目录
零、前置知识
一、什么是进程间通信
(一)含义
(二)发展
(三)类型
1.管道
2.System V IPC
3.POSIX IPC
二、为什么要有进程间通信
三、怎么进行进程间通信
(一)什么是管道
(二)匿名管道
1.匿名管道的原理
2.匿名管道的创建:pipe函数
3.匿名管道使用步骤
4.匿名管道读写规则
(二)管道特点
1.管道内部自带同步与互斥机制。
2.管道的生命周期随进程。
3.管道提供的是流式服务。
4.管道是半双工通信的。
(三)管道的四种特殊情况
(四)匿名管道特征总结:
四、命名管道(FIFO)
(一)命名管道原理
(二)创建命名管道
1.命名管道可以从命令行上创建
2.命名管道也可以从程序里创建
(二)命名管道的打开规则
1.如果当前打开操作是为读而打开FIFO时。
2.如果当前打开操作是为写而打开FIFO时。
(三)用命名管道实现serve&client通信
1.共用头文件
2.服务端
3.客户端
(四)命名管道和匿名管道的区别
(五)总结
零、前置知识
- 因为进程具有独立性,如果两个或者多个进程需要相互通信,就必须要看到同一份资源:就是一段内存!这个内存可能以文件的方式提供,也可能以队列的方式,也可能提供的就是原始的内存块!
- 这个公共资源应该属于谁?这个公共资源肯定不属于任何进程,如果这个资源属于进程,这个资源就不应该再让其它进程看到,要不然进程的独立性怎么保证呢?所以这个资源只能属于操作系统!
- 进程间通信的前提:是有OS参与,提供一份所有通信进程能看到的公共资源!
一、什么是进程间通信
(一)含义
进程间通信(IPC,InterProcess Communication)是指在不同进程之间传播或交换信息。IPC的方式通常有管道(包括匿名管道和命名管道)、消息队列、信号量、共享内存等。
进程间通信的本质就是,让不同的进程看到同一份资源。
由于各个运行进程之间具有独立性,这个独立性主要体现在数据层面,而代码逻辑层面可以私有也可以公有(例如父子进程),因此各个进程之间要实现通信是非常困难的。
各个进程之间若想实现通信,一定要借助第三方资源,这些进程就可以通过向这个第三方资源写入或是读取数据,进而实现进程之间的通信,这个第三方资源实际上就是操作系统提供的一段内存区域。
因此,进程间通信的本质就是,让不同的进程看到同一份资源(内存,文件内核缓冲等)。 由于这份资源可以由操作系统中的不同模块提供,因此出现了不同的进程间通信方式。

(二)发展
- 管道
- System V进程间通信
- POSIX进程间通信
(三)类型
典型进程间通信方式: 管道,共享内存,消息队列,信号量,网络通信,文件 等多种方式!
