本文中所有代码及数据均存放于:https://github.com/MADMAX110/WineQualityPrediction
本文根据酸度、残糖和酒精浓度等特征训练和调整一个随机的葡萄酒质量森林模型。
一、设置环境,确认你的电脑安装了以下环境
- Python 3+
- NumPy
- Pandas
- Scikit-Learn (a.k.a. sklearn)
强烈推荐使用Anaconda安装Python,它已经安装了以上所有的包。
二、导入库和包
#导入numpy,可以提供更高效的数值计算
import numpy as np
#导入pandas,支持数据帧的便捷库
import pandas as pd
#导入modelselection模块中的train_test_split函数,包含许多实用程序
from sklearn.model_selection import train_test_split
#导入整个预处理模块,包含用于缩放、转换和整理数据的实用程序
from sklearn import preprocessing
#导入随机森林模型,这段代码中只专注于训练随机森林并调整其参数。
from sklearn.ensemble import RandomForestRegressor
#导入工具以执行交叉验证
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
#导入一些指标,以便稍后用于评估模型性能
from sklearn.metrics import mean_squared_error, r2_score
#导入一种保留模型以供将来使用的方法
import joblib
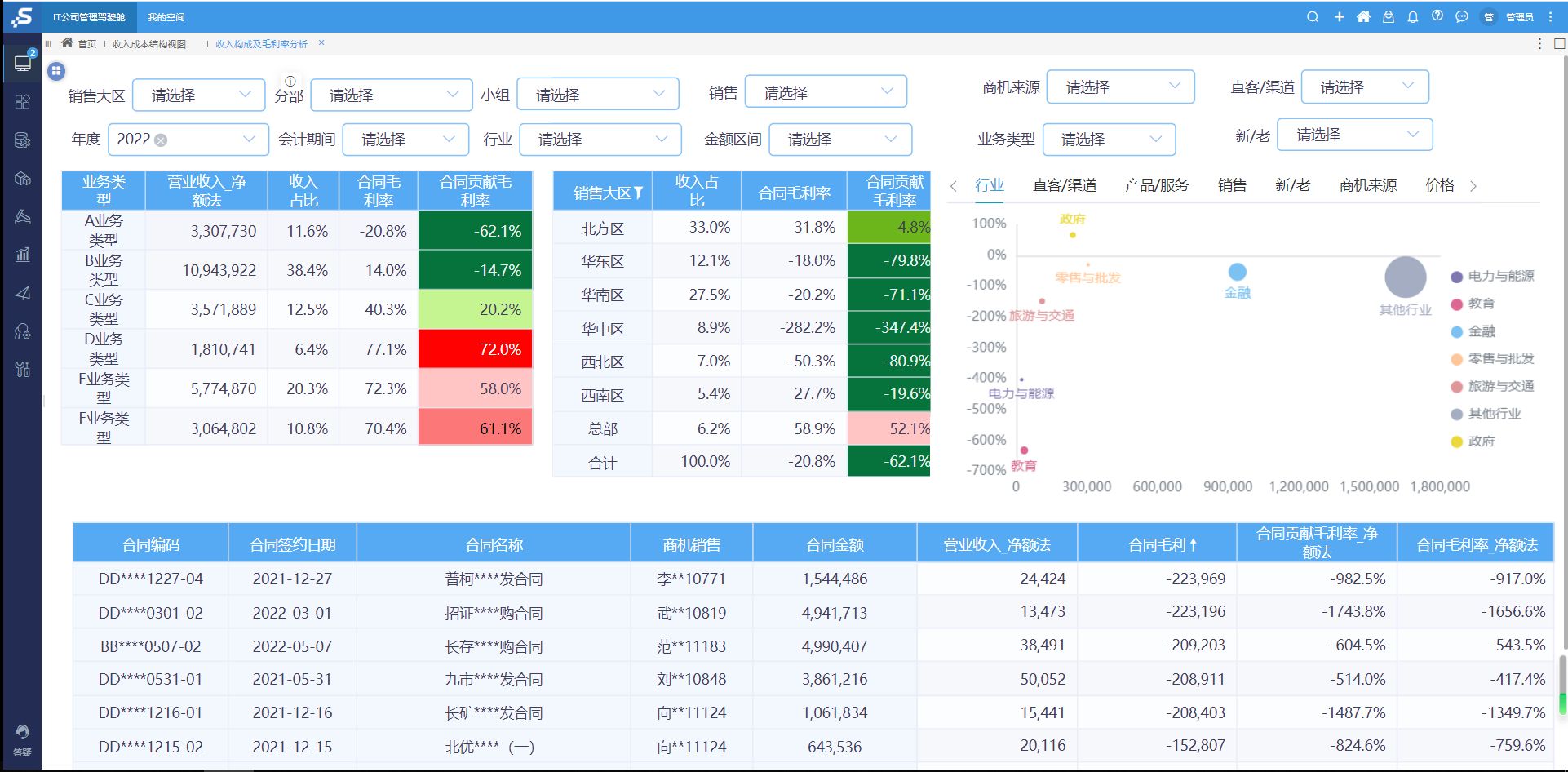
三、加载红酒数据
pandas库有一整套有用的导入/输出工具,这里将使用read_csv函数加载。
#加载数据
dataset_url = 'winequality/winequality-red.csv'
data = pd.read_csv(dataset_url)
#查看数据的前五行
print( data.head() )
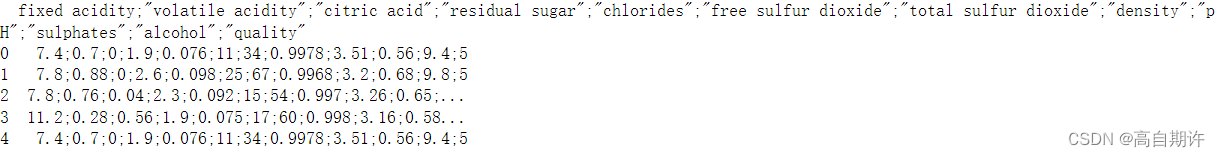
看起来CSV文件实际使用分号来分隔数据,可以使用
data = pd.read_csv(dataset_url, sep=';')
