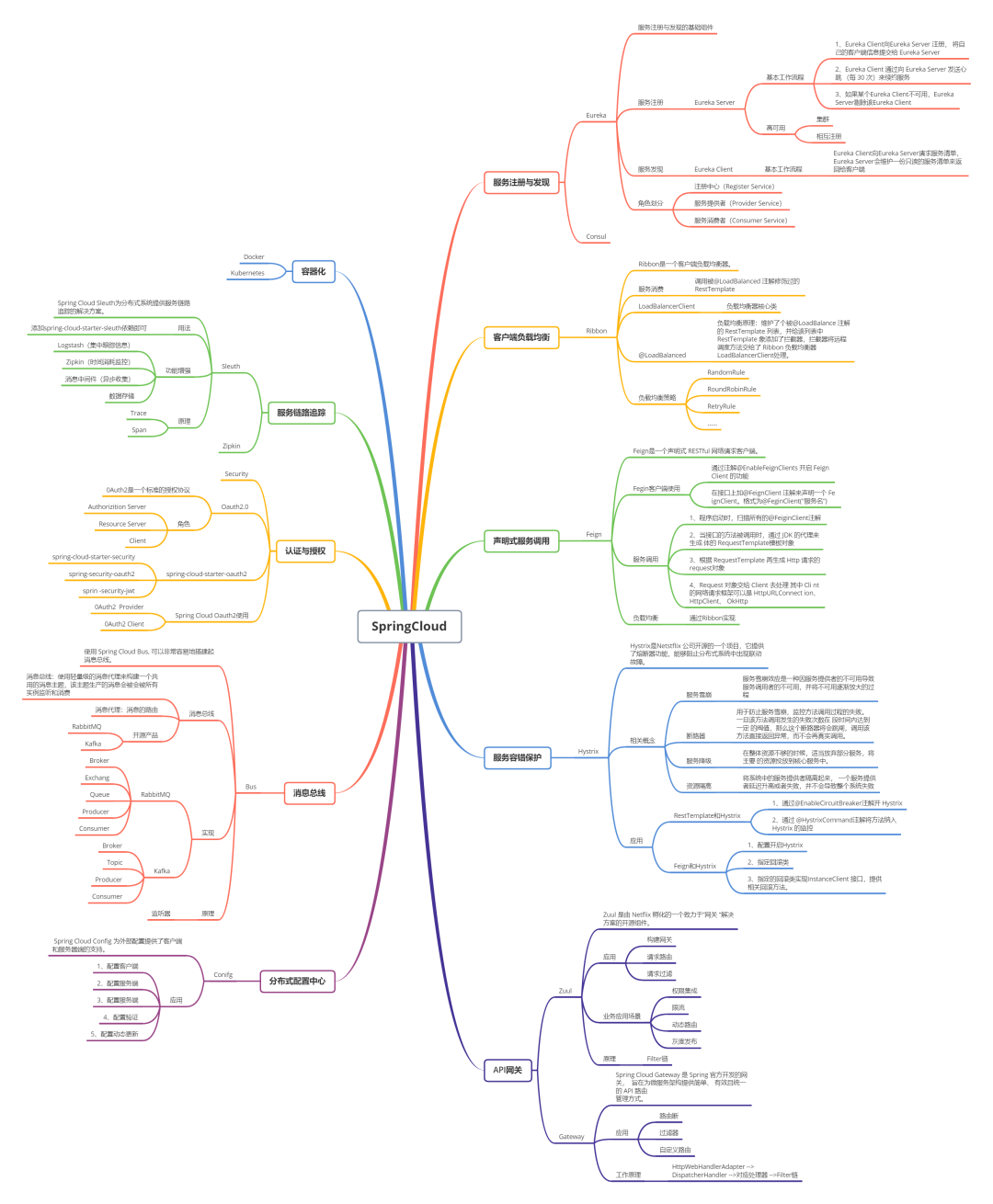
作者 | Python
自从推出以来,ChatGPT这款智能高效的人机对话平台迅速风靡全球。人们开始广泛尝试使用ChatGPT来解决各种问题,无论是医学检测报告的解释,还是公众号文章的取名,甚至是论文修改润色和rebuttal撰写等,ChatGPT等大型模型都活跃其中。其强大的语言生成和理解能力为人们提供了全新的工具和资源,使得各种任务的处理更加高效和便捷。
同时,许多自然语言处理领域的研究人员也感到困惑和苦恼。他们觉得传统的NLP研究方向,如问答、对话、翻译、信息抽取、文本语义与推理、知识图谱等已经失去了原本的意义。因为大型模型的出现,仅仅通过增加模型的规模和参数量,就能在自然语言处理领域中取得惊人的成就,成为解决一些任务的银弹。
诚然,大模型的高计算量必然会抬高自然语言处理的门槛。但就如同CNN/LSTM之于SVM,BERT之于CNN/LSTM一样,是人工智能领域发展的必然趋势。然而,另一方面,大模型真的是多任务通吃么?针对特定任务的模型就没有价值了么?近期的一些研究工作给出的证据表明,大模型并非一劳永逸的解法,像BERT在下游任务上做的各种精调和网络结构设计一样,大模型也需要根据任务特点做调整。
大模型的能力可能被高估
大模型虽然在很多任务中表现很好,但部分超绝的表现可能只是源于其训练数据与任务数据有所重叠造成的数据泄露。
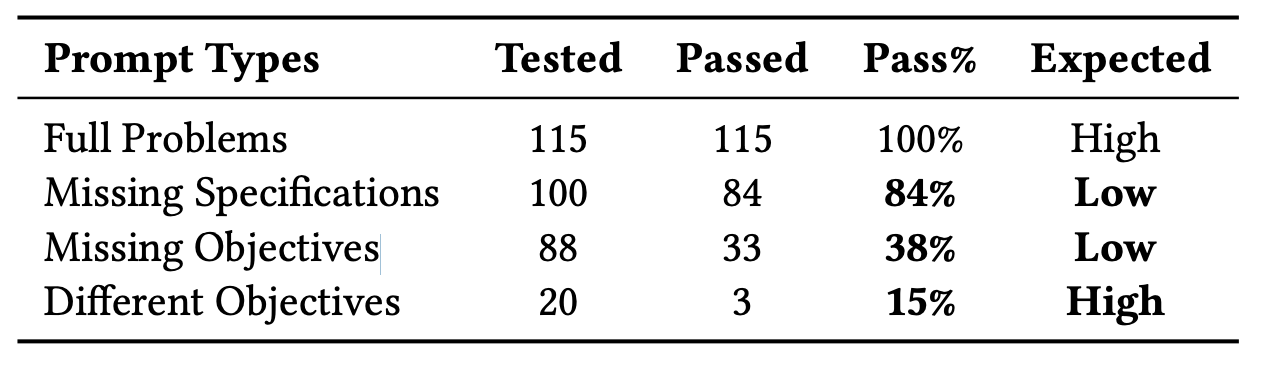
