论文阅读:Denoising Diffusion Probabilistic Models
最近一两年,在图像生成领域,扩散模型受到了越来越多的关注,特别是随着 DALL-E2 以及 Midjourney 的持续火爆,扩散模型也变得越来越流行,之前很多基于 GAN 的工作也逐渐被扩散模型所替代。今天介绍扩散模型里面非常重要的一篇文章,就是发表在 NeurIPS 2020 年的 Denoising Diffusion Probabilistic Models,即 DDPM。
在介绍 DDPM 之前,我们先回顾一下生成模型的发展历程。
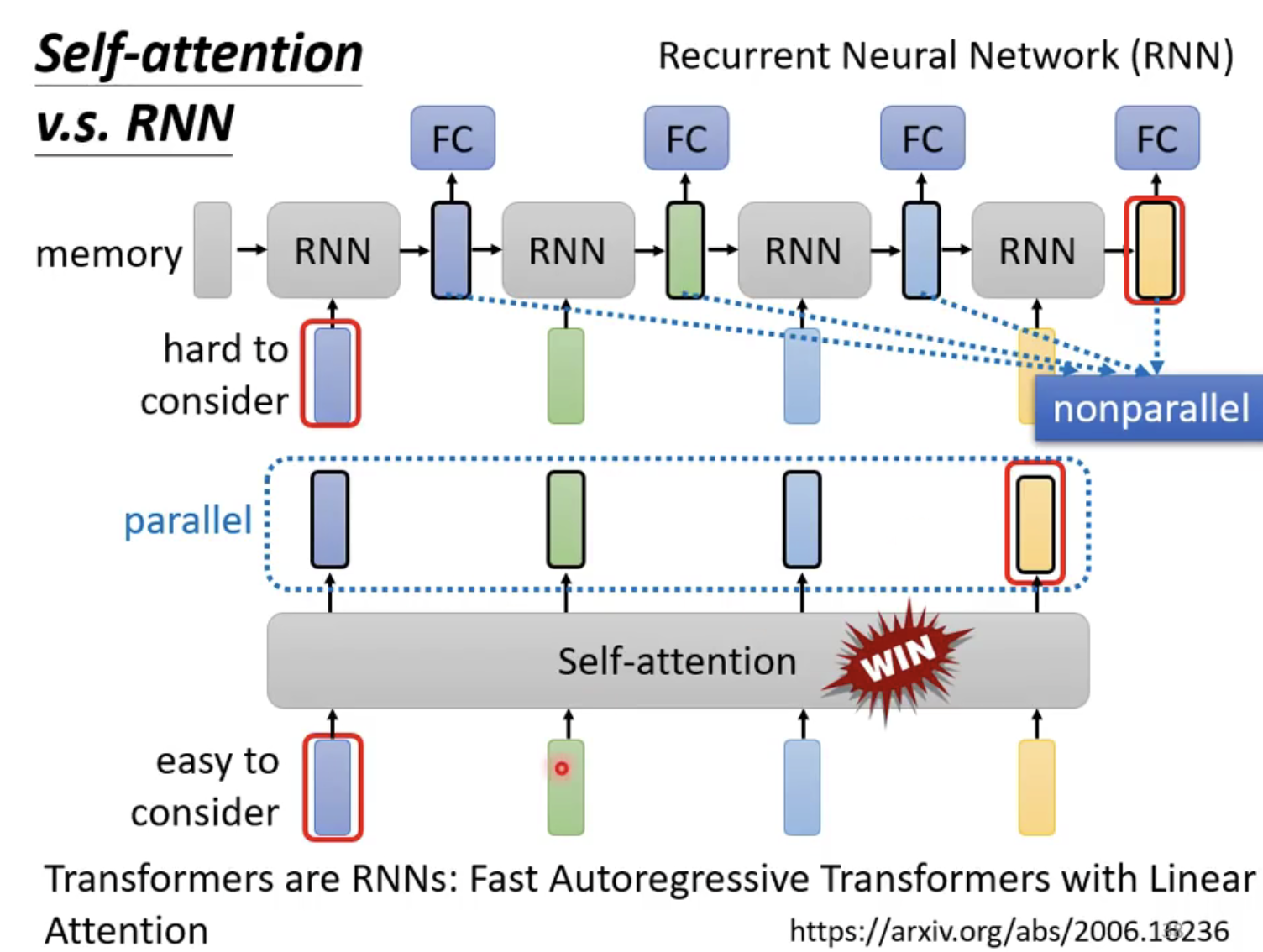
在机器学习中,一般有两大类的模型,一类叫判别式模型,一类叫生成式模型。判别式模型就是给你一个输入,输出一个分类标签,输出一个检测框等等。而生成式模型,一般是学习一个概率分布,从概率分布中预测出数据的真实分布。生成模型在深度学习时代之前,基本也是用于一些分类任务,比如朴素贝叶斯,马尔科夫链等。但是随着深度学习的兴起,生成模型也开始在做 “生成” 任务了,在 DDPM 出现之前,比较主流的有 GAN, VAE, FLOW 等。下面这张图,就很好地展示了这几类生成式模型的基本思想:

- 几种不同生成模型的示意图
首先是 GAN 模型,GAN 模型主要包含两部分,一部分称为判别器,一部分称为生成器,生成器的输入是高斯白噪声,而输出就是生成的图像,而判别器的输入就是一张图像,这张图像可以是生成器生成的图像,也可以是一张拍摄的真实图像,判别器的输出就是对输入图像的判别,如果输入图像是生成器生成的图像,判别器需要判别为 0,如果是拍摄的真实图像,那么判别器会判别为 1,生成器的最终目的就是让自己生成的图像判别器无法分辨出是生成的还是真实的,而判别器的目的就是将生成去生成的图像都能准确地判别出来,这就像是一种博弈,生成器就像是矛,判别器就像是盾,矛和盾不断相互提升,到达某种稳态的时候,生成器生成的图片就和真实拍摄的图片非常类似,可以达到以假乱真的地步。所以现在的 GAN 生成的图片都非常逼真。但是 GAN 也有一些致命的缺陷。首先是训练不太稳定,因为 GAN 本质上是一种博弈,需要最终达到一种微妙的平衡,如果训练不好,就有可能坍塌。
接下来看看 VAE 一系列的模型,最早的是 AE,也就是 Auto-Encoder,AE 的思想很简单,就是将一个高维的向量通过一个编码器压缩到一个低维的向量空间,然后再通过一个解码器重新映射回高维空间,所以 AE 解码器的输出就像编码器的输入,训练也比较简单直观。在 AE 之后,出现了 DAE,也就是 Denoising Autoencoder,DAE 与 AE 的流程也非常类似,唯一的区别在于编码器的输入,AE 的编码器的输入是原始的高维向量,而 DAE 的编码器的输入是对原始高维向量加入噪声扰动之后的高维向量,DAE 就是希望把加了噪声的高维向量恢复成原始的高维向量,这个过程有点像是对高维向量去噪,所以就叫 Denoising Autoencoder。不过 AE 和 DAE 中间的低维向量本质上是一种低维特征,并不是一个概率分布,所以为了能将中间的低维向量空间用一个概率分布区拟合,所以就有了 VAE,即 Variational Autoencoder,VAE 和之前的 AE, DAE 之间的区别就是 VAE 不再是学习低维特征本身,而是学习低维特征空间的一个概率分布,VAE 是用一个高斯分布来表征这个概率分布,而高斯分布本身可以用均值和方差来表征,所以 VAE 就是在学习低维特征空间概率分布的均值,方差,有了这个概率分布之后,可以通过对概率分布采样,再将采样得到的样本通过解码器,最后得到生成的高维向量。