将队列放在Prometheus前以提高可靠性并不总是"好主意"
为了防止突发流量,而在prometheus前加上消息队列以达到削峰填谷的目的
架构如下:
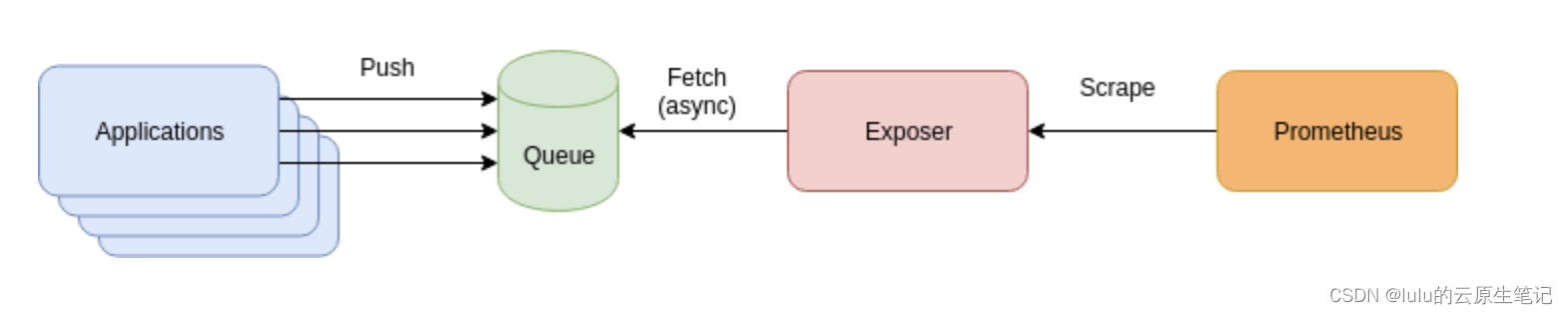
应用程序将指标推送到某种形式的队列(通常是 Kafka),暴露器二进制文件从队列中读取并提供自上次抓取到 Prometheus 以来的所有应用程序指标。细节各不相同,通常涉及分片和冗余。在某些情况下,queue 和 exposer 被组合在一起
给出这种设计的原因通常是其中之一,这是已经流传下来的所需企业架构,它是为了减少延迟,它是可扩展性所必需的,或者它是为了可靠性。
但是监控的可靠性是更多的是及时和准确,即实效性是非常重要的环节!甚至有时候迟到的数据不如没有数据
那么鉴于监控意义上的可靠性含义,上述设计类别存在哪些问题?
-
首先是应用程序和队列之间的通信。如果这不起作用,那么应用程序可能需要缓冲 RAM 中的指标。当事情发生故障时占用更多资源可能会导致问题变得更糟,例如,如果队列与其他系统共享并导致它们也在 RAM 中建立积压。您不能假定队列是可靠的,尤其是当涉及到共识机制时。例如,Kafka 领导人选举可能需要一段时间(尽管我相信较新的版本不再按分区顺序进行)。总是存在过载或意外达到资源限制的可能性。
-
第二个是当 Prometheus 抓取数据时,指标不会同步生成。这可能会由于数据未对齐而导致伪影(尤其是在传播延迟中存在抖动的情况下),并且延迟的时间序列在未被抓取时会被错误地标记为陈旧。您可能认为添加时间戳可以解决这个问题,但这样您就失去了陈旧处理的好处。记录规则和查询不会始终拥有最新数据,从而导致奇怪的图表和不正确的警报。所以就时间戳而言,在一次抓取中处理来自同一时间序列的具有不同时间戳的多个样本在技术上也是未定义的行为。
-
第三个是可扩展性问题。Prometheus 抓取是为许多小目标设计的,而不是为少数大目标设计的。让单个曝光器为单个抓取提供数十万个样本意味着您还需要 Prometheus 能够在抓取间隔内解析和摄取这些指标——否则 Prometheus 会将抓取视为失败。通过 exposer 集中抓取可扩展性实际上变得更糟,因为它现在是一个 CPU 核心瓶颈,需要仔细管理以确保抓取继续成功。
-
第四个是缺乏服务发现和摄取控制。由于 Prometheus 只知道曝光器,它不会up为每个目标提供时间序列,因此您必须实施其他一些解决方案来提供该功能。
因此,与普罗米修斯的设计背道而驰并不能给你带来多少好处,事实上,与普罗米修斯直接抓取应用程序的标准设置相比,总体上可能会使你的系统可靠性和可扩展性降低。
这并不是说你永远不应该使用队列,队列有很多有效的用例。Prometheus 不是其中之一,因为它在设计时考虑了一组不同的工程权衡。