Kafka_深入探秘者(9):kafka 集群管理
一、kafka 集群概述
1、kafka 集群概述:
-
集群是一种计算机系统,它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。在某种意义上,他们可以被看作是一台计算机。
-
集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式。
-
集群计算机通常用来改进单个计算机的计算速度和/或可靠性。一般情况下集群计算机比
单个计算机,比如工作站或超级计算机性能价格比要高得多。
2、集群的特点
集群拥有以下两个特点:
- 1.可扩展性; 集群的性能不限制于单一的服务实体,新的服务实体可以动态的添加到集群,从而增强集群的性能。
- 2.高可用性: 集群当其中一个节点发生故障时,这台节点上面所运行的应用程序将在另一台节点被自动接管,消除单点故障对于增强数据可用性、可达性和可靠性是非常重要的。
3、集群的能力
- 1.负载均衡: 负载均衡把任务比较均匀的分布到集群环境下的计算和网络资源,以提高数据吞吐量。
- 2.错误恢复: 如果集群中的某一台服务器由于故障或者维护需要无法使用,资源和应用程序将转移到可用的集群节点上。这种由于某个节点的资源不能工作,另一个可用节点中的资源能够透明的接管并继续完成任务的过程,叫做错误恢复。
4、负载均衡 和 错误恢复要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图必须是相同的。
5、集群使用场景
Kafka 是一个分布式消,息系统,具有高水平扩展和高吞吐量的特点。在 Kafka 集群中,没有“中心主节点”的概念,集群中所有的节点都是对等的。
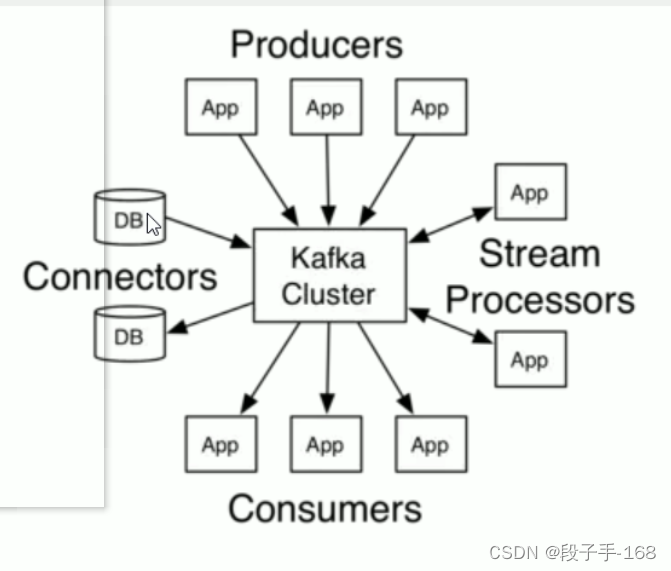
6、Broker(代理)
每个 Broker 即一个 Kafka 服务实例,多个 Broker 构成一个 Kafka集群,生产者发布的消,息将保存在 Broker中,消费者将从 Broker 中拉取消息进行消费。
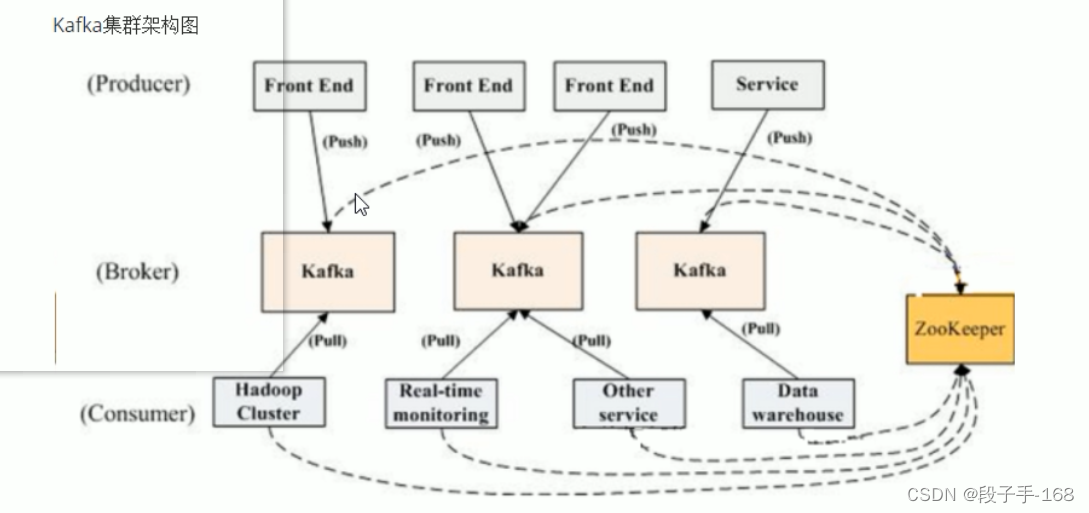
从上图中可以看出 Kafka 强依赖于 ZooKeeper ,通过 ZooKeeper 管理自身集群,如:Broker 列表管理、Partition 与 Broker的关系、Partition 与 Consumer 的关系、Producer 与 Consumer 负载均衡、消费进度 Offset 记录、消费者注册等,所以为了达到高可用,ZooKeeper 自身也必须是集群。
二、kafka 集群搭建 zookeeper
1、kafka 集群搭建 zookeeper
真实的集群环境需要部署在不同的服务器上的,测试启动多个虚拟机的内存消耗太大,
所以通常会搭建伪集群,也就是把所有服务搭建在一台虚拟机上,用端口进行区分。
2、下载安装 JDK ,并配置环境变量,查询 JDK 是否安装配置成功
- 下载 JDK
- 1. JDK-7 下载:
http://jdk.java.net/java-se-ri/7
- 2. JDK-8 下载:
https://jdk.java.net/java-se-ri/8-MR5
- 3. JDK-9 下载:
http://jdk.java.net/java-se-ri/9
- 4. JDK-10 下载:
http://jdk.java.net/java-se-ri/10
- 5. JDK-11 下载:
http://jdk.java.net/java-se-ri/11
- 6. JDK-12 下载:
http://jdk.java.net/java-se-ri/12
# 打开环境变量文件,配置JDK
sudo vim /etc/profile
# 添加 jdk 环境变量配置
# 你的 jdk 安装路径(java 默认安装路径:/usr/lib/jvm/java-8-openjdk-amd64/ )
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME-${JAVA_HOME}/jre
export PATH=S{JAVA_HOME}/bin:$PATH
# 配置完 JDK 记得断开连接重新连接 或者重启系统。
# 测试 jdk 是否安装配置成功
java -version
3、下载安装 Zookeeper 并上传 zookeeper 压缩包至服务器上。
1)zookeeper-3.6.3.tar.gz下载地址:
https://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/
