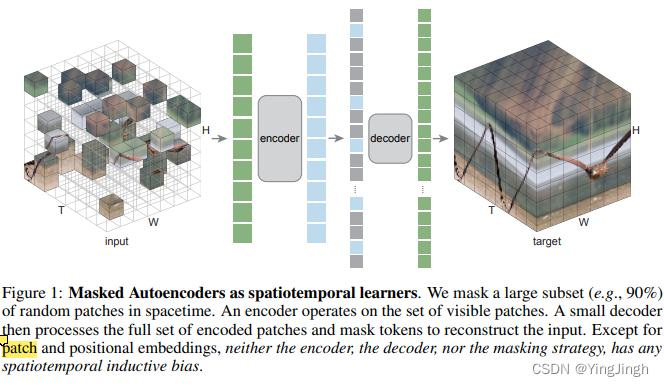
Masked Autoencoders As Spatiotemporal Learners
文章目录
- Masked Autoencoders As Spatiotemporal Learners
- 一、文章背景
- 二、文章变量
- 1 mask sampling 方式
- 2 Mask ratio
- 3 其余的ablation studies
一、文章背景
用于视频中的时间信息学习。
基本思想是重构,使用的类似于BERT的mask 然后reconstruct的方式。
We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels.
在mask的比例设置上,根据信息的冗杂度,在文本上bert是使用了15% ,在图片数据上是使用了75%,在视频video数据集上是使用了90%。
训练过程中存在的问题,视频加载速度慢,解决方式是采用对一个视频repeat sample的方式。
每次加载和解压一个原始视频时,我们都会从中抽取多个(默认为4个)样本。 这减少了每个样本的数据加载和解压时间
Each time a raw video is loaded and decompressed, we take multiple (4 by default) samples from it. This reduces the data loading and decompressing time per sample.
二、文章变量
1 mask sampling 方式

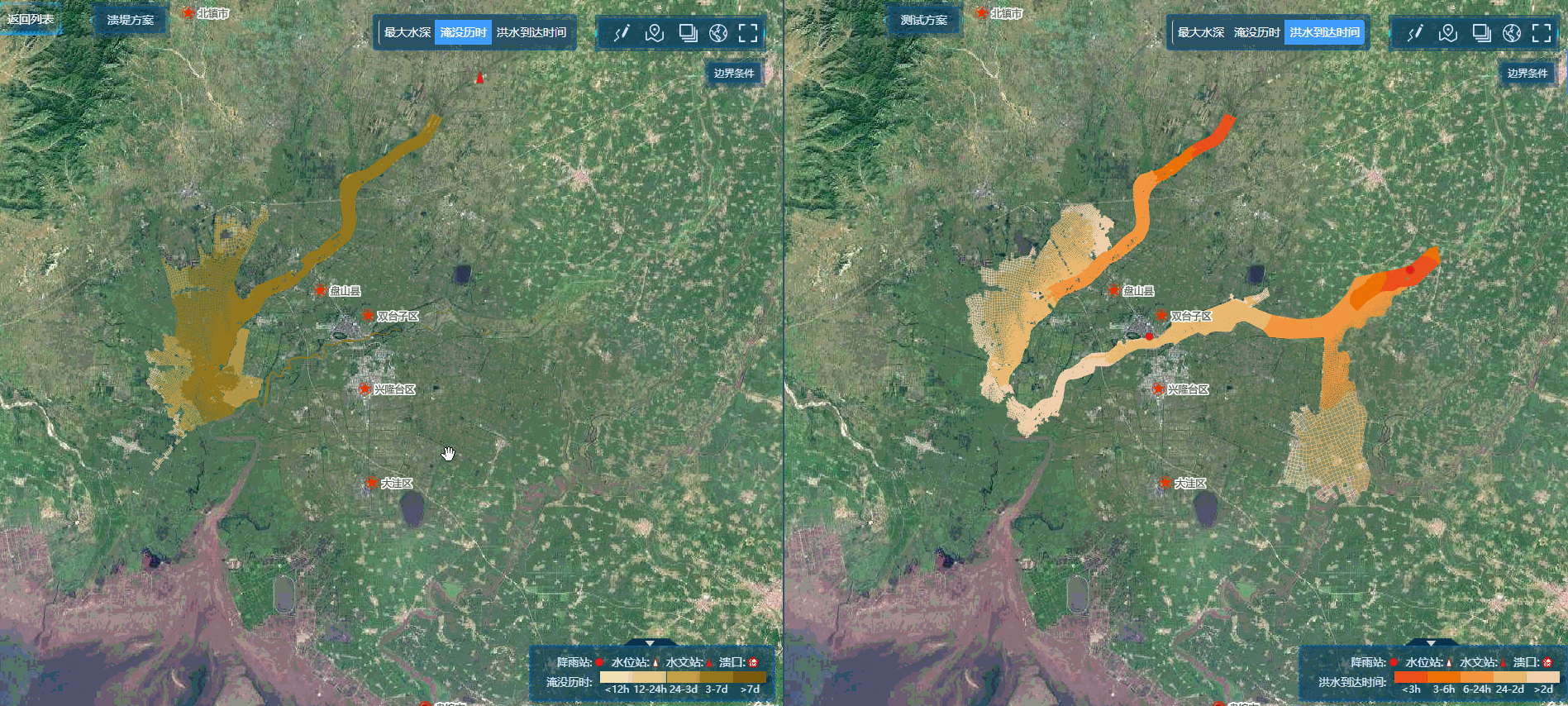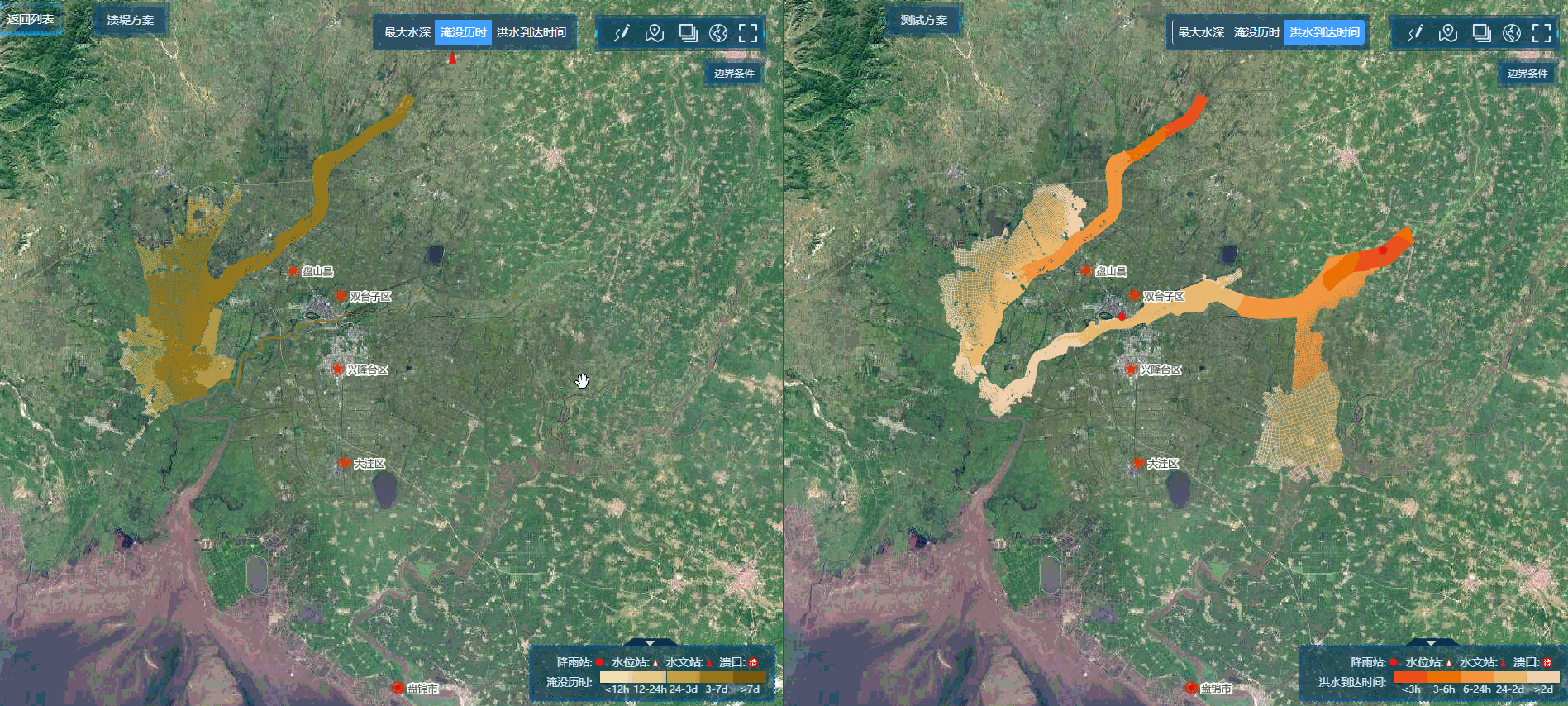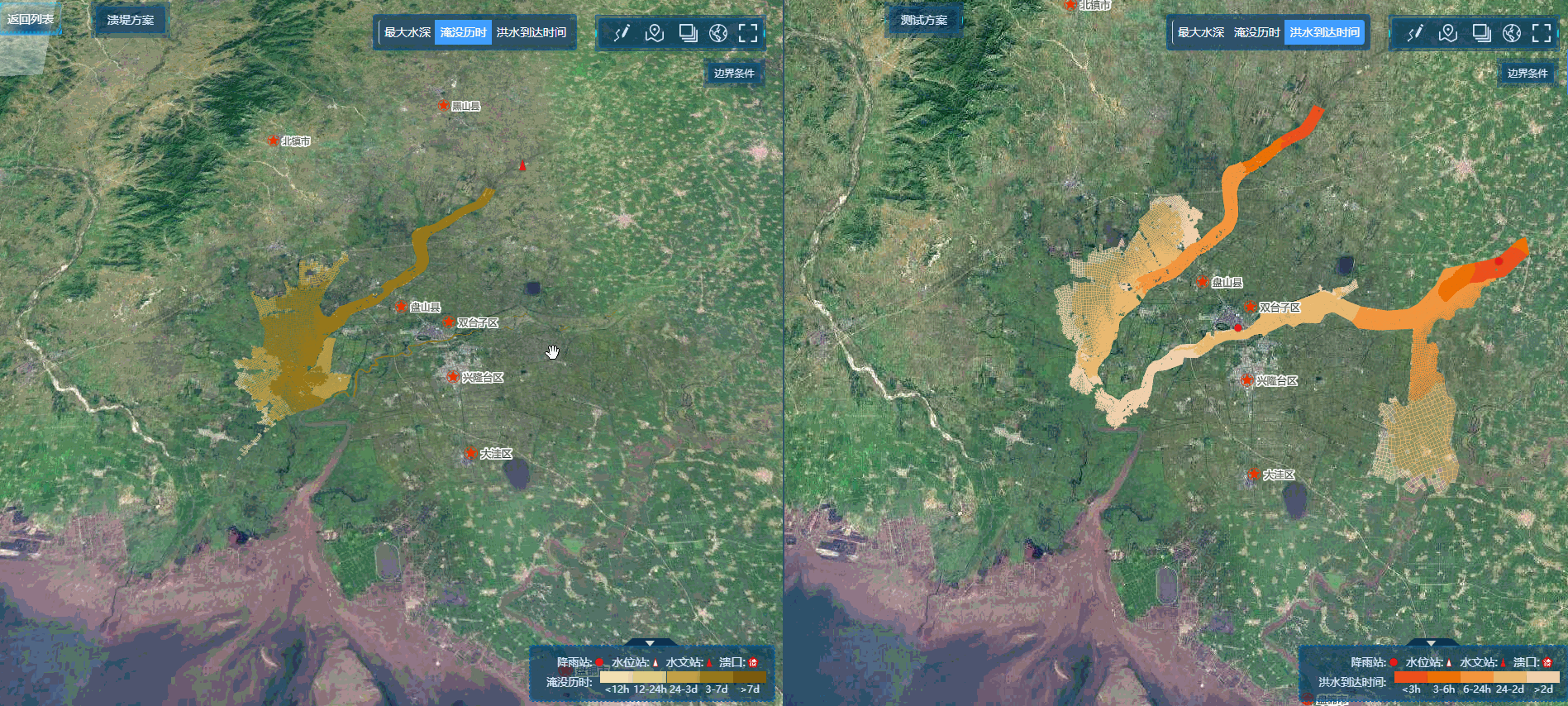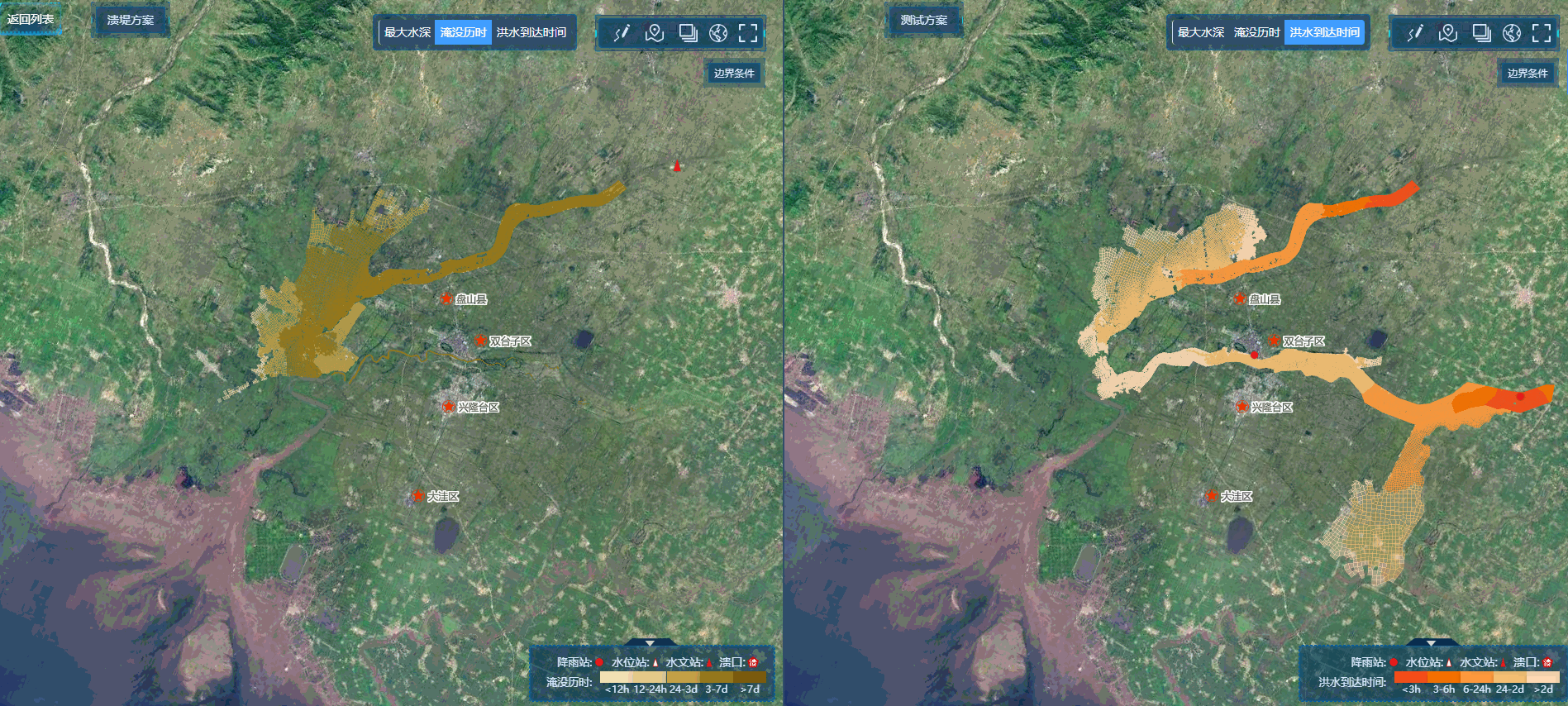
(a): 随机抽样是与空间时间无关的。(b): 仅限空间的随机抽样,广播到所有的时间步骤("管子 "屏蔽[77])。©: 仅限时间的随机抽样,广播到所有空间位置("框架 "掩蔽[77])。(d): 在时空中进行块状取样[3],去除大区域("立方体 "掩蔽[77])。在这个插图中,T×H×W是8×14×14;绿色标记被保留,其他标记被屏蔽掉了
2 Mask ratio
BERT[15]对语言使用15%的掩蔽率,MAE[31]对图像使用75%的掩蔽率,这表明图像比语言更具有信息冗余性。我们在视频上的经验结果支持这一假设。我们观察到的最佳掩蔽率是90%。
3 其余的ablation studies