目录
一. Lambda表达式
1. 函数式编程思想概述
2. Lambda的优化
3. Lambda的格式
标准格式:
参数和返回值:
省略格式:
4. Lambda的前提条件
二. 函数式接口
1. 概述
格式
FunctionalInterface注解
2. 常用函数式接口
Supplier接口
Consumer接口
Function接口
Predicate接口
三. Stream流
1 引言
2. 流式思想概述
3. 获取流方式
4. 常用方法
forEach : 逐一处理
filter:过滤
count:统计个数
limit:取用前几个
skip:跳过前几个
concat:组合
四. 结论
一. Lambda表达式
1. 函数式编程思想概述

在数学中,函数就是有输入量、输出量的一套计算方案,也就是“拿什么东西做什么事情”。相对而言,面向对象过分强调“必须通过对象的形式来做事情”,而函数式思想则尽量忽略面向对象的复杂语法——强调做什么,而不是以什么形式做。
y = 2*x + 5;
函数式思想:
public class A {
public int method(int x) {
return 2*x + 5;
}
}
面向对象思想:
A a = new A();
int y = a.method(5);
java.util.Scanner类
Scanner sc = ...;
int num = sc.nextInt();
做什么,而不是怎么做
我们真的希望创建一个匿名内部类对象吗?不。我们只是为了做这件事情而不得不创建一个对象。我们真正希望做的事情是:将run方法体内的代码传递给Thread类知晓。
传递一段代码——这才是我们真正的目的。而创建对象只是受限于面向对象语法而不得不采取的一种手段方式。那,有没有更加简单的办法?如果我们将关注点从“怎么做”回归到“做什么”的本质上,就会发现只要能够更好地达到目的,过程与形式其实并不重要。
2. Lambda的优化
当需要启动一个线程去完成任务时,通常会通过java.lang.Runnable接口来定义任务内容,并使用java.lang.Thread类来启动该线程。
传统写法,代码如下:
public class Demo03Thread {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}).start();
}
}本着“一切皆对象”的思想,这种做法是无可厚非的:首先创建一个Runnable接口的匿名内部类对象来指定任务内容,再将其交给一个线程来启动。
代码分析:
对于Runnable的匿名内部类用法,可以分析出几点内容:
-
Thread类需要Runnable接口作为参数,其中的抽象run方法是用来指定线程任务内容的核心; -
为了指定
run的方法体,不得不需要Runnable接口的实现类; -
为了省去定义一个
RunnableImpl实现类的麻烦,不得不使用匿名内部类; -
必须覆盖重写抽象
run方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错; -
而实际上,似乎只有方法体才是关键所在。

Lambda表达式写法,代码如下:
借助Java 8的全新语法,上述Runnable接口的匿名内部类写法可以通过更简单的Lambda表达式达到等效:
public class Demo04LambdaRunnable {
public static void main(String[] args) {
new Thread(() -> System.out.println("多线程任务执行!")).start(); // 启动线程
}
}这段代码和刚才的执行效果是完全一样的,可以在1.8或更高的编译级别下通过。从代码的语义中可以看出:我们启动了一个线程,而线程任务的内容以一种更加简洁的形式被指定。
不再有“不得不创建接口对象”的束缚,不再有“抽象方法覆盖重写”的负担,就是这么简单!
3. Lambda的格式
标准格式:
Lambda省去面向对象的条条框框,格式由3个部分组成:
-
一些参数
-
一个箭头
-
一段代码
Lambda表达式的标准格式为:
(参数类型 参数名称) -> { 代码语句 }
格式说明:
-
小括号内的语法与传统方法参数列表一致:无参数则留空;多个参数则用逗号分隔。
-
->是新引入的语法格式,代表指向动作。 -
大括号内的语法与传统方法体要求基本一致。
匿名内部类与lambda对比:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}).start();仔细分析该代码中,Runnable接口只有一个run方法的定义:
-
public abstract void run();
即制定了一种做事情的方案(其实就是一个方法):
-
无参数:不需要任何条件即可执行该方案。
-
无返回值:该方案不产生任何结果。
-
代码块(方法体):该方案的具体执行步骤。
同样的语义体现在Lambda语法中,要更加简单:
() -> System.out.println("多线程任务执行!")
