tip:作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。
💕💕 推荐:体系化学习Java(Java面试专题)
文章目录
- 1、什么是一致性 Hash 算法
- 2、一致性 Hash 算法详解
- 2.1、Hash 环
- 2.2、增删节点
- 2.3、不平衡问题
- 2.4、虚拟节点
- 3、一致性 Hash 算法的应用
1、什么是一致性 Hash 算法
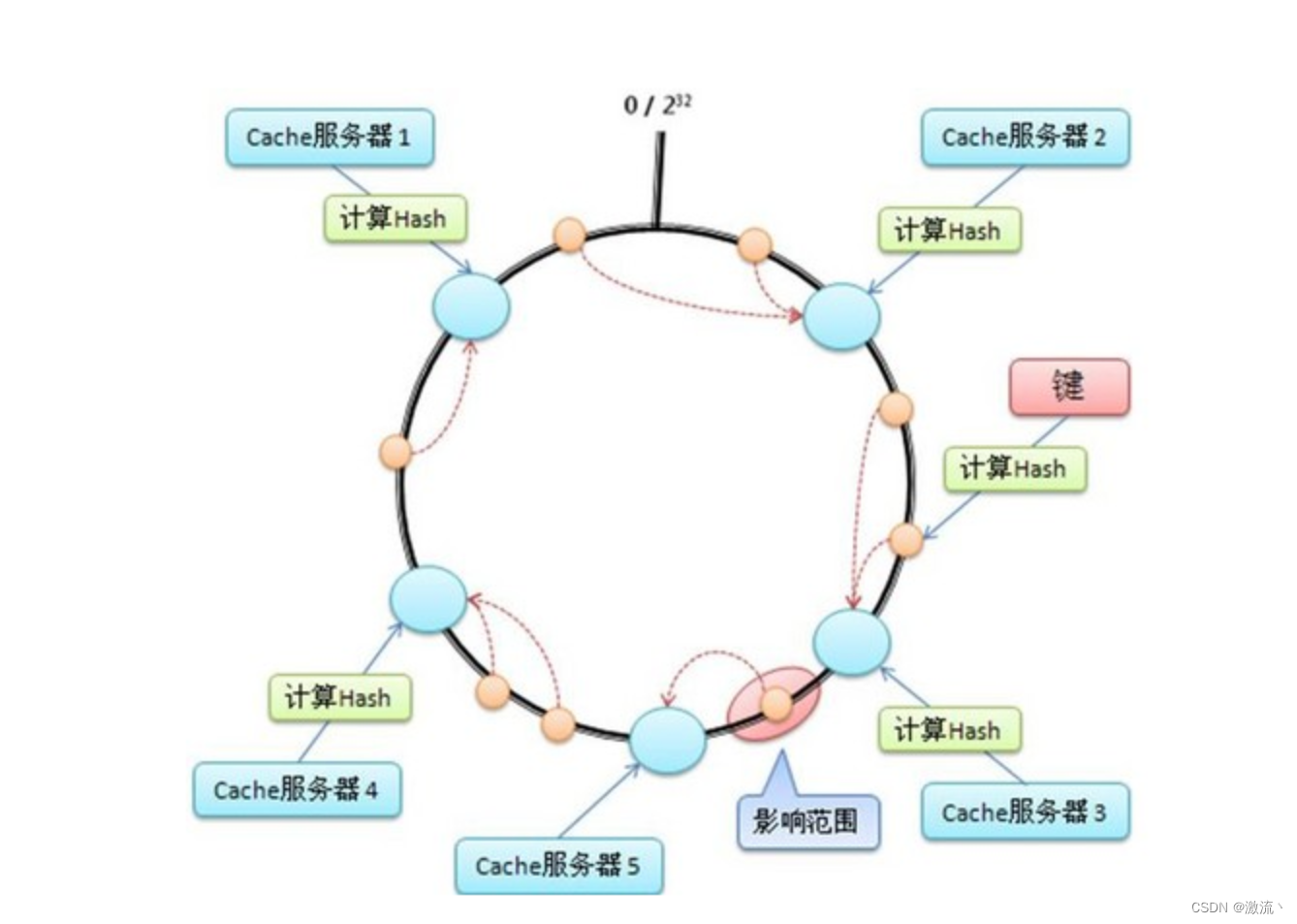
一致性哈希算法(Consistent Hashing)是一种分布式哈希算法,用于在分布式系统中解决节点动态变化带来的数据迁移问题。在一致性哈希算法中,哈希值的范围是一个环形空间,每个节点在环上占据一个位置,数据的哈希值也映射到环上,然后按照顺时针方向找到第一个节点,将数据存储在该节点上。当节点动态变化时,只需要对受影响的数据进行重新哈希,将其映射到新的节点上即可,无需对整个数据集进行重新分配。这种方式可以有效地减少数据迁移的开销,提高系统的可扩展性和稳定性。
2、一致性 Hash 算法详解
一致性哈希算法包含以下内容:
-
哈希环: 将数据的键值哈希到一个固定的范围内,通常是一个环形空间。
-
节点: 将节点的标识符哈希到环形空间上的一个位置,每个节点在环上占据一个位置。
-
数据分布: 将数据的键值哈希到环形空间上的一个位置,然后按照顺时针方向找到第一个节点,将数据存储在该节点上。
-
节点动态变化: 当节点动态变化时,只需要对受影响的数据进行重新哈希,将其映射到新的节点上即可,无需对整个数据集进行重新分配。
-
负载均衡: 由于节点在环上均匀分布,因此可以实现负载均衡,将数据均匀地分布在不同的节点上,避免单个节点的负载过高。
-
容错性: 由于节点在环上均匀分布,当某个节点发生故障时,只会影响其前一个节点到故障节点之间的数据,其他数据不会受到影响。
一致性哈希算法通过将数据的键值和节点的标识符映射到同一个环形空间上,实现了数据分布和负载均衡,并且具有良好的容错性和可扩展性。
2.1、Hash 环
哈希环(Hash Ring)是一种数据结构,通常用于实现一致性哈希算法。哈希环是一个环形结构,其中每个节点表示一个哈希值,节点按照哈希值的大小顺序排列,形成一个环。当需要将数据映射到节点时,可以通过哈希函数计算数据的哈希值,然后在哈希环上找到第一个大于等于该哈希值的节点,将数据映射到该节点上。
以下是自己手写一个 Hash 环的代码:
package com.pany.camp.algorithm;
import java.util.*;
/**
*
* @description: Hash 环
* @copyright: @Copyright (c) 2022
* @company: Aiocloud
* @author: pany
* @version: 1.0.0
* @createTime: 2023-06-09 12:58
*/
public class HashRing<T> {
private final TreeMap<Integer, T> ring = new TreeMap<>();
private final HashFunction hashFunction;
public HashRing(Collection<T> nodes, HashFunction hashFunction) {
this.hashFunction = hashFunction;
for (T node : nodes) {
addNode(node);
}
}
public void addNode(T node) {
for (int i = 0; i < 3; i++) { // 每个节点在哈希环上占据 3 个位置,增加数据的分布均匀性
int hash = hashFunction.hash(node.toString() + i);
ring.put(hash, node);
}
}
public void removeNode(T node) {
for (int i = 0; i < 3; i++) {
int hash = hashFunction.hash(node.toString() + i);
