入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、简单介绍与参考鸣谢
二、数据集介绍
三、数据预处理
1、重复标点符号表达
2、英文标点符号变为中文标点符号
3、繁体字转为简体字
4、限定长度
5、为后面制作词表做准备
6、代码实现(sol_data.py文件)
7、处理完的数据展示
四、词表制作以及转化(word2seq.py文件)
五、数据集加载(dataset.py)
六、GPT模型搭建(gpt_model.py)
1、原理解析
(1)Transformer与GPT
(2)多头注意力机制
(3)多头注意力机制
2、代码
七、训练模型(train.py)
八、补充实现(utils.py)
九、完整代码与结果
一、简单介绍与参考鸣谢
自己用pytorch搭建模型,训练一个小型的中文闲聊机器人。
数据集和实现思路部分参考这位博主大大@weixin_44599230的博文GPT模型介绍并且使用pytorch实现一个小型GPT中文闲聊系统_tinygpt_weixin_44599230的博客-CSDN博客
这位博主真的 tql 呜呜呜,他后续还出了另外一个版本的闲聊系统,在此鸣谢!
二、数据集介绍
数据集地址百度网盘 提取码jk8d
这份数据集是纯中文,没有英文、颜文字、数字等之类的干扰呜呜呜。
这份数据集是多轮次对话数据集,数据规模为50w,每一轮次用空行隔开。

三、数据预处理
虽然说这份数据集已经很nice了,但还是有一丢丢需要处理
1、重复标点符号表达
比如说:将“??????????????????”缩成“?”
emmm其实这个重不重复木有太大关系,主要是我想让他长度短一点,这样少点点计算
2、英文标点符号变为中文标点符号
比如说:“?"变为”?“
这也是为了让他别太复杂,算力有限能省就省(穷.jpg)
3、繁体字转为简体字
使用zhconv这个包。
这个包的下载安装以及使用方法可以看看这篇python汉字简繁体转换方法_python繁体字转简体字_一位代码的博客-CSDN博客
这位博主写得很清楚,点赞
4、限定长度
同样的算力有限哈哈哈,并且也希望数据集中样本长度相差别太大。我是限制每个样本(加上每句对话结束符后)长度不能超过100,这样数据集规模变为48w+。
5、为后面制作词表做准备
每个词(包括每句对话的结束符)用空格分开。
最早的时候我的想法是用jieba分词,将所得的所有分词作为我的词表,但是分词后词表的词频更加稀疏了,而且词表大小巨大(如果我没记错的话,词表大小是以万为单位的,害怕极了)。
于是乎我放弃了这种想法,就单独一个字一个字作为词来分就好了,这样词表大小是6000+个,大大减小了词表大小,词频也不会过于稀疏。
6、代码实现(sol_data.py文件)
其中的"import config"是我将所有配置信息都写在了config.py文件中,方便调整。
其中config.max_len=100,即前面提到的限制长度不超过100;
config.data_path_txt,即预处理后的数据保存地址
import re
from tqdm import tqdm
import zhconv
import config
#处理重复符号的表达,如替换多个重复符号
def delete_repeat(s):
#注释掉的是英文的表达
#s = re.sub('[!]+','!', s)
#s = re.sub('[?]+','?', s)
#s = re.sub('[,]+',',', s)
#s = re.sub('[:]+',':', s)
#s = re.sub('[;]+',';', s)
s = re.sub('[,]+',',', s)
s = re.sub('[!]+','!', s)
s = re.sub('[?]+','?', s)
s = re.sub('[:]+',':', s)
s = re.sub('[;]+',';', s)
s = re.sub('[。]+','。', s)
s = re.sub('[、]+','、', s)
return s
with open('data/origin_train.txt','r',encoding='utf-8') as f: #打开原始数据集
lines = f.readlines()
train_datas = []
temp_data = ''
#每个多轮对话中使用'<EOS>'将其划分
for line in tqdm(lines):
if line!='\n':
line = line.strip() #去除前导后方空格
#英文标点符号置换为中文标点符号
line = line.replace('!','!')
line = line.replace('?','?')