print(data.head())
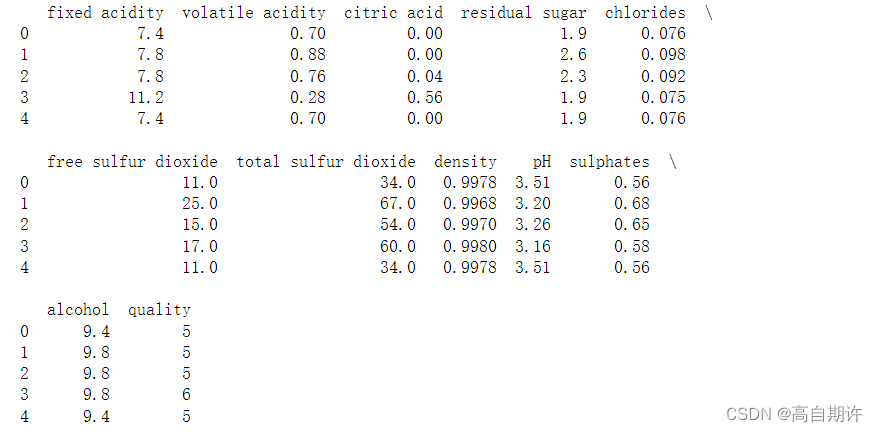
现在看起来就好多了,还可以查看以下数据的大小及汇总统计数据
print(data.shape)
print( data.describe() )
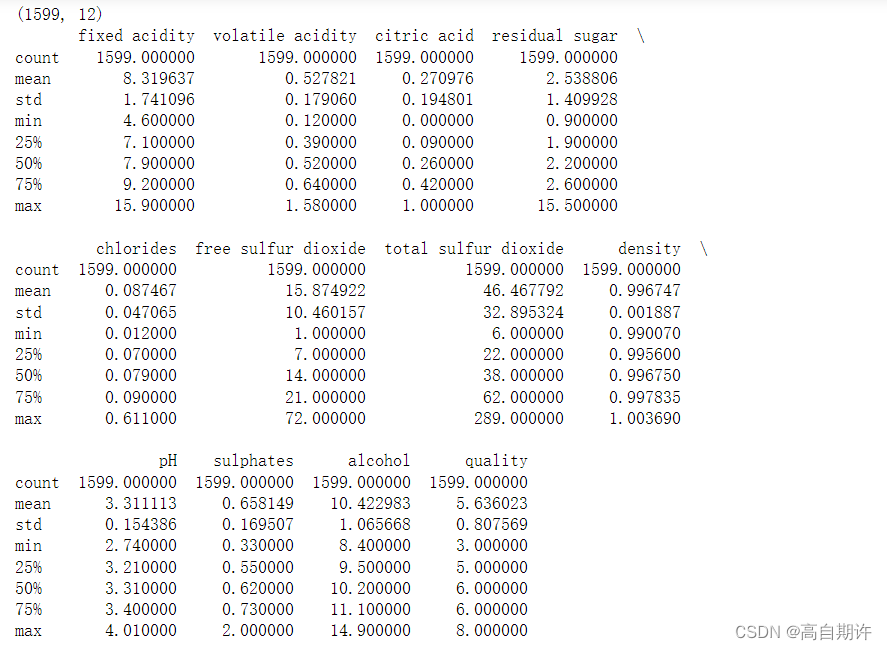
看起来该样本中有1599个样本和12个特征,所有特征都是数字,稍后再进行标准化。
四、将数据拆分为训练集和测试集
在建模工作流开始时将数据拆分为训练集和测试集对于实际估计模型的性能至关重要。首先需要将目标y特征和输入x特征分开。
#将quality列为标签,赋值给y
y = data.quality
#删除data数据框中的quality列,剩余部分作为特征,赋值给X
X = data.drop('quality', axis = 1)
axis=0表示沿着横向维度,也就是对行进行操作
axis=1表示沿着纵向维度,也就是对列进行操作
#使用sklearn中的train_test_split函数将X和y划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=123,
stratify=y)
train_test_split函数的参数含义:
- X和y:所要划分的数据和标签
- test_size=0.2:测试集占总数据的20%
- random_state=123:随机数种子,用于随机采样,确保每次运行得到同样的划分结果
- stratify=y:分层采样,确保训练集和测试集中的类别比例与原始数据一致,如果不使用这个,可能会导致训练集和测试集中的类别比例可能会差异较大,这会影响后续的模型评估。
执行后,我们得到:
- X_train和X_test:训练集特征和测试集特征
- y_train和y_test:训练集标签和测试集标签
这种训练集和测试集的划分是机器学习中非常重要的一步,关系到模型的泛化能力与最终性能。我们通常会将大约20%的数据作为测试集,其余作为训练集。
五、数据预处理
标准化是机器学习中一个很重要的预处理步骤。它的作用是将特征值转换到相同的量纲范围内,通常是0到1范围内,或-1到1范围内。
标准化的主要目的有:
- 消除量纲影响:不同特征可能具有不同的量纲和范围,这会影响模型的训练和系数的学习。标准化可以消除这种量纲影响,让模型公平地考虑各个特征。
- 提高优化效果:许多优化算法会更快地收敛当输入的特征位于相近范围时。标准化可以加速模型的训练过程。
