文章目录
- 摘要
- 主要特性
- 常用概念
- 框、边界框
- 交并比 (loU)
- 感受野
- 有效感受野
- 置信度
- 目标检测的基本思路
- 难点
- 滑框
- 在特征图进行密集计算
- 边界框回归
- 基于锚框VS无锚框
- NMS(非极大值抑制)
- 使周密集预测模型进行推理步骤
- 如何训练
- 密集预测模型的训练
- 匹配的基本思路
- 密集检测的基本范式
- 多尺度预测
- 如何处理尺度问题
- 基于锶框(Anchor)
- 图像金字塔 Image Pyramid
- 基于层次化特征
- 特征金字塔网络 Feature Pyramid Network (2016)
- 多尺度的密集预测基本范式
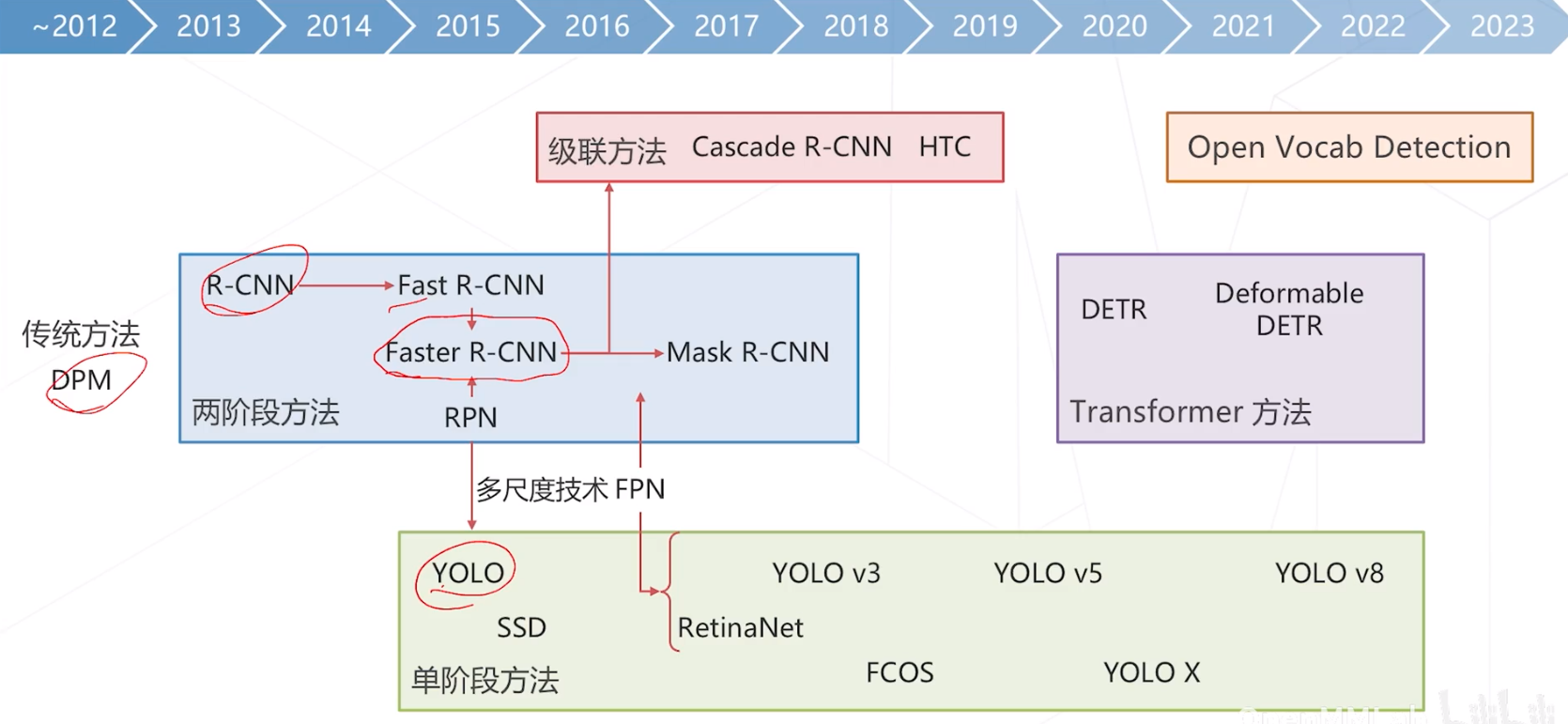
- 单阶段算法
- Region Proposal Network (2015)
- YOLO: You Only Look Once (2015)
- SSD: Single Shot MultiBox Detector (2016)
- RetinaNet (2017)
- 单阶段算法面临的正负样本不均衡问题
- YOLO v3 (2018)
- 无锚框算法
- 基于锚框VS 无锚框
- FCOS, Fully Convolutional One-Stage (2019)
- CenterNet (2019)
- YOLO X (2021)
- YoloV8
- 单阶段算法和元铓框算法的总结
摘要

MMDetection 是一个基于 PyTorch 的目标检测开源工具箱。它是 OpenMMLab 项目的一部分。是目前应用最广的算法库
主分支代码目前支持 PyTorch 1.6 以上的版本。代码链接:https://gitee.com/open-mmlab/mmdetection。
主要特性
-
模块化设计。MMDetection 将检测框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的检测模型
-
支持多种检测任务。MMDetection 支持了各种不同的检测任务,包括目标检测,实例分割,全景分割,以及半监督目标检测。
-
速度快。基本的框和 mask 操作都实现了 GPU 版本,训练速度比其他代码库更快或者相当,包括 Detectron2, maskrcnn-benchmark 和 SimpleDet。
-
性能高。MMDetection 这个算法库源自于 COCO 2018 目标检测竞赛的冠军团队 MMDet 团队开发的代码,我们在之后持续进行了改进和提升。 新发布的 RTMDet 还在实时实例分割和旋转目标检测任务中取得了最先进的成果,同时也在目标检测模型中取得了最佳的的参数量和精度平衡。
【课程链接】https://www.bilibili.com/video/BV1Ak4y1p7W9/
【讲师介绍】王若晖 OpenMMLab青年研究员
一阶段算法:SSD、YOLO系列等。二阶段:Faster R-CNN、Mask R-CNN等。

常用概念
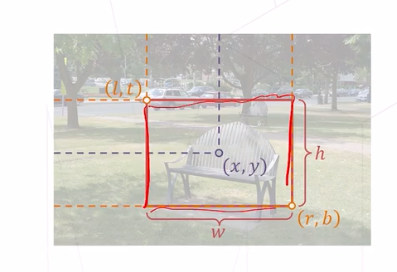
框、边界框
框泛指图像上的矩形框,边界横平坚直
描述一个框需要 4 个像素值:
- 方式 1: 左上右下边界坐标 (l, t, r, b)
- 方式2: 中心坐标和框的长宽 (x, y, w, h)
边界框通常指紧密包围感兴趣物体的框 检测任务要求为图中出现的每个物体预测一个边界框
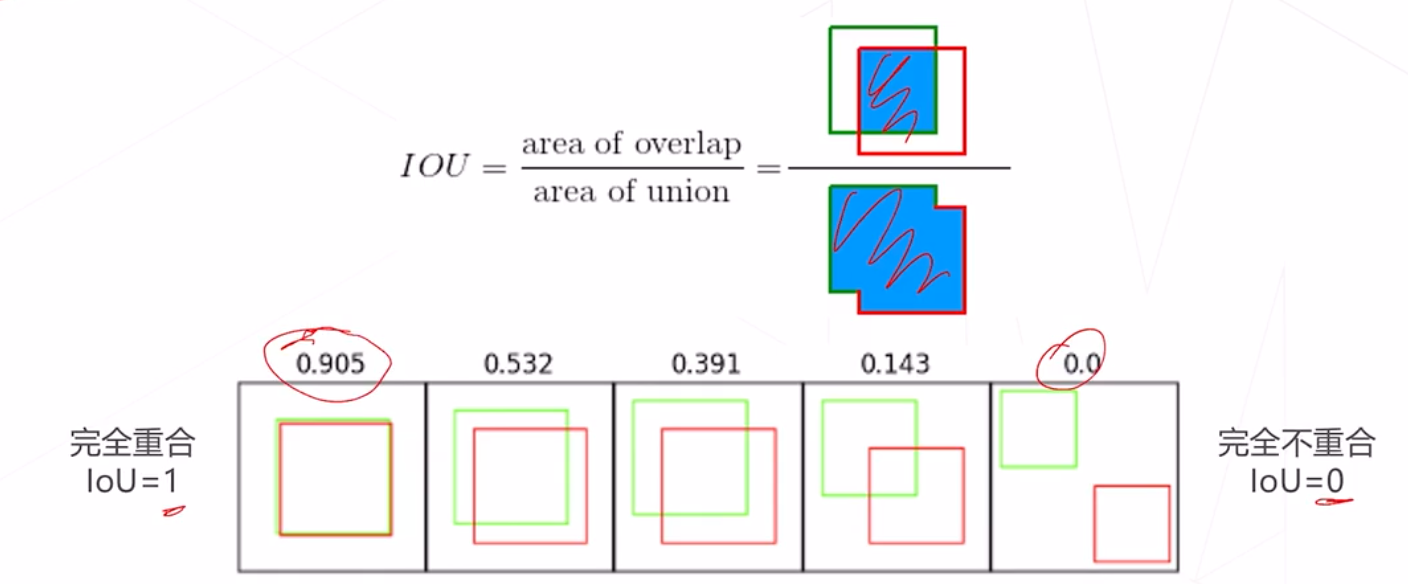
交并比 (loU)
交并比 (loU) 定义为两矩形框交集面积与并集面积之比,是矩形框重合程度的衡量指标
感受野
感受野: 神经网络中,一个神经元能"看到"的原图的区域
换句话说:
- 为了计算出这个神经元的激活值,原图上哪些像素参与运算了?
再换句话说: - 这个神经元表达了图像上哪个区域内的内容?
- 这个神经元是图像上哪个区域的特征?