ZooKeeper 官网: http://zookeeper.apache.org
https://github.com/apache/zookeeper/tags?after=release-3.8.0-1
2)Alt+P 进入 SFTP, 输入:put (yourpath) 上传,
(如:d:\zookeeper-3.6.3.tar.gz 为本地存放路径)
或者:rz 上传。
4、将 zookeeper 解压到 /usr/local/zookeeper 目录下。
# 切换目录:
cd /usr/local
# 创建 zookeeper 目录:
sudo mkdir zookeeper
cd /usr/local/zookeeper/
# 解压即安装
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C /usr/local/zookeeper/
5、修改 Zookeeper 的配置文件,首先进入安装路径 conf 目录,并将 zoo_sample.cfg 文件修改为 zoo.cfg,并对核心参数进行配置。文件内容如下:
# 切换目录
cd /usr/local/zookeeper/apache-zookeeper-3.6.3-bin/conf/
# 将 zoo_sample.cfg 文件修改为 zoo.cfg
mv zoo_sample.cfg zoo.cfg
# 对核心参数进行配置
vim zoo.cfg
# The number of milliseconds of each tick
#zk服务器的心跳时间
tickTime-2080
# The number of ticks that the initial
#synchronization phase can take
#投票选举新Leader的初始化时间
initlimit=10
# The number of ticks that can pass between
# sendidg a request and getting an acknowledgementsyncLimit-5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 数据目录(需要新建 data 此目录)
dataDir=/usr/local/zookeeper/apache-zookeeper-3.6.3-bin/data
# 日志目录
dataLogDir=/usr/local/zookeeper/apache-zookeeper-3.6.3-bin/log
# the port at which the clients will connect
#Zookeeper对外服务端口,保持默认
clientPort-2181
6、复制 /usr/local/zookeeper/apache-zookeeper-3.6.3-bin/ 三份,并分别改名为:zk-01, zk-02, zk-03
# 切换目录
cd /usr/local/zookeeper/
# 复制 zookeeper 三份并更名
cp -rf apache-zookeeper-3.6.3-bin ./zk-01
cp -rf apache-zookeeper-3.6.3-bin ./zk-02
cp -rf apache-zookeeper-3.6.3-bin ./zk-03
7、配置每一个 zookeeper 的 dataDir(zoo.cfg),clientPort 端口 分别为 2181 2182 2183
# 切换目录
cd /usr/local/zookeeper/
# 打开并编辑配置文件 zoo.cfg
vim zk-01/zoo.cfg
dataDir=/usr/local/zkcluster/zk-01/data
clientPort=2181
:wq (保存并退出)
# 打开并编辑配置文件 zoo.cfg
vim zk-02/zoo.cfg
dataDir=/usr/local/zkcluster/zk-02/data
clientPort=2182
# 打开并编辑配置文件 zoo.cfg
vim zk-03/zoo.cfg
dataDir=/usr/local/zkcluster/zk-03/data
clientPort=2183
8、zookeeper 配置集群
1)在每个 zookeeper 的 data 目录下创建一个 myid 文件,内容分别是 1,2,3
这个文件就是记录每个服务器的ID
# 切换目录
cd /usr/local/zookeeper/
vim zk-01/myid
1
:wq
vim zk-02/myid
2
:wq
vim zk-03/myid
3
:wq