- 避免特征过大影响模型:某个特征的取值范围很大,会主导模型的学习,从而影响模型的泛化能力。标准化可以使各特征对模型的重要性更加平衡。
常见的标准化方法有:
- 最小-最大标准化:新值 = (旧值 - 最小值) / (最大值 - 最小值)
- Z-score标准化:新值 = (旧值 - 均值) / 标准差
- 小数定标标准化:新值 = 旧值 / 平均值
标准化一般在模型训练前进行,并且只在训练数据上计算标准化所需的统计量,然后使用这些统计量将测试集也标准化,以保证训练和测试数据具有相同的分布。
标准化是机器学习中一个简单但非常重要的步骤。正确地标准化可以让我们的模型训练更加高效稳定,并在一定程度上提高模型的泛化能力与效果。理解各种标准化方法背后的原理和作用,可以让我们在不同场景下选用最佳方案。
sklearn使数据预处理变得轻而易举。
下面是一些我们不会使用地代码
简单地扩展数据集非常容易:
#使用preprocessing.scale()对训练集特征X_train进行标准化,结果存储在X_train_scaled中。
X_train_scaled = preprocessing.scale(X_train)
print( X_train_scaled )
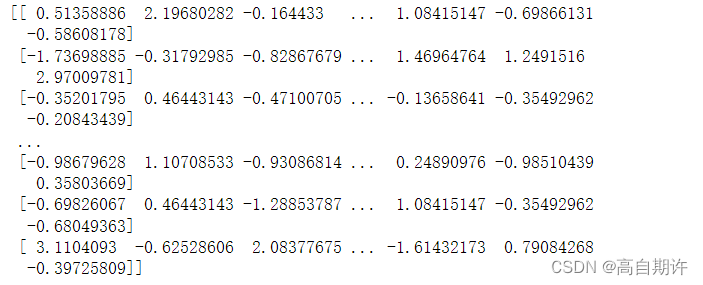
scale()函数实现的是Z-score标准化,公式为:
新值 = (原值 - 均值) / 标准差
下面可以确认缩放数据集确实以0为中心,单位方差:
#取消Numpy的科学计数法显示,打印完整精度。
np.set_printoptions(suppress=True)
#打印X_train_scaled的各特征均值
print( X_train_scaled.mean(axis=0) )
#打印X_train_scaled的各特征标准差
print( X_train_scaled.std(axis=0) )
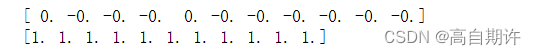
以上代码我们并不会使用,原因是我们无法在测试集上执行完全相同的转换。
下面是将要使用的预处理代码:
我们将使用sklearn中称为Transformer API的功能,而不是直接调用scale函数。Transformer API 允许您使用训练数据“拟合”预处理步骤,就像拟合模型一样.,然后在未来的数据集上使用相同的转换!
