一 闭包
- 闭包:通过封装一个函数, 该函数内部又封装一个函数用于返回,使得得到一个无法直接修改值的临时变量,只能通过函数调用修改。
- 闭包的作用:代替全局变量,避免全局变量的滥用。
- 闭包的优缺点:1)优点是可以避免全局变量;2)缺点是该临时变量会一直占用内存。 但是内存都非常大,所以缺点往往可以忽略它。
例如,下图是使用全局变量,当别人导入该包,是可以得到该全局变量account_amount,然后进行修改,那么这样你的金额就有风险了。
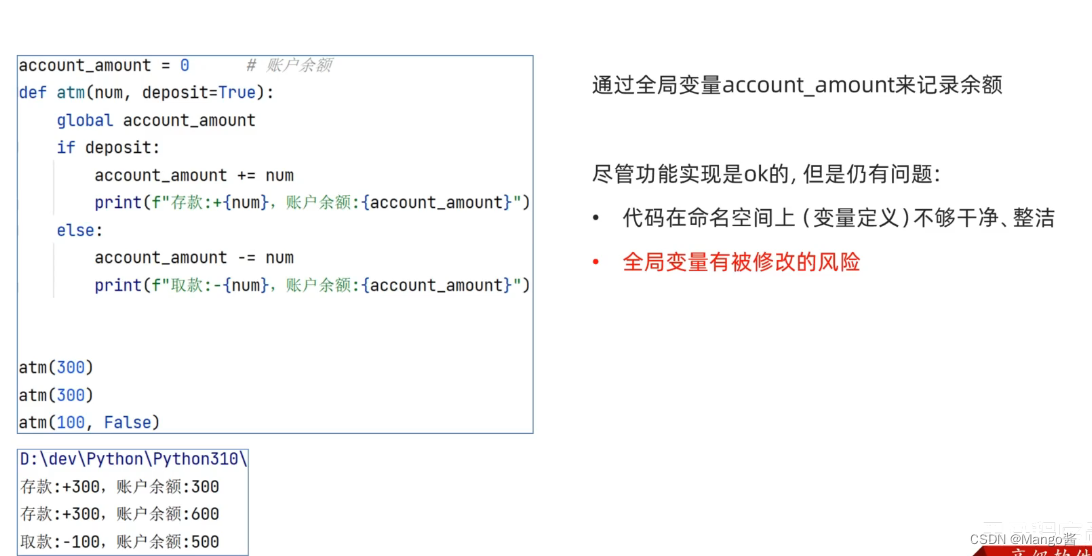
使用闭包代替。
在讲闭包之前,首先先讲nonlocal的作用。nonlocal的作用是,要想在内部函数修改外部函数的变量值,需要在内部函数中使用nonlocal声明该变量,才能使用。

# 使用nonlocal关键字修改外部函数的值
def outer(num1):
def inner(num2):
# nonlocal num1
num1 += num2
print(num1)
return inner
fn = outer(10)
fn(10)
例如,当我们注释掉nonlocal关键字,会报错:

上面了解nonlocal后,我们使用闭包实现ATM小案例。
# 使用闭包实现ATM小案例
def account_create(initial_amount=0):
def atm(num, deposit=True):
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:+{num}, 账户余额:{initial_amount}")
else:
initial_amount -= num
print(f"取款:-{num}, 账户余额:{initial_amount}")
return atm
# 调用account_create后,相当于得到一个全局变量initial_amount
atm = account_create()
# 往后调用atm函数,就是对initial_amount形参的操作。
atm(100)
atm(200)
atm(100, deposit=False)
结果:

上面看到,不管别人如何导包,都无法得到变量initial_amount,因为此时它是一个形参,要想修改initial_amount的值,只能通过调用返回的函数。
二 装饰器