1.管道
- 匿名管道pipe
- 命名管道
2.System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
3.POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
二、为什么要有进程间通信
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
三、怎么进行进程间通信
(一)什么是管道
- 管道是Unix中最古老的进程间通信的形式。
- 我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
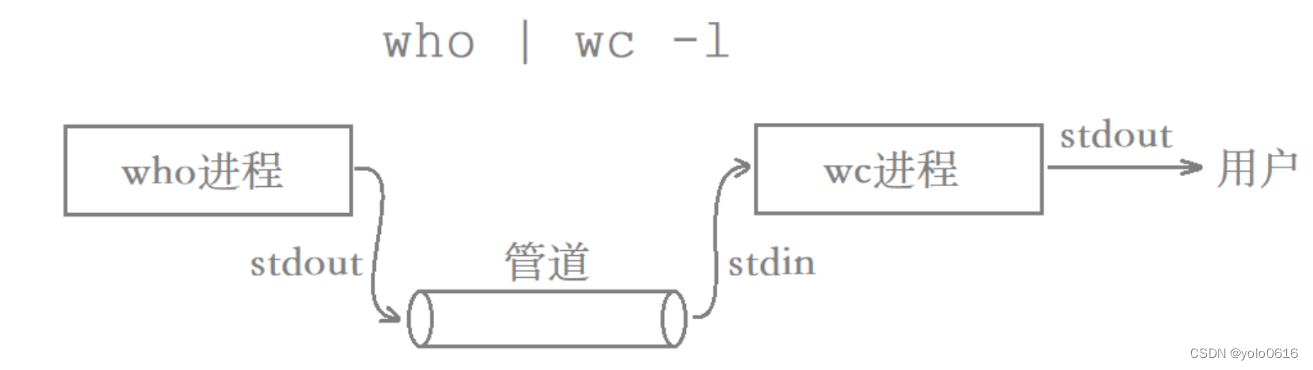
例如,统计我们当前使用云服务器上的登录用户个数。
其中,who命令和wc命令都是两个程序,当它们运行起来后就变成了两个进程,who进程通过标准输出将数据打到“管道”当中,wc进程再通过标准输入从“管道”当中读取数据,至此便完成了数据的传输,进而完成数据的进一步加工处理。

注明: who命令用于查看当前云服务器的登录用户(一行显示一个用户),wc -l用于统计当前的行数。
(二)匿名管道
1.匿名管道的原理
匿名管道用于进程间通信,且仅限于本地父子进程之间的通信。
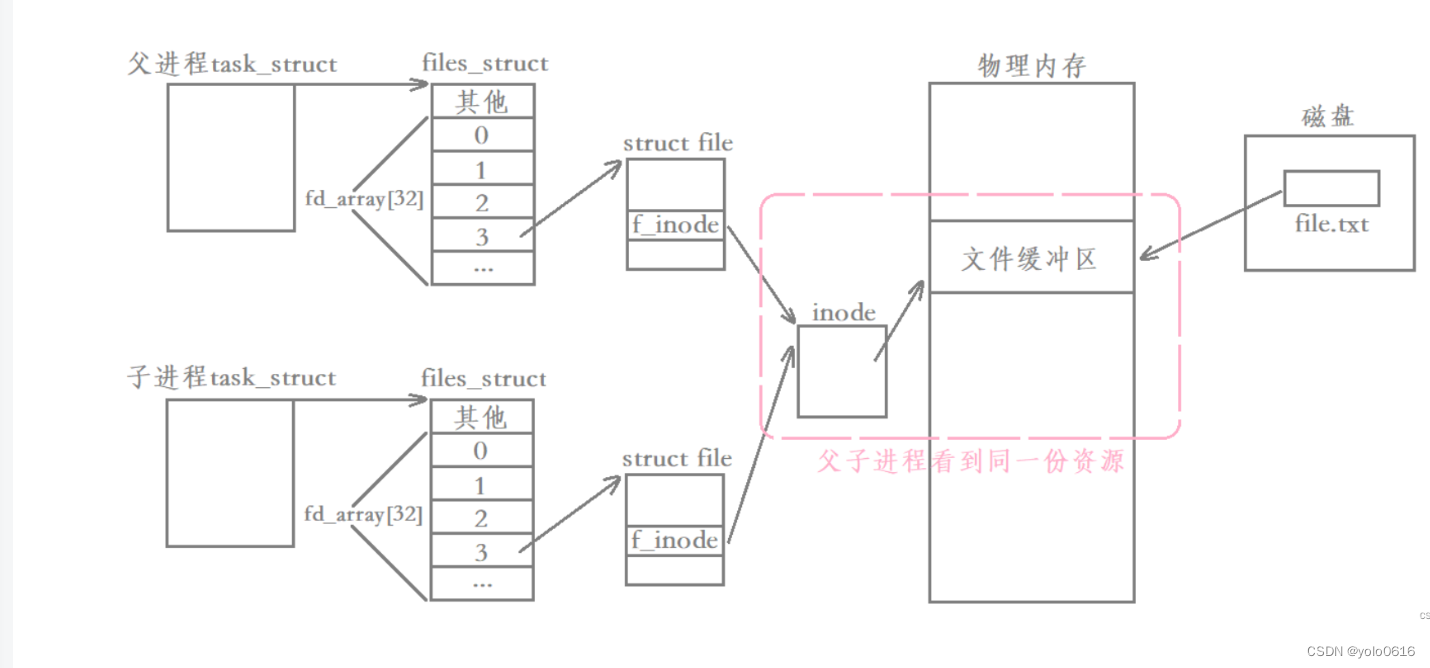
进程间通信的本质就是,让不同的进程看到同一份资源,使用匿名管道实现父子进程间通信的原理就是,让两个父子进程先看到同一份被打开的文件资源,然后父子进程就可以对该文件进行写入或是读取操作,进而实现父子进程间通信。
注意:
- 这里父子进看到的同一份文件资源是由操作系统来维护的,所以当父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝。
- 管道虽然用的是文件的方案,但操作系统一定不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率,而且也没有必要。也就是说,这种文件是一批不会把数据写到磁盘当中的文件,换句话说,磁盘文件和内存文件不一定是一一对应的,有些文件只会在内存当中存在,而不会在磁盘当中存在。
父进程写入文件的缓冲区,子进程去缓冲区里读,就实现了两个进程看到同一份资源,这个用于通信的内存级文件就叫做管道(普通级文件是为了保存数据到磁盘的)。struct file中有inode,inode中有一个联合体可以来表示自己是管道/块设备/文件/字符!