-
前面的一对小括号即
run方法的参数(无),代表不需要任何条件; -
中间的一个箭头代表将前面的参数传递给后面的代码;
-
后面的输出语句即业务逻辑代码。
参数和返回值:
下面举例演示java.util.Comparator<T>接口的使用场景代码,其中的抽象方法定义为:
-
public abstract int compare(T o1, T o2);
当需要对一个对象数组进行排序时,Arrays.sort方法需要一个Comparator接口实例来指定排序的规则。假设有一个Person类,含有String name和int age两个成员变量:
public class Person {
private String name;
private int age;
// 省略构造器、toString方法与Getter Setter
}传统写法
如果使用传统的代码对Person[]数组进行排序,写法如下:
public class Demo05Comparator {
public static void main(String[] args) {
// 本来年龄乱序的对象数组
Person[] array = { new Person("古力娜扎", 19), new Person("迪丽热巴", 18), new Person("马尔扎哈", 20) };
// 匿名内部类
Comparator<Person> comp = new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
};
Arrays.sort(array, comp); // 第二个参数为排序规则,即Comparator接口实例
for (Person person : array) {
System.out.println(person);
}
}
}这种做法在面向对象的思想中,似乎也是“理所当然”的。其中Comparator接口的实例(使用了匿名内部类)代表了“按照年龄从小到大”的排序规则。
代码分析
下面我们来搞清楚上述代码真正要做什么事情。
-
为了排序,
Arrays.sort方法需要排序规则,即Comparator接口的实例,抽象方法compare是关键; -
为了指定
compare的方法体,不得不需要Comparator接口的实现类; -
为了省去定义一个
ComparatorImpl实现类的麻烦,不得不使用匿名内部类; -
必须覆盖重写抽象
compare方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错; -
实际上,只有参数和方法体才是关键。
Lambda写法
public class Demo06ComparatorLambda {
public static void main(String[] args) {
Person[] array = {
new Person("古力娜扎", 19),
new Person("迪丽热巴", 18),
new Person("马尔扎哈", 20) };
Arrays.sort(array, (Person a, Person b) -> {
return a.getAge() - b.getAge();
});
for (Person person : array) {
System.out.println(person);
}
}
}省略格式:
省略规则
在Lambda标准格式的基础上,使用省略写法的规则为:
-
小括号内参数的类型可以省略;
-
如果小括号内有且仅有一个参数,则小括号可以省略;
-
如果大括号内有且仅有一个语句,则无论是否有返回值,都可以省略大括号、return关键字及语句分号。
备注:掌握这些省略规则后,请对应地回顾本章开头的多线程案例。
可推导即可省略
Lambda强调的是“做什么”而不是“怎么做”,所以凡是可以推导得知的信息,都可以省略。例如上例还可以使用Lambda的省略写法:
Runnable接口简化:
1. () -> System.out.println("多线程任务执行!")
Comparator接口简化:
2. Arrays.sort(array, (a, b) -> a.getAge() - b.getAge());
4. Lambda的前提条件
Lambda的语法非常简洁,完全没有面向对象复杂的束缚。但是使用时有几个问题需要特别注意:
-
使用Lambda必须具有接口,且要求接口中有且仅有一个抽象方法。 无论是JDK内置的
Runnable、Comparator接口还是自定义的接口,只有当接口中的抽象方法存在且唯一时,才可以使用Lambda。 -
使用Lambda必须具有接口作为方法参数。 也就是方法的参数或局部变量类型必须为Lambda对应的接口类型,才能使用Lambda作为该接口的实例。
备注:有且仅有一个抽象方法的接口,称为“函数式接口”。
注: Java 8 中 Lambda 表达式只允许捕获不可变变量的原因
# 说法一
局部变量在 Java 中是保存在栈上的,而不是堆上。每个线程都有自己的栈,因此局部变量仅限于其所在线程。这是因为局部变量的生命周期仅限于其所在的方法或代码块,当方法或代码块执行完成后,局部变量将被销毁。
由于局部变量仅限于其所在线程,因此在多线程编程中,局部变量被视为线程安全的。每个线程都有自己的栈,线程之间不会共享栈上的数据,因此不会出现线程安全问题。
Java8中Lambda表达式只允许捕获(使用)不可改变的局部变量,因为局部变量保存在栈上,并且隐式表示它们仅限于其所在线程。如果允许捕获可改变的局部变量,就会引发造成线程不安全的可能性,而这是我们不想看到的。(新的实例变量可以,因为它们保存在堆中,而堆是在线程之间共享的)
# 说法二
在 Java 8 中,Lambda 表达式允许使用外部变量。但是,使用 Lambda 表达式时,外部变量必须是有效的 final 或 effectively final。所谓 effectively final 是指变量值在 Lambda 表达式内部没有被修改。
有效 final 是指变量在声明后没有被重新赋值。这意味着您可以在 Lambda 表达式中访问变量的值,但不能修改它。这是因为 Lambda 表达式中捕获的变量实际上是变量的副本,而不是原始变量本身。如果变量是 final 的,则编译器可以保证变量的值不会发生变化,因此可以安全地在 Lambda 表达式中使用。
不遵守这个规则将会导致编译错误。
这个规则的目的是为了确保 Lambda 表达式中捕获的变量的值是不可变的,从而避免多线程并发访问变量时出现竞争条件。如果需要在 Lambda 表达式中修改变量的值,则可以使用可变变量(如数组或对象),或者使用 Atomic 变量来保证线程安全。
