文章目录
- Dynamic Focus-aware Positional Queries for Semantic Segmentation
- 摘要
- 本文方法
- Dynamic Focus-aware Positional Queries
- Efficient High-resolution Cross-attention
- Focus-aware Segmentation Framework
- 实验结果
Dynamic Focus-aware Positional Queries for Semantic Segmentation
摘要
类似DETR的分割器支持了语义分割方面的最新突破,即端到端地训练一组表示类原型或目标分割的查询。最近,为了更容易优化,提出了mask注意力来限制每个查询仅关注由先前解码器块预测的前景区域。尽管很有前途,但它依赖于可学习的参数化位置查询,这些查询往往会对数据集统计信息进行编码,导致不同的单个查询的定位不准确。
本文方法
- 提出了一种用于语义分割的简单而有效的查询设计,称为动态焦点感知位置查询(DFPQ),该查询基于先前解码器块的交叉注意力得分和相应图像特征的位置编码同时动态生成位置查询。
- DFPQ为目标分割保留了丰富的定位信息,并提供了准确和细粒度的位置先验。
- 仅基于低分辨率交叉注意力分数聚合上下文token来执行局部关系聚合,来有效地处理高分辨率交叉注意力。
代码地址
本文方法
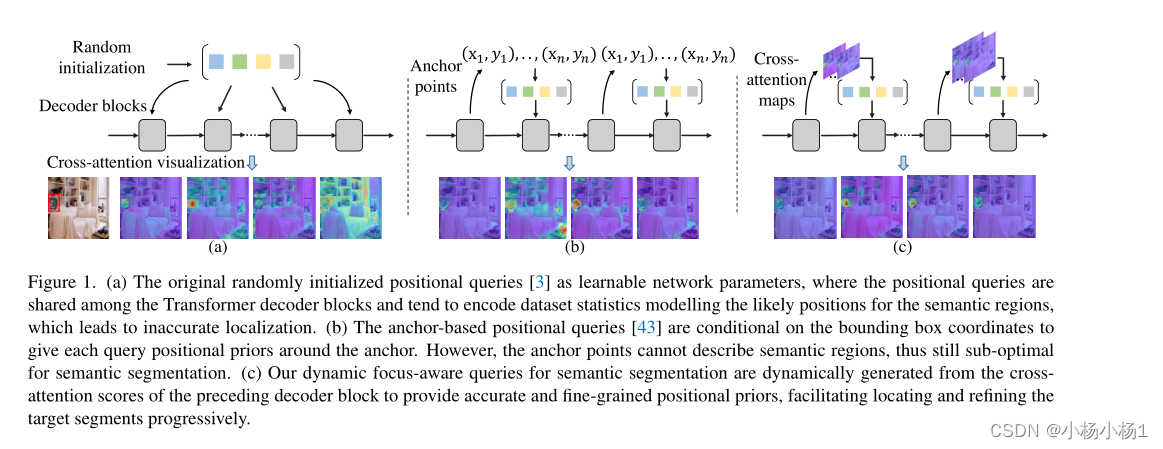