2.匿名管道的创建:pipe函数
pipe函数用于创建匿名管道,pip函数的函数原型如下:
#include <unistd.h>
int pipe(int pipefd[2]);pipe函数的参数是一个输出型参数,数组pipefd用于返回两个指向管道读端和写端的文件描述符:

为了方便理解:
0 - 嘴巴 - 读
1 - 钢笔 - 写字
pipe函数调用成功时返回0,调用失败时返回-1。
3.匿名管道使用步骤
在创建匿名管道实现父子进程间通信的过程中,需要pipe函数和fork函数搭配使用,具体步骤如下:
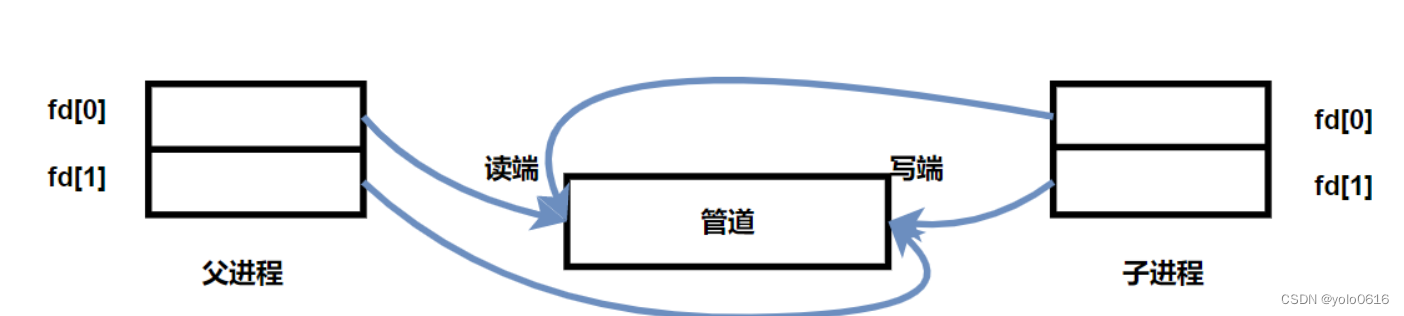
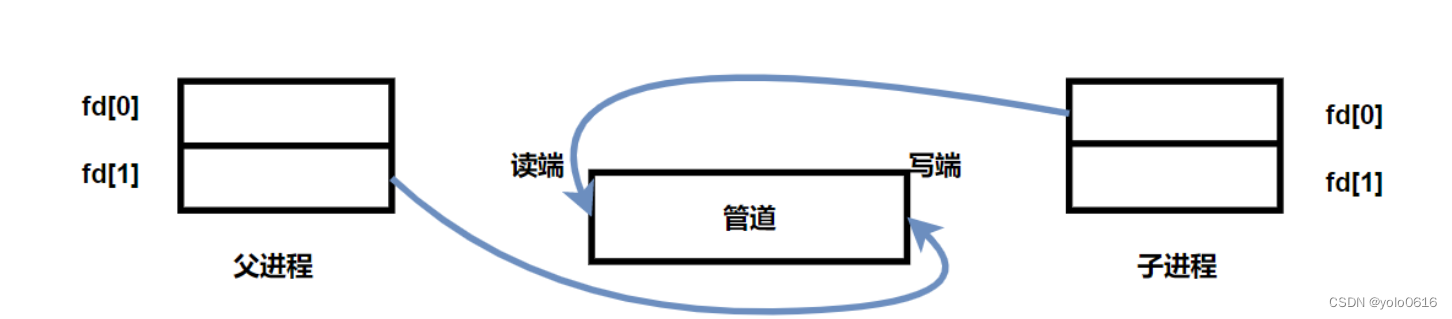