# 说法三
Java 8 中 Lambda 表达式只允许捕获不可变变量的原因是为了确保代码的线程安全性和可维护性。
如果 Lambda 表达式可以捕获可变变量,那么访问这些变量的值可能会在多个线程之间共享,从而引发竞态条件和线程安全问题。因此,为了避免这种情况,Lambda 表达式只能访问不可变变量。
此外,Lambda 表达式中使用的变量必须满足 effectively final 的要求,即变量在声明后没有被重新赋值。这样可以使代码更加清晰和易于理解,因为代码的读者可以更容易地理解变量的值不会在 Lambda 表达式中被改变。
对于可变变量,可以使用 Atomic 变量或其他线程安全的机制来保证线程安全性。但是,使用这些机制可能会增加代码的复杂性和维护成本。因此,建议在编写 Lambda 表达式时尽可能使用不可变变量,以保持代码的简洁性和可维护性。
二. 函数式接口
1. 概述
函数式接口在Java中是指:有且仅有一个抽象方法的接口。
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda,所以函数式接口就是可以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导。
备注:从应用层面来讲,Java中的Lambda可以看做是匿名内部类的简化格式,但是二者在原理上不同。
格式
只要确保接口中有且仅有一个抽象方法即可:
修饰符 interface 接口名称 {
public abstract 返回值类型 方法名称(可选参数信息);
// 其他非抽象方法内容
}
由于接口当中抽象方法的public abstract是可以省略的,所以定义一个函数式接口很简单:
public interface MyFunctionalInterface {
void myMethod();
}
FunctionalInterface注解
与@Override注解的作用类似,Java 8中专门为函数式接口引入了一个新的注解:@FunctionalInterface。该注解可用于一个接口的定义上:
@FunctionalInterface
public interface MyFunctionalInterface {
void myMethod();
}
2. 常用函数式接口
JDK提供了大量常用的函数式接口以丰富Lambda的典型使用场景,它们主要在java.util.function包中被提供。前文的MySupplier接口就是在模拟一个函数式接口:java.util.function.Supplier<T>。其实还有很多,下面是最简单的几个接口及使用示例。
Supplier接口
java.util.function.Supplier<T>接口,它意味着"供给" , 对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象数据。
抽象方法 : get
仅包含一个无参的方法:T get()。用来获取一个泛型参数指定类型的对象数据。
public class Demo08Supplier {
private static String getString(Supplier<String> function) {
return function.get();
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
System.out.println(getString(() -> msgA + msgB));
}
}求数组元素最大值
使用Supplier接口作为方法参数类型,通过Lambda表达式求出int数组中的最大值。提示:接口的泛型请使用java.lang.Integer类。
代码示例:
public class DemoIntArray {
public static void main(String[] args) {
int[] array = { 10, 20, 100, 30, 40, 50 };
printMax(() -> {
int max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max) {
max = array[i];
}
}
return max;
});
}
private static void printMax(Supplier<Integer> supplier) {
int max = supplier.get();
System.out.println(max);
}
}Consumer接口
java.util.function.Consumer<T>接口则正好相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型参数决定。
抽象方法:accept
Consumer接口中包含抽象方法void accept(T t),意为消费一个指定泛型的数据。基本使用如:
//给你一个字符串,请按照大写的方式进行消费
import java.util.function.Consumer;
public class Demo09Consumer {
public static void main(String[] args) {
String str = "Hello World";
//1.lambda表达式标准格式
fun(str,(String s)->{
System.out.println(s.toUpperCase());
});
//2.lambda表达式简化格式
fun(str,s-> System.out.println(s.toUpperCase()));
}
/*
定义方法,使用Consumer接口作为参数
fun方法: 消费一个String类型的变量
*/
public static void fun(String s,Consumer<String> con) {
con.accept(s);
}
}Function接口
java.util.function.Function<T,R>接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件,后者称为后置条件。有进有出,所以称为“函数Function”。
抽象方法:apply
Function接口中最主要的抽象方法为:R apply(T t),根据类型T的参数获取类型R的结果。使用的场景例如:将String类型转换为Integer类型。
//给你一个String的数字,你给我转成一个int数字
public class Demo11FunctionApply {