line = line.replace(',',',')
line = line.replace('.','。')
line = line.replace(':',':')
line = line.replace(';',';')
line = zhconv.convert(line, 'zh-cn') #转为简体字
line = " ".join(line)
temp_data+=(line+' <EOS> ')
else:
if len(temp_data.split()) <= config.max_len: #限制长度
train_datas.append(temp_data)
temp_data=''
with open(config.data_path_txt,'w',encoding='utf-8') as f: #将处理后的数据保存在另一个文件中
for train_data in train_datas:
f.write(train_data+'\n')7、处理完的数据展示

四、词表制作以及转化(word2seq.py文件)
先定义填充符<PAD>,未知符<UNK>和结束符<EOS>,然后再对数据集中的词进行标号,生成词表与转义词表,最后统计数据集中每个词出现的词频,生成一个词频表可以直观看看咱们的词表情况。
并且定义词到标号,标号到词的转化的方法,方便后期训练以及测试时使用。
其中,config.word_sequence_dict是保存词典的位置
#生成词表
#构造文本序列化和反序列化方法(文本转数字)
import pickle
import config
from tqdm import tqdm
class Word2Sequence():
PAD_TAG = "<PAD>" #填充编码
UNK_TAG = "<UNK>" #未知编码
EOS_TAG = "<EOS>" #句子结尾
#上面四种情况的对应编号
PAD = 0
UNK = 1
EOS = 2
def __init__(self):
#文字——标号字典
self.dict = {
self.PAD_TAG :self.PAD,
self.UNK_TAG :self.UNK,
self.EOS_TAG :self.EOS
}
#词频统计
self.count = {}
self.fited = False #是否统计过词典了
#以下两个转换都不包括'\t'
#文字转标号(针对单个词)
def to_index(self,word):
"""word -> index"""
assert self.fited == True,"必须先进行fit操作"
return self.dict.get(word,self.UNK) #无这个词则用未知代替
#标号转文字(针对单个词)
def to_word(self,index):
"""index -> word"""
assert self.fited == True, "必须先进行fit操作"
if index in self.inversed_dict:
return self.inversed_dict[index]
return self.UNK_TAG
# 获取词典长度
def __len__(self):
return len(self.dict)
#统计词频生成词典
def fit(self, sentence):
"""
:param sentence:[word1,word2,word3]
"""
for a in sentence:
if a not in self.count:
self.count[a] = 0
self.count[a] += 1
self.fited = True
def build_vocab(self, min_count=config.min_count, max_count=None, max_feature=None):
"""
:param min_count: 最小出现的次数
:param max_count: 最大出现的次数
:param max_feature: 总词语的最大数量
"""
# 限定统计词频范围
if min_count is not None:
self.count = {k: v for k, v in self.count.items() if v >= min_count}
if max_count is not None:
self.count = {k: v for k, v in self.count.items() if v <= max_count}
# 给对应词进行编号
if isinstance(max_feature, int): #是否限制词典的词数
#词频从大到小排序
count = sorted(list(self.count.items()), key=lambda x: x[1])
if max_feature is not None and len(count) > max_feature:
count = count[-int(max_feature):]
for w, _ in count:
self.dict[w] = len(self.dict)
else: #按字典序(方便debug查看)
for w in sorted(self.count.keys()):
self.dict[w] = len(self.dict)
# 准备一个index->word的字典
self.inversed_dict = dict(zip(self.dict.values(), self.dict.keys()))
#debug专用
f_debug_word = open("data/debug_word.txt","w",encoding='utf-8')
t = 0
for key,_ in self.dict.items():
t = t + 1
if t >= 4: #排除那3种情况(填充,未知,结尾)
f_debug_word.write(key+"★ "+str(self.count[key]) + "\n") #使用★ 区分是为了防止其中的词语包含分隔符,对我们后续的操作不利
f_debug_word.close()
def transform(self, sentence,max_len=None,add_eos=True):
"""
实现把句子转化为向量
:param max_len: 限定长度
:param add_eos: 是否在最后再补上<EOS>结束符
:return:
"""
assert self.fited == True, "必须先进行fit操作"
r = [self.to_index(i) for i in sentence]
if max_len is not None: #限定长度
if max_len>len(sentence):
if add_eos:
#添加结束符与填充符达到一定长度
r+=[self.EOS]+[self.PAD for _ in range(max_len-len(sentence)-2)]
else: #添加填充符达到一定长度
r += [self.PAD for _ in range(max_len - len(sentence)-1)]
else:
if add_eos:
r = r[:max_len-2]
r += [self.EOS]
else:
r = r[:max_len-1]
else:
if add_eos:
r += [self.EOS]
return r
def inverse_transform(self,indices):
"""
实现从句子向量 转化为 词(文字)
:param indices: [1,2,3....]
:return:[word1,word2.....]