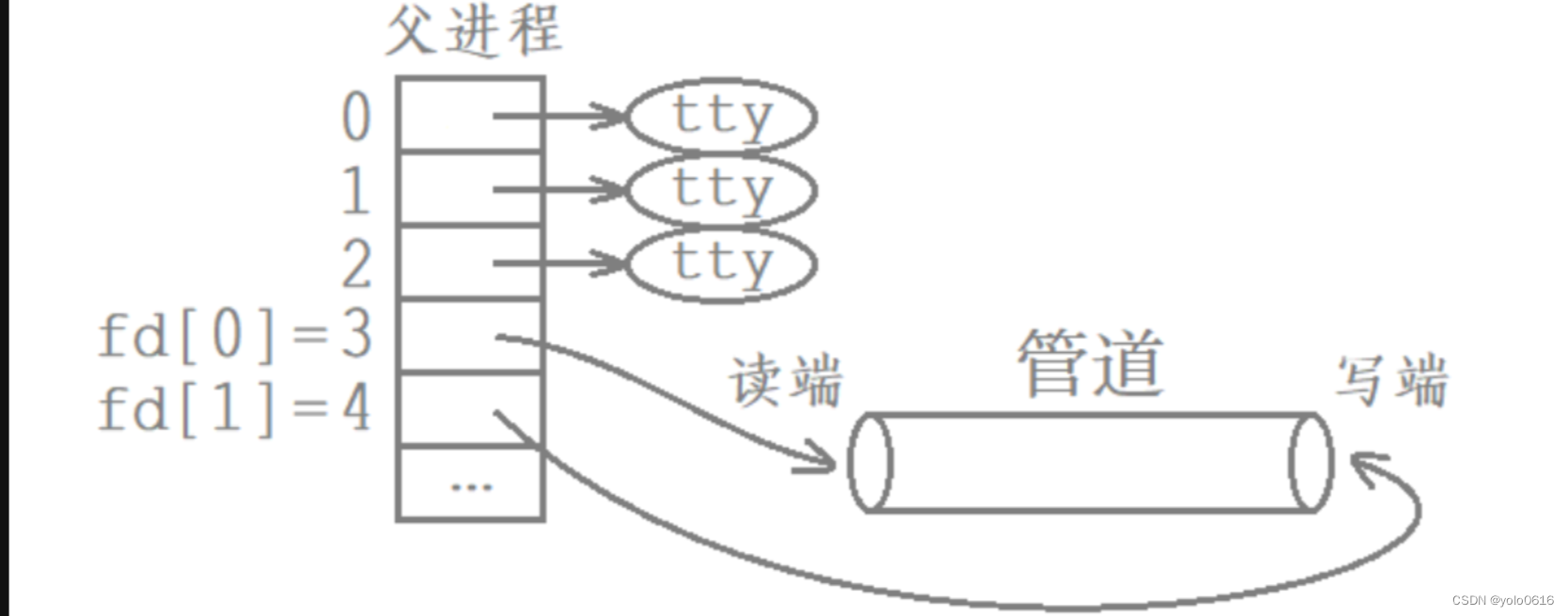
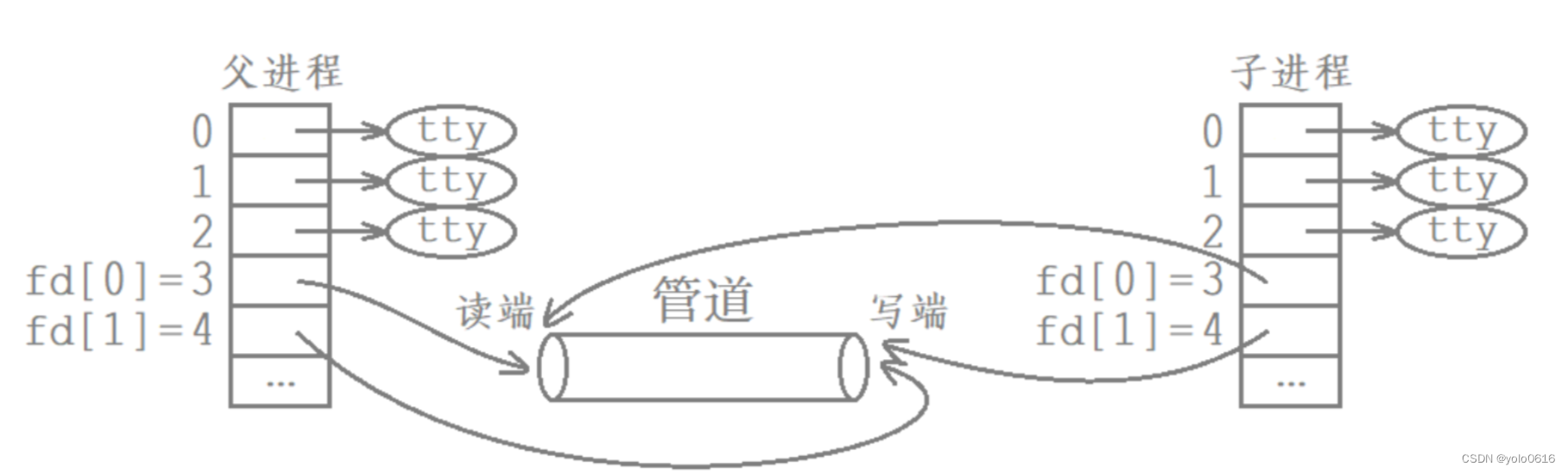
1.父进程调用pipe函数创建管道。
2.父进程创建子进程。
3.父进程关闭写端,子进程关闭读端,或者父进程关闭读端,子进程关闭写端.

注意:
- 管道只能够进行单向通信,因此当父进程创建完子进程后,需要确认父子进程谁读谁写,然后关闭相应的读写端。
- 从管道写端写入的数据会被内核缓冲区,直到从管道的读端被读取。
我们可以站在文件描述符的角度再来看看这三个步骤:
1.父进程调用pipe函数创建管道。
2.父进程创建子进程。
3.父进程关闭写端,子进程关闭读端,或者父进程关闭读端,子进程关闭写端.