private static void method(Function<String, Integer> function, Str str) {
int num = function.apply(str);
System.out.println(num + 20);
}
public static void main(String[] args) {
method(s -> Integer.parseInt(s) , "10");
}
}Predicate接口
有时候我们需要对某种类型的数据进行判断,从而得到一个boolean值结果。这时可以使用java.util.function.Predicate<T>接口。
抽象方法:test
Predicate接口中包含一个抽象方法:boolean test(T t)。用于条件判断的场景,条件判断的标准是传入的Lambda表达式逻辑,只要字符串长度大于5则认为很长。
//1.练习:判断字符串长度是否大于5
//2.练习:判断字符串是否包含"H"
public class Demo15PredicateTest {
private static void method(Predicate<String> predicate,String str) {
boolean veryLong = predicate.test(str);
System.out.println("字符串很长吗:" + veryLong);
}
public static void main(String[] args) {
method(s -> s.length() > 5, "HelloWorld");
}
}三. Stream流
在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。
1 引言
传统集合的多步遍历代码
几乎所有的集合(如Collection接口或Map接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如:
public class Demo10ForEach {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
for (String name : list) {
System.out.println(name);
}
}
}这是一段非常简单的集合遍历操作:对集合中的每一个字符串都进行打印输出操作。
循环遍历的弊端
Java 8的Lambda让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
-
for循环的语法就是“怎么做”
-
for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
-
将集合A根据条件一过滤为子集B;
-
然后再根据条件二过滤为子集C。
那怎么办?在Java 8之前的做法可能为:
这段代码中含有三个循环,每一个作用不同:
-
首先筛选所有姓张的人;
-
然后筛选名字有三个字的人;
-
最后进行对结果进行打印输出。
public class Demo11NormalFilter {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if (name.startsWith("张")) {
zhangList.add(name);
}
}
List<String> shortList = new ArrayList<>();
for (String name : zhangList) {
if (name.length() == 3) {
shortList.add(name);
}
}
for (String name : shortList) {
System.out.println(name);
}
}
}每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
那,Lambda的衍生物Stream能给我们带来怎样更加优雅的写法呢?
Stream的更优写法
下面来看一下借助Java 8的Stream API,什么才叫优雅:
public class Demo12StreamFilter {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(s -> System.out.println(s));
}
}2. 流式思想概述
注意:请暂时忘记对传统IO流的固有印象!
整体来看,流式思想类似于工厂车间的“生产流水线”。

当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它。
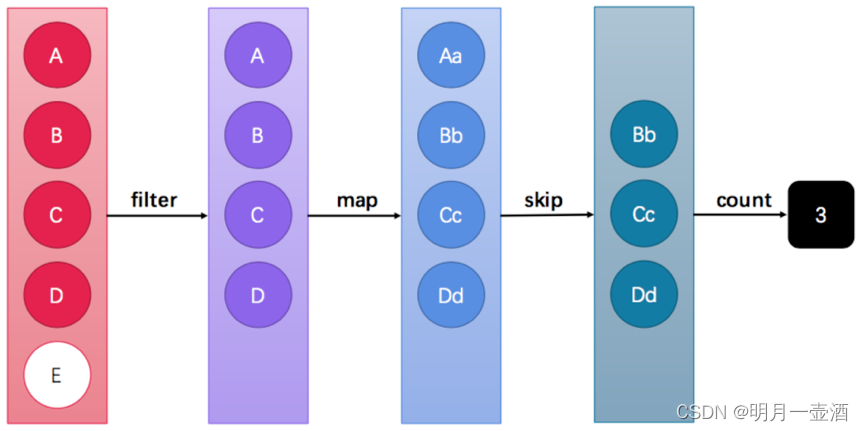
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字3是最终结果。
这里的filter、map、skip都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法count执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性。
备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
3. 获取流方式
java.util.stream.Stream<T>是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)
获取一个流非常简单,有以下几种常用的方式:
-
所有的
Collection集合都可以通过stream默认方法获取流; -
Stream接口的静态方法of可以获取数组对应的流。
方式1 : 根据Collection获取流
public default Stream<E> stream(): 获取Collection集合对象对应的Stream流对象
首先,java.util.Collection接口中加入了default方法stream用来获取流,所以其所有实现类均可获取流。
import java.util.*;
import java.util.stream.Stream;
/*
获取Stream流的方式
1.Collection中 方法
Stream stream()
2.Stream接口 中静态方法
of(T...t) 向Stream中添加多个数据
*/
public class Demo13GetStream {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// ...