比如[1]分析Codex(ChatGPT的前身之一),得到了如下表的结果。对于一道HackerRank上的编程题,如果把任务描述,或任务目标去掉之后,Codex依然可以取得很好的效果,然而如果仅仅替换任务目标,效果就会差很多。这表明Codex的效果可能依赖于对训练语料的记忆。
这一点,我们自己试用ChatGPT时也能很容易验证。比如直接问一道leetcode题目的解法,只给题号,ChatGPT也知道题目内容。

最近的一些研究表明,包括中文高考题[2],较难的代码生成在内[3],都难以被ChatGPT、GPT-4解决。
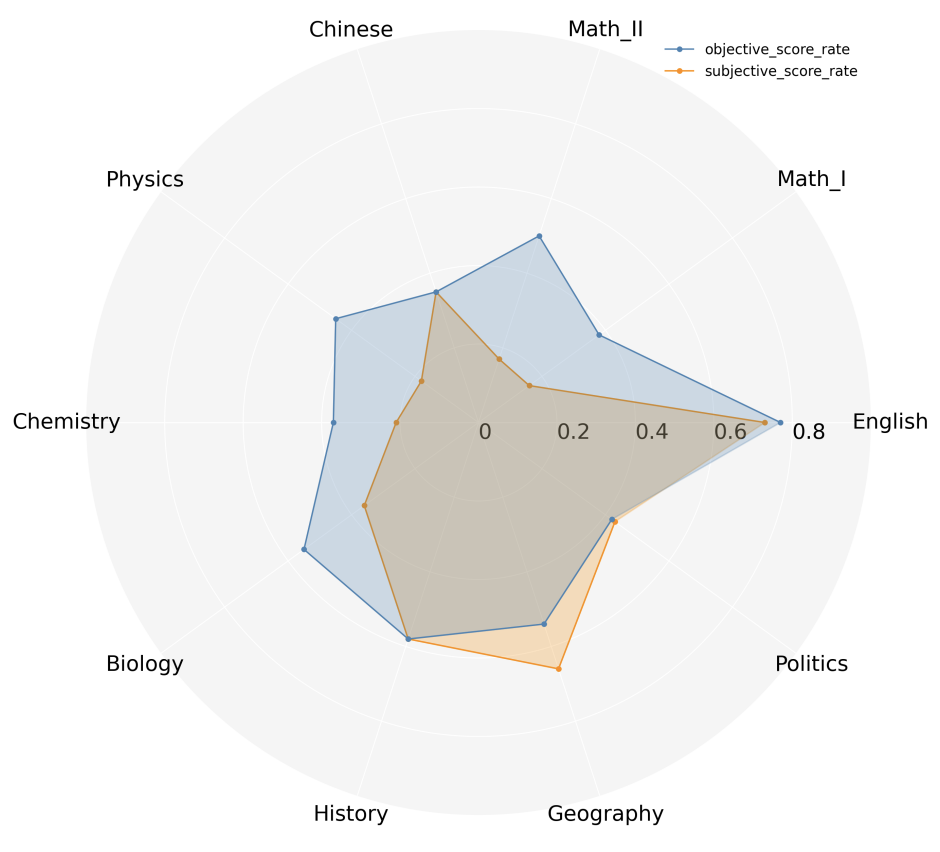
下图为ChatGPT在最近13年全国卷上,各科主/客观题的均分(每科归一化)。可以看到,在主观题,特别是语文和英语以外的科目,ChatGPT的表现并不理想。
任务特定的训练/精调方式依然有效
就如同BERT在做QA任务时可以用NLI和SQuAD做中间预训练一样。根据任务特点,对大模型做调整,以降低其泛用性为代价,提升某一方面的能力,也是可行的。
例如新加坡国立大学的一篇文章[4]提出,基于7B的LLaMA,用LoRA+24GB显存,结合一个人造数据集精调,就可以在BIG-bench算数任务上取得和GPT-4相当的表现。

类似地,在7个写作辅助任务上,Writing-Alpaca-7B[5]经过特定的指令精调,也可以取得超越ChatGPT的表现。