最简单的实现就是:
print("我睡觉了")
time.sleep(random.randint(1, 5))
print("我起床了")
但是,这种太low了,我们可以使用装饰器进行实现。
# 装饰器的一般写法(闭包)
def outer(func):
def inner():
print("我睡觉了")
func()
print("我起床了")
return inner
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1, 5))
fn = outer(sleep)
fn()
结果:

上图看到,我们将sleep传给形参,这样就相当于一个全局变量,即通过闭包实现了装饰器。
下面我们来升级一下装饰器的写法,叫做装饰器的语法糖写法。

# 装饰器的快捷写法(语法糖)
def outer(func):
def inner():
print("我睡觉了")
func()
print("我起床了")
return inner
@outer
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1, 5))
sleep()
结果是一样的。

上面看到,使用装饰器的语法糖写法,通过在sleep前声明@outer关键字,当我们调用sleep()时,相当于将sleep()函数作为参数传给了outer()函数,然后调用outer函数。
三 单例模式


单例模式实现:
str_tools_py.py:
class StrTools:
pass
str_tool = StrTools()
test.py:
from str_tools_py import str_tool
s1 = str_tool
s2 = str_tool
print(id(s1))
print(id(s2))

四 工厂模式


"""
演示设计模式之工厂模式
"""
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class PersonFactory:
def get_person(self, p_type):
if p_type == 'w':
return Worker()
elif p_type == 's':
return Student()
else:
return Teacher()
pf = PersonFactory()
worker = pf.get_person('w')
stu = pf.get_person('s')
teacher = pf.get_person('t')
五 多线程并行执行概念



六 多线程编程

"""
演示多线程编程的使用
"""
import time
import threading
def sing(msg):
while True:
print(msg)
#time.sleep(1)
def dance(msg):
while True:
print(msg)
#time.sleep(1)
if __name__ == '__main__':
# 创建一个唱歌的线程
sing_thread = threading.Thread(target=sing, args=("我要唱歌 哈哈哈", ))
# 创建一个跳舞的线程
dance_thread = threading.Thread(target=dance, kwargs={"msg": "我在跳舞哦 啦啦啦"})
# 让线程去干活吧
sing_thread.start()
dance_thread.start()
# # 等待线程结束并回收
# sing_thread.join()
# dance_thread.join()
#
# # 测试主线程是否退出
# print("main结束")
结果,就是两个线程一直在打印,这个打印顺序是无序的,看CPU的调用顺序决定,CPU先调用谁,那么就哪个线程执行。

七 Socket服务端开发

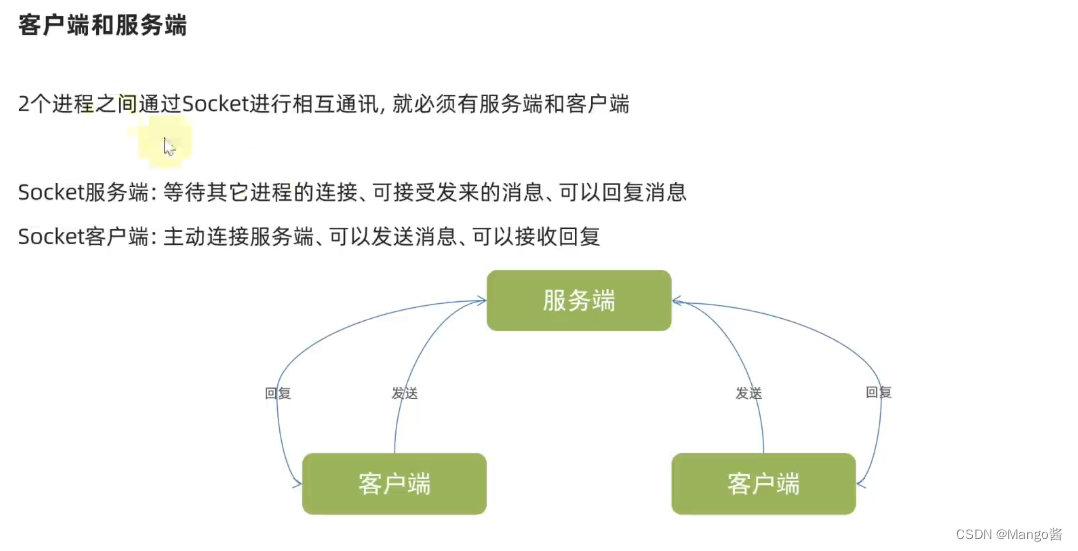
服务端编程步骤:


"""
演示Socket服务端开发
"""
import socket
# 1 创建Socket对象
socket_server = socket.socket()
# 2 绑定ip地址和端口
socket_server.bind(("localhost", 8888))
# 3 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受的客户端链接数量
print(f"等待客户端连接,服务器端口是:8888")
# 4 等待客户端链接。
# 这里没有客户端连接时会阻塞
# result: tuple = socket_server.accept()
# conn = result[0] # 客户端和服务端的链接对象
# address = result[1] # 客户端的地址信息
conn, address = socket_server.accept()
# accept方法返回的是二元元组(链接对象, 客户端地址信息)
# 可以通过 变量1, 变量2 = socket_server.accept()的形式,直接接受二元元组内的两个元素
# accept()方法,是阻塞的方法,等待客户端的链接,如果没有链接,就卡在这一行不向下执行了
print(f"接收到了客户端的链接,客户端的信息是:{address}")
while True:
# 5 接受客户端信息,要使用客户端和服务端的本次链接对象,而非socket_server对象
# recv客户端没有接收到数据也会阻塞,这里只演示1个客户端的例子.
data: str = conn.recv(1024).decode("UTF-8")
# recv接受的参数是缓冲区大小,一般给1024即可
# recv方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象
print(f"客户端发来的消息是:{data}")
# 6 发送回复消息
msg = input("请输入你要和客户端回复的消息:")
if msg == 'exit':
break
conn.send(msg.encode("UTF-8"))
# 7 关闭链接
conn.close()
socket_server.close()
下载网络调试助手作为客户端:
https://github.com/nicedayzhu/netAssist/releases。

八 Socket客户端开发


那么我们在pycharm启动上面服务端和客户端的代码,注意在pycharm是可以同时运行的。
客户端打印:
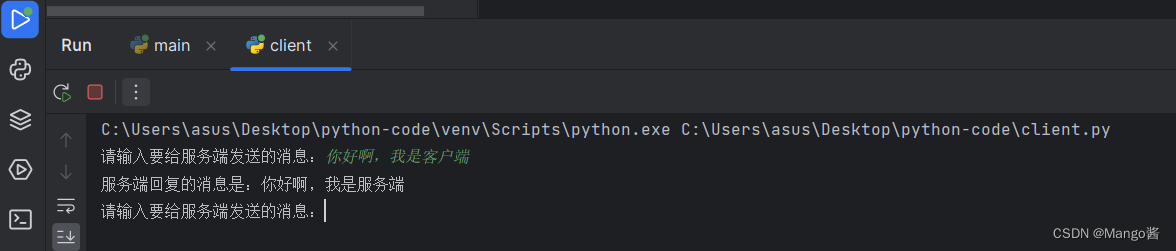
服务端打印:
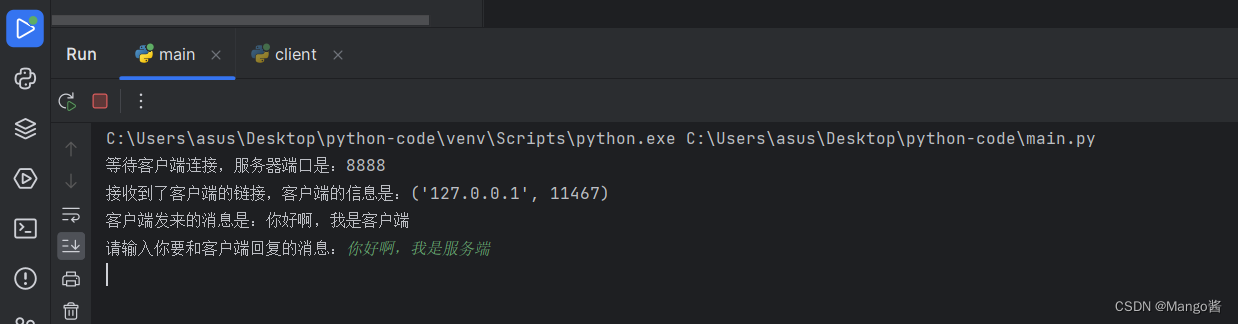
九 正则表达式-基础方法

