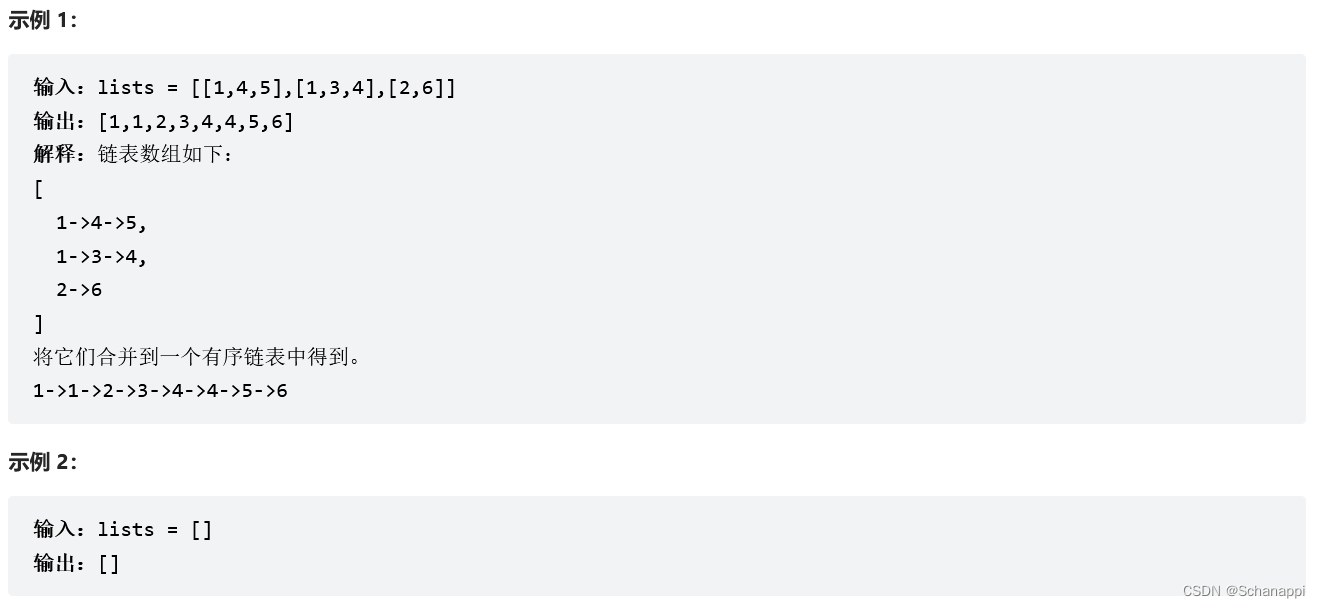
23. 合并 K 个升序链表(困难)



方法一:顺序合并
思路


ListNode* mergeTwoLists(ListNode *a, ListNode *b) {
if ((!a) || (!b)) return a ? a : b;
ListNode head, *tail = &head, *aPtr = a, *bPtr = b;
while (aPtr && bPtr) {
if (aPtr->val < bPtr->val) {
tail->next = aPtr; aPtr = aPtr->next;
} else {
tail->next = bPtr; bPtr = bPtr->next;
}
tail = tail->next;
}
tail->next = (aPtr ? aPtr : bPtr);
return head.next;
}

代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* merge2Lists(ListNode* a, ListNode* b){
// 如果二者中有空链表 返回非空链表
if((!a) || (!b)) return a ? a : b;
ListNode head, *tail = &head, *aptr=a, *bptr=b;
while(aptr && bptr){
// a的值比较小 加入a
if(aptr->val < bptr->val){
tail->next = aptr;
aptr = aptr-> next;
}
// b的值比较小
else{
tail->next = bptr;
bptr = bptr->next;
}
tail = tail -> next;
}
tail->next = (aptr ? aptr : bptr);
// 因为head是节点 所以用.访问
return head.next;
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
ListNode *ans=nullptr;
for(int i=0; i<lists.size(); ++i){
// 将ans和list[i]逐一合并
ans = merge2Lists(ans, lists[i]);
}
return ans;
}
};
方法二:分治
思路