再往后,就是 VQ-VAE,Vector Quantised-Variational AutoEncoder,VQ-VAE 和 VAE 的区别在于,VAE 是学习一个低维空间的概率分布,而 VQ-VAE 将这个低维空间的概率分布用一个 codebook 做了替换,VQ-VAE 不再去学低维空间的概率分布,而是学习输入到 codebook 的映射,输入的图像通过一个编码器得到一个特征向量,特征向量与 codebook 里的预置向量进行匹配,寻找与输入特征向量最接近的一个预置向量,然后将这个预置向量送入后面的解码器,从而解码得到一个高维向量。不过 VQ-VAE 的问题在于它的特征隐空间被限制在了一个 codebook 里面了,无法再从一个概率分布中进行采样,为了改进这个,后面又出来了一个 VQ-VAE2,VQ-VAE2 就是在 VQ-VAE 的基础上进行了改进,训练了一个 prior 网络,prior 网络就是对 codebook 的一个建模,将固定的 codebook 换成了一个 prior 网络,这样就可以利用 prior 网络来实现采样。
而流模型也是一种生成模型,Flow 模型通过一系列可逆的变换去拟合真实的数据分布,虽然数学形式上更加优美,但是最后也没有火起来。
然后,就是最近一两年大火的 diffusion model,也就是扩散模型,在生成领域,风头已经盖过了之前的 GAN,VQ-VAE,俨然成为了新时代生成领域的霸主。

扩散模型的整个过程看起来非常简洁,给定一张图像,每次在图像上叠加很小的噪声,随着这个过程的进行,到一定次数的时候,原始的图像可能就完全被噪声所淹没了,假设 x 0 \mathbf{x}_0 x0 是从原始图像分布中抽取的一个初始样本,然后每次叠加少量的噪声,生成一系列的带噪图像, x 1 , x 2 , . . . , x T \mathbf{x}_1, \mathbf{x}_2, ..., \mathbf{x}_T x1,x2,...,xT,整个前向的扩散过程可以表示成如下的式子:
q ( x t ∣ x t − 1 ) = N ( x t , 1 − β t x t − 1 , β t I ) q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t, \sqrt{1 - \beta_{t}}\mathbf{x}_{t-1}, \beta_{t}\mathbf{I}) \quad q(\mathbf{x}_{1:T} | \mathbf{x}_{0}) = \prod_{t=1}^{T} q(\mathbf{x}_t | \mathbf{x}_{t-1}) q(xt∣xt−1)=N(xt,1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
可以看到,整个序列,当前的状态 x t \mathbf{x}_t xt 只和前一次的状态 x t − 1 \mathbf{x}_{t-1} xt−1 有关,遵循马尔科夫随机过程,因为叠加的噪声是高斯噪声,而高斯分布的和依然是高斯分布,可以利用重参数化的技巧,将所有的中间状态 x t \mathbf{x}_t xt 与初始状态建立联系:
假设 α t = 1 − β t \alpha_{t} = 1 - \beta_{t} αt=1−βt, α t ˉ = ∏ i = 1 t α i \bar{\alpha_t} = \prod_{i=1}^{t} \alpha_{i} αtˉ=∏i=1tαi

- 重参数化过程
前向的扩散过程,是一个逐渐加噪的过程,图像逐渐变成高斯噪声,那么反过来看,就是噪声逐渐变成图像的过程,这个过程也被称为逆扩散过程,如果能得到逆扩散过程的分布,那么给定一个随机噪声,就能通过逆扩散过程得到最终的图像。但是逆扩散过程的分布很难直接获得,所以扩散模型最终是通过学习一个模型来近似这个逆扩散过程,
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_{\theta}(\mathbf{x}_{0:T}) = p(\mathbf{x}_T) \prod_{t=1}^{T} p_{\theta}(\mathbf{x}_{t-1} | \mathbf{x}_{t}) \quad p_{\theta}(\mathbf{x}_{t-1} | \mathbf{x}_{t}) = \mathcal{N}(\mathbf{x}_{t-1}; \mu_{\theta}(\mathbf{x}_t, t), \Sigma_{\theta}(\mathbf{x}_t, t)) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
通过一堆眼花缭乱的推导(此处略去xx字),最终可以得到:
μ θ ( x t , t ) = 1 α t ( x t − 1 − α t 1 − α t ˉ ϵ θ ( x t , t ) ) \mu_{\theta}(\mathbf{x}_t, t) = \frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}}\epsilon_{\theta}(\mathbf{x}_t, t )) μθ(xt,t)=αt1(xt−1−αtˉ1−αtϵθ(xt,t))
x t − 1 = N ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α t ˉ ϵ θ ( x t , t ) ) , Σ θ ( x t , t ) ) \mathbf{x}_{t-1} = \mathcal{N}(\mathbf{x}_{t-1}; \frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}}\epsilon_{\theta}(\mathbf{x}_t, t )), \Sigma_{\theta}(\mathbf{x}_t, t)) xt−1=N(xt−1;αt1(xt−1−αtˉ1−αtϵθ(xt,t)),Σθ(xt,t))
而最终的扩散过程和逆扩散过程可以表示成如下是形式:

-
扩散与采样过程的程序
-
参考:
https://www.bilibili.com/video/BV17r4y1u77B/?spm_id_from=333.788&vd_source=bb80399e033aacf33a21a9f9864c6086
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/