"""
sentence = []
for i in indices:
word = self.to_word(i)
sentence.append(word)
return sentence
#以下可供第一次运行,下一次就可以注释掉了
#初始
word_sequence = Word2Sequence()
#词语导入
for line in tqdm(open(config.data_path.txt,encoding='utf-8').readlines()):
word_sequence.fit(line.strip().split())
print("生成词典...")
word_sequence.build_vocab(min_count=None,max_count=None,max_feature=None)
print("词典大小:",len(word_sequence.dict))
pickle.dump(word_sequence,open(config.word_sequence_dict,"wb")) #保存词典五、数据集加载(dataset.py)
定义一个ChatDataset类,可以逐一取出数据,并且获取数据集大小。
并且定义一个处理数据的方法——将句子中的词转为标号,并且进行填充。这里并不是整份数据集都是一样的样本长度,只要保证一个batch里的样本长度一致就好了(不一致就填充),这样设计的原因见后面的模型原理分析。
#构建数据集
import torch
import pickle
import config
from torch.utils.data import Dataset,DataLoader
from tqdm import tqdm
from word2seq import Word2Sequence
word_sequence = pickle.load(open(config.word_sequence_dict,"rb")) #词典加载
class ChatDataset(Dataset):
def __init__(self):
super(ChatDataset,self).__init__()
#读取内容
data_path = config.data_path_txt
self.data_lines = open(data_path,encoding='utf-8').readlines()
#获取对应索引的问答
def __getitem__(self, index):
input = self.data_lines[index].strip().split()[:-1]
target = self.data_lines[index].strip().split()[1:]
#为空则默认读取下一条
if len(input) == 0 or len(target)==0:
input = self.data_lines[index+1].split()[:-1]
target = self.data_lines[index+1].split()[1:]
#此处句子的长度如果大于max_len,那么应该返回max_len
return input,target,len(input),len(target)
#获取数据长度
def __len__(self):
return len(self.data_lines)
# 整理数据————数据集处理方法
def collate_fn(batch):
# 排序
batch = sorted(batch,key=lambda x:x[2],reverse=True) #输入长度排序
input, target, input_length, target_length = zip(*batch)
max_len = max(input_length[0],target_length[0]) #这里只需要固定每个batch里面的样本长度一致就好,并不需要整个数据集的所有样本长度一致
# 词变成词向量,并进行padding的操作
input = torch.LongTensor([word_sequence.transform(i, max_len=max_len, add_eos=False) for i in input])
target = torch.LongTensor([word_sequence.transform(i, max_len=max_len, add_eos=False) for i in target])
input_length = torch.LongTensor(input_length)
target_length = torch.LongTensor(target_length)
return input, target
print("数据集装载...")
data_loader = DataLoader(dataset=ChatDataset(),batch_size=config.batch_size,shuffle=True,collate_fn=collate_fn,drop_last=True)
'''''
#测试专用(debug)
if __name__ == '__main__':
for idx, (input, target) in enumerate(data_loader):
print(idx)
print(input)
print(target)
'''''六、GPT模型搭建(gpt_model.py)
1、原理解析
(1)Transformer与GPT
说到GPT就要提到Transformer啦。GPT是Transformer的Decoder部分。