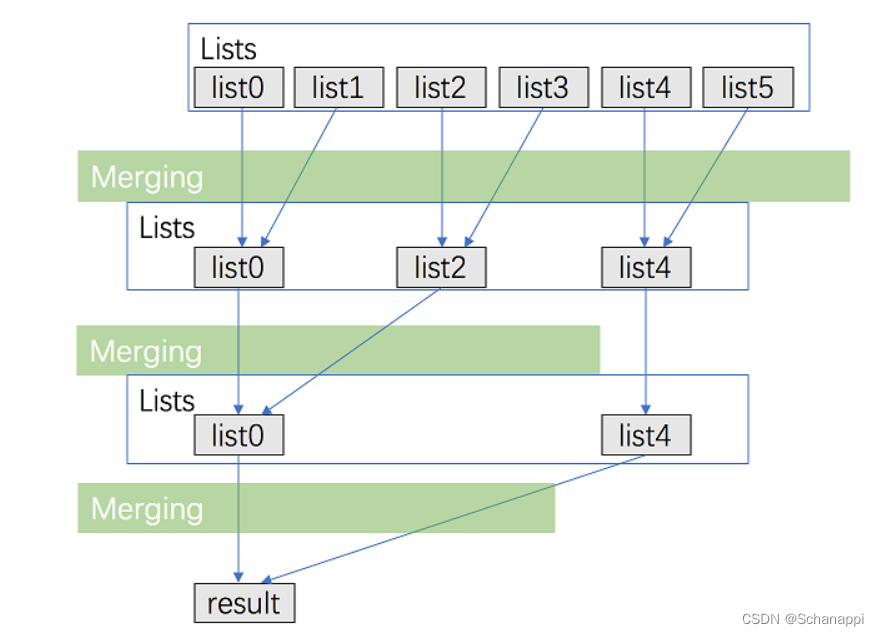
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* merge2Lists(ListNode* a, ListNode* b){
// 如果二者中有空链表 返回非空链表
if((!a) || (!b)) return a ? a : b;
ListNode head, *tail = &head, *aptr=a, *bptr=b;
while(aptr && bptr){
// a的值比较小 加入a
if(aptr->val < bptr->val){
tail->next = aptr;
aptr = aptr-> next;
}
// b的值比较小
else{
tail->next = bptr;
bptr = bptr->next;
}
tail = tail -> next;
}
tail->next = (aptr ? aptr : bptr);
// 因为head是节点 所以用.访问
return head.next;
}
ListNode* merge(vector<ListNode*> a, int l, int r){
if(l == r) return a[l];
if(l > r) return nullptr;
int mid = (l + r) / 2;
return merge2Lists(merge(a, l, mid), merge(a, mid+1, r));
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
return merge(lists, 0, lists.size()-1);
}
};
方法三:优先队列
-
什么是优先队列?
优先队列是一种容器适配器,采用了堆这样的数据结构,保证了第一个元素总是整个优先队列中最大的(或最小的)元素。
优先队列默认使用vector作为底层存储数据的容器,在vector上使用了堆算法将vector中的元素构造成堆的结构,所以其实我们就可以把它当作堆,凡是需要用堆的位置,都可以考虑优先队列。
-
priority_queue类模板参数
template <class T, class Container = vector<T>, class Compare = less<typename Container::value_type> > class priority_queue;-
class T:T是优先队列中存储的元素的类型。
-
class Container = vector< T>:Container是优先队列底层使用的存储结构,可以看出来,默认采用vector。
-
class Compare = less< typename Container::value_type> :Compare是定义优先队列中元素的比较方式的类。默认是按小于(less)的方式比较,创建出来的就是大堆。所以优先队列默认就是大堆。如果需要创建小堆,就需要将less改为greater。
下面是less类的内部函数,less类的内部重载(),参数列表中有左右两个参数,左边小于右边的时候返回true,此时优先队列就是大堆。
template <class T> struct less : binary_function <T,T,bool> { bool operator() (const T& x, const T& y) const {return x<y;} };注意:less类和greater类只能比较内置类型的数据的大小,如果用户需要比较自定义类型的数据,就需要自己定义一个比较类,并且重载()。
同时less类和greater类也具有模板参数,因为他们也是模板,所以我们如果要存储自定义类型的元素,就要将自定义类型作为模板参数传递给less类和greater类。
-
-
示例
因为priority_queue是模板,所以创建对象时需要传入模板参数,但是由于模板参数内部是具有默认值的,所以创建大堆时可以只传递元素类型即可。但创建小堆的时候,模板参数是不可以省略的。
//完整版按大堆创建对象 priority_queue<int,vector<int>, less<int>> q; //按小堆创建对象(按小堆创建时参数列表不可以省略) priority_queue<int, vector<int>, greater<int>> q;

- 注意,因为 Comp 函数默认是对最大堆进行比较并维持递增关系,如果我们想要获取到最小的节点值,则需要实现一个最小堆,因此比较函数应该维持递减关系,所以 operator() 中返回时用大于号进行比较。
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
// 比较模板
struct Comp{
bool operator() (ListNode* l1, ListNode* l2){
// 最小堆
return l1->val > l2->val;
}
};
ListNode* mergeKLists(vector<ListNode*>& lists) {
if(lists.empty()) return nullptr;
// 最小堆的优先队列,所以模板不可以省略
priority_queue<ListNode*, vector<ListNode*>, Comp> q;
// 只存入每个链表的第一个元素
for(ListNode* list:lists){
// 注意要非空
if(list)
q.push(list);
}
// dummy 虚拟节点,最终返回它的下一个位置
ListNode *dummy = new ListNode(0), *cur = dummy;
while(!q.empty()){
cur->next = q.top();
q.pop();
cur = cur -> next;
// 即q.top()所在链表还没有遍历结束
// 那么需要存入它的下一个节点
if(cur->next){
q.push(cur->next);
}
}
return dummy->next;
}
};
参考资料
- 官方题解
- C++ 优先队列 priority_queue 使用篇