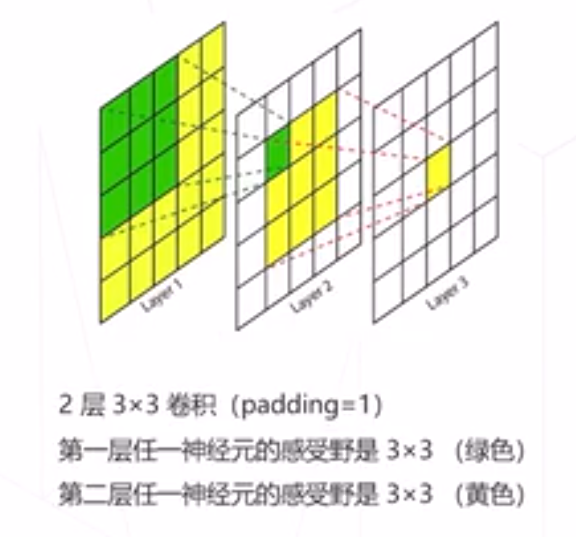
感受野的中心
- 一般结论比较复杂
- 对于尺寸
3
×
3
3 \times 3
3×3 、
p
a
d
=
1
p a d=1
pad=1 的卷积(或池化)堆叠起来的模 型,感受野中心=神经元再特征图上的坐标
×
\times
× 感受野步长
感受野的步长(=降采样率=特称图尺寸的缩减倍数) - 神经网络某一层上, 相邻两个神经元的感受野的距离
- 步长=这一层之前所有stride的乘积
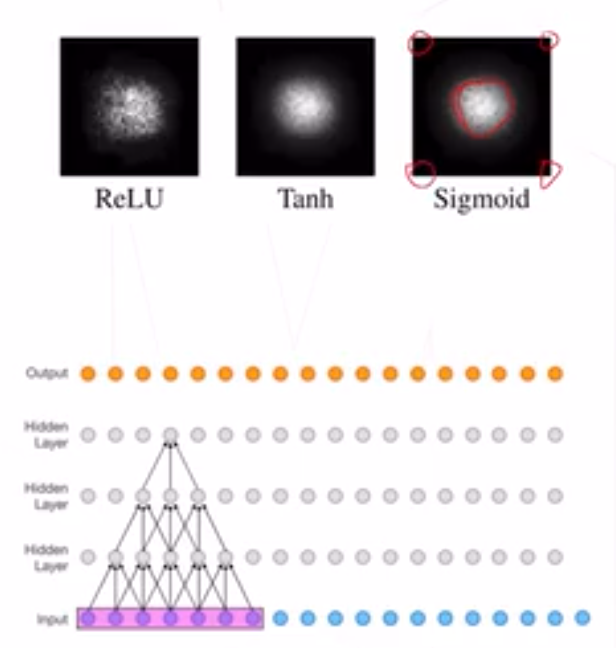
有效感受野
感受野一般很大,但不同像素对激活值的贡献是不同的
换句话说:
激活值对感受野内的像素求导数,大小不同
影响比较大的像素通常聚集在中间区域,可以认为对应神经元 提取了有效感受野范围内的特征
置信度
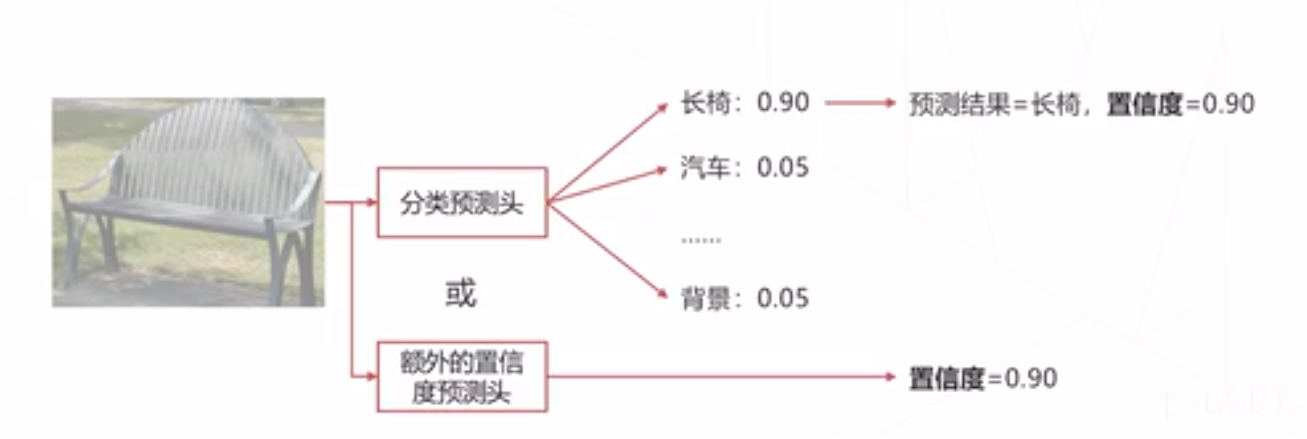
置信度(Confidence Score):模型认可自身预测结果的程度,通常需要为每个框预测一个置信度 我们倾向认可置信度高的预测结果,例如有两个重复的预测结果,丟弃置信度低的
- 部分算法直接取模型预测物体属于特定类别的概率
- 部分算法让模型单独预测一个置信度(训练时有GT,可以得相关信息作为监督)