Transformer的网络结构如下:(图是网上找的,侵权立删)
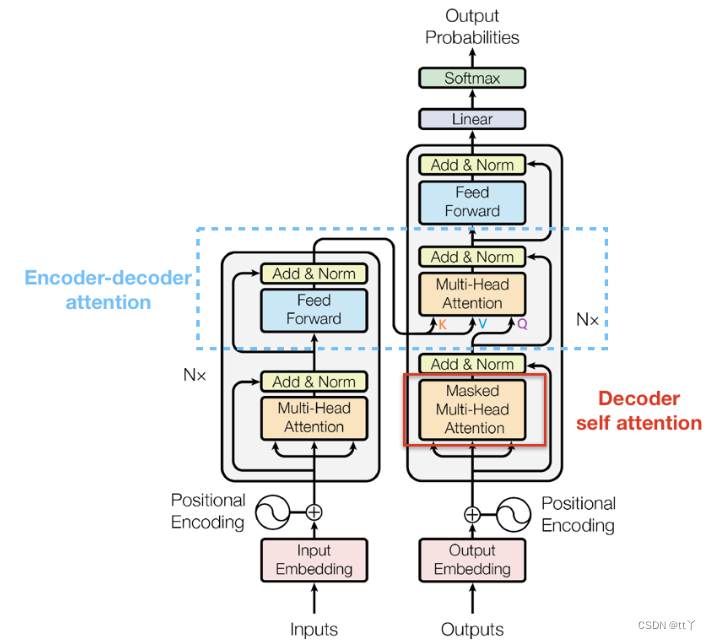
而GPT则如下:
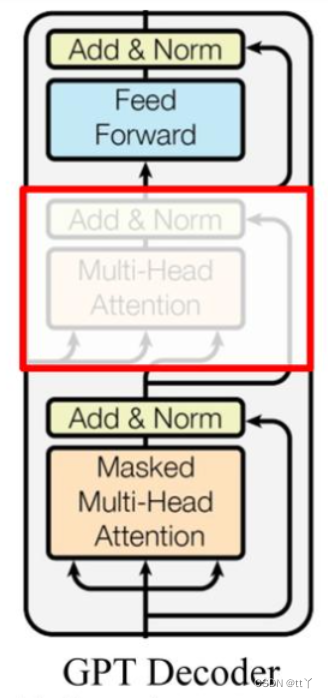
因为其没有encoder的输出作为另一个输入分支,所以去掉了encoder-decoder的attention机制。
(2)多头注意力机制
A、提出原因
self attention是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重,然后再以权重和的形式来计算得到整个句子的隐含向量表示(self attention提出原因:在深度学习领域,模型往往需要接收和处理大量的数据,然而在特定的某个时刻,往往只有少部分的数据是重要的。这种情况下应该让模型更加关注这些重要数据,这样他就可以在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题)。
但self attention的缺陷是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此提出了通过多头注意力机制来解决这一问题。
注:为了更好发挥并行输入的特点,首先要解决的问题就是要让输入的内容具有一定的位置信息,因此引入位置编码。
B、注意力机制
键值对注意力机制公式如下:
🌳 查询、键、值
在注意力机制下,将自主性提示称为查询(Query),key表示注意力分布,value表示聚合信息。即在给定一个Q的情况下,选择一个key并输出其对应的value,这里的key和value是一一对应的关系(K,V),当K=V时,键值对模式退化为一般注意力机制。
即:
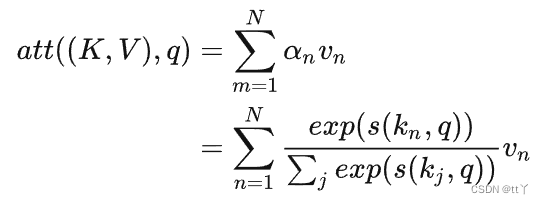
左边的α为注意力得分,即使用查询向量 q 和相应的键 kn 进行计算注意力权值,得到每个索引对应的注意力概率(softmax后的,取值0、1之间)。当计算出在输入数据上的注意力分布a之后,利用注意力分布和键值对中的对应值进行加权融合计算,使得整体表示当前时刻的上下文向量context(将注意力信息包含进去,越值得关注的,注意力得分越高)。
在自注意力机制中,这里的Q、K、V都使用输入信息进行生成,相当于模型读到输入信息后,根据输入信息本身决定当前最重要的信息。
🌳 具体步骤
输入信息 是H=[h1,h2] ,每行代表对应一个输入向量;
Wq,Wk,Wv 3个矩阵,它们负责将输入信息H依次转换到对应的查询空间 Q=[q1,q2] ,键空间 K=[k1,k2] 和值空间 V=[v1,v2] 。
第一步:
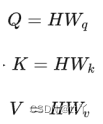
第二步——使用缩放点积模型求得注意力分布(通过除以一个平方根项——embdim来平滑分数数值):
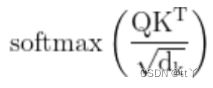
第三步——进行加权求和得到最终的context:
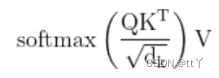
所以,最终为:
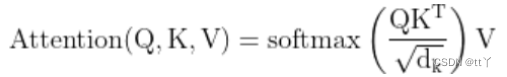
(3)多头注意力机制
利用多个查询向量Q=[q1,q2,...,qm] ,并行地从输入信息 (K,V)=[(k1,v1),(k2,v2),...,(kn,vn)] 中选取多组信息。在查询过程中,每个查询向量 qi 将会关注输入信息的不同部分,即从不同的角度上去分析当前的输入信息(在多个不同的投影空间中捕捉不同的交互信息)。
思路与前面的自注意力机制类似,只是把Q、K、V分别拆成相应的head数,然后按前面的思路来,最后用concat把不同部分的信息组合起来。
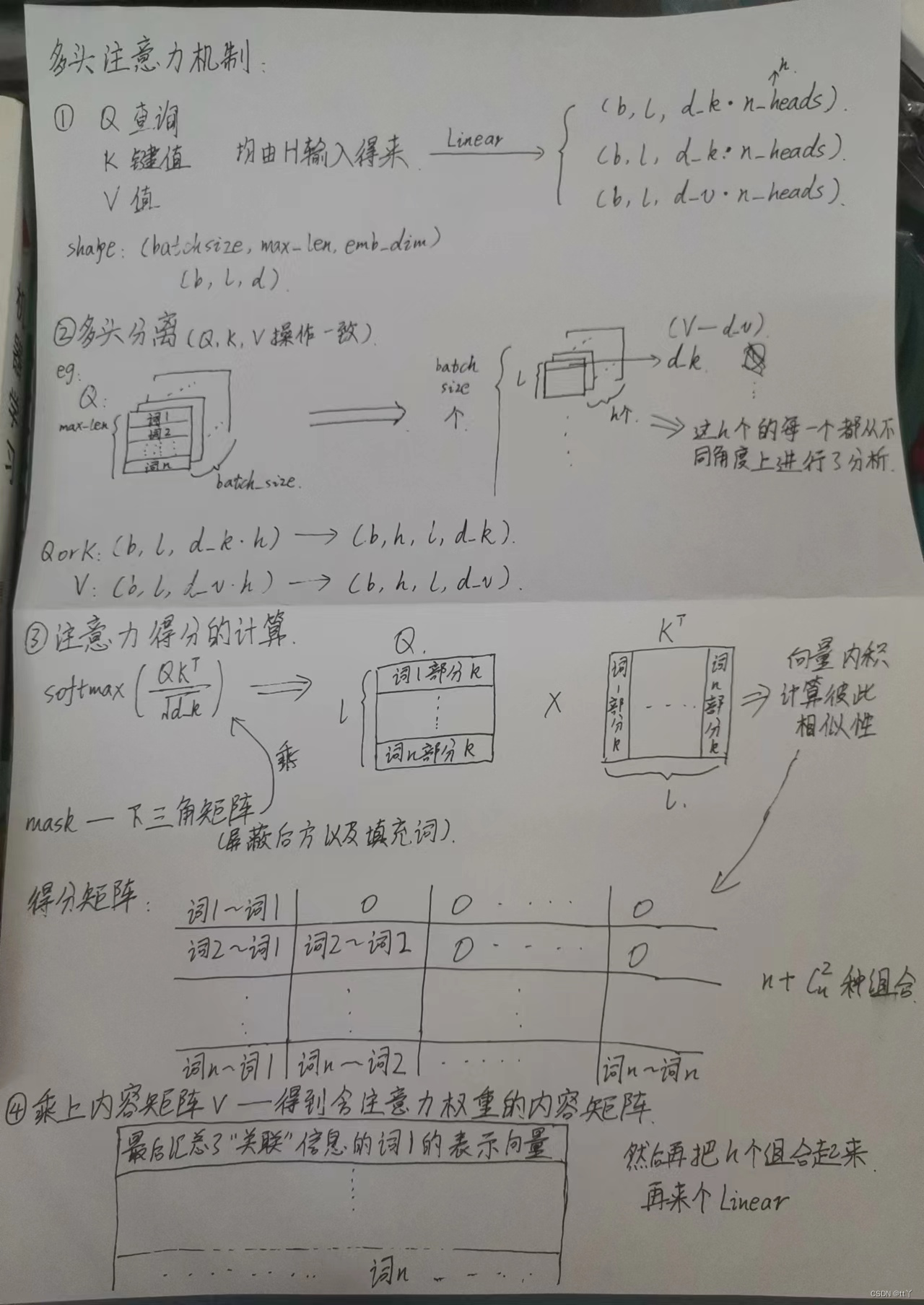
接上文所说的只要每个batch里的样本长度一致就行,不用整个数据集的样本长度都一致。
这么处理是因为网络的权重与样本长度没有关系,因此不用固定。这样就不用那么多的填充符啦。又节省计算,也能使模型不会总是去处理这些没有用的填充。可能只有我这么个憨憨,之前还固定整个数据集样本的长度(扶额)。
2、代码
import torch
from torch import nn
import math
import torch.nn.functional as F
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
#生成掩码矩阵mask
def create_masks(input):
#input的shape为:(batch_size, max_len)
def subsequent_mask(size):
mask = torch.tril(torch.ones(size, size).type(dtype=torch.uint8)) #torch.triu()返回一个下三角矩阵(让其只注意到前面的信息,后面注意不到,因为为0)
return mask.unsqueeze(0) # shape: (1,size,size)
input_mask = input!=0 #屏蔽掉填充词(填充符的标号为0)
input_mask = input_mask.unsqueeze(1) # (batch_size, 1, max_len)
input_mask = input_mask & subsequent_mask(input.size(-1)).type_as(input_mask.data) #统一成int形式再进行与操作,shape:(batch_size, max_len, max_len)
