背景
社区版 MySQL 支持的联邦引擎可以将位于远程数据库实例的表像本地表一样访问,大大方便了用户管理多个数据库实例的数据做聚合查询和分析。但是在性能方面存在着可以优化的地方:
- 只有在可以使用索引 RANGE/REF 方式扫描时,可以将索引上的条件作为 SQL 的一部分发送到远程数据库实例,而其他条件都保留在本地数据库执行;
- 即使 SQL 只访问了联邦表的一列数据,仍然会拉取远程表的全部列数据到本地;
- 带有 LIMIT OFFSET 语法的 SQL,也会拉取全部的数据到本地。
针对这三个问题,PolarDB MySQL 实现了条件下推、按需返回列和 LIMIT OFFSET 下推功能,能够在最大程度的减少无效数据的访问和传输代价,大大提升执行效率。这篇文章会在 PolarDB MySQL 线上环境中,各自模拟这三种场景的查询,测试这些特征对性能的提升情况。
条件下推
条件下推将数据在远程过滤,减少网络 IO 和本地格式转换代价
对于涉及联邦引擎的查询,社区版 MySQL 只有在可以利用索引 RANGE/REF 扫描时,才能将索引上的条件下推,其他的条件保留在本地 server 执行。而实际情况中,一条查询的 WHERE 条件涉及字段可能比较多,或者在索引字段上使用了 function 导致无法直接使用索引,这时联邦引擎会向远程 server 发送全表扫描查询,将所有数据都拉回本地后执行。这种执行方式显然是非常低效的,既导致大量数据的网络传输占用带宽,又带来大量数据在本地进行拷贝、格式转换的代价,通过尽可能将兼容的条件下推,可以使数据在远程就被过滤掉,提升执行性能。
我们使用包含 1 千万条数据的 sysbench 表来模拟在不同选择率条件下,条件下推带来的性能收益,远程和本地 server 均为 4c32G 规格 PSL5 PolarDB MySQL 标准实例,远程表和联邦表定义为:
CREATE TABLE `sbtest1` (
`id` int NOT NULL,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_1` (`k`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE SERVER s
FOREIGN DATA WRAPPER mysql
OPTIONS (USER 'username', PASSWORD 'password', HOST 'hostname', PORT 3306, DATABASE 'dbname');
CREATE TABLE `sbtest1` (
`id` int NOT NULL,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_1` (`k`)
) ENGINE=FEDERATED DEFAULT CHARSET=utf8 CONNECTION='s'
使用如下查询:
local> set optimizer_switch='engine_condition_pushdown=off';
Query OK, 0 rows affected (0.03 sec)
local> EXPLAIN SELECT COUNT(*) FROM sbtest1 WHERE id + 1 < 100;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.04 sec)
local> set optimizer_switch='engine_condition_pushdown=on';
Query OK, 0 rows affected (0.10 sec)
local> EXPLAIN SELECT COUNT(*) FROM sbtest1 WHERE id + 1 < 100;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------------------------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------------------------------------------------------------------------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using where with pushed condition ((`federated`.`sbtest1`.`id` + 1) < 100) |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------------------------------------------------------------------------------------+
1 row in set, 1 warning (0.05 sec)
由于 WHERE 条件中使用的是包含主键的 function 与常量进行比较,最优执行计划使用的是全表扫描方式。差别在于是否将 WHERE 条件下推到远程执行,通过改变常量值为selectivity * table_size,构造不同的选择率条件,测试性能得到:


可以看到当条件选择率较低(小于0.1)时,有约一倍的性能提升。


通过监控也可以看看测试期间对于网络带宽的占用情况,在测试过程中,条件下推与不下推的查询交替进行,可以看到:
- 当条件不下推时,对于网络带宽的占用很高,且在不同选择率条件下都是相同的;
- 当条件下推且选择率较低(小于0.1)时,网络的流量非常小,随着选择率的增大逐渐增多,和条件不下推的网络 IO 相比有明显区别。
条件下推给远程 server 更多的执行计划选择,带来更优的计划
涉及联邦引擎的查询在寻找最优执行计划时,本地的统计数据非常有限,是临时向远程 server 发送SHOW TABLE STATUS LIKE 'table_name'命令获取的,返回的结果里只有表一共多少行的估算是可用的。索引上的统计信息完全缺失,因此在涉及索引选择时会出现非常大的代价偏差,下面的例子可以说明:
沿用上节的表定义,远程表中包含 1 千万条数据,k 也从 1 到 1 千万均匀随机分布。当使用如下查询时,不论 WHERE 条件的值为什么,优化器都会默认选择联邦表的主键 RANGE 扫描方式,因为优化器不具备根据值来估算代价的能力:
local> EXPLAIN SELECT COUNT(*) FROM federated.sbtest1 WHERE id < 10000000 AND k BETWEEN 9000000 AND 9000100;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | sbtest1 | NULL | range | PRIMARY,idx_1 | PRIMARY | 4 | NULL | 2 | 2.50 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