该过程如下所示:
1、在训练集上设置transformer(保存均值和标准偏差)
2、在训练集上使用transformer(缩放训练数据)
3、在测试集上使用transformer(使用相同的均值和标准偏差)
这使得模型性能的最终估计更加真实,并允许将预处理步骤插入到交叉验证管道中。
#在训练数据X_train上拟合StandardScaler()
scaler = preprocessing.StandardScaler().fit(X_train)
#使用上一条语句中的参数将X_train进行标准化
X_train_scaled = scaler.transform(X_train)
print X_train_scaled.mean(axis=0)
# [ 0. -0. -0. -0. 0. -0. -0. -0. -0. -0. -0.]
print X_train_scaled.std(axis=0)
# [ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
现在scaler对象为训练集中的每个特征都保存了均值和标准差
然后使用对测试集使用相同的转换方法
X_test_scaled = scaler.transform(X_test)
print (X_test_scaled.mean(axis=0))
print (X_test_scaled.std(axis=0))

这里的单位方差并没有完全以0为中心!这就是我们期望的,因为我们使用训练集的方法而不是测试集本身来转换测试集。
接着使用make_pipeline()构建一个机器学习流程(pipeline),
#构建一个机器学习流程(pipeline)
pipeline = make_pipeline(preprocessing.StandardScaler(),
RandomForestRegressor(n_estimators=100,
random_state=123))
该学习流程包括两个步骤
- preprocessing.StandardScaler(): Z-score标准化
- RandomForestRegressor(): 随机森林回归模型
pipeline会按顺序执行这两个步骤:
- 首先使用StandardScaler对数据进行标准化
- 然后使用随机森林模型对标准化后的数据进行回归训练和预测
make_pipeline()的作用是将多个数据处理与模型步骤组合成一个流程,方便我们对整体流程进行训练、预测和调参。
六、声明要调优的超参数
通常我们需要考虑两种类型的参数:模型参数和超参数。模型参数可以直接从数据中学习(回归系数),而超参数不能。超参数一般表示有关模型的更高级别结构信息,通常在训练模型之前设置。
以随机森林举例,在每个决策树中,计算机可以根据均方误差MSE或均值绝对误差MAE凭经验决定在哪里创建分支,这里的实际分支位置就是模型参数。
但是该算法不知道应该使用MSE或MAE中的哪一个,也无法决定森林中包含多少棵树,这些是用户必须设置的超参数。
可以通过以下函数列出可调超参数:
print( pipeline.get_params() )