目标检测的基本思路
难点
- 需要同时解决 “是什么" 和 “在哪里"
- 图中物体位置、数量、尺度变化多样

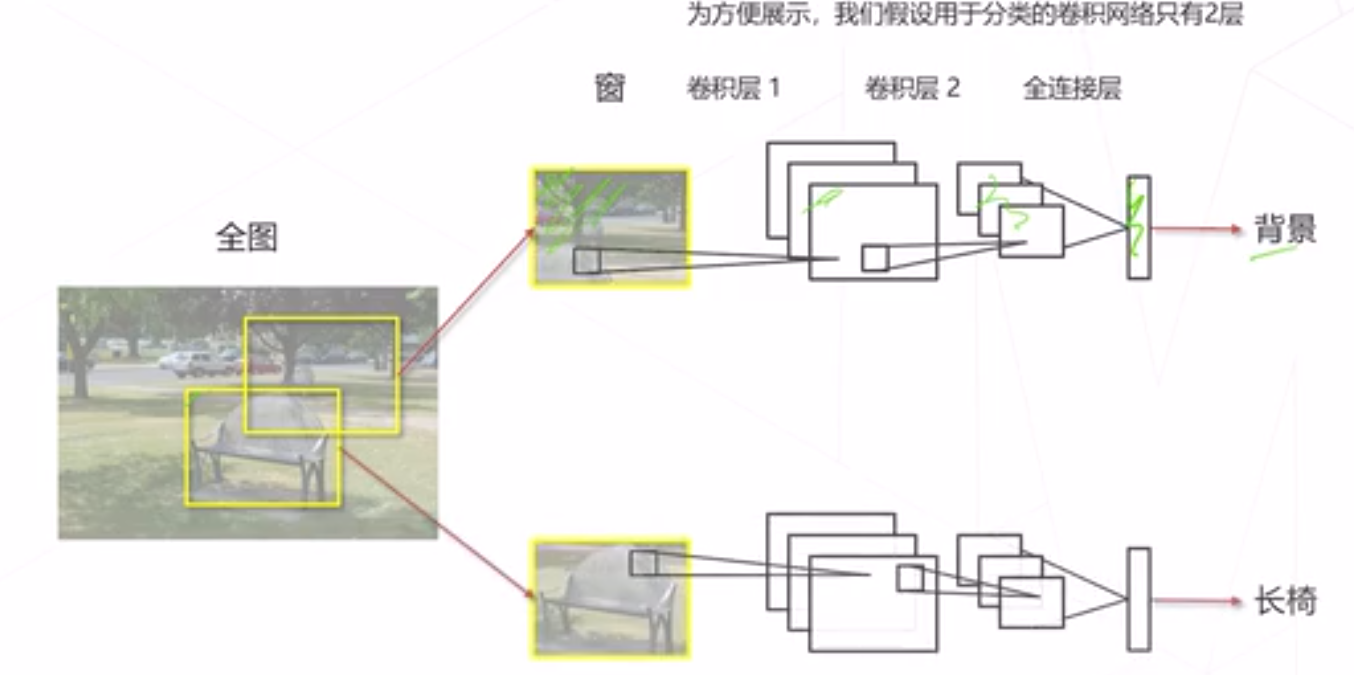
滑框
-一个好的检测器应满足不重、不漏的要求, 滑窗是实现这个要求的一个朴素手段。
-
设定一个固定大小的窗口
-
遍历图像所有位置,所到之处用分类模型 (假没已经汌统好) 识别窗口中的内容
-
为了检测不同大小、不同形状的物体,可以使用不同大小、长宽比的窗口扫描图片

缺点,效率低、冗余计算。

改进思路 1:使用启发式算法替换榩力退历
用相对低计算量的方式祖筡出可能包含物体的位置,再使用卷积网络预测 早期二阶段方法使用, 依款外部算法, 系统实现复杂
改进2:分析重复计算,减少冗余计算。
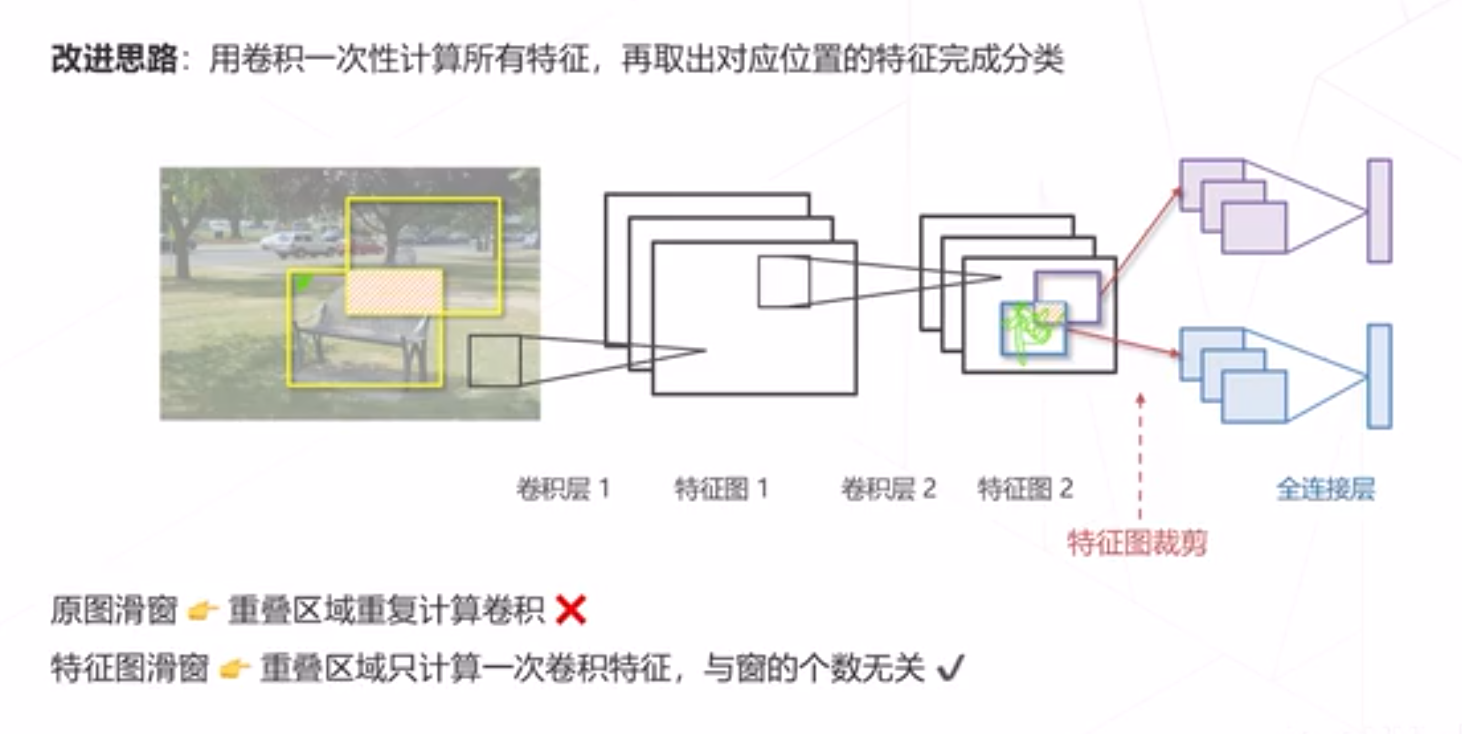
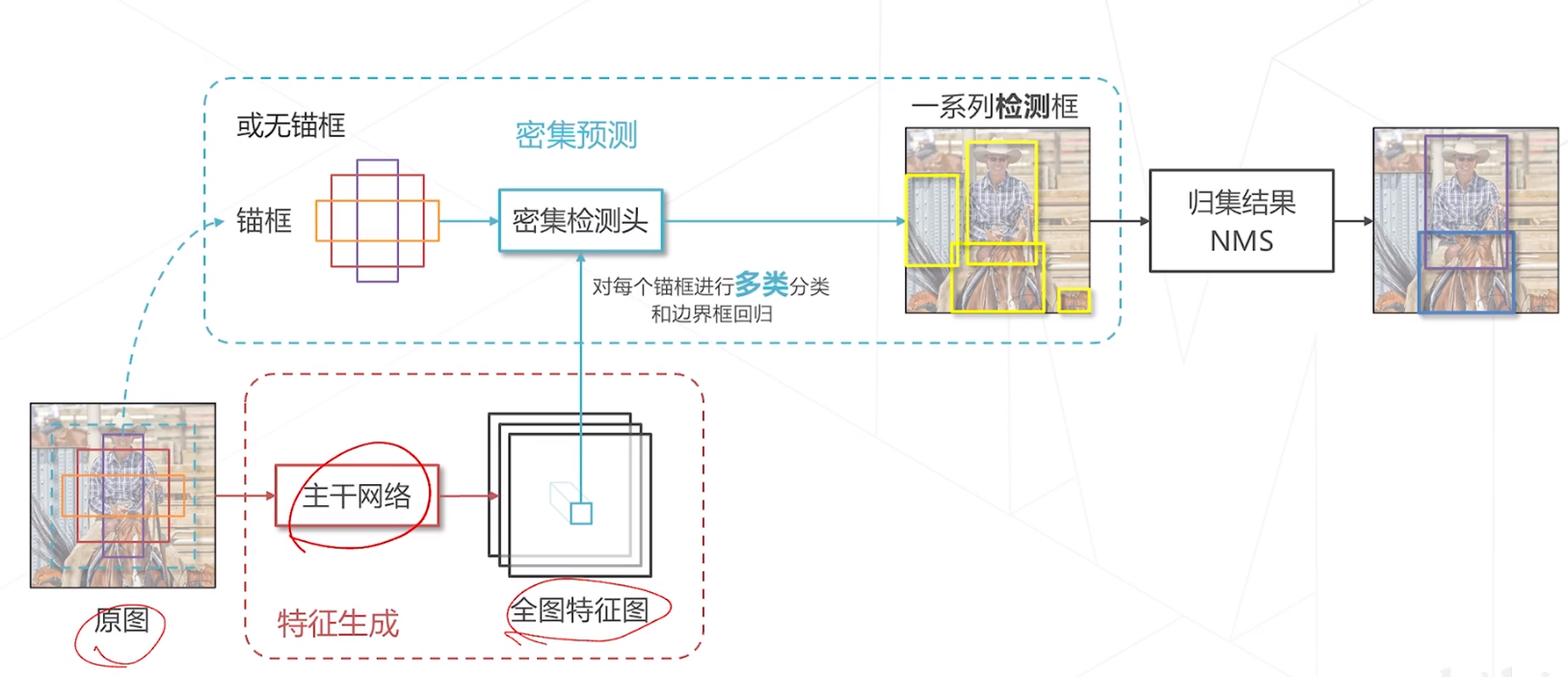
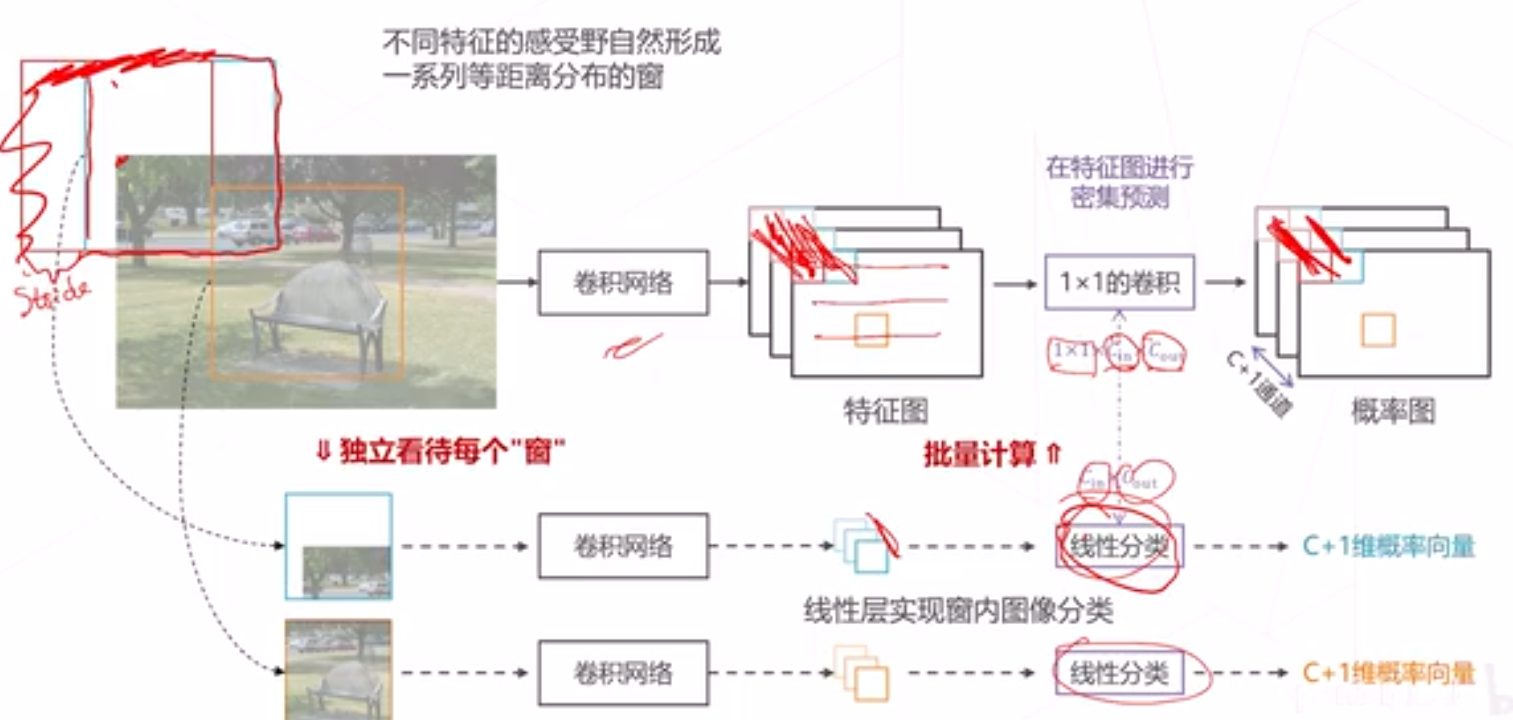
在特征图进行密集计算
得到框中物体的分类概率
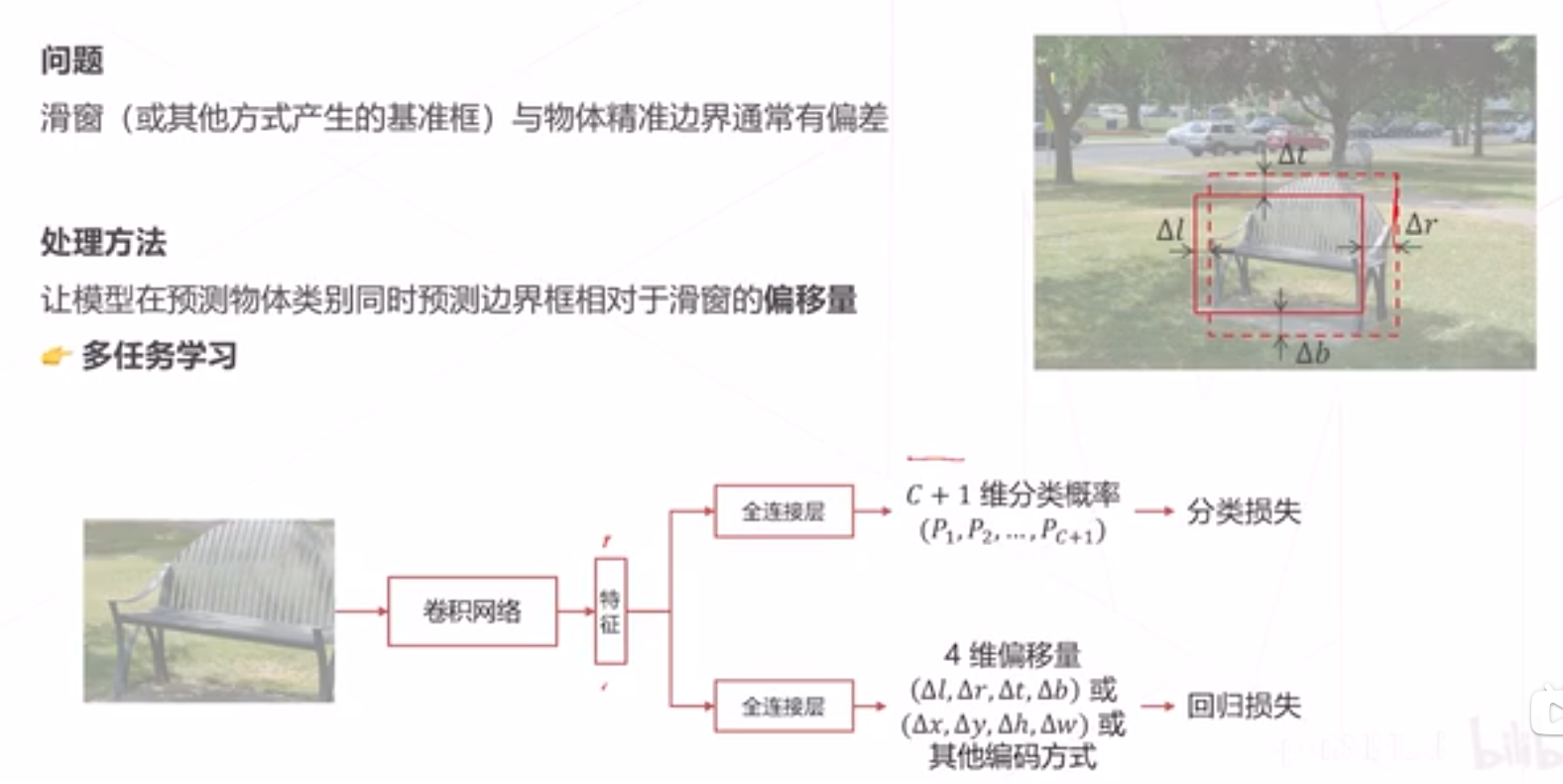
边界框回归
计算出精确的位置!