2)在每一个zookeeper的 zoo.cfg 配置客户端访问端口(clientPort)和集群服务器IP列表
server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
# 切换目录
cd /usr/local/zookeeper/
vim zk-01/conf/zoo.cfg
vim zk-02/conf/zoo.cfg
vim zk-03/conf/zoo.cfg
# 文件末尾都添加:
server.1=172.19.206.8:2881:3881
server.2=172.19.206.8:2882:3882
server.3=172.19.206.8:2883:3883
:wq (保存并退出)
9、启动集群:
依次启动三个 zookeeper 实例,其中有一个 leader 和两个 follower 。
# 切换目录
cd /usr/local/zookeeper/
# 启动 Zookeeper
zk-01/bin/zkServer.sh start
zk-02/bin/zkServer.sh start
zk-03/bin/zkServer.sh start
# 查询 zookeeper 是否启动成功
ps -ef | grep zookeeper
# 或者
jps -l
# 查看启动状态
zk-01/zkServer.sh status
zk-02/zkServer.sh status
zk-03/zkServer.sh status
Mode: follower
Mode: leader
Mode: follower
# 关闭 zookeeper
zk-01/zkServer.sh stop
zk-02/zkServer.sh stop
zk-03/zkServer.sh stop
三、kafka 集群搭建
1、拷贝三份 kafka_2.12-2.8.0 分别命名为:kafka-01, kafka-02, kafka-03
# 切换目录
cd /usr/local/kafka/
# 拷贝三份 kafka_2.12-2.8.0 分别命名为:kafka-01, kafka-02, kafka-03
cp -rf kafka_2.12-2.8.0 ./kafka-01
cp -rf kafka_2.12-2.8.0 ./kafka-02
cp -rf kafka_2.12-2.8.0 ./kafka-03
2、修改 kafka-01 的配置文件 kafka/kafka-01/config/server.properties
broker.id=0, log.dirs=/usr/local/kafka/kafka-01/logs, port=9092
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-01 的配置文件 kafka-01/config/server.properties
vim kafka-01/config/server.properties
# 修改以下几个配置:
broker.id=0
log.dirs=/usr/local/kafka/kafka-01/logs
# listeners=PLAINTEXT://localhost:9092
# host.name=localhost
# port=9092
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110):
listeners=PLAINTEXT://172.18.30.110:9092
# 修改 zookeeper 地址为集群
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110):
zookeeper.connect=172.18.30.110:2181,172.18.30.110:2182,172.18.30.110:2183
3、修改 kafka-02 的配置文件 kafka/kafka-02/config/server.properties
broker.id=1, log.dirs=/usr/local/kafka/kafka-02/logs, port=9093
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-02 的配置文件 kafka-02/config/server.properties
vim kafka-02/config/server.properties
# 修改以下几个配置:
broker.id=1
log.dirs=/usr/local/kafka/kafka-02/logs