示例代码:
将可变参数 “…” 按照format的格式格式化为字符串,然后再将其拷贝至str中。
snprintf(),函数原型为int snprintf(char *str, size_t size, const char *format, ...)。#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cassert>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
using namespace std;
int main() {
int fd[2] = {0};
if (pipe(fd) < 0) {
perror("perror error");
return 1;
}
pid_t id = fork();
assert(id >= 0);
if (id == 0) {
// 子进程进行写入
close(fd[0]); // 子进程关闭读端
const char *s = "我是子进程,我正在给你发消息";
int count = 10;
while (count --) {
char buff[1024];
snprintf(buff,sizeof buff,"child->parent say: %s[%d][%d]",s,count,getpid());
write(fd[1],buff, strlen(buff));
sleep(1);
cout << "count : " << count << endl;
}
close(fd[1]);
cout << "子进程关闭自己的写端" << endl;
exit(0);
}
// 父进程进行读取
close(fd[1]);
while (1) {
sleep(1);
char buff[1024];
ssize_t s = read(fd[0],buff,sizeof(buff) - 1);
if (s > 0) {
buff[s] = '\0';
cout << "Get Message# " << buff << " | my pid: " << getpid() << endl;
}
else if(s == 0) { 当read返回0时说明写端已关闭,所以要退出
cout << "read file end" << endl;
break;
}
else {
cout << "read error" << endl;
break;
}
}
close(fd[0]);
cout << "父进程关闭读端" << endl;
int status = 0;
int n = waitpid(id,&status,0);
assert(n == id);
cout <<"pid->"<< n << " : "<< (status & 0x7F) << endl;
return 0;
}运行结果如下:

- 当子进程没有写入数据的时候,父进程在等。所以,子进程写入之后,父进程才能read(会返回)到数据,父进程打印读取数据要以子进程的节奏为主!
- 父进程和子进程读写管道的时候(是有一定的顺序性的!)。那么父子进程各自printf的时候,会有顺序吗?——答:无序。printf就是向显示器写入,也是文件,但是缺乏访问控制。
- 父进程和子进程读写管道的时候:——管道内部,没有数据,reader就必须阻塞等待(read),等管道有数据(阻塞等待就是当前进程的 task_ struct 放入等待队列中,R->S/D/T)
- 管道内部,如果数据被写满,writer就必须阻塞等待(write)等待管道中有空间因为pipe内部自带访问控制机制——同步和互斥机制。
4.匿名管道读写规则
pipe2函数与pipe函数类似,也是用于创建匿名管道,其函数原型如下:
int pipe2(int pipefd[2], int flags);pipe2函数的第二个参数用于设置选项。
1、当没有数据可读时:
O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来为止。
O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
2、当管道满的时候:
O_NONBLOCK disable:write调用阻塞,直到有进程读走数据。
O_NONBLOCK enable:write调用返回-1,errno值为EAGAIN。
3、如果所有管道写端对应的文件描述符被关闭,则read返回0。
4、如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出。
