leetcode数据库题第四弹
- 619. 只出现一次的最大数字
- 620. 有趣的电影
- 626. 换座位
- 627. 变更性别
- 1045. 买下所有产品的客户
- 1050. 合作过至少三次的演员和导演
- 1068. 产品销售分析 I
- 1070. 产品销售分析 III
- 1075. 项目员工 I
- 1084. 销售分析III
- 小结
619. 只出现一次的最大数字
https://leetcode.cn/problems/biggest-single-number/
简单的聚合,用group 加 having 轻松完成一拖三
select max(num) num from (select num from mynumbers group by num having(count(0)=1)) a
CSDN 文盲老顾的博客,https://blog.csdn.net/superwfei
620. 有趣的电影
https://leetcode.cn/problems/not-boring-movies/
嗯,oracle 居然不支持 % 运算求余
# oracle
select *
from cinema
where description <> 'boring' and mod(id,2) = 1
order by rating desc
# mysql && mssql
select *
from cinema
where description <> 'boring' and id % 2 = 1
order by rating desc
626. 换座位
https://leetcode.cn/problems/exchange-seats/
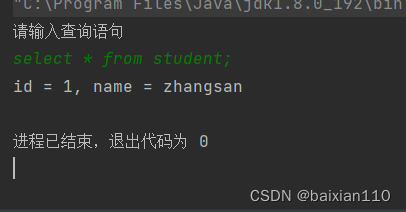
这个题目有问题,在力扣官方修正之前,这个题目没必要做了。为什么说有问题呢,看截图就知道了。


瞧瞧,输入信息一致,期待结果却不同。如果没有这个问题,老顾拉用例也能给他混个 ac了。
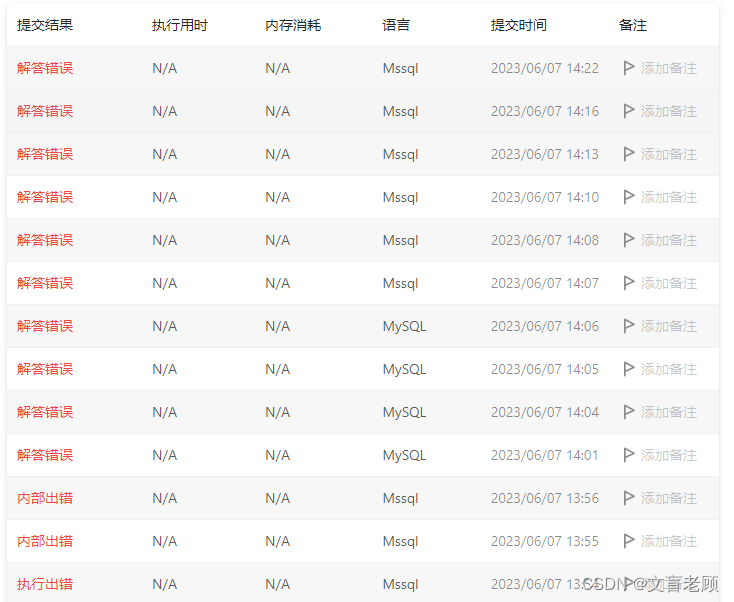
这为了验证官方题解,其他人的题解,以及拉用例,错了一地啊。
627. 变更性别
https://leetcode.cn/problems/swap-salary/
这个是 update 里用 case when 来实现。
# mysql && mssql
update salary
set sex = (case when sex = 'f' then 'm' else 'f' end)
1045. 买下所有产品的客户
https://leetcode.cn/problems/customers-who-bought-all-products/
group 加 having 加子查询即可
# mysql && oracle
select distinct customer_id
from customer
group by customer_id
having(count(distinct product_key) = (select count(0) from product))
这个指令在 mssql 是可用的,不知道为什么会出现超时,所以换个写法
select customer_id
from (
select customer_id,count(0) as cnt
from (
select distinct customer_id,product_key
from customer
) a
group by customer_id
) a
inner join (
select count(0) as cnt from product
) b on a.cnt=b.cnt
1050. 合作过至少三次的演员和导演
https://leetcode.cn/problems/actors-and-directors-who-cooperated-at-least-three-times/
简单的 having 判断一下就好
select actor_id,director_id
from actordirector
group by actor_id,director_id
having(count(0)>2)
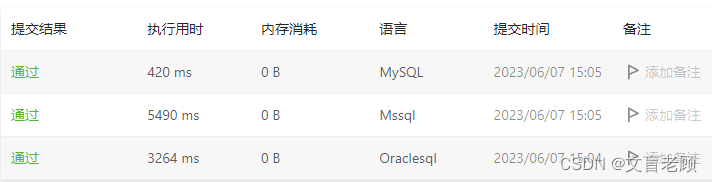
这个指令的用时其实还是很让老顾诧异的。
那就换个写法好了
select distinct actor_id,director_id
from (
select actor_id,director_id
,row_number() over(partition by actor_id,director_id order by timestamp) rid
from actordirector
) a
where rid>2
1068. 产品销售分析 I
https://leetcode.cn/problems/product-sales-analysis-i/
还以为有行列转换需求,结果发现,就是 left join 的内容。
select product_name,year,price
from sales s