return input_mask
#(batch_size, 1, max_len, max_len)
#emb
class Embeddings(nn.Module):
"""
实现词嵌入并添加它们的位置编码
"""
def __init__(self, vocab_size, emb_dim, max_pos):
super(Embeddings, self).__init__()
self.embed = nn.Embedding(vocab_size, emb_dim) #文字标号转emb词向量
self.pos_emb = nn.Embedding(max_pos, emb_dim) #位置编码
def forward(self, encoded_words):
#输入shape:[batch_size, max_len]
max_len = encoded_words.size(1)
pos = torch.arange(max_len, dtype=torch.long,device=device)
pos = pos.unsqueeze(0).expand_as(encoded_words) # [max_len] -> [batch_size, max_len] —— 0为填充符
embedding = self.embed(encoded_words) + self.pos_emb(pos)
return embedding #[batch_size, max_len, emb_dim]
#多头注意力机制
class MultiHeadAttention(nn.Module):
def __init__(self, heads, emb_dim, d_k, d_v):
super(MultiHeadAttention, self).__init__()
self.d_k = d_k
self.d_v = d_v
self.heads = heads
self.dropout = nn.Dropout(0.1)
self.query = nn.Linear(emb_dim, d_k*heads)
self.key = nn.Linear(emb_dim, d_k*heads)
self.value = nn.Linear(emb_dim, d_v*heads)
self.concat = nn.Linear(d_v*heads, emb_dim)
def forward(self, query, key, value, mask):
"""
query, key, value of shape: (batch_size, max_len, emb_dim)
mask of shape: (batch_size, max_len, max_len)
"""
query = self.query(query) #(batch_size, max_len, d_k*heads)
key = self.key(key) #(batch_size, max_len, d_k*heads)
value = self.value(value) #(batch_size, max_len, d_v*heads)
query = query.view(query.shape[0], -1, self.heads, self.d_k).permute(0, 2, 1, 3) #(batch_size, h, max_len, d_k)
key = key.view(key.shape[0], -1, self.heads, self.d_k).permute(0, 2, 1, 3) #(batch_size, h, max_len, d_k)
value = value.view(value.shape[0], -1, self.heads, self.d_v).permute(0, 2, 1, 3) #(batch_size, h, max_len, d_v)
# (batch_size, h, max_len, d_k) matmul (batch_size, h, d_k, max_len) --> (batch_size, h, max_len, max_len)
scores = torch.matmul(query, key.permute(0,1,3,2)) / math.sqrt(self.d_k)
mask = mask.unsqueeze(1).repeat(1, self.heads, 1,
1) # attn_mask : [batch_size, n_heads, max_len, max_len]
scores = scores.masked_fill(mask == 0, -1e9) # (batch_size, h, max_len, max_len) masked_fill()函数主要用在transformer的attention机制中,在时序任务中,主要是用来mask掉当前时刻后面时刻的序列信息(即不为0的用-1e9替换)
weights = F.softmax(scores, dim = -1) # (batch_size, h, max_len, max_len) 那么前面被mask掉的(即-1e9的概率就会很小很小,几乎为0,实现了屏蔽的效果)
#weights = self.dropout(weights)
# (batch_size, h, max_len, max_len) matmul (batch_size, h, max_len, d_v) --> (batch_size, h, max_len, d_v)
context = torch.matmul(weights, value)