5、当要写入的数据量不大于PIPE_BUF时,Linux将保证写入的原子性。
6、当要写入的数据量大于PIPE_BUF时,Linux将不再保证写入的原子性。
(二)管道特点
1.管道内部自带同步与互斥机制。
我们将一次只允许一个进程使用的资源,称为临界资源。管道在同一时刻只允许一个进程对其进行写入或是读取操作,因此管道也就是一种临界资源。
临界资源是需要被保护的,若是我们不对管道这种临界资源进行任何保护机制,那么就可能出现同一时刻有多个进程对同一管道进行操作的情况,进而导致同时读写、交叉读写以及读取到的数据不一致等问题。
为了避免这些问题,内核会对管道操作进行同步与互斥:
- 同步: 两个或两个以上的进程在运行过程中协同步调,按预定的先后次序运行。比如,A任务的运行依赖于B任务产生的数据。
- 互斥: 一个公共资源同一时刻只能被一个进程使用,多个进程不能同时使用公共资源。也就是说,互斥具有唯一性和排它性,但互斥并不限制任务的运行顺序
2.管道的生命周期随进程。
管道本质上是通过文件进行通信的,也就是说管道依赖于文件系统,那么当所有打开该文件的进程都退出后,该文件也就会被释放掉,所以说管道的生命周期随进程。
3.管道提供的是流式服务。
对于进程A写入管道当中的数据,进程B每次从管道读取的数据的多少是任意的,这种被称为流式服务,与之相对应的是数据报服务:
- 流式服务: 数据没有明确的分割,不分一定的报文段。
- 数据报服务: 数据有明确的分割,拿数据按报文段拿。\
4.管道是半双工通信的。
在数据通信中,数据在线路上的传送方式可以分为以下三种:
单工通信(Simplex Communication):单工模式的数据传输是单向的。通信双方中,一方固定为发送端,另一方固定为接收端。
半双工通信(Half Duplex):半双工数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。
全双工通信(Full Duplex):全双工通信允许数据在两个方向上同时传输,它的能力相当于两个单工通信方式的结合。全双工可以同时(瞬时)进行信号的双向传输。
管道是半双工的,数据只能向一个方向流动,需要双方通信时,需要建立起两个管道。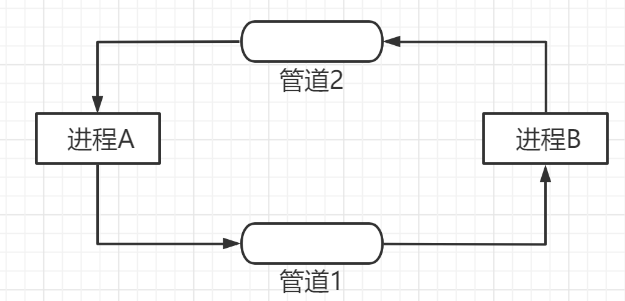
(三)管道的四种特殊情况

在使用管道时,可能出现以下四种特殊情况:
- 写端进程不写,读端进程一直读,那么此时会因为管道里面没有数据可读,对应的读端进程会被挂起(阻塞),直到管道里面有数据后,读端进程才会被唤醒。
- 读端进程不读,写端进程一直写,那么当管道被写满后,对应的写端进程会被挂起(阻塞),直到管道当中的数据被读端进程读取后,写端进程才会被唤醒。
- 写端进程将数据写完后将写端关闭,那么读端进程将管道当中的数据读完后,就会继续执行该进程之后的代码逻辑,而不会被挂起。(也就是说读端一直读,写端不写并且关闭,读取到0,代表文件结束。)
- 读端进程将读端关闭,而写端进程还在一直向管道写入数据,那么操作系统会将写端进程杀掉(写端被OS发送13号信号SIGPIPE杀掉)。
其中前面两种情况就能够很好的说明,管道是自带同步与互斥机制的,读端进程和写端进程是有一个步调协调的过程的,不会说当管道没有数据了读端还在读取,而当管道已经满了写端还在写入。读端进程读取数据的条件是管道里面有数据,写端进程写入数据的条件是管道当中还有空间,若是条件不满足,则相应的进程就会被挂起,直到条件满足后才会被再次唤醒。
第三种情况也很好理解,读端进程已经将管道当中的所有数据都读取出来了,而且此后也不会有写端再进行写入了,那么此时读端进程也就可以执行该进程的其他逻辑了,而不会被挂起。
第四种情况就是说:既然管道当中的数据已经没有进程会读取了,那么写端进程的写入将没有意义,因此操作系统直接将写端进程杀掉。(假设子进程是写端)而此时子进程代码都还没跑完就被终止了,属于异常退出,那么子进程必然收到了某种信号。
由此可知,当发生情况四时,操作系统向子进程发送的是SIGPIPE信号将子进程终止的。(13号)
(四)匿名管道特征总结:
(命令行管道|,其实就是匿名管道)
- 管道只能用来进行具有血缘关系的进程之间,进行进程间通信。常用于父子通信
- 管道只能单向通信(内核实现决定的),半双工的一 种特殊情况(半双工:某时某刻只要一个人在说一个人在听)
- 管道自带同步机制(pipe满—> writer等 ; pipe空—> reader等) --自带访问控制
- 管道是面向字节流的----现在还解释不清楚--先写的字符,一定是先被读取的,没有格式边界,需要用户来定义区分内容的边界[sizeof (uint32_ t)] ---- 网络tcp,我们自定义协议的