left join product p on s.product_id=p.product_id
1070. 产品销售分析 III
https://leetcode.cn/problems/product-sales-analysis-iii/
这个题目,用排名函数很简单就能完成,不过需要注意,可能某产品在某一年有多次销售,所以不能使用 row_number ,要用 rank 或 dense_rank。老顾开始没有注意这个问题,一提交,结果是错误。。。郁闷咯。
select product_id,year first_year,quantity,price
from (
select s.*,rank() over(partition by product_id order by year) rid
from sales s
) a
where rid=1
order by sale_id
用别名的原因是,oracle 必须有别名,才能追加计算列。
当然,这个题目也有用 group + min(year) inner join 原表的方式来实现的办法,老顾就不写了。
1075. 项目员工 I
https://leetcode.cn/problems/project-employees-i/
分组求平均,这部分通用,然后,保留两位小数,这个问题需要各自解决了。
# oracle && mysql
select p.project_id,round(avg(e.experience_years),2) average_years
from project p
left join employee e on p.employee_id=e.employee_id
group by p.project_id
# mssql
select p.project_id,convert(decimal(38,2),avg(e.experience_years*1.0)) average_years
from project p
left join employee e on p.employee_id=e.employee_id
group by p.project_id
sqlserver 居然有超时的风险,然后发现 convert(float) 得到的结果,因精度问题,产生了不同的结果,只好老老实实的用 decimal 了
# mssql
select p.project_id,round(avg(convert(decimal(16,2),e.experience_years)),2) average_years
from project p
left join employee e on p.employee_id=e.employee_id
group by p.project_id
order by 1
1084. 销售分析III
https://leetcode.cn/problems/sales-analysis-iii/
日期类型数据计算,各自有各自的写法。
# mssql
select product_id,product_name
from product p
where exists(select 1 from sales where product_id=p.product_id and sale_date between '2019-1-1' and '2019-3-31')
and not exists(select 1 from sales where product_id=p.product_id and (sale_date < '2019-1-1' or sale_date>'2019-3-31'))
发现用 exists 和 not exists 速度有点慢,有超时风险,换个写法,直接一拖三。
select p.product_id,p.product_name
from product p
inner join sales s on p.product_id=s.product_id
group by p.product_id,p.product_name
having min(sale_date) >= '2019-1-1' and max(sale_date) < '2019-4-1'
小结
又是十个数据库题目,按顺序做下来,除了中间有一个用例错误的没有通过,其他还是没什么歧义的,大部分指令都能一拖三。
本次10个题目,有一半用到了分组聚合,熟悉一下这些题目,以后在工作中碰到了,也不会抓瞎了。以老顾实际在工作中碰到的情况,实际需要用 group 的地方并不多,多数都是统计数据才需要用到。
但是关联查询则用的太多太多了,毕竟为了减少数据的重复录入和数据不一致的情况,多数数据库结构,至少符合三范式要求,所以关联查询是不可避免的一个重头内容。
left join、right join、inner join 这三个使用的频率,基本上占日常业务的90% 以上了。掌握好关联查询,才是数据库查询的第一个热点。
至于说这些题目,有时候有超时风险,速度慢效率低,那是因为没有任何辅助优化措施,下次再碰到有超时风险的题目,老顾就直接建立索引,看看这些题目是否能支持起来。
好了,这次刷题就到这里,我们下次再见。