# listeners=PLAINTEXT://localhost:9093
# host.name=localhost
# port=9093
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110):
listeners=PLAINTEXT://172.18.30.110:9093
# 修改 zookeeper 地址为集群
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110):
zookeeper.connect=172.18.30.110:2181,172.18.30.110:2182,172.18.30.110:2183
4、修改 kafka-03 的配置文件 kafka/kafka-03/config/server.properties
broker.id=2, log.dirs=/usr/local/kafka/kafka-03/logs, port=9094
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-03 的配置文件 kafka-03/config/server.properties
vim kafka-03/config/server.properties
# 修改以下几个配置:
broker.id=2
log.dirs=/usr/local/kafka/kafka-03/logs
# listeners=PLAINTEXT://localhost:9094
# host.name=localhost
# port=9094
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110):
listeners=PLAINTEXT://172.18.30.110:9094
# 修改 zookeeper 地址为集群
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
# 或者把 localhost 换成 填写你的 虚拟机 IP 地址(如:172.18.30.110):
zookeeper.connect=172.18.30.110:2181,172.18.30.110:2182,172.18.30.110:2183
5、删除 kafka 三个节点 kafka-01, kafka-02, kafka-03 以前的日志文件。
删除命令:rm -rf logs/*
# 切换目录
cd /usr/local/kafka/
# 删除 节点1:kafka-01 以前的日志文件
rm -rf kafka-01/logs/*
# 删除 节点2:kafka-02 以前的日志文件
rm -rf kafka-02/logs/*
# 删除 节点3:kafka-03 以前的日志文件
rm -rf kafka-03/logs/*
6、启动 kafka 三个节点 kafka-01, kafka-02, kafka-03
启动命令:bin/kafka-server-start.sh config/server.properties
# 切换目录
cd /usr/local/kafka/
# 启动 节点1:kafka-01
kafka-01/bin/kafka-server-start.sh kafka-01/config/server.properties
# 启动 节点2:kafka-02
kafka-02/bin/kafka-server-start.sh kafka-02/config/server.properties
# 启动 节点3:kafka-03
kafka-03/bin/kafka-server-start.sh kafka-03/config/server.properties
四、kafka 集群同步总结
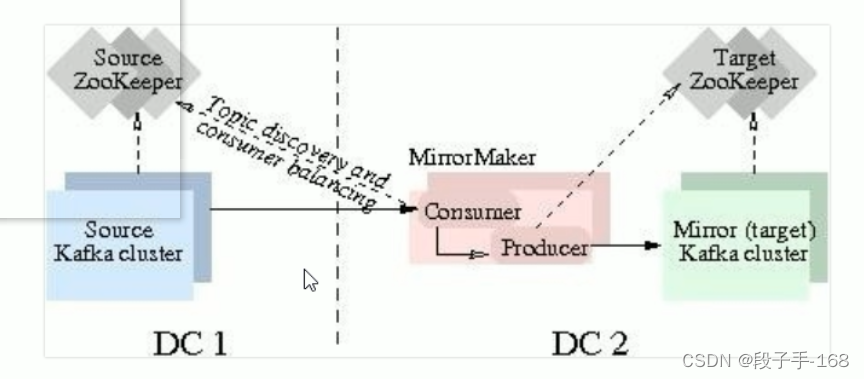
MirrorMaker 是为解决 Kafka 跨集群同步、创建镜像集群而存在的。
下图展示了其工作原理。该工具消费源集群消息然后将数据重新推送到目标集群。
上一节关联链接请点击
# Kafka_深入探秘者(8):kafka 高级应用
![腾讯云函数部署环境[使用函数URL]](https://i-blog.csdnimg.cn/direct/18f2ce17c76542a4aea985437ffdde17.png)









![Java [ 基础 ] Stream流 ✨](https://img-blog.csdnimg.cn/direct/626f619b6923406d884bd02519fe0a29.png)