- 管道的生命周期--管道是文件--进程退出了,曾经打开的文件会怎么办?退出--管道的生命周期随进程。与该文件相关的所有进程退出,此文件的引用计数--到0,文件也会关闭
四、命名管道(FIFO)
(一)命名管道原理
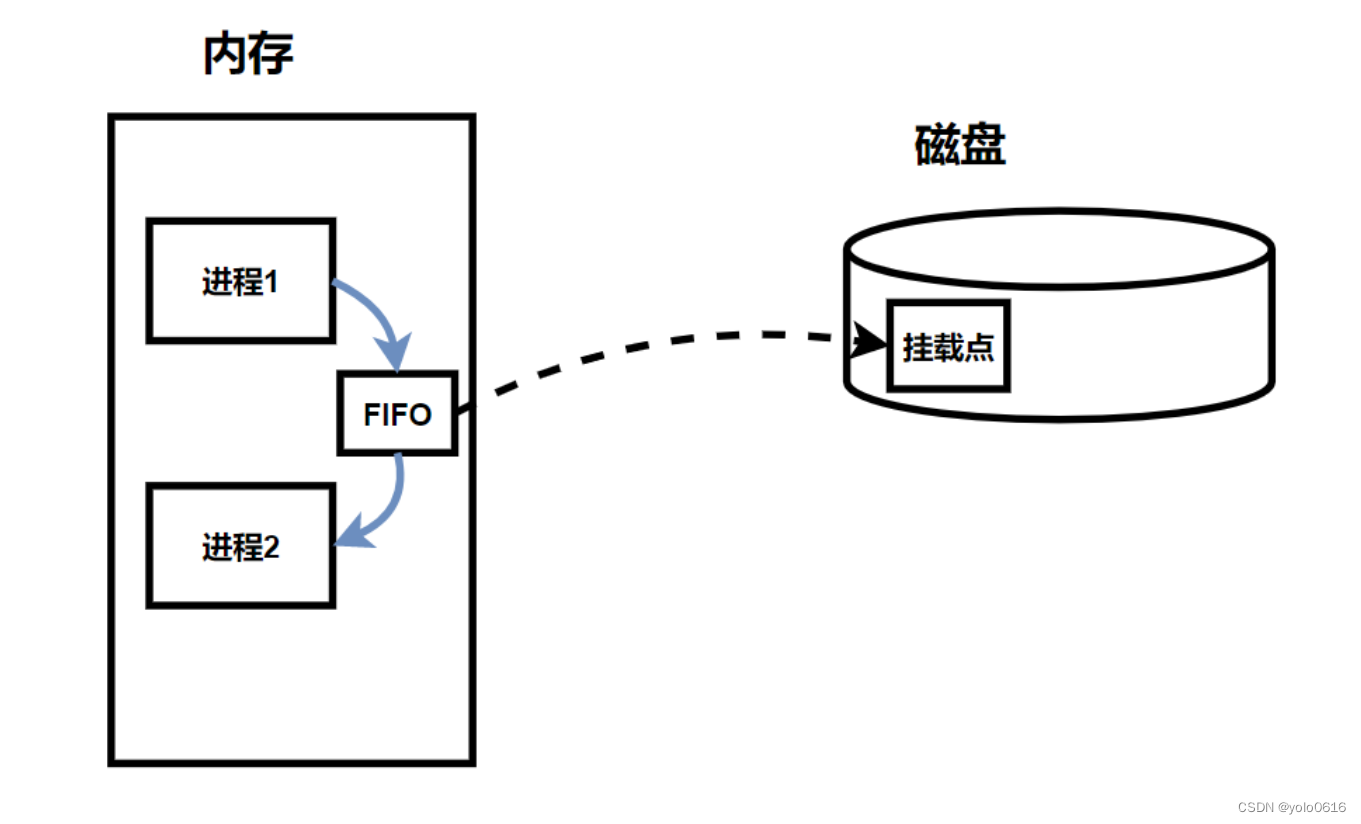
- 命名管道在某种程度上可以看做是匿名管道 ,但他打破了匿名管道只能在有血缘关系的进程间的通信。
- 命名管道之所以可以实现进程间通信,在于通过同一个路径名而看到同一份资源,这份资源以FIFO的文件形式存在于文件系统中。
- 它作为特殊的设备文件存在于文件系统中。因此,在进程中可以使用open()和close()函数打开和关闭命名管道。
命名管道原理:磁盘中的内存把 文件描述的结构体struct_file 加载到内存中,进程1打开此文件,引用计数加1;进程2打开此文件,遍历内核发现文件存在,引用计数变为2,两个进程可以看到同一份资源。两进程通信时在内存中通信,数据不会刷新到磁盘上,此文件只是一种符号
通过一个fifo文件->有路径->具有唯一性->通过路径,找到同一个资源!磁盘
(二)创建命名管道
1.命名管道可以从命令行上创建
mkfifo fifo
2.命名管道也可以从程序里创建
#include <sys/tyoes.h>
#include <sys/stat.h>
int mkfifo(const char* pathname, mode_t mode);
参数:
- pathname是一个文件的路径名,是创建的一个命名管道的文件名;
- 参数mode是指文件的权限,文件权限取决于(mode&~umask)的值。
返回值:
- 返回值:若成功则返回0,否则返回-1
注意第二个参数的权限问题:
例如,将mode设置为0666,按理说命名管道文件创建出来的权限如下:
prw-rw-rw-
但实际上创建出来文件的权限值还会受到umask(文件默认掩码)的影响,实际创建出来文件的权限为:mode&(~umask)。
umask的默认值一般为0002,当我们设置mode值为0666时实际创建出来文件的权限为0664。即prw-rw-r-
若想创建出来命名管道文件的权限值不受umask的影响,则需要在创建文件前使用umask函数将文件默认掩码设置为0。
umask(0); //将文件默认掩码设置为0从程序里创建命名管道示例:
//在当前路径下,创建出一个名为myfifo的命名管道。
1 #include<stdio.h>
2 #include<sys/stat.h>
3 #include<sys/types.h>
4
5 #define My_FIFO "./fifo"
6
7 int main()
8 {
9 umask(0); //将文件默认掩码设置为0
10 if(mkfifo(My_FIFO,0666)<0)
11 {
12 perror("mkfifo");
13 return 1;
14 }
15 return 0;
16 }
(二)命名管道的打开规则
1.如果当前打开操作是为读而打开FIFO时。
- O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO。
- O_NONBLOCK enable:立刻返回成功。
2.如果当前打开操作是为写而打开FIFO时。
- O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO。
- O_NONBLOCK enable:立刻返回失败,错误码为ENXIO。
(三)用命名管道实现serve&client通信
实现服务端(server)和客户端(client)之间的通信之前,我们需要先让服务端运行起来,我们需要让服务端运行后创建一个命名管道文件,然后再以读的方式打开该命名管道文件,之后服务端就可以从该命名管道当中读取客户端发来的通信信息了。
1.共用头文件
#pragma once
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_NAME "myfifo" //让客户端和服务端使用同一个命名管道
2.服务端
我们让服务端实现读取客户端内容的功能,只需要用mkfifo创建,然后用open打开,其他操作与匿名管道相同。
大致流程为:
而对于客户端来说,因为服务端运行起来后命名管道文件就已经被创建了,所以客户端只需以写的方式打开该命名管道文件,之后客户端就可以将通信信息写入到命名管道文件当中,进而实现和服务端的通信。
①创建管道
②打开管道
③循环读取数据
④关闭管道
⑤结束程序
#include "comm.hpp"
// 你可不可以把刚刚写的改成命名管道呢!