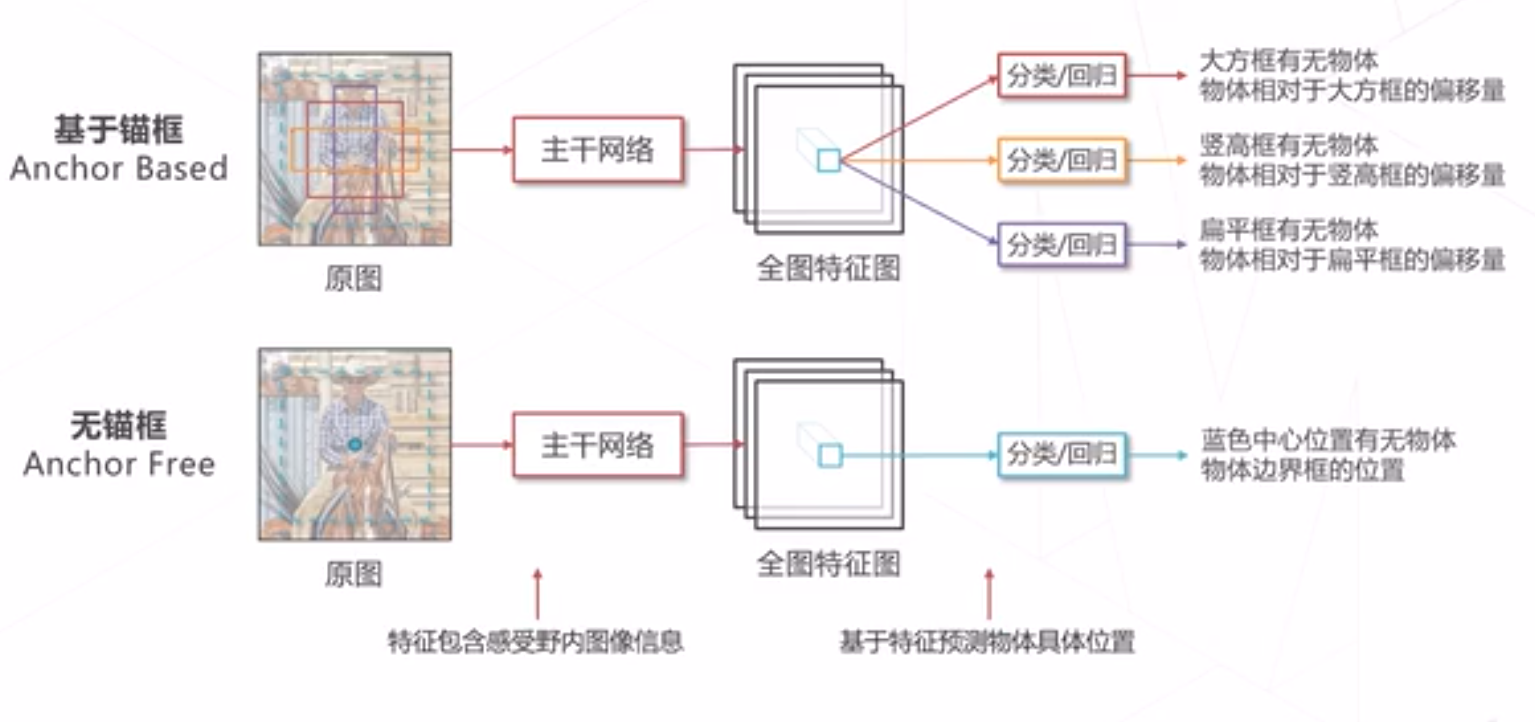
基于锚框VS无锚框
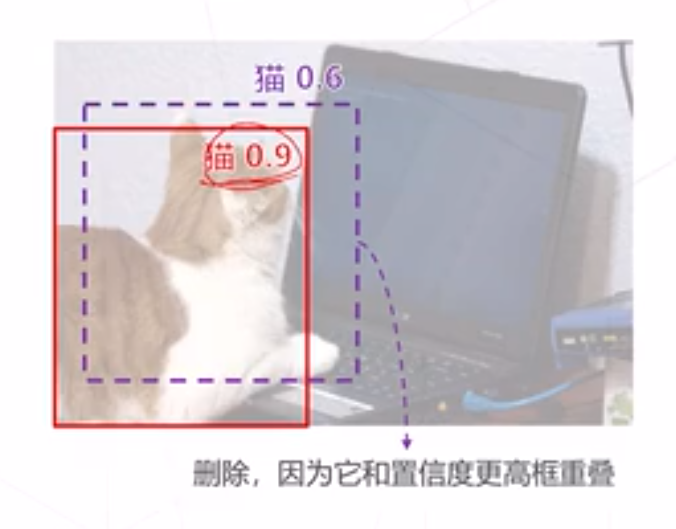
NMS(非极大值抑制)
滑窗类算法通常会在物体周围给出多个相近的检测框 这些框实际指向同一物体,只需要保留其中置信度最高的
使周密集预测模型进行推理步骤
基本流程
- 用模型做密集预测,得到预测图,每个位置包含类别概率、边界框回归的预侧结果
- 保留预训类别不是背景的"框"
- 基于"框"中心,和边界框回归结果,进行边界框解码
- 后处理:非极大值抑制 (Non-Maximum Suppression)
如何训练
如何训练
- 给定图像数据集和标注框,如何训练一个密集预测的检别模型
回想:认练神经网络的一般套路 - 模型基于当前参数给出给出预测
- 计算 loss: 衡量预测的好坏
- 反传 loss、更新参数
如何套用到密集预测中?
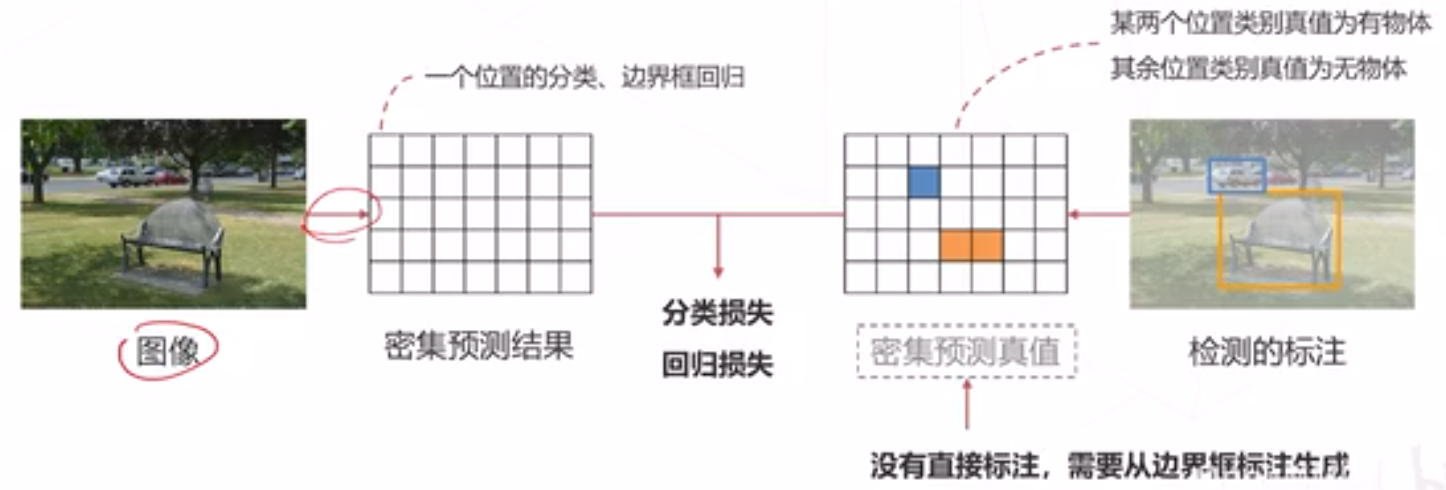
密集预测模型的训练
- 检测头在每个位置产生一个预测 (有无物体、类别、位置偏移量)
- 该预测值应与某个真值比较产生损失,进而才可以训练检测器
- 但这个真值在数据标注中并不存在, 标注只标出了有物体的地方
- 我们需要基于稀疏的标注框为密集预测的结果产生真值,这个过程称为匹聶 (Assignment)
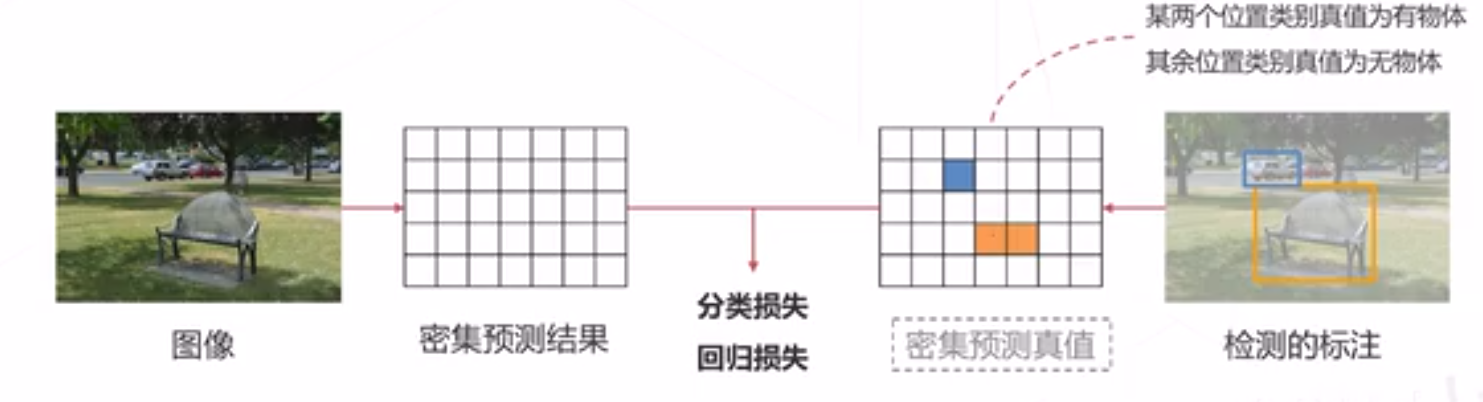
匹配的基本思路
- 对于每个标注框,在特征图上找到与其最接近的位置(可以不止一个),该位置的分类真值设置为对 应的物体
- 位置的接近程度,通常基于中心位置或者与基准框的 IoU 判断
- 其余位置真值为无物体
- 采样:选取一部分正、负样本计算 Loss (例如可以不计算真值框边界位置的loss)