# ...
# 'randomforestregressor__criterion': 'squared_error',
# 'randomforestregressor__max_depth': None,
# 'randomforestregressor__max_features': 'auto',
# 'randomforestregressor__max_leaf_nodes': None,
# ...
声明超参数,格式是Python字典,其中键是超参数名称,值是要尝试的设置列表。
hyperparameters = { 'randomforestregressor__max_features' : ['auto', 'sqrt', 'log2'],
'randomforestregressor__max_depth': [None, 5, 3, 1]}
七、使用交叉验证管道优化模型
交叉验证(cross-validation)是所有机器学习中最重要的技能之一,它可以最大限度地提高模型性能,同时减少过度拟合地机会。
交叉验证是通过使用相同的方法多次训练和评估模型来可靠地估计构建模型的方法的性能的过程,以下是CV的步骤
1、将数据拆分为 k份 相等的部分(通常 k=10)。
2、在 前k-1个部分 (例如前 9 个部分)上训练模型。
3、在剩余的“保留”部分(例如第 10 个部分)上对其进行评估。
4、执行步骤(2)和(3)k次,每次保持不同的部分。
5、汇总所有 k 份的性能。这是就是性能指标。
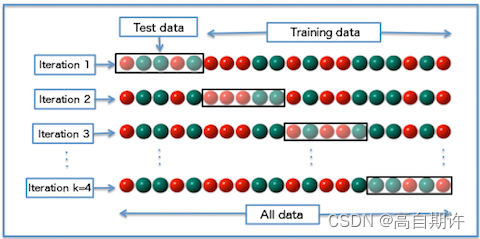
它的基本思想是:将数据集划分为训练集和验证集,在训练集上训练模型,在验证集上评估模型性能,并通过多次试验减少评估的方差,获得更加可靠的评估结果。
而交叉验证管道指的是将交叉验证整合到机器学习流程中的一种方法。
它的基本思想是:
- 在机器学习流程的各个步骤(数据清理、特征工程、模型选择等)中都采用交叉验证进行评估
- 重复以上步骤,获得多轮交叉验证的结果
- 综合多轮交叉验证的结果,得出最终的评估结论
交叉验证管道的目的在于:更全面和真实地评估整个机器学习流程的效果,而不仅仅是评估某一个模型算法的效果。一个典型的交叉验证管道可以包含:
- 对不同的数据清理和特征选取方案进行评估,选择效果最佳的方案
- 在选取的特征上,对不同的机器学习模型进行评估,选择最优模型
- 通过多次重复步骤1和2,评估数据清理、特征工程和模型选择的稳定性,得出最终的方案
- 使用最终确定的方案在全部数据集上重新训练模型,并在独立的测试集上测试最终的效果
交叉验证管道为我们提供了一种更加全面评估完整机器学习流程的手段。它考虑到机器学习效果的不确定性,通过多轮试验和效果的汇总统计,能让我们的结论更加可靠。
可以使用sklearn方便地实现这一点:
#GridSearch本质上就是对超参数的所有可能的排列执行交叉验证
clf = GridSearchCV(pipeline, hyperparameters, cv=10)
#拟合和调整模型
clf.fit(X_train, y_train)
#输出最佳参数集
print( clf.best_params_ )
八、在整个训练集上重新拟合
使用交叉验证适当地调整超参数后,通常可以通过在整个训练集上重新拟合模型来获得较小的性能改进。
方便的是,来自sklearn的GridSearchCV将使用整个训练集自动使用最佳超参数集重新调整模型。此功能默认处于打开状态,但可以确认一下
Python
print( clf.refit )
# True
九、根据测试数据评估模型管道
#使用训练好的分类模型clf对测试集X_test进行预测,结果存储在y_pred中。
y_pred = clf.predict(X_test)
#将真实标签y_test和预测结果y_pred输入r2_score函数,计算R squared(R方)值,并打印结果。
print( r2_score(y_test, y_pred) )
# 0.4712595193413647
#将真实标签y_test和预测结果y_pred输入mean_squared_error函数,计算均方误差(MSE),并打印结果。
print( mean_squared_error(y_test, y_pred) )
# 0.34118218749999996
- R方值越高,表示预测结果与真实值的相关性越高,模型效果越好。R方为1表示完全相关,0表示不相关。
- MSE值越低,表示预测误差越小,模型效果越好。
十、保存模型以便将来使用
Joblib是一个Python库,提供了简单易用的序列化与持久化方案。
#将训练好的模型clf序列化后保存到文件rf_regressor.pkl中
joblib.dump(clf, 'rf_regressor.pkl')
#从文件rf_regressor.pkl中加载序列化后的模型,并赋值给clf2。
clf2 = joblib.load('rf_regressor.pkl')
#用现成的模型预测数据
clf2.predict(X_test)
通过这三行代码,我们实现了模型的持久化存储与加载。
序列化后的模型文件rf_regressor.pkl中包含模型的各个参数与配置信息。当我们需要使用该模型对新数据进行预测时,只需要从文件加载模型即可,而不需要重新训练。
这在实际工作中有几个主要的应用:
- 模型部署:我们可以训练好模型,序列化并发布,用户只需要加载模型文件即可使用,无需训练模型。
- 避免重复训练:如果模型训练成本较高,我们可以周期性训练并序列化最新的模型,在需要预测时直接加载最新模型,避免重复训练。
- 模型备份:序列化模型可以长期保存,避免训练好的模型丢失,有备份可以随时加载使用。