match():

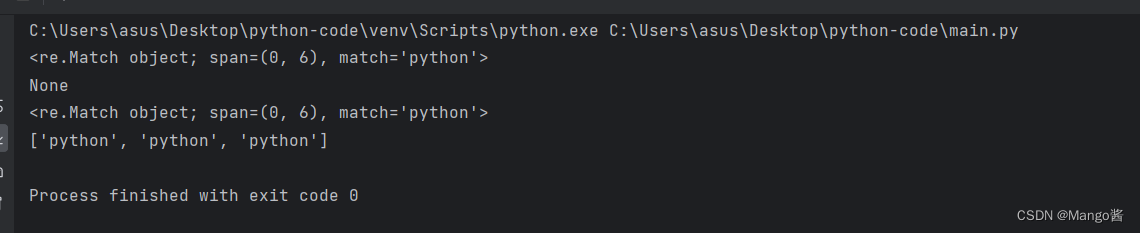
这里注意,match()要求开头就要匹配,如果开头都不匹配,那么直接返回None,例如上图的s='1python xxx’与’python’比较,因为开头就不匹配了。所以直接返回None。
search():
搜索整个字符串,返回找到匹配的第一个字符串。类似C++的string.find()。

findall():搜索整个字符串,返回找出的全部匹配项。

"""
演示Python正则表达式re模块的3个基础匹配方法
"""
import re
s1 = "python itheima python python"
s2 = "1python itheima python python"
# 1 match 从头匹配
result = re.match("python", s1)
print(result)
# print(result.span())
# print(result.group())
result = re.match("python", s2)
print(result)
# 2 search 搜索匹配
result = re.search("python", s1)
print(result)
# 3 findall 搜索全部匹配
result = re.findall("python", s1)
print(result)
十 正则表达式-元字符匹配