# WHERE 条件是 id < 10000000 AND k BETWEEN 9000000 AND 9000100 时,trace 输出:
"range_scan_alternatives": [
{
"index": "PRIMARY",
"ranges": [
"id < 10000000"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"in_memory": -1,
"rows": 2,
"cost": 1.31,
"chosen": true
},
{
"index": "idx_1",
"ranges": [
"9000000 <= k <= 9000100"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"in_memory": -1,
"rows": 2,
"cost": 1.31,
"chosen": false,
"cause": "cost"
}
]
# WHERE 条件是 id < 10 AND k BETWEEN 9000000 AND 9000100 时
"range_scan_alternatives": [
{
"index": "PRIMARY",
"ranges": [
"id < 10"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"in_memory": -1,
"rows": 2,
"cost": 1.31,
"chosen": true
},
{
"index": "idx_1",
"ranges": [
"9000000 <= k <= 9000100"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"in_memory": -1,
"rows": 2,
"cost": 1.31,
"chosen": false,
"cause": "cost"
}
]
从上面 optimizer trace 在不同条件下的输出可以看到,代价的评估结果都是相同、根据默认值生成的。由于用到主键索引,MySQL 社区版会将主键上的条件下推,其他条件保留,所以这条查询实际发往到远程表的 SQL 为:
remote> EXPLAIN SELECT id, k, c, pad FROM sbtest1 WHERE id < 10000000;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | sbtest1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 4925050 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
造成主键扫描返回大量的数据。而如果我们将字段 k 上的条件也下推,会给远程优化器更多的索引选择空间,而且在远程 server 上是有索引上的统计信息,也可以 index dive 去根据具体值估算代价,得到更优的执行计划:
remote> EXPLAIN SELECT id, k, c, pad FROM sbtest1 WHERE id < 10000000 AND k BETWEEN 9000000 AND 9000100;
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | sbtest1 | NULL | range | PRIMARY,idx_1 | idx_1 | 4 | NULL | 92 | 50.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
所以开启下推所有条件,可以带来性能的大幅提升:
local> set optimizer_switch='engine_condition_pushdown=off';
Query OK, 0 rows affected (0.00 sec)
local> SELECT COUNT(*) FROM federated.sbtest1 WHERE id < 10000000 AND k BETWEEN 9000000 AND 9000100;
+----------+
| COUNT(*) |
+----------+
| 94 |
+----------+
1 row in set (8.49 sec)
local> set optimizer_switch='engine_condition_pushdown=on';
Query OK, 0 rows affected (0.00 sec)
local> SELECT COUNT(*) FROM federated.sbtest1 WHERE id < 10000000 AND k BETWEEN 9000000 AND 9000100;
+----------+
| COUNT(*) |
+----------+
| 94 |
+----------+
1 row in set (0.00 sec)
按需返回列
联邦查询在获取远程表的数据时,返回的是所有列的值;但实际情况中,一条查询可能只需要部分列的值,其他列的值并没有发挥作用,反而增加了远程服务器选取、格式转换的代价,增加了网络传输数据量,占用带宽。因此 PolarDB MySQL 在社区版 MySQL 的基础上做了进一步优化,使得联邦查询只会向远程 server 选取需要的列,大幅减少了远程 server 选取的代价和网络 IO,提升了查询性能,表的列数越多,效果越明显。
下面使用包含 1 百万数据,不同列数的表来模拟真实场景。包含 100 列的表定义如下,重复定义 sysbench 表中 k、c、pad 三列来拓宽表;减少字符类型的长度来支持定义更多列,而不至于空间占用非常剧烈,500 列的空间占用约为 5 GB,可以完全缓存在 Buffer Pool 中。
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(15) NOT NULL DEFAULT '',
`pad` char(8) NOT NULL DEFAULT '',
`k1` int(11) NOT NULL DEFAULT '0',
`c1` char(15) NOT NULL DEFAULT '',
`pad1` char(8) NOT NULL DEFAULT '',
...