#(batch_size, h, max_len, d_v) --> (batch_size, max_len, h, d_v) --> (batch_size, max_len, h * d_v)
context = context.permute(0,2,1,3).contiguous().view(context.shape[0], -1, self.heads * self.d_v) #torch.contiguous()方法首先拷贝了一份张量在内存中的地址,否则直接view是不会重新创建一个的
#(batch_size, max_len, h * d_v)
interacted = self.concat(context)
return interacted #(batch_size, max_len, emb_dim)
# FeedForward的输入是Multi-Head Attention的输出做了残差连接和Norm之后的数据,然后FeedForward做了两次线性线性变换,为的是更加深入的提取特征。
class FeedForward(nn.Module):
# torch.nn.Linear的输入和输出的维度可以是任意的,默认对最后一维做全连接
def __init__(self, emb_dim, middle_dim = 2048):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(emb_dim, middle_dim)
self.fc2 = nn.Linear(middle_dim, emb_dim)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
out = F.relu(self.fc1(x))
out = self.fc2(self.dropout(out))
return out
class DecoderLayer(nn.Module):
def __init__(self, n_heads, d_model, d_k, d_v):
super(DecoderLayer, self).__init__()
self.layernorm = nn.LayerNorm(d_model)
self.self_multihead = MultiHeadAttention(n_heads, d_model, d_k, d_v)
self.feed_forward = FeedForward(d_model)
def forward(self, dec_inputs, dec_self_attn_mask):
'''
dec_inputs: [batch_size, max_len, emb_dim]
dec_self_attn_mask: [batch_size, max_len, max_len]
'''
# dec_outputs: [batch_size, max_len, emb_dim]
dec_outputs = self.self_multihead(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs = self.layernorm(dec_outputs + dec_inputs)
output = self.layernorm(self.feed_forward(dec_outputs) + dec_outputs)
return output
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, max_pos, n_heads, d_k, d_v, n_layers):
super(Decoder, self).__init__()
self.embed = Embeddings(vocab_size, d_model, max_pos)
self.layers = nn.ModuleList([DecoderLayer(n_heads, d_model, d_k, d_v) for _ in range(n_layers)])
def forward(self, dec_inputs):
'''
dec_inputs: [batch_size, max_len]
'''
dec_outputs = self.embed(dec_inputs) # [batch_size, max_len, d_model]
dec_self_attn_mask = create_masks(dec_inputs) # [batch_size, max_len, max_len] 生成mask矩阵
for layer in self.layers:
# dec_outputs: [batch_size, max_len, d_model]
dec_outputs = layer(dec_outputs, dec_self_attn_mask)
return dec_outputs
class GPT(nn.Module):
def __init__(self, vocab_size, d_model, max_pos, n_heads, d_k, d_v, n_layers):
super(GPT, self).__init__()
self.decoder = Decoder(vocab_size, d_model, max_pos, n_heads, d_k, d_v, n_layers)
self.projection = nn.Linear(d_model,vocab_size)
def forward(self,dec_inputs):
"""