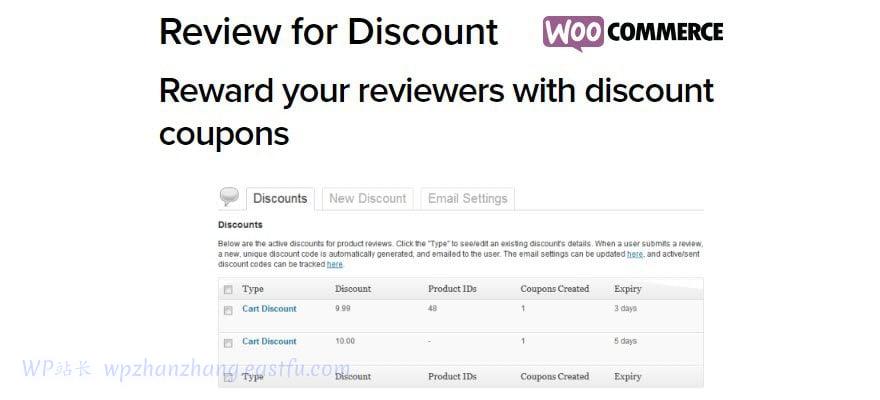
(a) 原始随机初始化的位置查询作为可学习的网络参数,其中位置查询在Transformer解码器块之间共享,并且倾向于对建模语义区域的可能位置的数据集统计进行编码,这导致不准确的定位。
(b) 基于锚点的位置查询以边界框坐标为条件,以给出每个查询围绕锚点的位置先验。然而,锚点不能描述语义区域,因此对于语义分割来说仍然是次优的。
(c) 我们用于语义分割的动态焦点感知查询是根据先前解码器块的交叉注意力分数动态生成的,以提供准确和细粒度的位置先验,从而有助于逐步定位和细化目标片段。
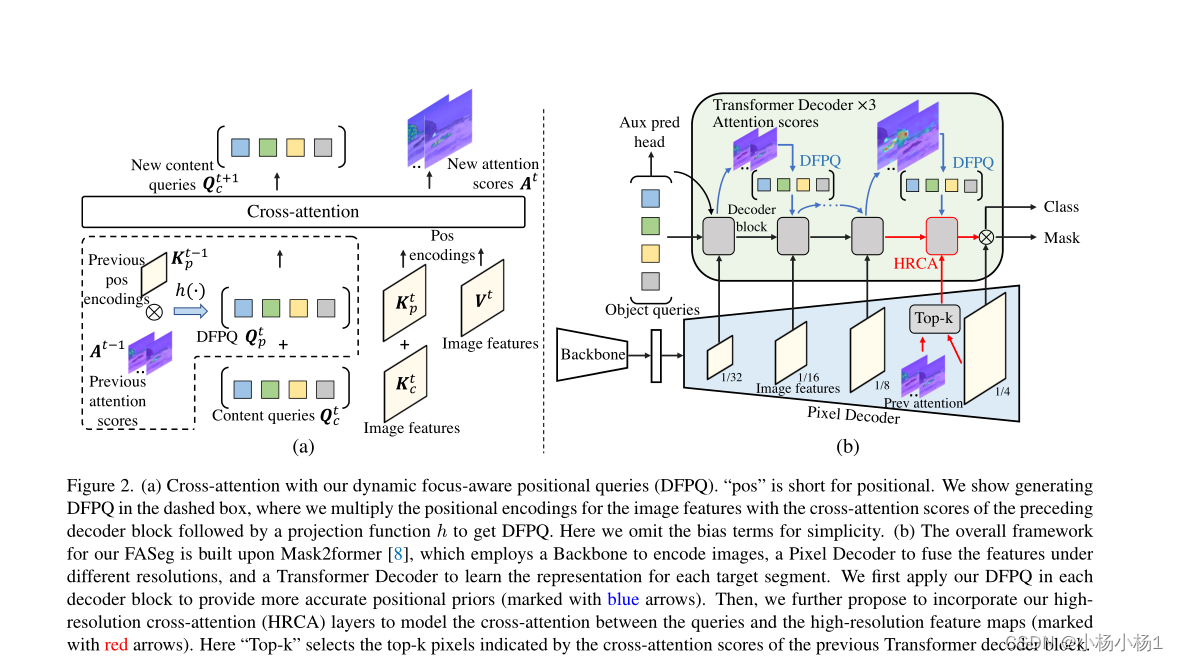
(a) 我们的动态焦点感知位置查询(DFPQ)交叉注意力。“pos”是位置的缩写。我们在虚线框中显示了生成DFPQ,其中我们将图像特征的位置编码与前一解码器块的交叉注意力分数相乘,然后是投影函数h,以获得DFPQ。为了简单起见,这里我们省略了偏项。
(b) 我们的FASeg的总体框架建立在Mask2former的基础上,它使用主干对图像进行编码,使用像素解码器融合不同分辨率下的特征,使用变换器解码器学习每个目标片段的表示。我们首先在每个解码器块中应用我们的DFPQ,以提供更准确的位置先验(用蓝色箭头标记)。然后,我们进一步建议结合我们的高分辨率交叉注意力(HRCA)层来对查询和高分辨率特征图(用红色箭头标记)之间的交叉注意力进行建模。
