目录结构定义
首先来看一下项目整体的结构
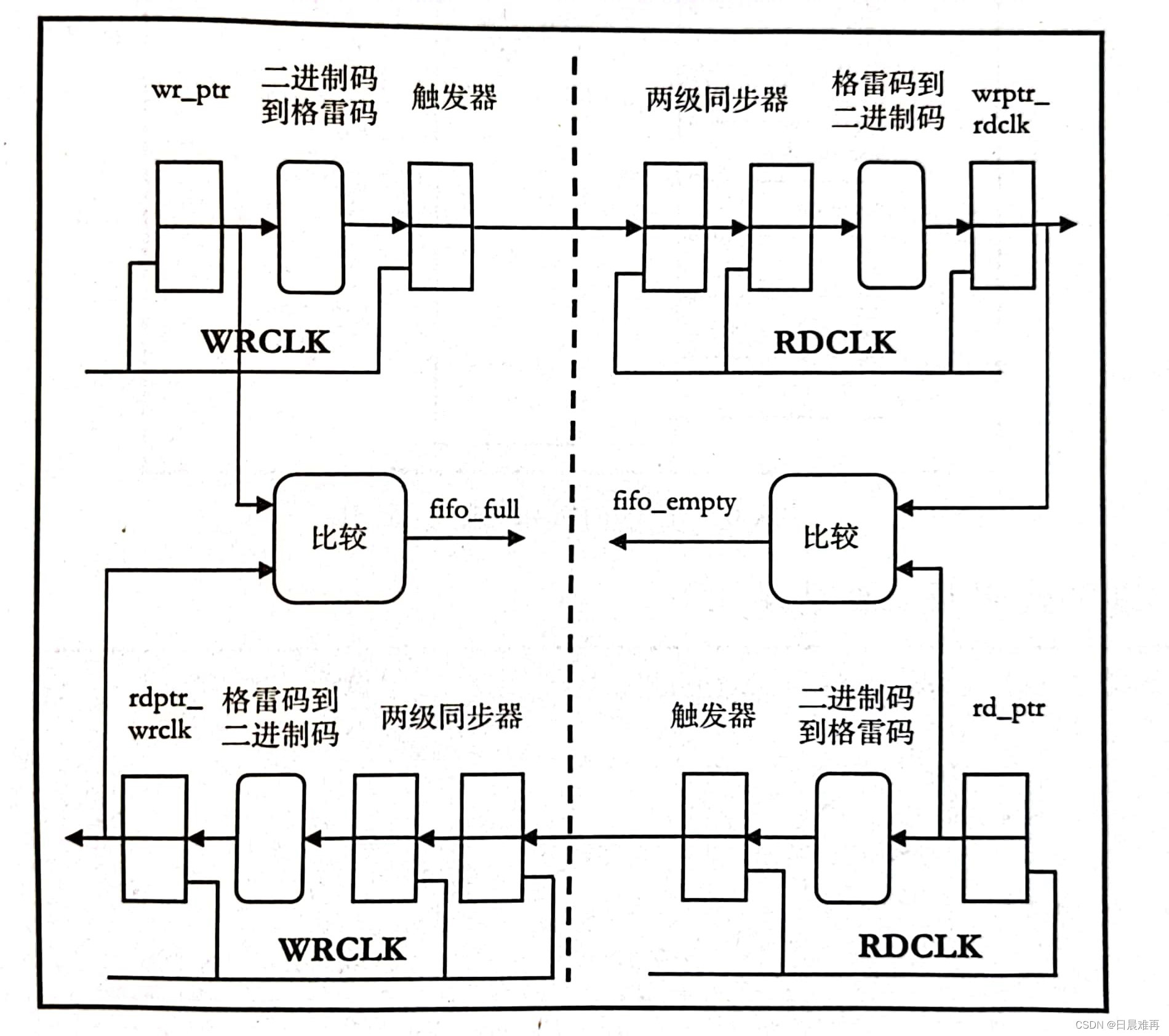
框架结构

代码结构

Excel 文件结构

代码详细解析
1.工具包 tools
封装操作 excel 方法 excel_operation.py
import xlrd
from config.config import PROJECT_PATH
class OperationExcel:
def __init__(self, file_name=None, sheet_id=0):
if file_name:
self.file_name = PROJECT_PATH + '/data/' + file_name
self.sheet_id = sheet_id
else:
try:
self.file_name = PROJECT_PATH + '/data/case.xlsx'
self.sheet_id = 0
except FileExistsError:
raise FileExistsError("the default testcase file not found")
self.book = self.get_book()
self.data = self.get_data()
# 获取工作簿
def get_book(self):
book = xlrd.open_workbook(self.file_name)
return book
# 获取 sheets 的内容
def get_data(self):
book = self.book
tables = book.sheets()[self.sheet_id]
return tables
# 获取所有 sheet 的名字
def get_sheet_name(self):
book = self.book
return book.sheet_names()
# 获取所有 sheets
def get_sheets(self):
book = self.book
sheets = book.sheets()
return sheets
# 获取某个单元格的内容
def get_cell_value(self, row, col):
return self.data.cell_value(row, col)
# 获取单元格的行数
def get_lines(self):
tables = self.data
case_rows = tables.nrows - 1
return case_rows
# 获取某一列的内容
def get_cols_data(self, col_id=None):
if col_id is not None:
cols = self.data.col_values(col_id)
else:
cols = self.data.col_values(0)
return cols
# 获取某一行的内容
def get_rows_data(self, row_id=None):
if row_id is not None:
rows = self.data.row_values(row_id)
else:
rows = self.data.row_values(0)
return rows
# 获取某个 caseid 对应的行号
def get_row_num(self, case_id):
num = 0
cols_data = self.get_cols_data()
for col_data in cols_data:
if case_id in col_data:
return num
num += 1
使用 xlrd 库来操作 excel,同时,该类只做最底层的 excel 数据提取,不做任何业务相关的判断。后面会陆续增加 json,yaml 等数据结构的操作工具。
中间数据操作层 operate_data.py
from config.config import ExcelConfData
class OperateExcelData(object):
def get_caseid(self):
return ExcelConfData.caseid
def get_url(self):
return ExcelConfData.url
def get_method(self):
return ExcelConfData.method
def get_is_auto_run(self):
return ExcelConfData.automated
def get_header(self):
return ExcelConfData.header
def get_data(self):
return ExcelConfData.data
def get_casename(self):
return ExcelConfData.casename
def get_statuscode(self):
return ExcelConfData.statuscode
def get_checkpoints(self):
return ExcelConfData.checkpoints
def get_validate(self):
return ExcelConfData.validate
def get_caseuniqueid(self):
return ExcelConfData.caseuniqueid
def get_authtype(self):
return ExcelConfData.authtype
属于操作数据的中间层,从配置文件中拿到我们定义好的 excel 结构,这样,如果我们的 excel 结构有变化,只需要修改配置文件即可
配置文件中的 excel 结构如下
class ExcelConfData:
caseid = '0'
casename = '1'
caselevel = '2'
preconditions = '3'
testcontent = '4'
expect = '5'
casecategory = '6'
automated = '7' # 1 是自动运行, 2 是非自动运行
caseuniqueid = '1' # 8
method = '9'
url = '10'
data = '11'
header = '12'
statuscode = '13'
checkpoints = '14'
validate = '15'
parameterize = '16'
result = '17'