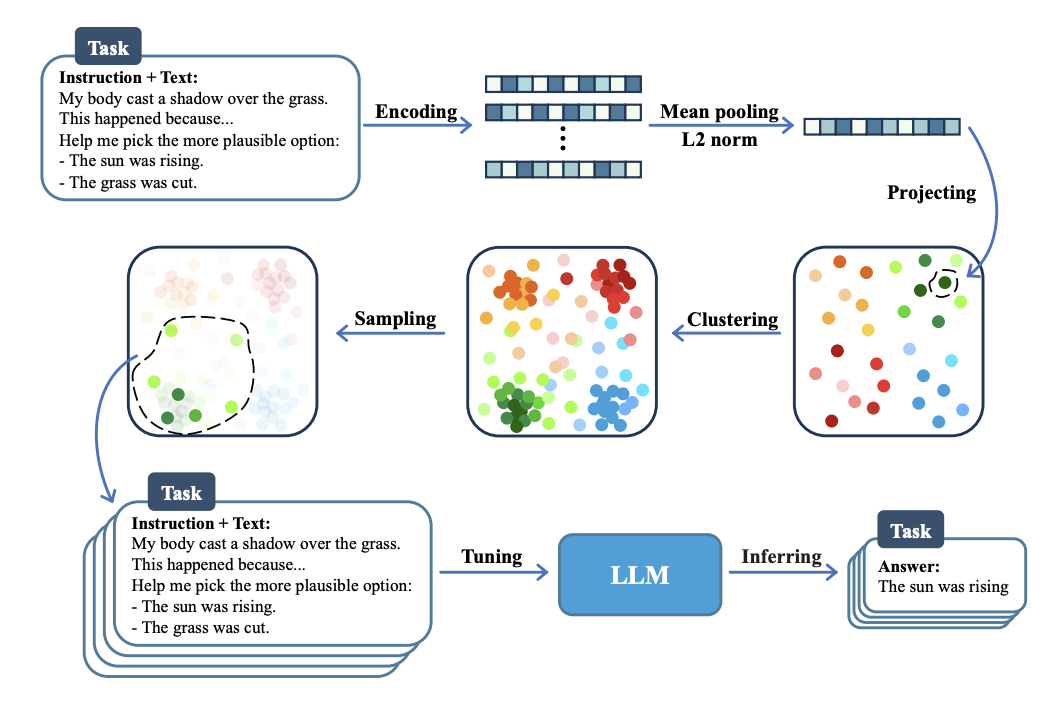
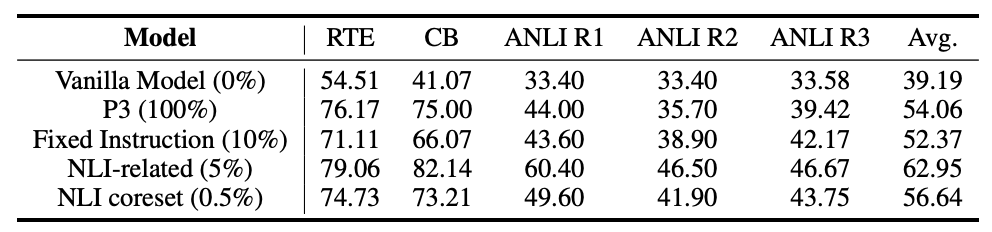
浙江大学提出[6],以Galactica-1.3b为基础,针对自然语言推断(NLI)相关的5个任务,从P3中筛选0.5%的指令精调数据,就可以取得比用全部数据精调高2%的平均表现。
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
任务特定的prompt方法也有价值
就如同BERT在预训练的基础上结合各种网络结构一样,根据任务特点,在大模型的基础上采取不同的prompt方案,也能取得一定的提升。
今年5月港中文和哈工深的一篇文章[7]提出elicit CoT prompt,在对话生成任务上用一组辅助的prompt让大模型生成一些与用户的personality, emotions, psychology相关的内容,进而辅助对话生成,提升helpfulness等主观指标。

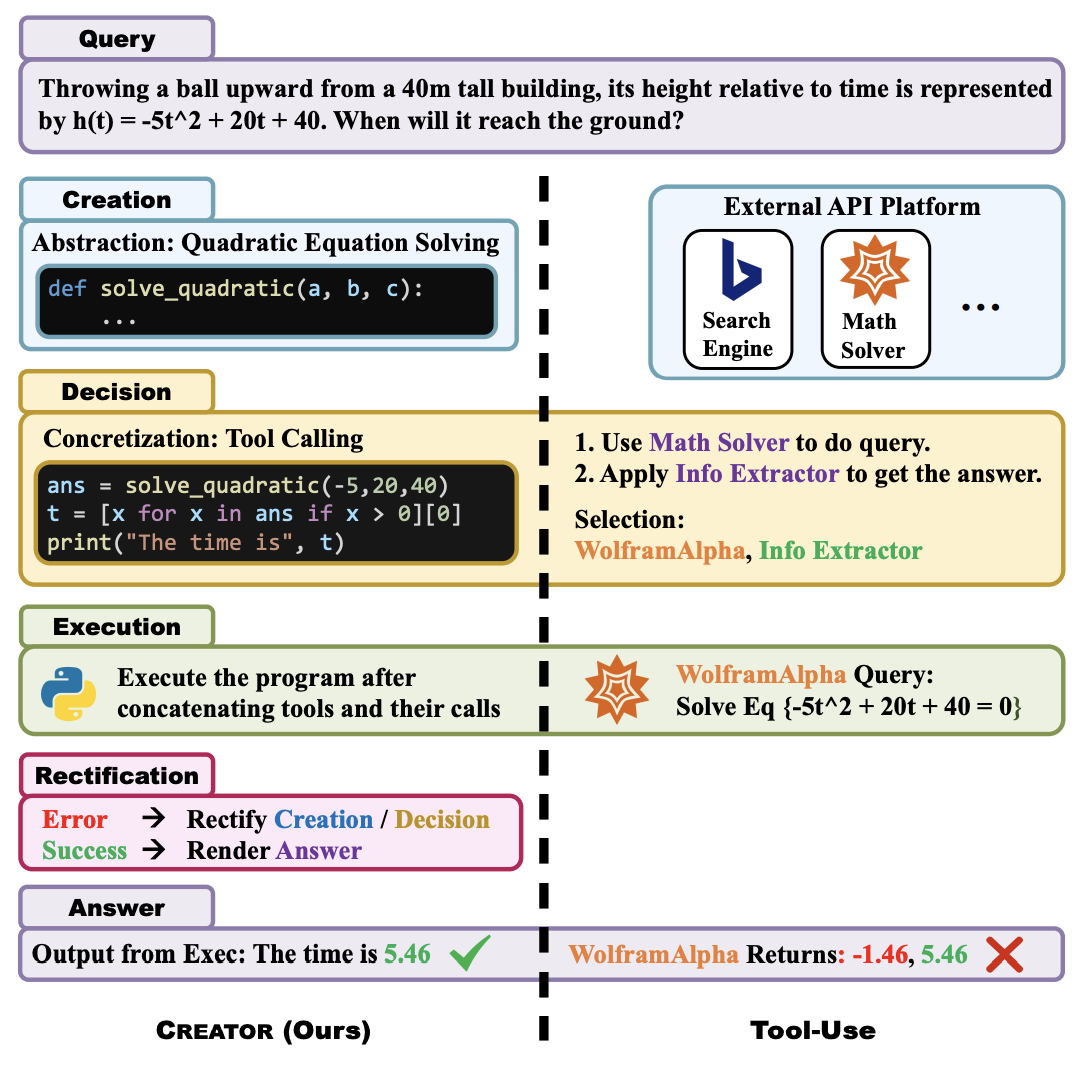
清华大学和UIUC[8]提出交互式地结合外部工具,可以让ChatGPT更好地解决数学任务。
谷歌和普林斯顿提出[9],针对需要探索或初始决策很重要的任务,设计Tree of Thoughts以取代CoT,在24点、创意写作、crosswords等任务上取得了明显的提升。