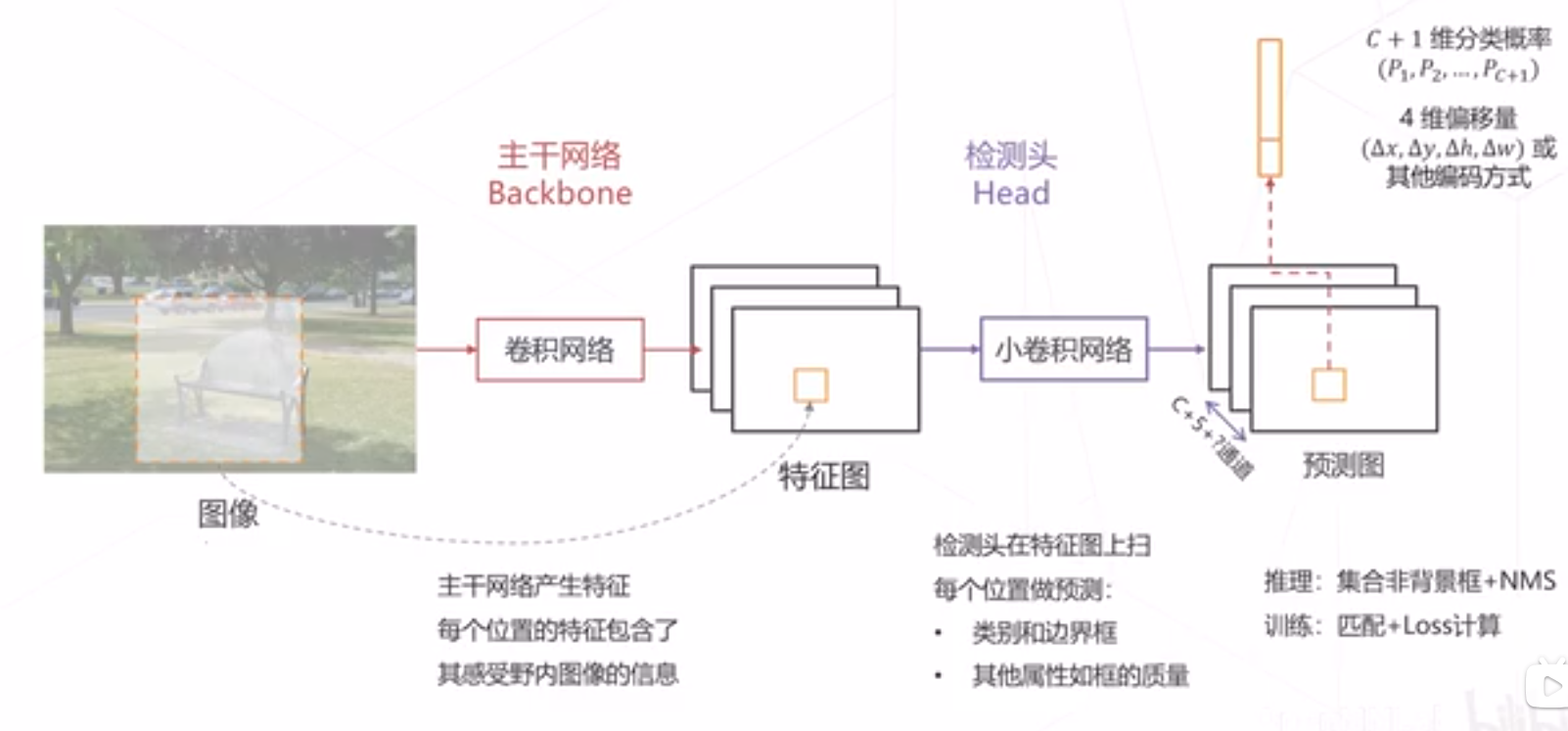
密集检测的基本范式
多尺度预测
如何处理尺度问题
图像中物体大小可能有很大差异
(
10
p
x
∼
500
p
x
)
(10 \mathrm{px} \sim 500 \mathrm{px})
(10px∼500px)
朴素的密集范式中,如果让模型基于主干网络最后一层或倒数第二层特征图进行预测:
- 受限于结构 (感受野), 只擅长中等大小的物体
- 高层特征图经过多次采样,位置信息逐层丢失,小物体检测能力较弱,定位精度较低

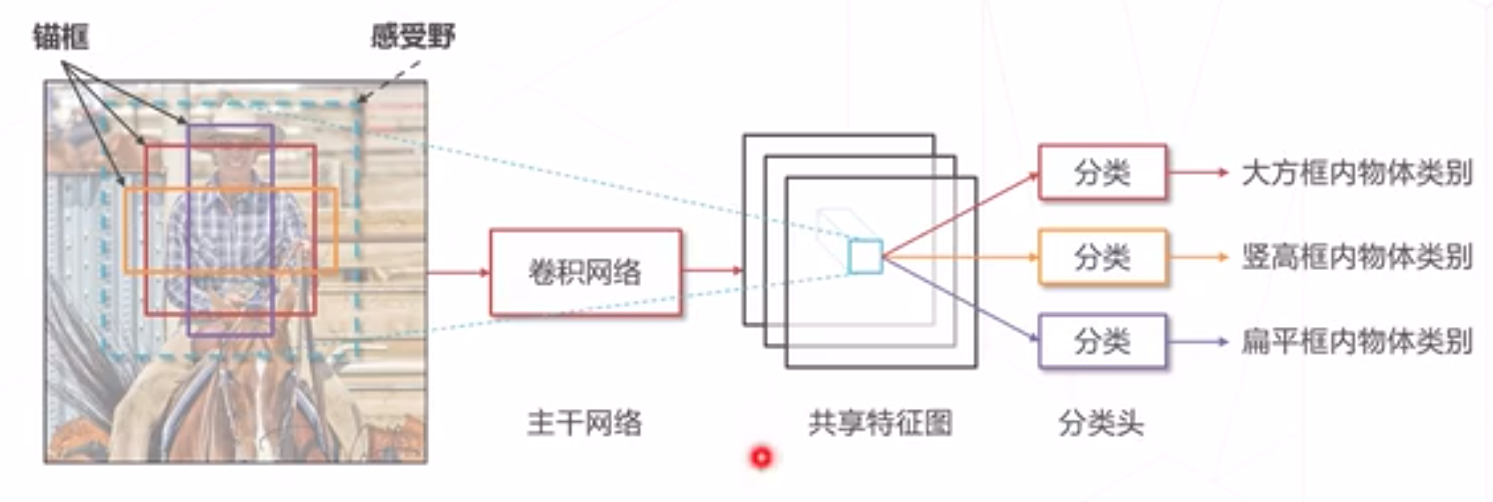
基于锶框(Anchor)
在原图上设置不同尺寸的基准哐,称为锚诓,基于特征分别预测每个锚诓中是否包含物体
(1) 可以生成不同尺寸的预测框
(2) 可以在同一位置生成多个提议框覆盖不同物体
图像金字塔 Image Pyramid
将图像缩放到不同大小,形成图像金字塔
检测算法在不同大小图像上即可检测出不同大小物体
优势:算法不经改动可以适应不同尺度的物体
劣势: 计算成本成倍增加
可用于模型集成等不在意计算成本的情况

基于层次化特征
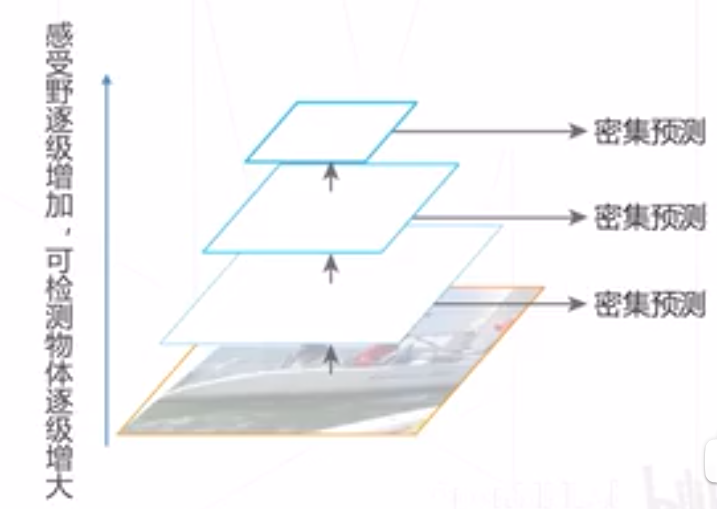
基于主干网络自身产生的多级特征图产生预测结果
由于不同层的感受大小不同,因此不同层级的特征天然适用于检测不同尺寸的物体
优势:计算成本低
劣势: 低层特征抽象级别不够,预测物体比较困难
特征金字塔网络 Feature Pyramid Network (2016)
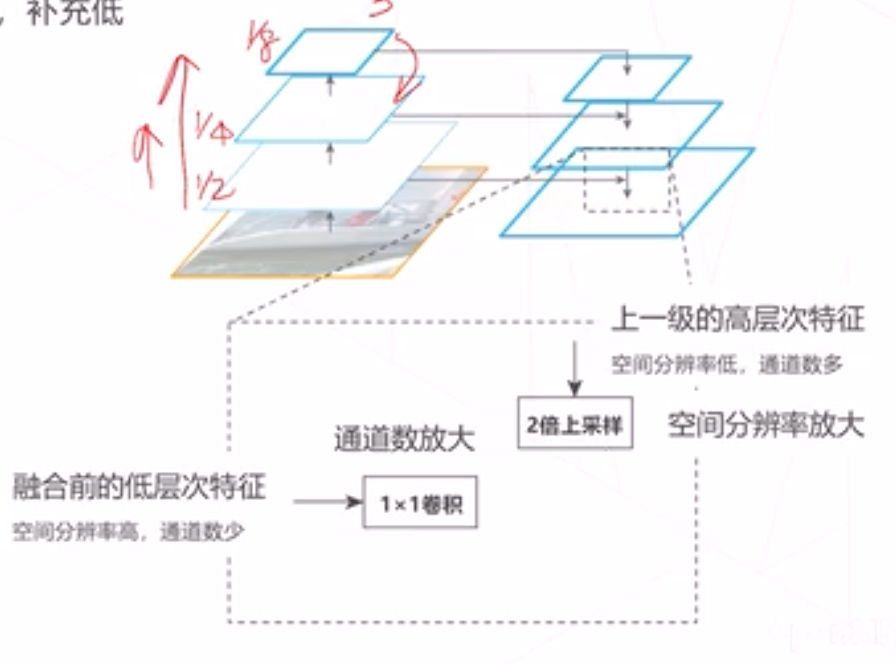
改进思路: 高层次特征包含足㿟抽象语义 信息。将高层特征融入低层特征,补充低 层特征的语义信息
融合方法:特征求和
多尺度的密集预测基本范式