这里,“Top-k”选择由前一个Transformer解码器块的交叉注意力分数指示的前k个像素。
交叉注意力:
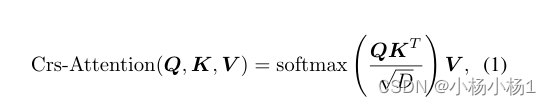
Q和K都是由图像特征和位置编码组成
V为图像特征
Dynamic Focus-aware Positional Queries
在这项工作中,我们的目标是开发位置查询,在类似DETR的语义分割框架下提供有效的位置先验。我们认为,以交叉注意力得分为条件生成位置查询有三个好的性质。首先,交叉注意力得分指示具有丰富上下文的区域,并且可以直接反映目标片段的定位信息。因此,当在类似DETR的框架中堆叠具有交叉关注层的几个解码器块时,前一块中的定位信息有助于在后一块中逐步定位目标片段,特别是当块处理不同尺度的特征时。
其次,交叉注意力得分是动态生成的。与作为可学习参数的内容不可知的位置查询不同,后者倾向于对整个数据集的统计数据进行编码,并限制模型的泛化能力,交叉注意力得分是以反映特定上下文位置的每个目标片段为条件的,因此更准确。最后,交叉注意力得分可以覆盖细粒度的分割细节、边缘和边界,而不是只对单个中心或锚点进行编码
因此,我们建议同时根据前一解码器块的交叉注意力得分和相应图像特征的位置编码来生成位置查询,如图2(a)所示。具体地说,由于图像特征的位置编码Kp保留了位置信息,我们通过聚集Kp来形成我们的DFPQ,如前一解码器块的交叉关注层中的交叉关注分数A所示,其可以公式化为