ring.remove(hash);
}
}
public T getNode(String key) {
if (ring.isEmpty()) {
return null;
}
int hash = hashFunction.hash(key);
if (!ring.containsKey(hash)) {
Map.Entry<Integer, T> entry = ring.ceilingEntry(hash);
if (entry == null) {
entry = ring.firstEntry();
}
return entry.getValue();
}
return ring.get(hash);
}
public interface HashFunction {
int hash(String key);
}
}
根据 Hash 环,举个一个负载均衡的例子。LoadBalancer 类封装了一个 HashRing 对象,用于存储服务器节点。构造函数中需要传入服务器集合,getServer 方法用于将请求映射到服务器节点上。在 main 方法中,创建一个 LoadBalancer 对象,然后循环发送 10 个请求,将请求映射到不同的服务器上。由于 HashRing 实现了一致性哈希算法,因此可以保证请求的负载均衡性。
package com.pany.camp.algorithm;
import java.util.*;
/**
*
* @description: 负载均衡
* @copyright: @Copyright (c) 2022
* @company: Aiocloud
* @author: pany
* @version: 1.0.0
* @createTime: 2023-06-09 12:58
*/
public class LoadBalancer {
private final HashRing<String> serverRing;
public LoadBalancer(Collection<String> servers) {
serverRing = new HashRing<>(servers, key -> Math.abs(key.hashCode()));
}
public String getServer(String request) {
return serverRing.getNode(request);
}
public static void main(String[] args) {
List<String> servers = Arrays.asList("server1", "server2", "server3");
LoadBalancer lb = new LoadBalancer(servers);
for (int i = 0; i < 10; i++) {
String request = "request" + i;
String server = lb.getServer(request);
System.out.println("Request " + request + " is sent to server " + server);
}
}
}
2.2、增删节点
根据上面的 HashRing 解释一致性哈希算法的增删节点逻辑:
-
添加节点
添加节点时,需要计算节点的哈希值,并将其添加到哈希环上。在 HashRing 中,可以通过 addNode 方法来添加节点。该方法首先计算节点的哈希值,然后将其添加到哈希环上。如果节点已经存在,则不会进行任何操作。通常情况下,每个节点会在哈希环上占据多个位置,以增加数据的分布均匀性。在 HashRing 中,可以通过 replicaCount 参数来指定每个节点在哈希环上占据的位置数。 -
删除节点
删除节点时,需要将节点从哈希环上删除。在 HashRing 中,可以通过 removeNode 方法来删除节点。该方法首先计算节点的哈希值,然后将其从哈希环上删除。如果节点不存在,则不会进行任何操作。 -
查找节点
