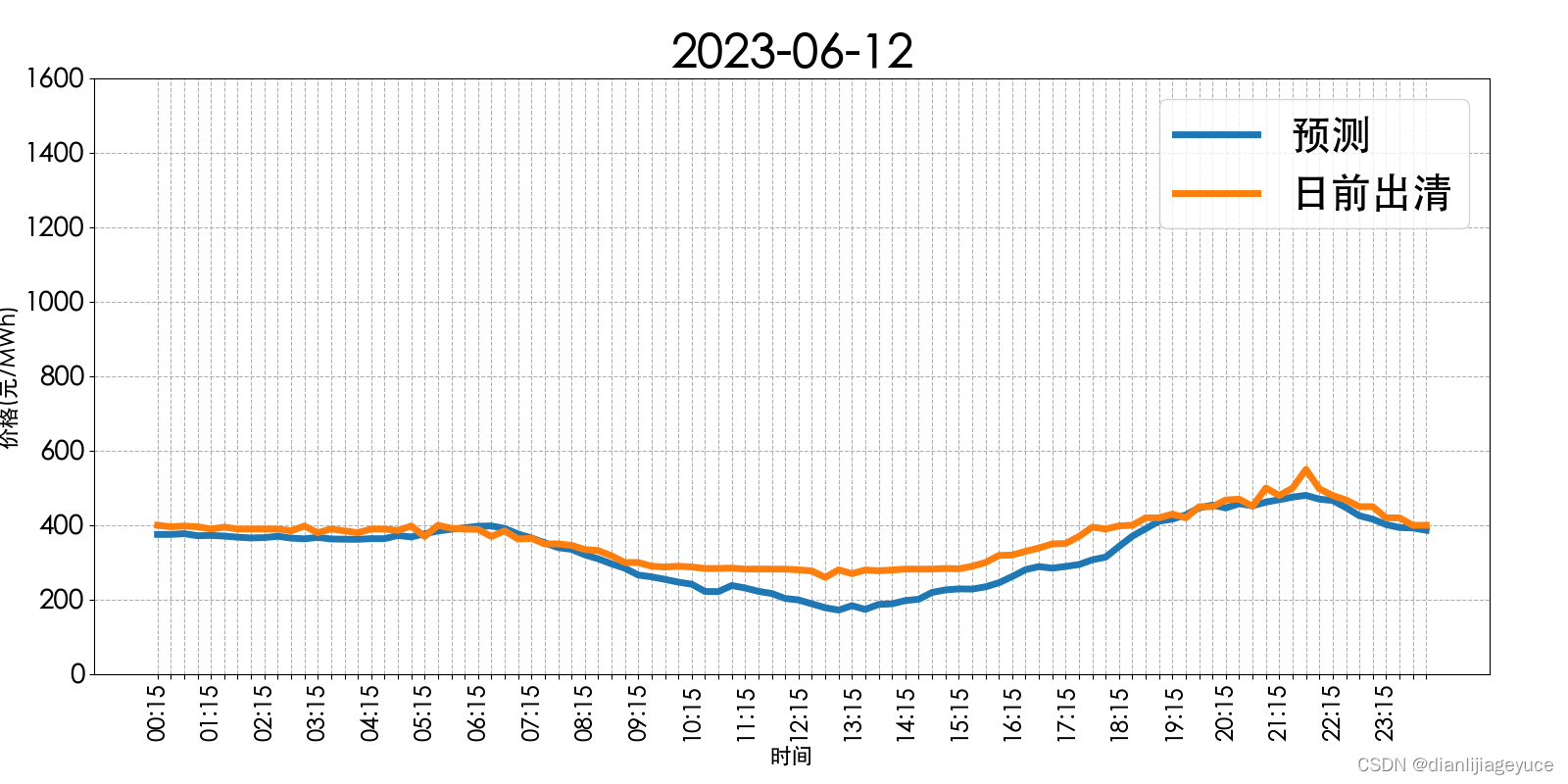
三个算法的吞吐量和用时: Figure 1, Figure 2, Figure 3
工作负载: Table 4
worker 大小和任务与数据并行负载平衡之间的权衡: Figure 4
笔者总结
本文的核心在于提出了一个任务并行 GPU 调度框架. 该框架基于任务并行, 使用单个共享任务队列, 允许用户通过选择 worker 大小和每个任务中的项目数 (负载均衡); 支持持续内核, 以及消除全局同步屏障的跨边界结点集的异步执行 (针对小边界结点集).
Atos 属于单机 GPU 图计算框架.