dec_inputs: [batch_size, max_len]
"""
# dec_outpus: [batch_size, max_len, d_model]
dec_outputs = self.decoder(dec_inputs)
# dec_logits: [batch_size, max_len, vocab_size]
dec_logits = self.projection(dec_outputs)
return dec_logits七、训练模型(train.py)
import pickle
import config
import torch
import torch.utils.data
from gpt_model import *
from dataset import data_loader
from utils import AdamWarmup, LossWithLS, get_acc
import numpy as np
from torch.utils.tensorboard import SummaryWriter
summaryWriter = SummaryWriter("logs/log2")
# config
emb_dim = config.emb_dim
max_pos = config.max_pos
heads = config.heads
d_k = config.d_k
d_v = config.d_v
num_layers = config.num_layers
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
epochs = config.epochs
word_map = pickle.load(open(config.word_sequence_dict,"rb")) #词典
print(len(word_map.dict))
if config.load == False: #新的训练
gpt = GPT(vocab_size=len(word_map.dict), d_model=emb_dim, max_pos=max_pos, n_heads= heads, d_k=d_k, d_v=d_v, n_layers=num_layers).to(device)
adam_optimizer = torch.optim.Adam(gpt.parameters(), lr=1e-4, betas=(0.9, 0.98), eps=1e-9) #Adam优化器
#gpt_optimizer = AdamWarmup(model_size = emb_dim, warmup_steps = 4000, optimizer = adam_optimizer) #使用warmup策略
#criterion = LossWithLS(len(word_map.dict), 0.1) #损失函数
epoch_start = 0
else: #加载之前的模型接着训练
checkpoint = torch.load('model.pth.rar')
gpt = checkpoint['gpt']
adam_optimizer = checkpoint['adam_optimizer']
epoch_start = checkpoint['epoch'] + 1
criterion = nn.CrossEntropyLoss(ignore_index=0).to(device)
def train(train_loader, gpt, criterion, epoch):
gpt.train()
sum_loss = 0
count = 0
sum_acc = 0
for i, (question, reply) in enumerate(train_loader):
torch.cuda.empty_cache() #释放缓存空间
samples = question.shape[0]
# Move to device
question = question.to(device)
reply = reply.to(device)
# question的shape(batchsize,max_len),reply是(batchsize,max_len-1)
# Get the gpt outputs
out = gpt(question)
# Compute the loss
loss = criterion(out.view(-1, out.size(-1)), reply.view(-1))
acc = get_acc(out, reply)
# Backprop
#gpt_optimizer.optimizer.zero_grad()
adam_optimizer.zero_grad() #存留梯度清零
loss.backward() #反向传播计算梯度
#gpt_optimizer.step()
adam_optimizer.step() #根据梯度进行参数更新
sum_loss += float(loss.item()) * samples
sum_acc += acc.item() * samples
count += samples
if i % 100 == 0:
print("Epoch [{}][{}/{}]\tLoss: {:.3f}\tAcc: {:.3f}".format(epoch, i, len(train_loader), sum_loss/count,sum_acc/count)) #输出累计情况下平均一个词的loss
return sum_loss/count
print("train...")