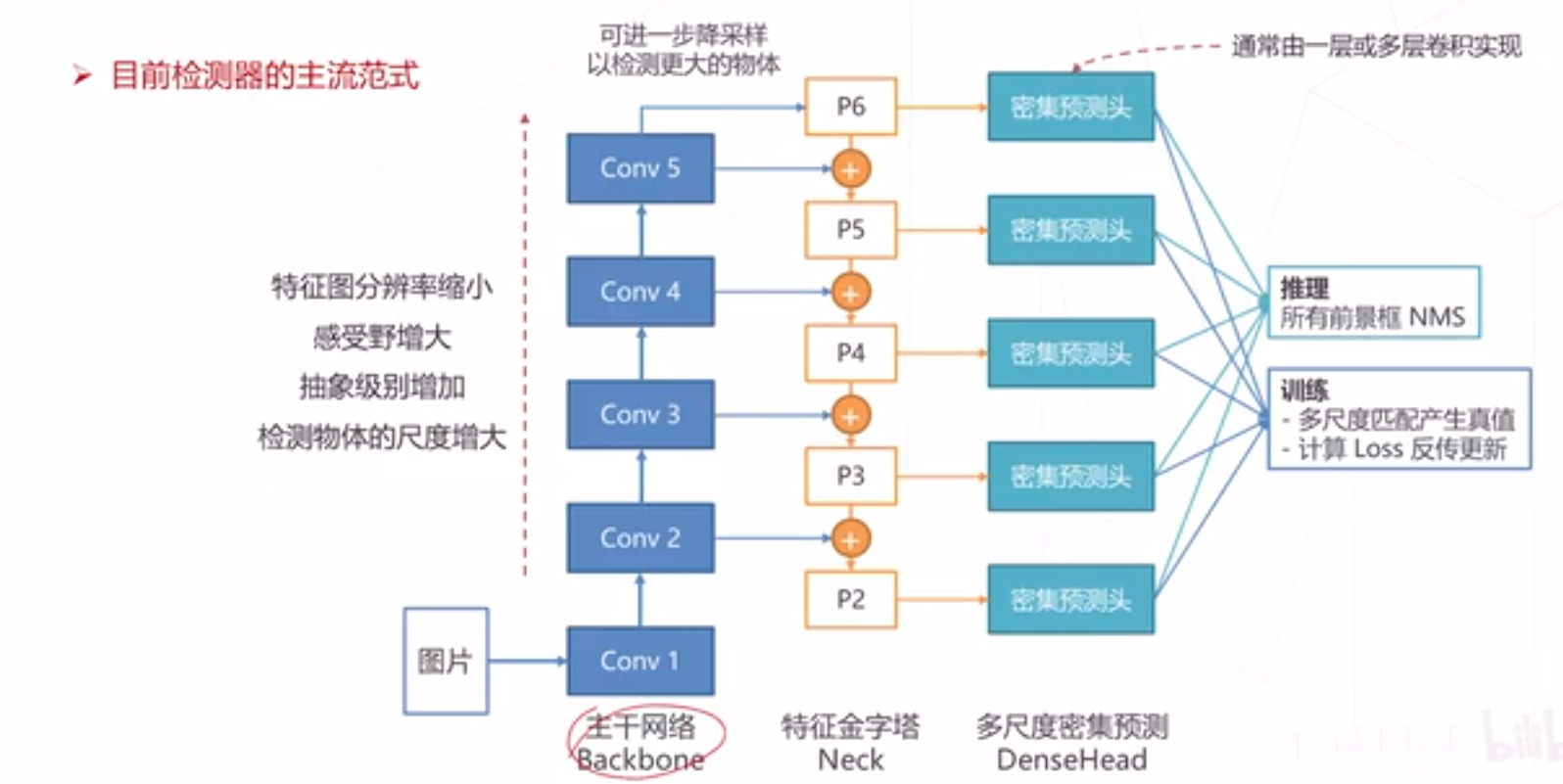
单阶段算法
单阶段算法直接通过密集预郧产生检测框,相比于两阶段算法,模型结构 简单、速度快、易于在设备上部署
早期由于主干网络、多尺度技术等相关技术不成昡,单阶段算法在性能上 不如两阶段算法, 但因为速度和简洁的优势仍受到工业界青睐
随着单阶段算法性能逐渐提升,成为目标检测的主流方法

Region Proposal Network (2015)
- RPN → P r o p o s e R e g i o n = \rightarrow Propose Region = →ProposeRegion= 初步筛选出图像中包含物体的位置,不预测具体类别
- RPN 算"半个检测器", 是二阶段算法 Faster RCNN 的第一阶段
- RPN 是基于密集预测的
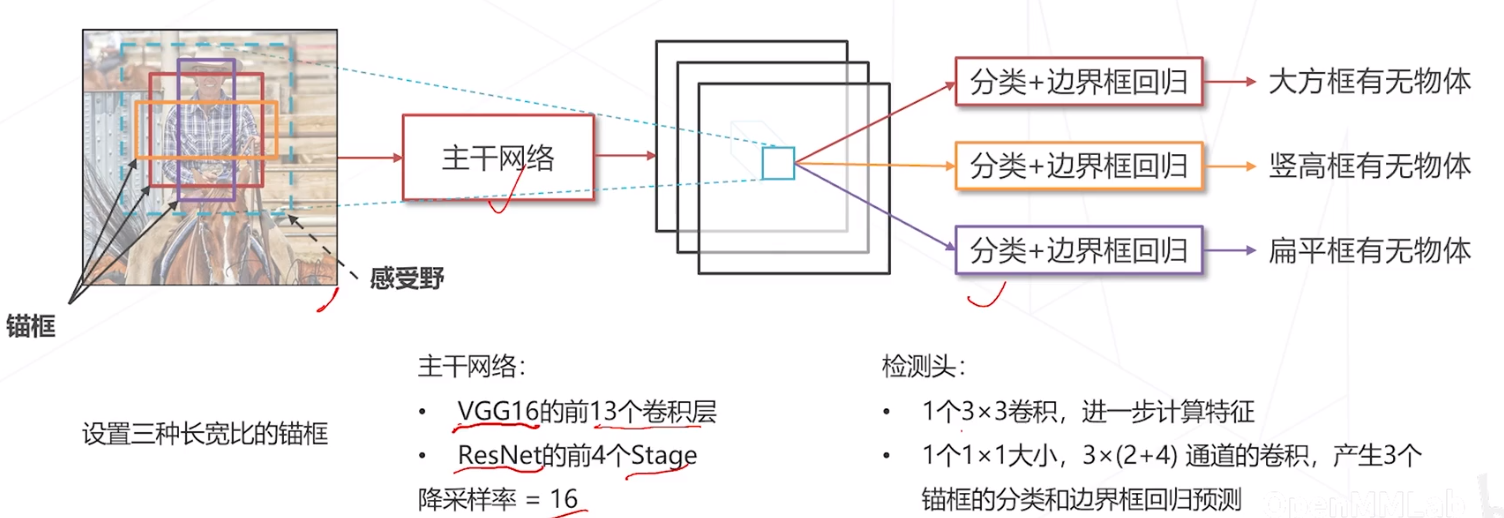
RPN 的主干网络,去掉蓝色区域。
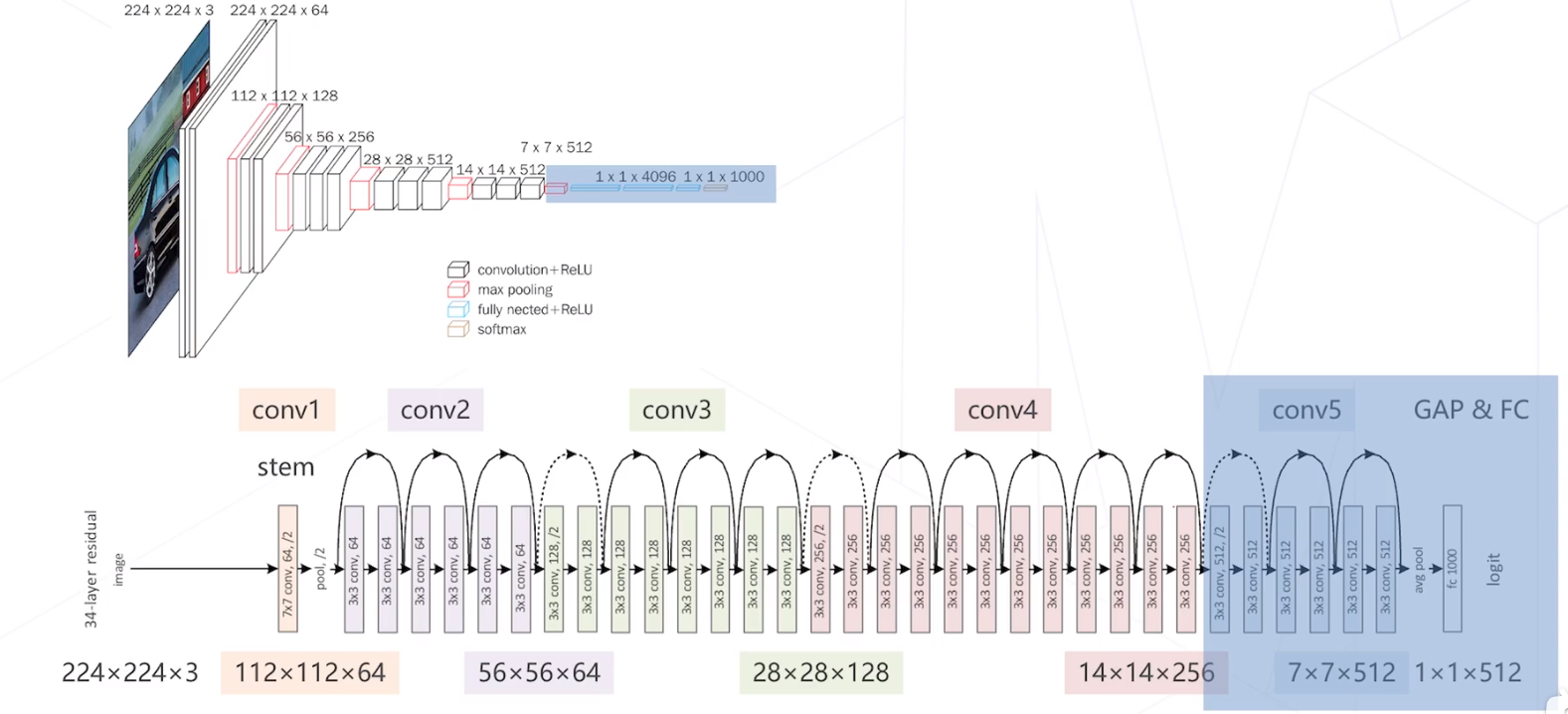
YOLO: You Only Look Once (2015)
最早的单阶段检测器之一, 激发了单阶段算法的研究潮流
主干网络:自行设计的 DarkNet 结构,产生
7
×
7
×
1024
7 \times 7 \times 1024
7×7×1024 维的特征图
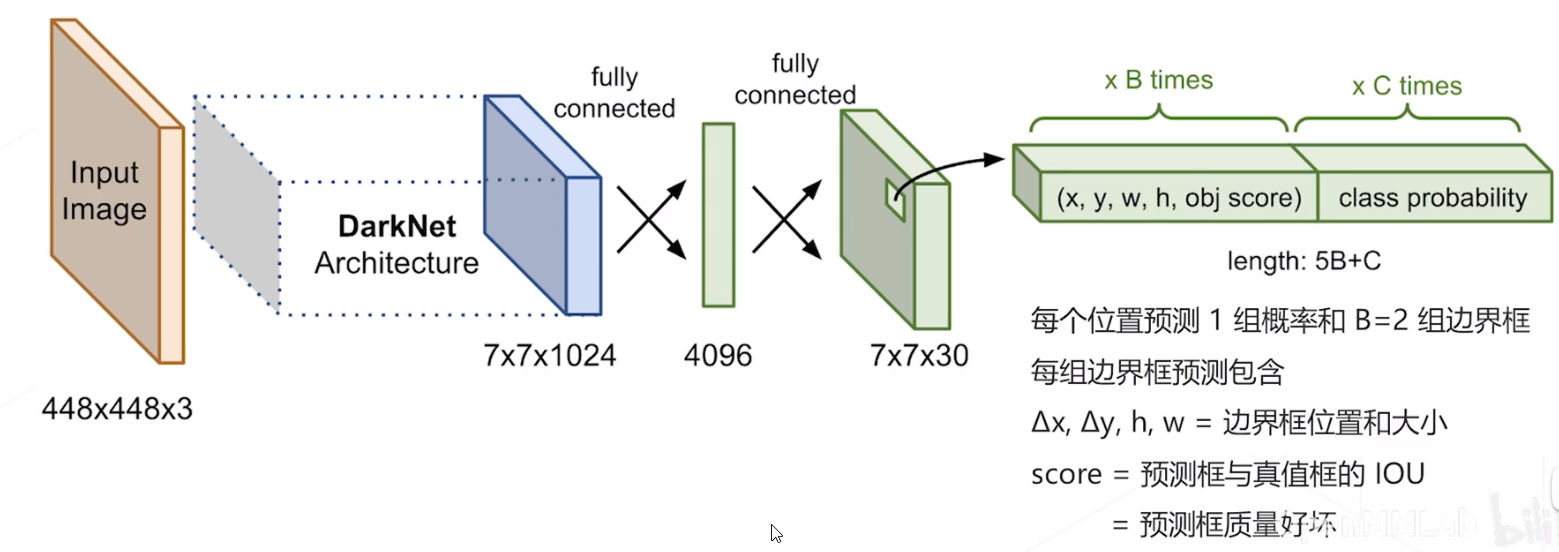
检测头: 2 层全连接层产生
7
×
7
7 \times 7
7×7 组预测结果,对应图中
7
×
7
7 \times 7
7×7 个空间位置上物体的类别和边界框的位置
YOLO 的匹配与框编码
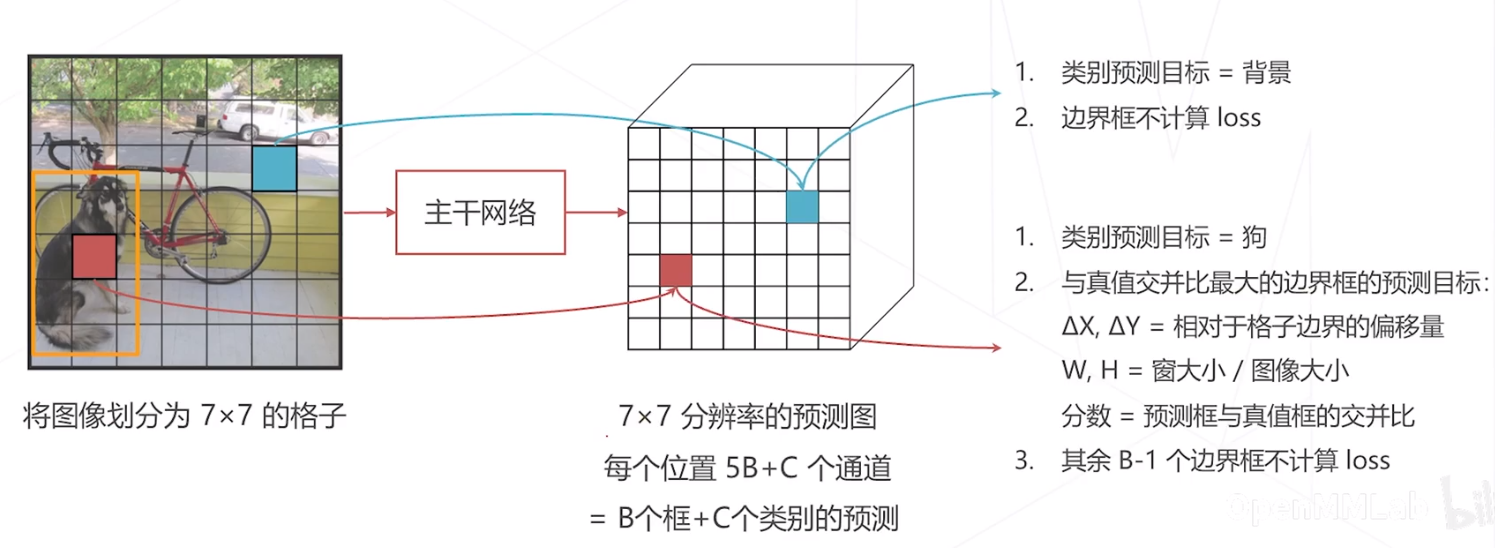