案例。

"""
演示Python正则表达式使用元字符进行匹配
"""
import re
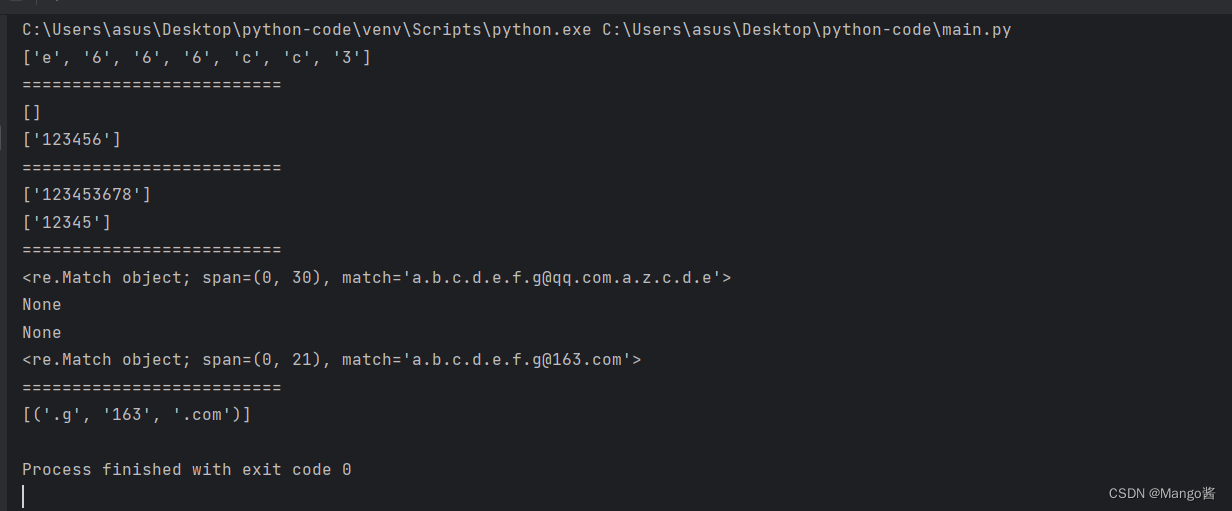
# 1. 查找小写b到e,大写F-Z,数字3-9的所有字符
s1 = "itheima1 @@python2 !!666 ##itccast3"
result = re.findall(r'[b-eF-Z3-9]', s1) # 字符串前面带上r的标记,表示字符串中转义字符无效,就是普通字符的意思
print(result)
print("==========================")
# 2 匹配账号,只能由字母和数字组成,长度限制6到10位
# ^[0-9a-zA-Z]:表示开头第一个字符只能是数字和字母
# {6,10}:表示上一个规则出现6-10次。
# $:表示我要结尾,后面不能有内容
r = '^[0-9a-zA-Z]{6,10}$'
s2 = '123456_'
s21 = '123456'
print(re.findall(r, s2))
print(re.findall(r, s21))
print("==========================")
# 3 匹配QQ号,要求纯数字,长度5-11,第一位不为0
# ^[1-9]:表示第一个字符是1-9的数字。
# [0-9]:表示第二个字符串是0-9的数字
# {4,10}:表示前一个规则的字符出现4-10次。注意,本规则是修饰上一个规则,
# 这个4包含上一个规则([0-9]),所以是{4,10},而不是{3,10}。上面的{6,10}同理
r = '^[1-9][0-9]{4,10}$'
s3 = '123453678'
s31 = '12345'
print(re.findall(r, s3))
print(re.findall(r, s31))
print("==========================")
# 4 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
# abc.efg.daw@qq.com.cn.eu.qq.aa.cc
# abc@qq.com
# 我们假设邮箱地址是xxx.xxx.xxx@xxx.xxx的形式,反正内容可以出现很多次,例如:
# {内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}@{内容}.{内容}.{内容}
# 1)^[\w-]:表示开头只能是单词字符,然后-表示也可以出现它,即表示第一个字符可以出现 单词字符 和 -。
# 2)+:表示前一个规则可以出现1到无数次。
# 3)(\.[\w-]+):外层括号表示这个括号内是一整个规则; \.表示点,\只是转义; [\w-]+表示单词字符和-可以出现1到无数次,即代表内容。
# 所以这里意思就是:第一个字符是., 然后后面的内容是单词字符可以出现1到无数次。
# 注意(个人理解),这里的+应该只修饰[\w-],而不是修饰\.[\w-],即不带上点(.),因为[\w-]只代表一个字符,
# 如果带上点的话,那么(\.[\w-]+)就表示:.内容.内容.内容... 一直这样,而内容[\w-]只代表一个字符,
# 例如:.a.b.c 所以这是不合理的。
# 4)*:表示上一个规则可以出现0-无数次,即.内容可以是0-无数次。
# 5)@(qq|163|gmail):匹配 @ 加上qq、163、gmail其中的一种。
# 6)(\.[\w-]+):和第3)点一样。
# 7)+:表示前一个规则可以出现1到无数次。
# 8)$:表示结尾。
# 9)注意,我们看到,最外层加上了大括号,r'(xxx)',这是因为如果不加,findall会把结果安装每个小规则分成多个元素返回
r = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
s4 = 'a.b.c.d.e.f.g@qq.com.a.z.c.d.e'
s41 = 'a.b.c.d.e.f.g@126.com.a.z.c.d.e'
s42 = 'a.b.c.d.e.f.g@163'
s43 = 'a.b.c.d.e.f.g@163.com'
print(re.match(r, s4))
print(re.match(r, s41))
print(re.match(r, s42))
print(re.match(r, s43))
print("==========================")
# 9)注意,我们看到,最外层加上了大括号,r'(xxx)',这是因为如果不加,findall会把结果安装每个小规则分成多个元素返回
r44 = r'^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$'
s44 = 'a.b.c.d.e.f.g@163.com'
print(re.findall(r44, s44))
结果:
十一 递归