南京大学提出头脑风暴法[10],在CoT的基础上,通过一个过生成+排序筛选+生成的过程,在APPS和CodeContests上的复杂编程题中取得明显提升。

西湖大学和港中文提出Chain-of-Symbol方法[11],在给定一个文字表述的和地理位置信息相关的内容,生成回复的任务中,用简练的符号而非自然语言在CoT中阐述位置关系,相较ChatGPT与InstructGPT取得提升。

浙江大学与香侬科技针对文本分类任务,提出了更好的prompt: Clue And
Reasoning Prompting[12] (CARP,下图下半部分)。

浙江大学和阿里提出,通过反刍式思考[13],对反思生成内容,以提高大模型的推理能力。
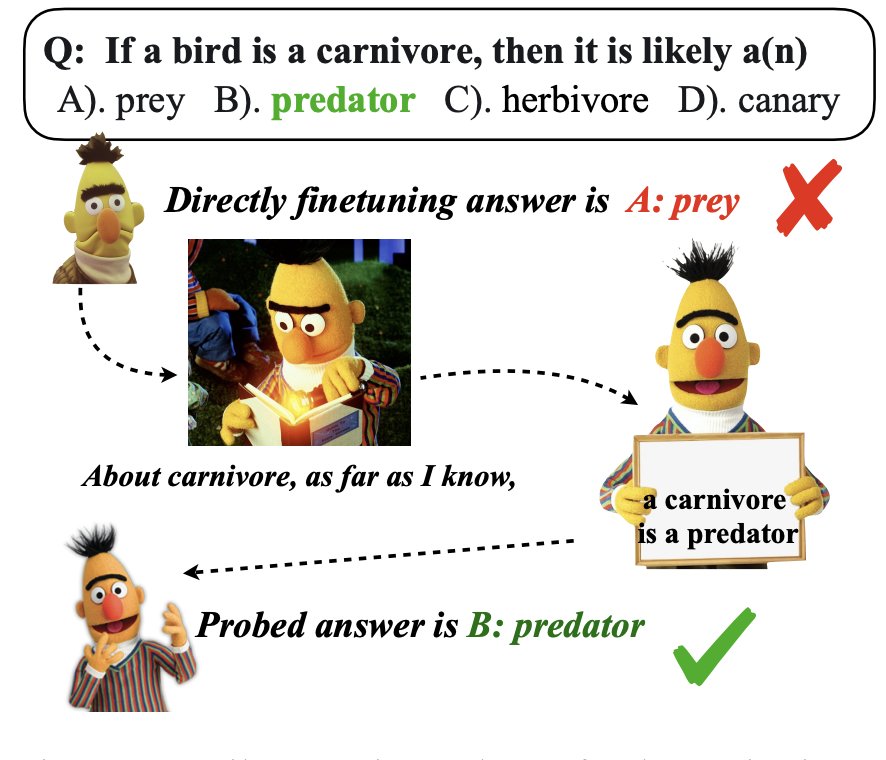
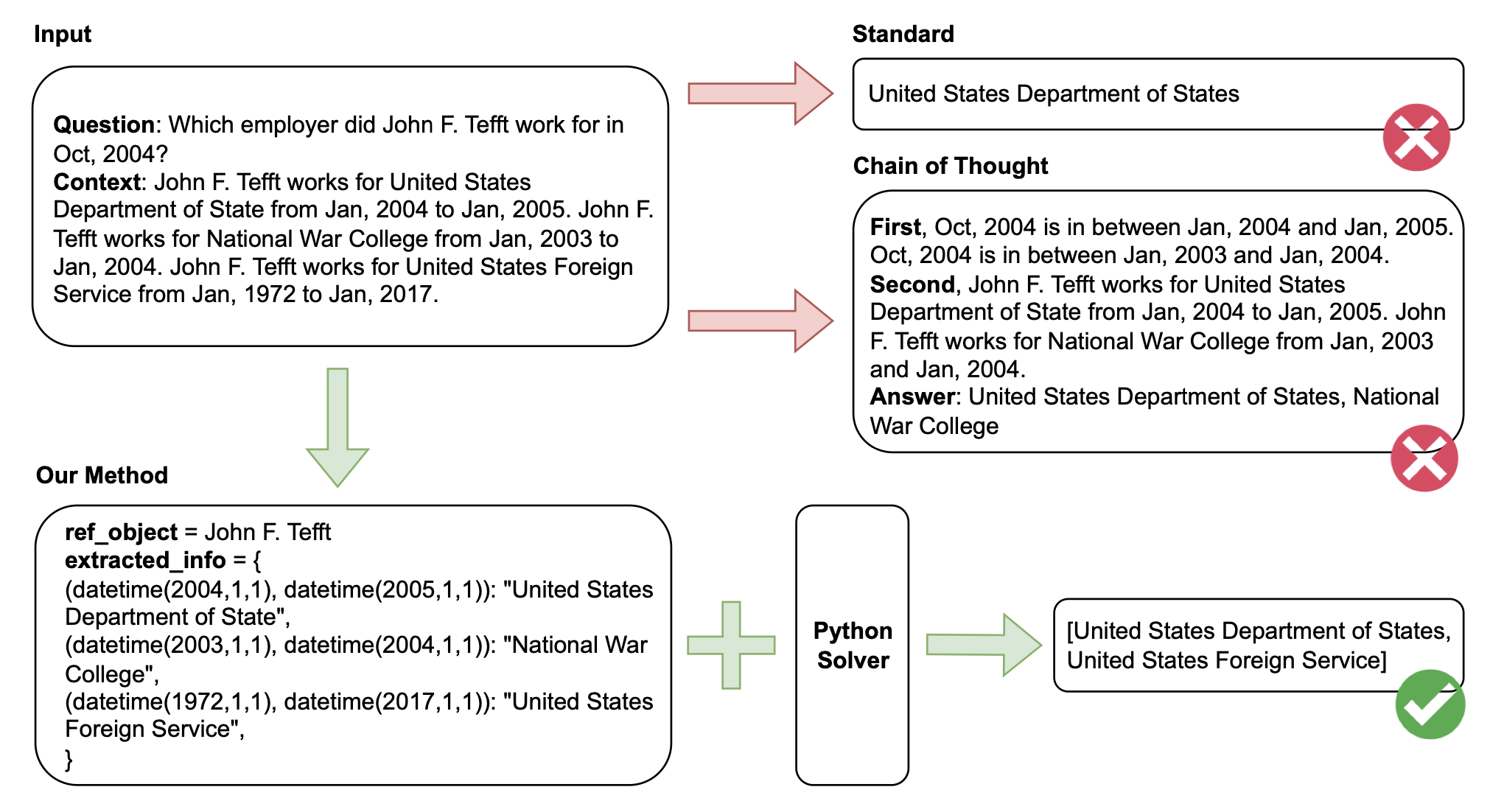
阿里达摩院提出通过可执行的代码[14]来解锁InstructGPT与GPT-4回答时序推理相关问题的能力。
结束语
从上述近期工作可以看出,当前大模型的能力可能被高估,其解决部分任务的能力可能源于训练数据与任务数据有所重叠。在大模型年代,针对任务特点,利用LoRA等低资源手段,可以在单机单卡到单机多卡的配置范围内,对十几亿到几十亿参数的大模型做指令调整,取得超越千亿大模型的表现。针对特定任务设计prompt方法,也可以取得明显的提升。