- 将原图切分成 S × S \mathrm{S} \times \mathrm{S} S×S 大小的格子,对应预测图上 S × S \mathrm{S} \times \mathrm{S} S×S 个位置
- 如果原图上某个物体的中心位于某个格子内,则对应位置的预测值应给出物体类别和B组边界框位置
- 其余位置应预测为背景类别,不关心边界框预测结果
YOLO 的优点和缺点
快! 在Pascal VOC 数据集上,使用自己设计的 DarkNet 结构可以达到实时速度,使用相同的 VGG 可以达到 3 倍于 Faster R-CNN 的速度
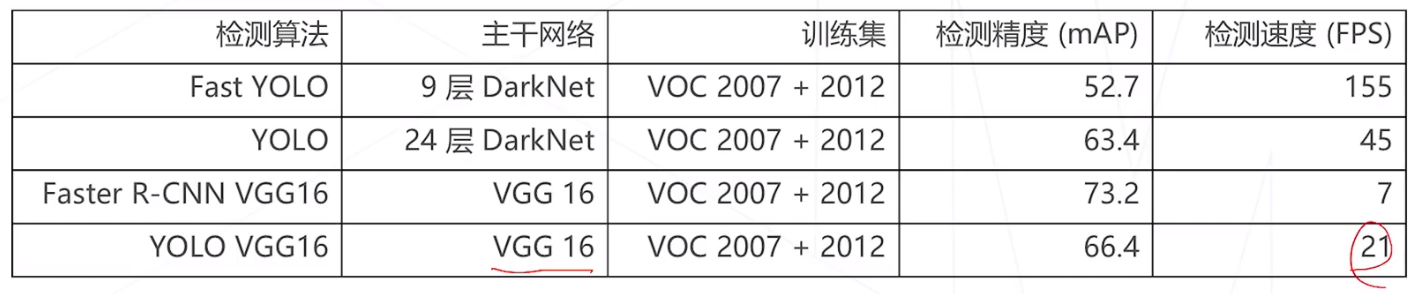
- 由于每个格子只能预测 1 个物体,因此对重叠物体、尤其是大量重叠的小物体容易产生漏检
- 直接回归边界框 (无锚框) 有难度,回归误差较大,YOLO V2 开始使用锚框
SSD: Single Shot MultiBox Detector (2016)
主干网络:使用 VGG + 额外卷积层,产生 11 级特征图
检测头:在 6 级特征图上进行密集预测,产生所有位置、不同尺度的预测结果

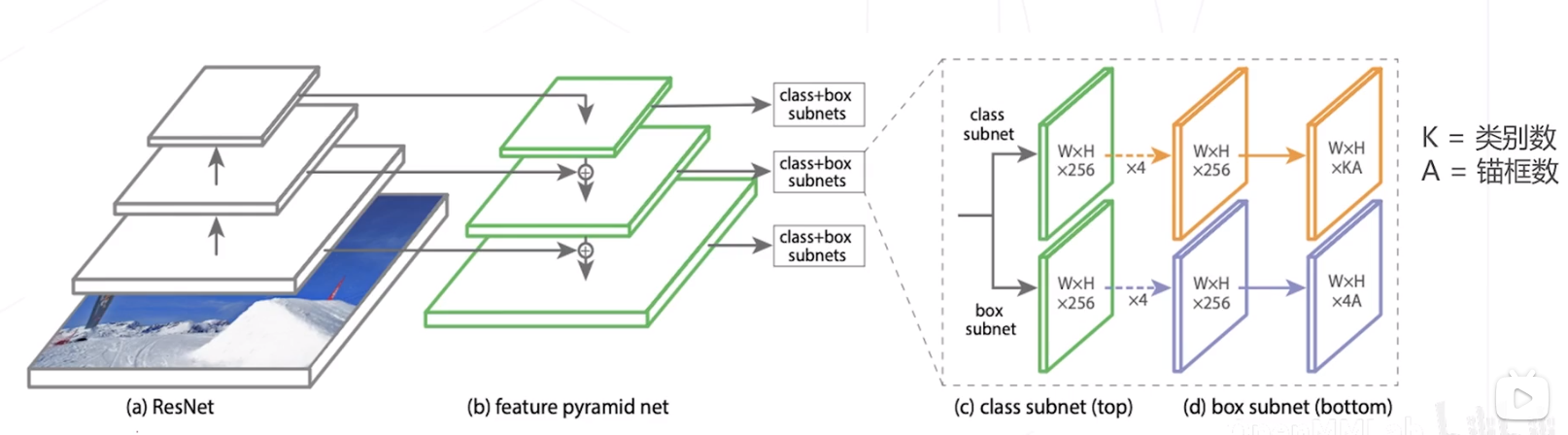
RetinaNet (2017)
特征生成: ResNet 主干网络 + FPN 产生 P_{3} \sim P_{7} 共 5 级特征图,对应降采样率 8 128 倍
多尺度针框:每级特征图上设置 3 种尺寸×3 种长宽比的针框,覆盖 32 813 像素尺寸
密集预测头:两分支、 5 层卷积构成的检测头,针对每个针框产生 K 个二类预测以及 4 个边界框偏移量 损失函数: Focal Loss
单阶段算法面临的正负样本不均衡问题
- 单阶段算法共产生尺度数 × \times × 位置数 × \times × 针框数个预测
- 而这些预测之中,只有少量针框的真值为物体 (正样本),大部分针框的真值为背景(负样本)