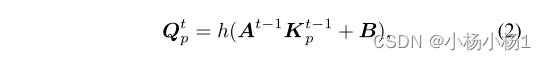
通过这种方式,我们动态生成DFPQ,以提供目标片段的位置先验。它还可以覆盖不受锚点限制的细粒度分割提示。
Efficient High-resolution Cross-attention
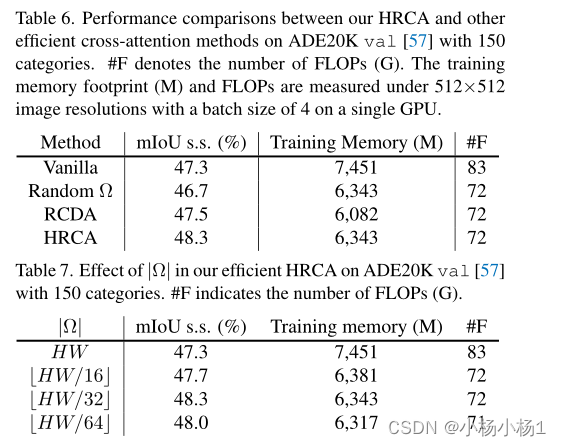
如现有技术所证明的,高分辨率图像特征对于分割小区域是重要的。然而,对对象查询和高分辨率图像特征之间的交叉关注进行建模需要大量的内存占用和计算成本。在这种情况下,我们提出了一种高效的高分辨率交叉注意(HRCA)层,以从高分辨率特征图中挖掘细节,并承担合理的内存负担。具体而言,我们首先从所有对象查询的交叉注意力得分最高的低分辨率图像特征中选择前k个像素。然后,我们以自上而下的方式将这些区域映射到高分辨率特征图位置,并仅对这些位置进行交叉关注。
形式上,我们首先得到低分辨率的交叉注意力得分Al,然后通过双线性上采样操作f(·)导出其高分辨率对应值Ah=f(Al)。接下来,我们将Ah中得分最高的前k个像素纳入集合Ω, 有效的HRCA可以公式化为
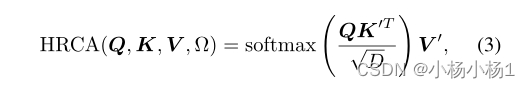
我们的HRCA与以前的稀疏注意力方法密切相关,这些方法只关注整个序列的一部分。不同的是,我们的HRCA专门用于类似DETR的框架,该框架根据信息像素对目标片段的贡献而不是其他像素来确定信息像素。与我们的HRCA类似的一项工作是RCDA模块,这是一种具有代表性的稀疏交叉注意力方法,将交叉注意力解耦为行和列注意力,以降低内存和计算成本。