查找节点时,需要先计算数据的哈希值,然后在哈希环上找到第一个大于等于该哈希值的节点,将数据映射到该节点上。如果不存在该节点,则取哈希环上最小的节点。在 HashRing 中,可以通过 getNode 方法来查找节点。该方法首先计算数据的哈希值,然后在哈希环上查找第一个大于等于该哈希值的节点。如果找不到该节点,则返回哈希环上最小的节点。
需要注意的是,当添加或删除节点时,可能会导致某些数据映射到新的节点上,从而需要重新分配数据。为了减少数据的迁移量,可以使用虚拟节点(也称为虚拟哈希环)来增加节点数量,从而使得每个节点在哈希环上占据更多的位置。在 HashRing 中,可以通过虚拟节点来实现。具体来说,可以为每个节点分配多个虚拟节点,然后将虚拟节点添加到哈希环上。这样,当添加或删除节点时,只需要重新分配少量的数据即可。
2.3、不平衡问题
一致性哈希算法的不平衡问题主要是由于节点数量过少或者节点分布不均匀所导致的。当节点数量较少时,可能会出现节点分布不均匀的情况,从而导致某些节点负载过重,而其他节点负载较轻。当节点分布不均匀时,可能会出现数据倾斜的情况,从而导致某些节点存储的数据过多,而其他节点存储的数据过少。
为了解决这个问题,可以采取以下措施:
-
增加节点数量
增加节点数量可以增加哈希环上的节点数量,从而使得数据分布更加均匀。通常情况下,节点数量应该足够多,以保证数据分布的均匀性。 -
使用虚拟节点
使用虚拟节点可以增加节点数量,从而使得每个节点在哈希环上占据更多的位置。这样可以减少数据的倾斜程度,从而提高负载均衡性。在 HashRing 中,可以通过虚拟节点来实现。 -
负载均衡策略
可以采用更加智能的负载均衡策略,例如基于节点负载情况的动态负载均衡策略。这样可以使得节点的负载更加均衡,从而提高系统的性能和可靠性。
2.4、虚拟节点
在一致性哈希算法中,虚拟节点是指将一个物理节点映射到多个虚拟节点上的技术。通过将一个物理节点映射到多个虚拟节点上,可以增加节点在哈希环上的占据位置,从而使得数据分布更加均匀。虚拟节点的数量可以根据需要进行调整,通常情况下,虚拟节点的数量要足够多,以保证数据分布的均匀性。
例如,在一个有 3 个物理节点的哈希环中,每个物理节点可以映射到 5 个虚拟节点上,这样总共就会有 15 个虚拟节点。当需要将一个数据存储到哈希环上时,首先需要计算该数据的哈希值,然后将其映射到离其最近的虚拟节点上。由于每个物理节点在哈希环上占据了多个虚拟节点的位置,因此可以使得数据分布更加均匀,从而提高负载均衡性。
虚拟节点的实现可以通过在哈希值的计算过程中,将物理节点和虚拟节点一起计算。在 HashRing 中,可以通过传递一个计算虚拟节点数量的函数来实现虚拟节点的功能。具体而言,计算虚拟节点数量的函数可以将物理节点和虚拟节点的编号拼接在一起,然后计算它们的哈希值。这样就可以将一个物理节点映射到多个虚拟节点上。
3、一致性 Hash 算法的应用
一致性哈希算法是一种常用的分布式算法,它在很多分布式系统和应用中得到了广泛的应用,下面介绍一些常见的应用场景:
-
分布式缓存
一致性哈希算法被广泛应用于分布式缓存系统中,如 Memcached、Redis 等。在分布式缓存系统中,数据通常会被分散到多个缓存节点上,而一致性哈希算法可以有效地将数据均匀地分布到各个缓存节点上,从而提高缓存系统的性能和可扩展性。 -
负载均衡
一致性哈希算法也可以用于负载均衡系统中,如 HTTP 负载均衡、DNS 负载均衡等。在负载均衡系统中,一致性哈希算法可
以将请求均匀地分发到多个服务器上,从而提高系统的负载均衡性和可扩展性。 -
分布式数据库
一致性哈希算法也可以用于分布式数据库系统中,如 Cassandra、MongoDB 等。在分布式数据库系统中,数据通常会被分散到多个节点上,而一致性哈希算法可以将数据均匀地分布到各个节点上,从而提高数据的可用性和可扩展性。 -
分布式文件系统
一致性哈希算法也可以用于分布式文件系统中,如 HDFS、GlusterFS 等。在分布式文件系统中,文件通常会被分散到多个
节点上,而一致性哈希算法可以将文件均匀地分布到各个节点上,从而提高文件系统的性能和可扩展性。
总之,一致性哈希算法是一种非常实用的分布式算法,可以在很多分布式系统和应用中发挥重要作用。
💕💕 本文由激流原创,首发于CSDN博客,博客主页 https://blog.csdn.net/qq_37967783?spm=1010.2135.3001.5421
💕💕喜欢的话记得点赞收藏啊