authtype = '18' # 0:admin, 1:common user, 2:not login
获取测试文件中数据工具 get_data.py
from tools.excel_operation import OperationExcel
from tools.operate_data import OperateExcelData
class GetExcelData(object):
def __init__(self, filename=None, sheet_id=0):
self.operate_excel = OperationExcel(filename, sheet_id)
self.operate_data = OperateExcelData()
# 获取 sheet 个数
def get_sheets(self):
sheet_num = self.operate_excel.get_sheets()
return len(sheet_num)
# 获取 excel 行数,即用例个数
def get_case_lines(self):
return self.operate_excel.get_lines()
# 获取是否执行
def get_is_auto_run(self, row):
auto_flag = False
col = int(self.operate_data.get_is_auto_run())
run_model = self.operate_excel.get_cell_value(row, col)
if run_model == 1:
auto_flag = True
else:
auto_flag = False
return auto_flag
# 获取请求方式
def get_request_method(self, row):
col = int(self.operate_data.get_method())
request_method = self.operate_excel.get_cell_value(row, col)
return request_method
# 获取 url
def get_request_url(self, row):
col = int(self.operate_data.get_url())
url = self.operate_excel.get_cell_value(row, col)
return url
# 获取请求数据
def get_request_data(self, row):
col = int(self.operate_data.get_data())
data = self.operate_excel.get_cell_value(row, col)
return data
# 获取 status code
def get_response_statuscode(self, row):
col = int(self.operate_data.get_statuscode())
statuscode = self.operate_excel.get_cell_value(row, col)
return statuscode
# 获取 checkpoints
def get_checkpoints(self, row):
col = int(self.operate_data.get_checkpoints())
checkpoints = self.operate_excel.get_cell_value(row, col)
return checkpoints
# 获取 validate
def get_validate(self, row):
col = int(self.operate_data.get_validate())
validate = self.operate_excel.get_cell_value(row, col)
return validate
# 获取测试用例唯一 ID
def get_caseuniqueid(self, row):
col = int(self.operate_data.get_caseuniqueid())
caseuniqueid = self.operate_excel.get_cell_value(row, col)
if isinstance(caseuniqueid, float):
caseuniqueid = int(caseuniqueid)
return str(caseuniqueid)
# 获取 header 信息
def get_header(self, row):
col = int(self.operate_data.get_header())
header = self.operate_excel.get_cell_value(row, col)
return header
# 获取是否需要鉴权信息
def get_authtype(self, row):
col = int(self.operate_data.get_authtype())
authtype = self.operate_excel.get_cell_value(row, col)
return authtype
获取到测试数据中业务相关的数据,例如是否自动化执行,是否使用 header,是否需要鉴权信息等。
通用工具文件 common_util.py
import json
import operator
from config.config import UserInfo, EnvConf
import requests
class CommonUtil(object):
def is_contain(self, str1, str2):
"""
:param str1: 原始字符串
:param str2: 被查找的字符串
:return: True or False
"""
flag = None
if str1 in str2:
flag = True
else:
flag = False
return flag
def is_equal_dict(self, d1, d2):
if isinstance(d1, str):
d1 = json.loads(d1)
if isinstance(d2, str):
d2 = json.loads(d2)
return operator.eq(d1, d2)
def adminlogin():
url = f"http://{EnvConf.host}:{EnvConf.port}/api/user-management/tokens"