`k32` int(11) NOT NULL DEFAULT '0',
`c32` char(15) NOT NULL DEFAULT '',
`pad32` char(8) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8
使用查询SELECT pad FROM sbtest1分别在按需返回列开启和不开启状态下进行测试,由于远程表在 pad 字段上没有索引,所以执行计划都是主键全表扫描,结果如下:
| 表列数 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|---|---|---|
| 按需返回列(s) | 2.97 | 3.1 | 3.09 | 3.96 | 4.55 | 4.95 | 5.74 | 6.91 |
| 返回全表(s) | 3.14 | 3.33 | 4.12 | 6.05 | 8.8 | 12.6 | 20.3 | 38.7 |
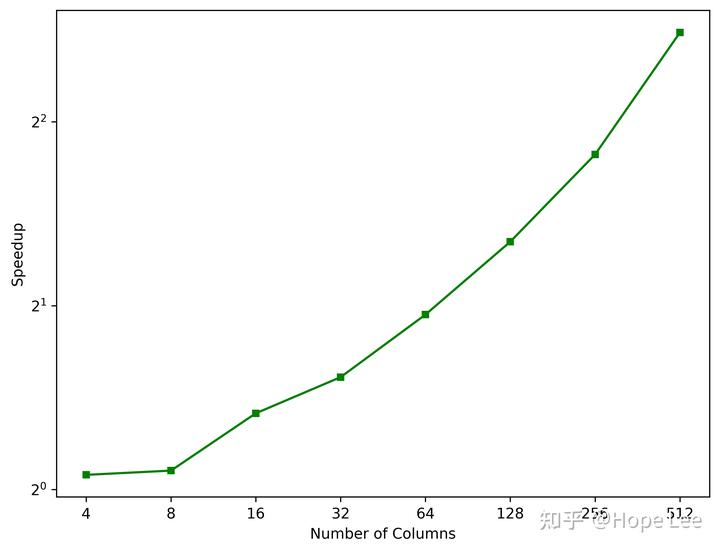

从加速比曲线可以看出,随着表列数的增加,按需返回列特征带来的加速比接近线性提升。
在测试过程中对网络 IO 的占用减少效果也非常明显:


此外,按需返回列特征也会增加远程 server 的计划选择空间,如果查询所访问的列可以用到索引,那么会在远程表使用索引扫描,而不是全表扫描,这会带来巨大的性能提升:
mysql> SET federated_fetch_select_field_enabled=OFF;
Query OK, 0 rows affected (0.19 sec)
mysql> SELECT SUM(k) FROM federated_col_64.sbtest1;
+--------------+
| SUM(k) |
+--------------+
| 499868973740 |
+--------------+
1 row in set (5.20 sec)
mysql> SET federated_fetch_select_field_enabled=ON;
Query OK, 0 rows affected (0.11 sec)
mysql> SELECT SUM(k) FROM federated_col_64.sbtest1;
+--------------+
| SUM(k) |
+--------------+
| 499868973740 |
+--------------+
1 row in set (0.45 sec)
LIMIT OFFSET 下推
社区版 MySQL 在联邦查询上的分页查询由于无法将条件全下推,所以必须将全部数据拉回本地,使用 WHERE 条件过滤后再进行分页。当 PolarDB MySQL 实现条件下推后,如果语句只涉及单个联邦表,且不包含聚合、窗口、UNION、DISTINCT、ORDER BY、HAVING 等影响结果正确性的语法时,就可以将 LIMIT OFFSET 语法下推到远程 server,仅返回需要的数据,本地 server 可以直接输出结果到客户端。使用效果如下:
local> set optimizer_switch='limit_offset_pushdown=on';
Query OK, 0 rows affected (0.05 sec)
local> EXPLAIN SELECT * FROM federated.sbtest1 LIMIT 100 OFFSET 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | Using limit-offset pushdown |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
1 row in set, 1 warning (0.06 sec)
local> set optimizer_switch='limit_offset_pushdown=off';
Query OK, 0 rows affected (0.05 sec)
local> EXPLAIN SELECT * FROM federated.sbtest1 LIMIT 100 OFFSET 1000;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
| 1 | SIMPLE | sbtest1 | NULL | ALL | NULL | NULL | NULL | NULL | 9850101 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
1 row in set, 1 warning (0.05 sec)
在 1 千万条数据的 sysbench 表上,使用LIMIT 100 OFFSET ?测试不同的 OFFSET 值:
| OFFSET 值 | 0 | 10 | 100 | 1000 | 10000 | 100000 | 1000000 | 10000000 |
|---|---|---|---|---|---|---|---|---|
| LIMIT OFFSET 下推 | 110 ms | 168 ms | 238 ms | 280 ms | 219 ms | 184 ms | 320 ms | 1.16 s |
| 未下推 | 6.7 s | 6.6 s | 6.68 s | 6.66 s | 6.69 s | 6.77 s | 6.94 s | 9.87 s |
OFFSET 值越小,效果越明显,最高约 60x 加速比。
总结
条件下推和按需返回列可以将不需要的数据和多余列在远程数据库就被过滤掉,对于过滤性强的条件和宽表有显著的性能效果,也减少了网络资源的带宽占用。同时可以给远程数据库更大的计划选择空间,更优的计划往往意味着查询性能巨大的提升。
LIMIT OFFSET 下推可以在分页查询场景仅查询需要的数据,加速效果非常明显。