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
// ...
Stream<String> stream2 = set.stream();
}
}方式2: 根据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以Stream接口中提供了静态方法of,使用很简单:
import java.util.stream.Stream;
public class Demo14GetStream {
public static void main(String[] args) {
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
}
}备注:
of方法的参数其实是一个可变参数,所以支持数组。
4. 常用方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
-
终结方法:返回值类型不再是
Stream接口自身类型的方法,因此不再支持类似StringBuilder那样的链式调用。本小节中,终结方法包括count和forEach方法。 -
非终结方法:返回值类型仍然是
Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
备注:本小节之外的更多方法,请自行参考API文档。
forEach : 逐一处理
虽然方法名字叫forEach,但是与for循环中的“for-each”昵称不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的。
void forEach(Consumer<? super T> action);
该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。例如:
import java.util.stream.Stream;
public class Demo15StreamForEach {
public static void main(String[] args) {
Stream<String> stream = Stream.of("大娃","二娃","三娃","四娃","五娃","六娃","七娃","爷爷","蛇精","蝎子精");
//Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若");
stream.forEach((String str)->{System.out.println(str);});
}
}在这里,lambda表达式(String str)->{System.out.println(str);}就是一个Consumer函数式接口的示例。
filter:过滤
可以通过filter方法将一个流转换成另一个子集流。方法声明:
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个Predicate函数式接口参数(可以是一个Lambda)作为筛选条件。
基本使用
Stream流中的filter方法基本使用的代码如:
public class Demo16StreamFilter {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter((String s) -> {return s.startsWith("张");});
}
}在这里通过Lambda表达式来指定了筛选的条件:必须姓张。
count:统计个数
正如旧集合Collection当中的size方法一样,流提供count方法来数一数其中的元素个数:
long count();
该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。基本使用:
public class Demo17StreamCount {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s -> s.startsWith("张"));
System.out.println(result.count()); // 2
}
}limit:取用前几个
limit方法可以对流进行截取,只取用前n个。方法签名:
Stream<T> limit(long n):获取Stream流对象中的前n个元素,返回一个新的Stream流对象
参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用:
import java.util.stream.Stream;
public class Demo18StreamLimit {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.limit(2);
System.out.println(result.count()); // 2
}
}skip:跳过前几个
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流:
Stream<T> skip(long n): 跳过Stream流对象中的前n个元素,返回一个新的Stream流对象
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
import java.util.stream.Stream;
public class Demo19StreamSkip {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.skip(2);
System.out.println(result.count()); // 1
}
}concat:组合
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat:
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b): 把参数列表中的两个Stream流对象a和b,合并成一个新的Stream流对象
备注:这是一个静态方法,与
java.lang.String当中的concat方法是不同的。
该方法的基本使用代码如:
import java.util.stream.Stream;
public class Demo20StreamConcat {
public static void main(String[] args) {
Stream<String> streamA = Stream.of("张无忌");
Stream<String> streamB = Stream.of("张翠山");
Stream<String> result = Stream.concat(streamA, streamB);
}
}四. 结论
- 可以说 Lambda 表达式是函数式编程语言的一种附属品,在 Java 中被引入是为了提高 Java 语言的灵活性和表达能力,更好地支持函数式编程的概念
- Lambda 表达式的本质是一种匿名函数,它可以作为方法参数传递,或者作为函数式接口的实例使用,近而实现函数式编程的概念。从而实现更加简洁、高效和易读的代码。
- 函数式接口、Stream API、方法引用等特性,与 Lambda 表达式一起构成了 Java 8 函数式编程的核心内容。
- Lambda 表达式和 Stream API 是相互关联的,Lambda 表达式提供了实现 Stream API 中各种操作的方式
- Lambda 表达式是 Java 8 中支持函数式编程的核心特性之一,而函数式接口则是支持 Lambda 表达式的重要前提。
- Stream 和函数式接口是密切相关的。Stream API 提供了一组函数式接口,这些接口可以用于操作集合数据,使得代码更加简洁和易于理解。同时,函数式接口也是 Stream API 的基础,Stream API 中的很多操作都是基于函数式接口实现的。