data = UserInfo.admininfo
resp = requests.post(url=url, json=data)
try:
token = f"Bearer {resp.json()['data']['access_token']}"
except:
raise
return token
def commonlogin():
url = f"http://{EnvConf.host}:{EnvConf.port}/api/user-management/tokens"
data = UserInfo.commoninfo
resp = requests.post(url=url, json=data)
try:
token = f"Bearer {resp.json()['data']['access_token']}"
except:
raise
return token
主要编写一些验证器,或者通用的获取登陆 token 信息等函数。这里的验证器还很简单,后面再慢慢添加,比如正则校验,解析 json 校验等。
2. 基础包 base
封装 http 请求 runmethod.py
import requests
import json
class RunMethod(object):
def __init__(self):
self.verify = False
self.headers = None
def post_main(self, url, data=None, header=None):
res = None
if header is not None:
res = requests.post(url=url, data=data, headers=header)
else:
res = requests.post(url=url, data=data)
return res.json()
def get_main(self, url, data=None, header=None, param=None):
res = None
if header is not None:
res = requests.get(url=url, data=data, headers=header, verify=self.verify, params=param)
else:
res = requests.get(url=url, data=data, verify=self.verify, params=param)
return res.json()
def del_main(self, url, data=None, header=None):
res = None
if header is not None:
res = requests.delete(url=url, data=data, headers=header)
else:
res = requests.delete(url=url, data=data)
return res.json()
def run_main(self, method, url, data=None, header=None):
res = None
if method == 'POST':
res = self.post_main(url, data, header)
elif method == 'GET':
res = self.get_main(url, data, header)
else:
res = self.del_main(url, data, header)
return json.dumps(res, ensure_ascii=False, sort_keys=True, indent=2)
当前的封装还是很简陋的,并没有过多的异常处理,参数校验等,后面会对这方面做一下增强。
runmock.py 是用来做 mock 数据的,以后再用。
提取 excel 数据文件 basetest.py
from tools.get_data import GetExcelData
from base.runmethod import RunMethod
from tools.common_util import CommonUtil
from config.config import EnvConf, Header
import json
from tools.excel_operation import OperationExcel
from tools.common_util import adminlogin, commonlogin
class CaseDataAllSheets:
def __init__(self, filename=None):
self.filename = filename
self.opera_excel = OperationExcel(filename)
self.sheet_nums = self.opera_excel.get_sheets()
def get_all_sheets_data(self):
total_data = {
"sheet-data": [],
'case_data_ids': []
}
for i in range(len(self.sheet_nums)):
data = {}
sheet_name = self.opera_excel.get_sheet_name()[i]
casedata = CaseData(filename=self.filename, sheet_id=i)
test_data, case_data_ids = casedata.get_testcase_data()
data[sheet_name] = test_data
total_data['sheet-data'].append(data)
total_data['case_data_ids'].append(case_data_ids)
return total_data
class CaseData:
def __init__(self, filename=None, sheet_id=0):
self.exceldata = GetExcelData(filename, sheet_id)
self.casenums = self.exceldata.get_case_lines()
def get_testcase_data(self):
test_data = {
'parameterize': []
}
case_data_ids = []