int main()
{
std::cout << "client begin" << std::endl;
int wfd = open(NAMED_PIPE, O_WRONLY);
std::cout << "client end" << std::endl;
if(wfd < 0) exit(1);
//write
char buffer[1024];
while(true)
{
std::cout << "Please Say# ";
fgets(buffer, sizeof(buffer), stdin); // abcd\n
if(strlen(buffer) > 0) buffer[strlen(buffer)-1] = 0;
ssize_t n = write(wfd, buffer, strlen(buffer));
assert(n == strlen(buffer));
(void)n;
}
close(wfd);
return 0;
}3.客户端
我们让客户端实现给服务端发送数据的功能,大致流程为:
①打开管道
②循环读取用户信息
③将信息输入管道中
④关闭管道结束程序
#include "comm.hpp"
int main()
{
bool r = createFifo(NAMED_PIPE);
assert(r);
(void)r;
std::cout << "server begin" << std::endl;
int rfd = open(NAMED_PIPE, O_RDONLY);
std::cout << "server end" << std::endl;
if(rfd < 0) exit(1);
//read
char buffer[1024];
while(true)
{
ssize_t s = read(rfd, buffer, sizeof(buffer)-1);
if(s > 0)
{
buffer[s] = 0;
std::cout << "client->server# " << buffer << std::endl;
}
else if(s == 0)
{
std::cout << "client quit, me too!" << std::endl;
break;
}
else
{
std::cout << "err string: " << strerror(errno) << std::endl;
break;
}
}
close(rfd);
// sleep(10);
removeFifo(NAMED_PIPE);
return 0;
}对于如何让客户端和服务端使用同一个命名管道文件,这里我们可以让客户端和服务端包含同一个头文件,该头文件当中提供这个共用的命名管道文件的文件名,这样客户端和服务端就可以通过这个文件名,打开同一个命名管道文件,进而进行通信了。
代码编写完毕后,先将服务端进程运行起来,之后我们就能看到这个已经被创建的命名管道文件。
接着再将客户端也运行起来,此时我们从客户端写入的信息被客户端写入到命名管道当中,服务端再从命名管道当中将信息读取出来打印在服务端的显示器上,此时这两个进程之间是能够通信的。
服务端和客户端之间的退出关系:
当客户端退出后,服务端将管道当中的数据读完后就再也读不到数据了,那么此时服务端也就会去执行它的其他代码了(在当前代码中是直接退出了)。
当服务端退出后,客户端写入管道的数据就不会被读取了,也就没有意义了,那么当客户端下一次再向管道写入数据时,就会收到操作系统发来的13号信号(SIGPIPE),此时客户端就被操作系统强制杀掉了。
通信是在内存当中进行的!
若是我们只让客户端向管道写入数据,而服务端不从管道读取数据,那么这个管道文件的大小会不会发生变化呢?
此时,分别运行客户端和服务端,在客户端写入数据,服务端并不读取管道当中的数据,此时使用ll命令看到命名管道文件的大小依旧为0,也就是管道当中的数据并没有被刷新到磁盘,也就说明了双方进程之间的通信依旧是在内存当中进行的,和匿名管道通信是一样的。
(四)命名管道和匿名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfifo函数创建,由open函数打开。
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在于它们创建与打开的方式不同,一旦这些工作完成之后,它们具有相同的语义。
拓展:在命令行当中的管道(“|”)到底是匿名管道还是命名管道呢?
由于匿名管道只能用于有亲缘关系的进程之间的通信,而命名管道可以用于两个毫不相关的进程之间的通信,因此我们可以先看看命令行当中用管道(“|”)连接起来的各个进程之间是否具有亲缘关系。
我们如果通过管道(“|”)连接了三个进程,通过ps命令查看这三个进程就可以发现,这三个进程的PPID是相同的,也就是说它们是由同一个父进程创建的子进程。而它们的父进程实际上就是命令行解释器,这里为bash。
也就是说,由管道(“|”)连接起来的各个进程是有亲缘关系的,它们之间互为兄弟进程。
(五)总结
- 命名管道可以实现任意两个进程间的通信。
- 管道只能单向通信(内核实现决定的),是半双工的一种特殊情况。
- 管道自带同步机制 – 自带访问控制。
- 管道是面向字节流的,没有格式边界,需要用户来自定义区分内容的边界。
- 管道的生命周期,随进程退出而退出。