Focus-aware Segmentation Framework
们通过简单地结合我们的DFPQ和HRCA,在Mask2former框架上开发了我们的FASeg。我们的FASeg概述如图2(b)所示。我们首先为具有DFPQ的Mask2former提供了更准确和细粒度的位置先验。我们在每个解码器块的交叉关注层中应用DFPQ,以提供良好的位置先验,用于聚合上下文图像特征以定位目标片段。以这种方式,随着我们在解码器块中深入,我们逐渐地定位目标片段。由于在第一个Transformer解码器块之前没有交叉关注分数,我们通过对来自辅助预测头的预测前景掩码执行平均池化来获得第一个块的DFPQ。
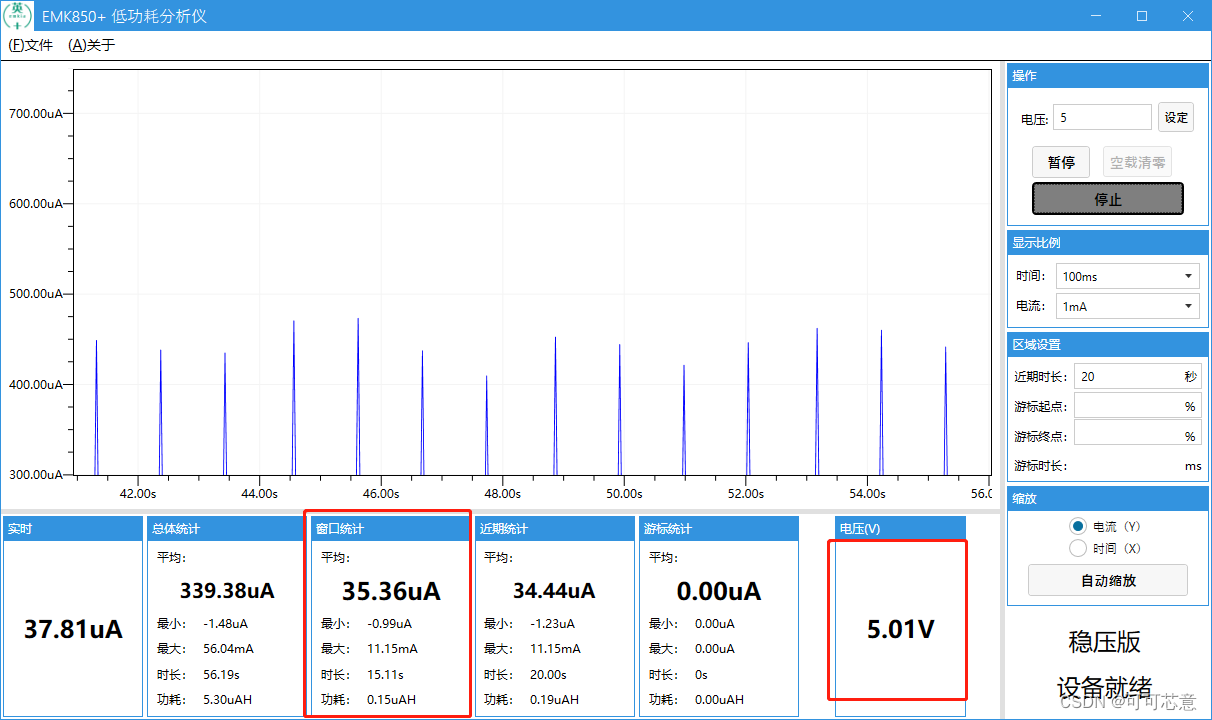
接下来,我们使用HRCA(第3.3节)来丰富分割细节,使其具有可承受的峰值时间内存占用和计算复杂性。在级联的三个解码器块之后,我们添加了配备有HRCA的第四个解码器块,以自上而下的方式对高分辨率特征图上的交叉注意力进行建模。通过两个简单的修改,我们的FASeg比原来的Mask2former获得了稳定的性能增益
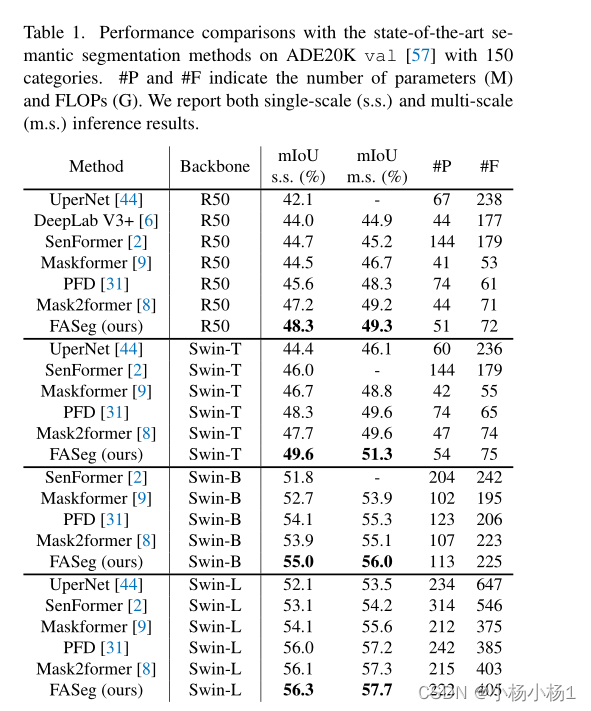
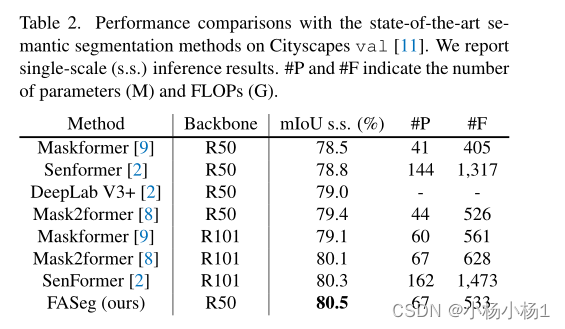
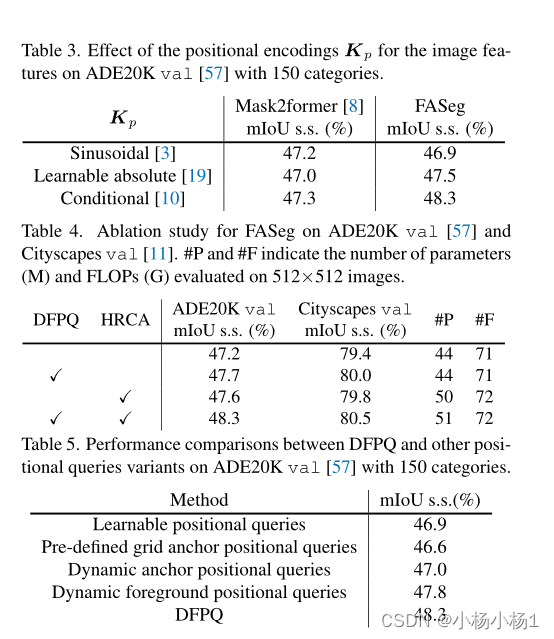
实验结果