for case in range(1, self.casenums + 1):
if self.exceldata.get_is_auto_run(case):
case_data_json = {
'request-data': {},
'response-data': {}
}
case_method = self.exceldata.get_request_method(case)
data_url = self.exceldata.get_request_url(case)
case_url = f"http://{EnvConf.host}:{EnvConf.port}" + data_url
case_data = self.exceldata.get_request_data(case)
if case_data != '':
try:
case_data = json.loads(case_data)
except:
raise
case_header = self.exceldata.get_header(case)
if case_header == '':
case_header = Header.headers
else:
try:
case_header = json.loads(case_header)
except:
raise
case_statuscode = self.exceldata.get_response_statuscode(case)
case_checkpoint = self.exceldata.get_checkpoints(case)
case_validate = self.exceldata.get_validate(case)
case_uniqueid = self.exceldata.get_caseuniqueid(case)
print(case_uniqueid)
print(type(case_uniqueid))
case_authtype = self.exceldata.get_authtype(case)
if case_authtype == 0:
token = adminlogin()
case_header['authorization'] = token
elif case_authtype == 1:
token = commonlogin()
case_header['authorization'] = token
else:
pass
case_data_json['request-data']['url'] = case_url
case_data_json['request-data']['data'] = case_data
case_data_json['request-data']['header'] = case_header
case_data_json['request-data']['method'] = case_method
case_data_json['response-data']['statuscode'] = case_statuscode
case_data_json['response-data']['checkpoint'] = case_checkpoint
case_data_json['response-data']['validate'] = case_validate
case_data_ids.append(case_uniqueid)
test_data['parameterize'].append(case_data_json)
return test_data, case_data_ids
我把真正的处理 excel 测试用例数据的功能放在了这里,将我们需要的数据,如:url,请求体 data,请求方法 method 等信息组装好,放到内存中,供 pytest 参数化时使用。
3. pytest 测试用例代码
在 case 文件夹中,用来存放真正的 pytest 测试代码,我们写一个简单的测试代码 demo
from base.basetest import BaseTest, CaseData
import pytest
class Test_example(BaseTest):
testcase = CaseData('test.xlsx', 1)
testdata, ids = testcase.get_testcase_data()
@pytest.mark.parametrize('autotest', testdata['parameterize'], ids=ids)
def test_case(self, autotest, casefile):
res_json = self.runmethod.run_main(autotest['request-data']['method'], autotest['request-data']['url'],
data=autotest['request-data']['data'],
header=autotest['request-data']['header'])
print(res_json)
print("casefile", casefile)
assert self.validate.is_equal_dict(res_json, autotest['response-data']['checkpoint']) is True
这里时获取 excel 中的 sheet 序号为1的内容来作为测试数据,如果我们需要把 excel 中所有 sheet 中的数据都作为测试数据来供 pytest 参数化的话,那么就可以实例化 CaseDataAllSheets 类。
4. 测试执行
最后,我们在 main.py 中运行 pytest 主程序
if __name__ == '__main__':
import pytest
pytest.main(['-s', '-q', '-vv', '--html=./report/report.html', '--self-contained-html'])
使用一个 report 插件来自动产生测试报告。
至此,我们以后只需要编写易于操作的 excel,而几乎不需要动任何 Python 代码,就能完成一次接口自动化测试了。当然,编写好的 excel 要放到 data 文件夹下哦!







![[MAUI]写一个跨平台富文本编辑器](https://img-blog.csdnimg.cn/d3174ea5f8094709912c50cdd0038254.gif)