loss_max = 10000000000
for epoch in range(epoch_start, epochs):
loss = train(data_loader, gpt, criterion, epoch)
#tensorboard实时监控
summaryWriter.add_scalars('epoch_metric', {'epoch_loss': loss }, epoch)
if loss_max > loss: #选择性保存
print("保存轮数:",epoch)
loss_max = loss
#state = {'epoch': epoch, 'gpt': gpt, 'gpt_optimizer': gpt_optimizer}
state = {'epoch': epoch, 'gpt': gpt, 'adam_optimizer': adam_optimizer}
torch.save(state, 'model.pth.rar') #记下每次最好的结果(为了防止中断程序后,啥都没保存)
if epoch == epochs-1: #保存最后的结果
torch.save(state, 'model_last.pth.rar')八、补充实现(utils.py)
warmup策略的实现效果还不如adam,所以最终我没有使用它(代码就不展示了)
import torch
import torch.nn as nn
import torch.utils.data
def get_acc(out,target): #训练准确率计算
pred = torch.argmax(out,dim = 2)
mask = target!=0 #(batch_size, max_words)————屏蔽掉填充词
result = (pred==target)
return (result*mask).sum()/mask.sum()九、完整代码与结果
完整代码:https://github.com/tt-s-t/Small-chinese-Chatbot-based-on-gpt.git
我现阶段训练epoch过少,模型效果不佳,想提高效果可以增大数据集以及训练轮次epoch,或者后续看看怎么魔改。
初代测试效果如下:
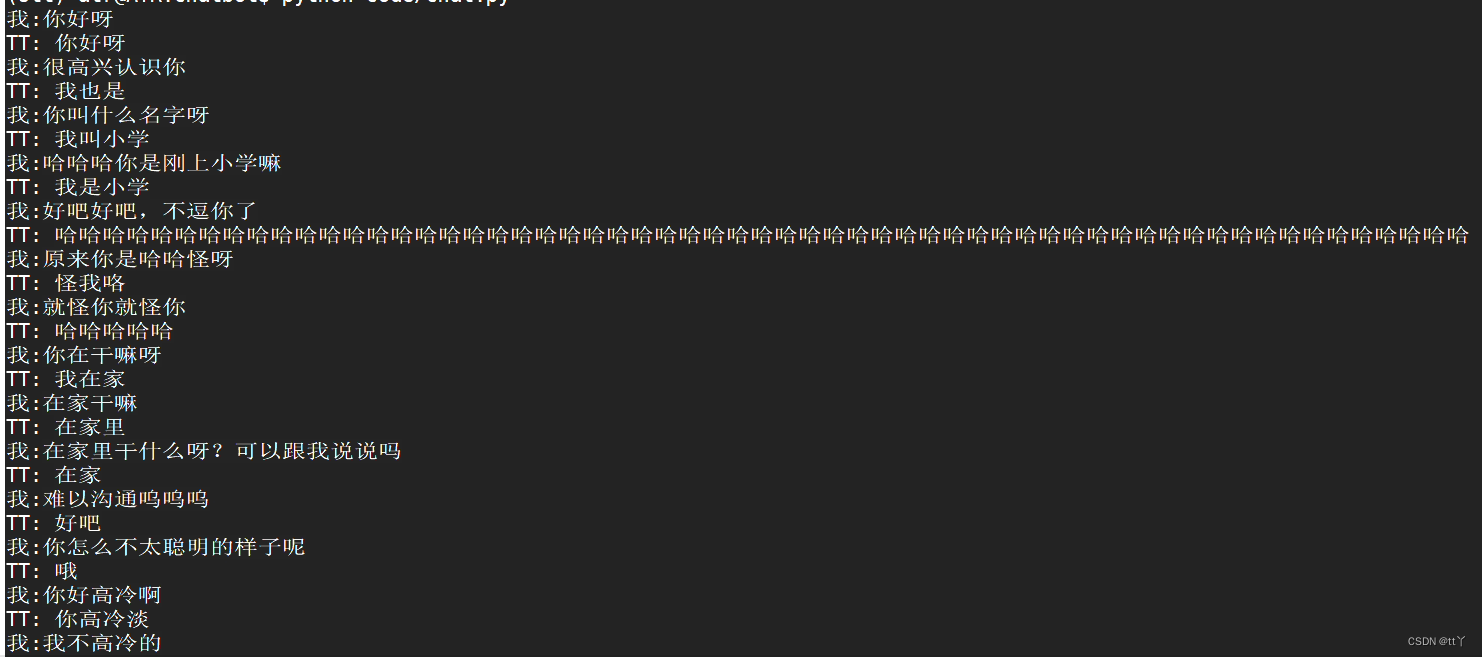
第一版感觉笨笨的哈哈哈
未完待续,欢迎大家在评论区批评指正,谢谢~