因此,单一的大而全,可能也并非是解决一切问题的银弹方法。NLPer们不比担心一个或几个大模型把所有问题都解决了而导致失业。任务特定的设计依然是有价值的。即使计算量提升,但如果仅需几十GB显存的单机多卡,国内一流高校的实验室也能够负担得起计算花销的。
之前听有一个老师说得特别好,谷歌搜索早就这么强了,也没听说做IR的都失业呀。作为一个商业产品,谷歌搜索/ChatGPT尽量地大而全地满足所有用户的需求,但在小而精的角度,一定有其尚未解决的问题。我们学术界就是需要发现这些问题,并提出解决方案,从而让工业界有机会将其整合到现有的商业产品中去,(让谷歌搜索/ChatGPT等)取得进一步的提升。
所以,不要过度迷恋大模型,认真观察其缺点,提出改进方案,自然语言处理还是有前途的。
参考资料
[1] Experience Grounds Language,https://arxiv.org/abs/2004.10151[1] Codex Hacks HackerRank: Memorization Issues and a Framework for Code Synthesis Evaluation, https://arxiv.org/pdf/2212.02684.pdf
[2] Evaluating the Performance of Large Language Models on GAOKAO Benchmark, https://arxiv.org/pdf/2305.12474.pdf
[3] Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation, https://arxiv.org/pdf/2305.01210.pdf