先讲几个与文件目录相关的接口:
def test_os():
"""演示os模块的3个基础方法"""
print(os.listdir("D:/test")) # 列出路径下的内容
# print(os.path.isdir("D:/test/a")) # 判断指定路径是不是文件夹
# print(os.path.exists("D:/test")) # 判断指定路径是否存在
我们以递归找文件为例,下面是文件目录结构:

"""
演示Python递归操作
需求:通过递归,找出一个指定文件夹内的全部文件
思路:写一个函数,列出文件夹内的全部内容,如果是文件就收集到list
如果是文件夹,就递归调用自己,再次判断。
"""
import os
def test_os():
"""演示os模块的3个基础方法"""
print(os.listdir("C:/Users/asus/Desktop/python-code/递归")) # 列出路径下的内容
# print(os.path.isdir(C:/Users/asus/Desktop/python-code/递归")) # 判断指定路径是不是文件夹
# print(os.path.exists(C:/Users/asus/Desktop/python-code/递归")) # 判断指定路径是否存在
def get_files_recursion_from_dir(path):
"""
从指定的文件夹中使用递归的方式,获取全部的文件列表
:param path: 被判断的文件夹
:return: list,包含全部的文件,如果目录不存在或者无文件就返回一个空list
"""
print(f"当前判断的文件夹是:{path}")
file_list = []
if os.path.exists(path):
for f in os.listdir(path):
new_path = path + "/" + f
if os.path.isdir(new_path):
# 进入到这里,表明这个目录是文件夹不是文件
file_list += get_files_recursion_from_dir(new_path)
else:
file_list.append(new_path)
else:
print(f"指定的目录{path},不存在")
return []
return file_list
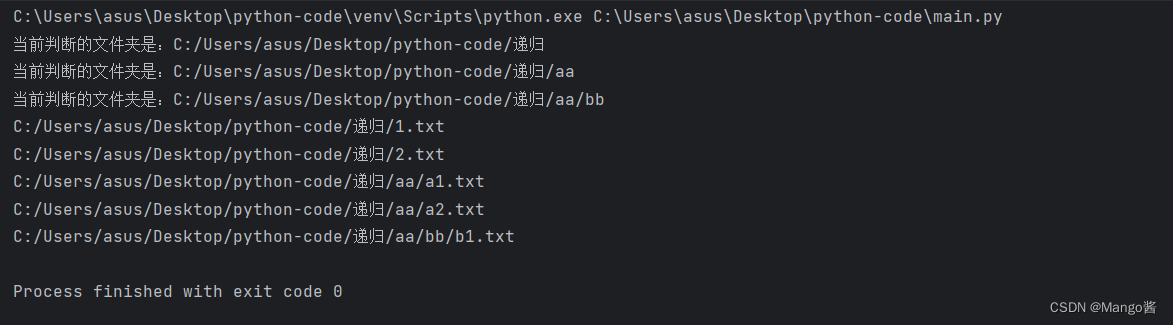
if __name__ == '__main__':
file_lists = get_files_recursion_from_dir("C:/Users/asus/Desktop/python-code/递归")
for f in file_lists:
print(f)