[4] Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks, https://arxiv.org/pdf/2305.14201.pdf
[5] Multi-Task Instruction Tuning of LLaMa for Specific Scenarios: A Preliminary Study on Writing Assistance, https://arxiv.org/pdf/2305.13225.pdf
[6] MAYBE ONLY 0.5% DATA IS NEEDED: A PRELIMINARY EXPLORATION OF LOW TRAINING DATA INSTRUCTION TUNING, https://arxiv.org/pdf/2305.09246.pdf
[7] Chain-of-thought prompting for responding to in-depth dialogue questions with LLM, https://arxiv.org/pdf/2305.11792.pdf
[8] CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation, https://arxiv.org/pdf/2305.14318.pdf
[9] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, https://arxiv.org/pdf/2305.10601.pdf
[10] Think Outside the Code: Brainstorming Boosts Large Language Models in Code Generation, https://arxiv.org/pdf/2305.10679.pdf
[11] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models, https://arxiv.org/pdf/2305.10276.pdf
[12] Text Classification via Large Language Models, https://arxiv.org/pdf/2305.08377.pdf
[13] Knowledge Rumination for Pre-trained Language Models, https://arxiv.org/pdf/2305.08732.pdf
[14] Unlocking Temporal Question Answering for Large Language Models Using Code Execution, https://arxiv.org/pdf/2305.15014.pdf