YOLO v3 (2018)
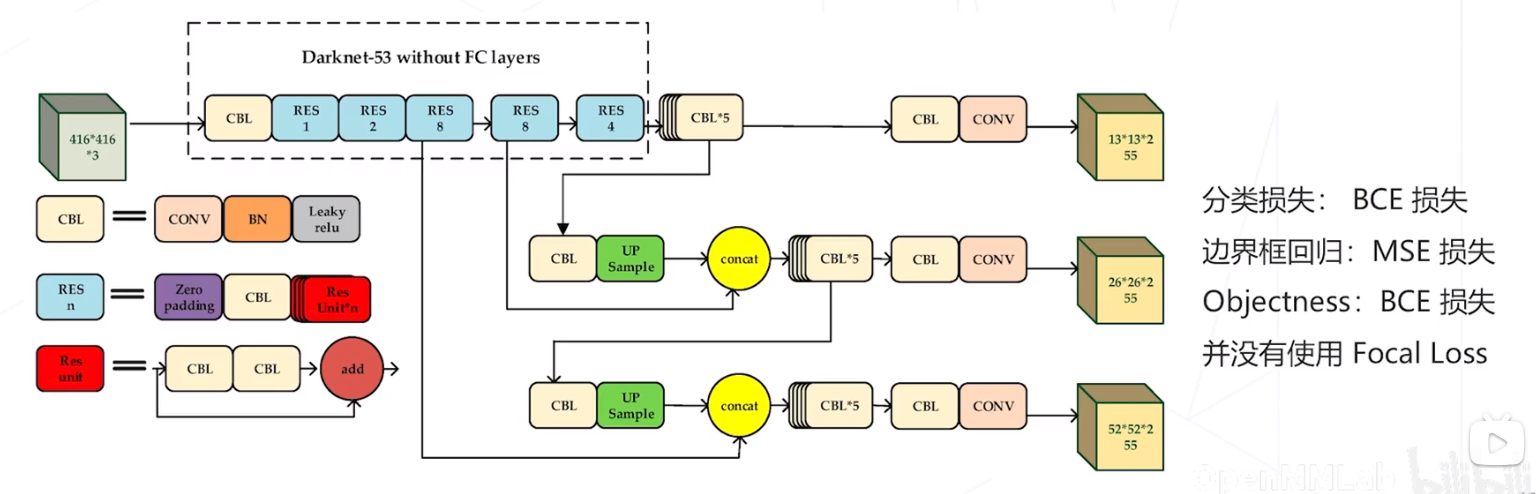
- 自定义的 DarkNet-53 主干网络和类 FPN 结构,产生 1/8、1/16、1/32 降采样率的 3 级特征图
- 在每级特征图上设置 3 个尺寸的针框,针框尺寸通过对真值框聚类得到
- 两层卷积构成的密集预测头,在每个位置、针对每个锚框产生 80 个类别预测、4个边界框偏移量、1个 objectness 预 测,每级特征图 3 × ( 80 + 4 + 1 ) = 255 3 \times(80+4+1)=255 3×(80+4+1)=255 通道的预测值
无锚框算法
基于锚框VS 无锚框

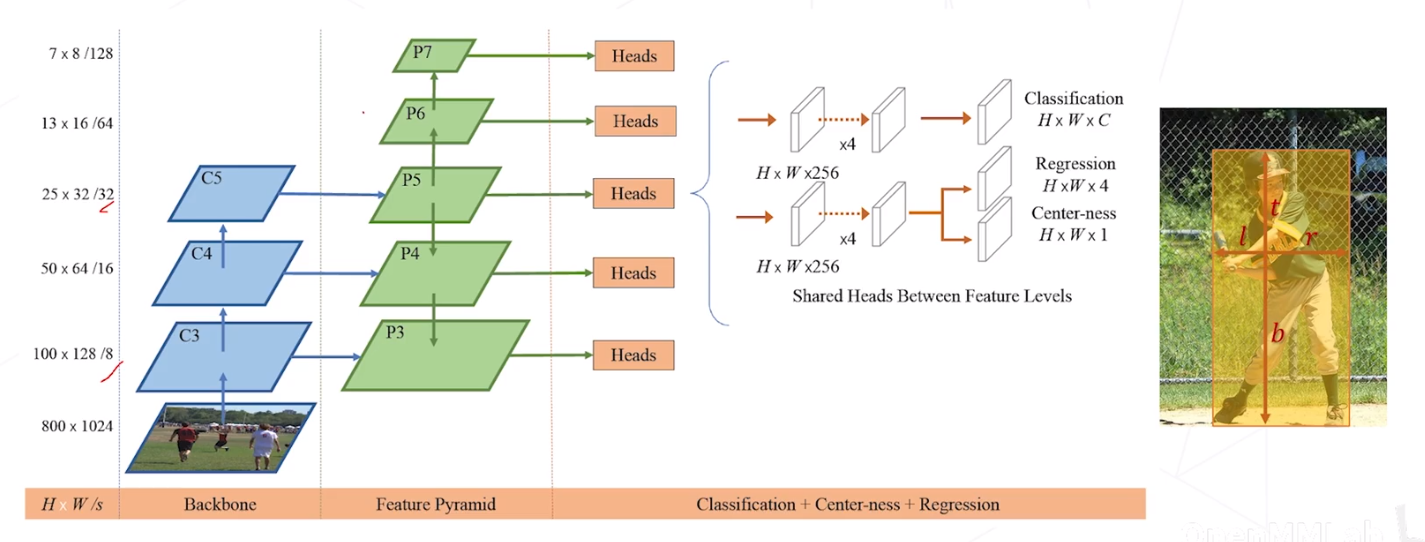
FCOS, Fully Convolutional One-Stage (2019)
模型结构与 RetinaNet 基本相同: 主干网络 + FPN +两分支、5 层卷积构成的密集预测头 预测目标不同:对于每个点位,预测类别、边界框位置和中心度三组数值
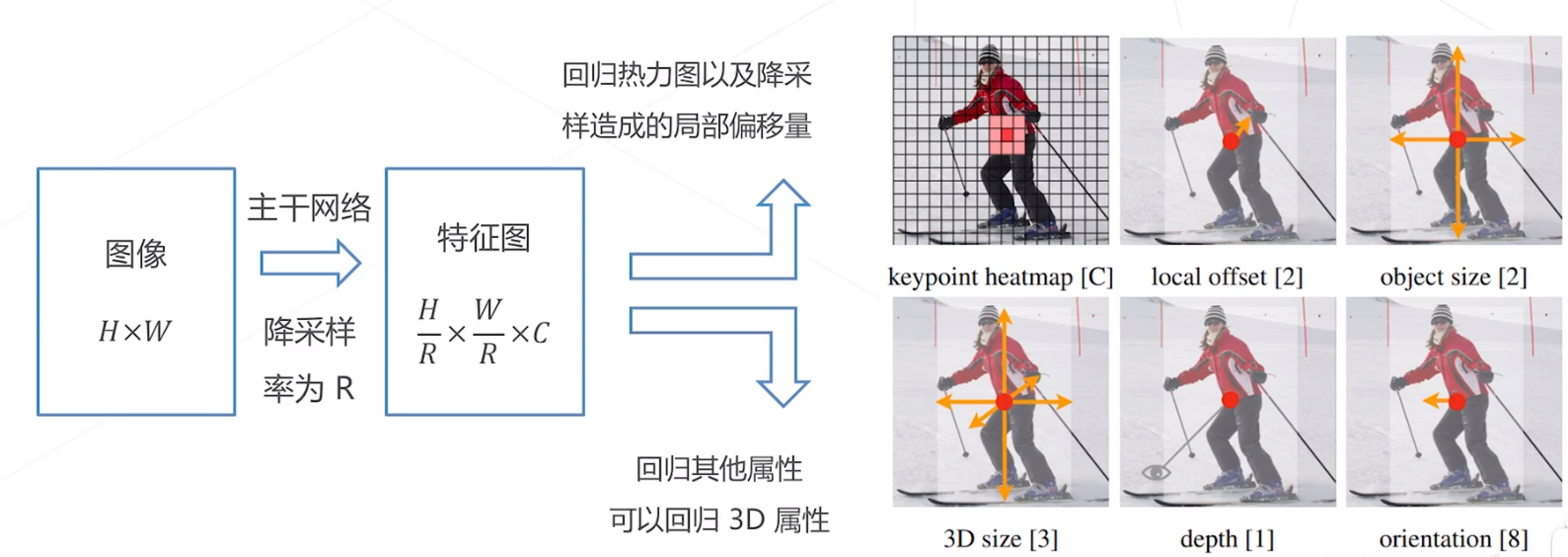
CenterNet (2019)
针对 2 D 检测的算法,将传统检测算法中的 “以框表示物体" 变成 “以中心点表示物体",将 2D 检测建模 为关键点检测和额外的回归任务,一个框架可以同时覆盖 2 D 检测、3D 检测、姿态估计等一系列任务
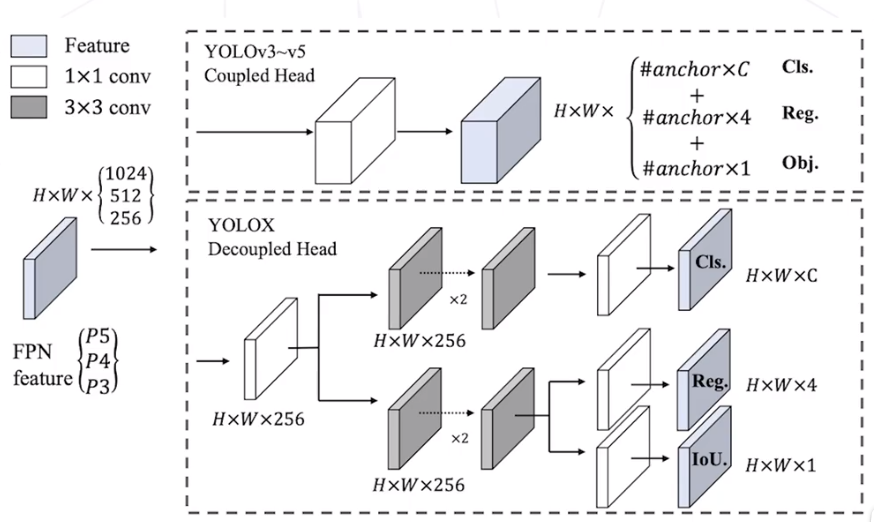
YOLO X (2021)
以 YOLO V3 为基准模型改进的无针框检测器
- Decouple Head 结构
- 更多现代数据增强策略
- SimOTA 分配策略
- 从小到大的一系列模型
SOTA 的精度和速度
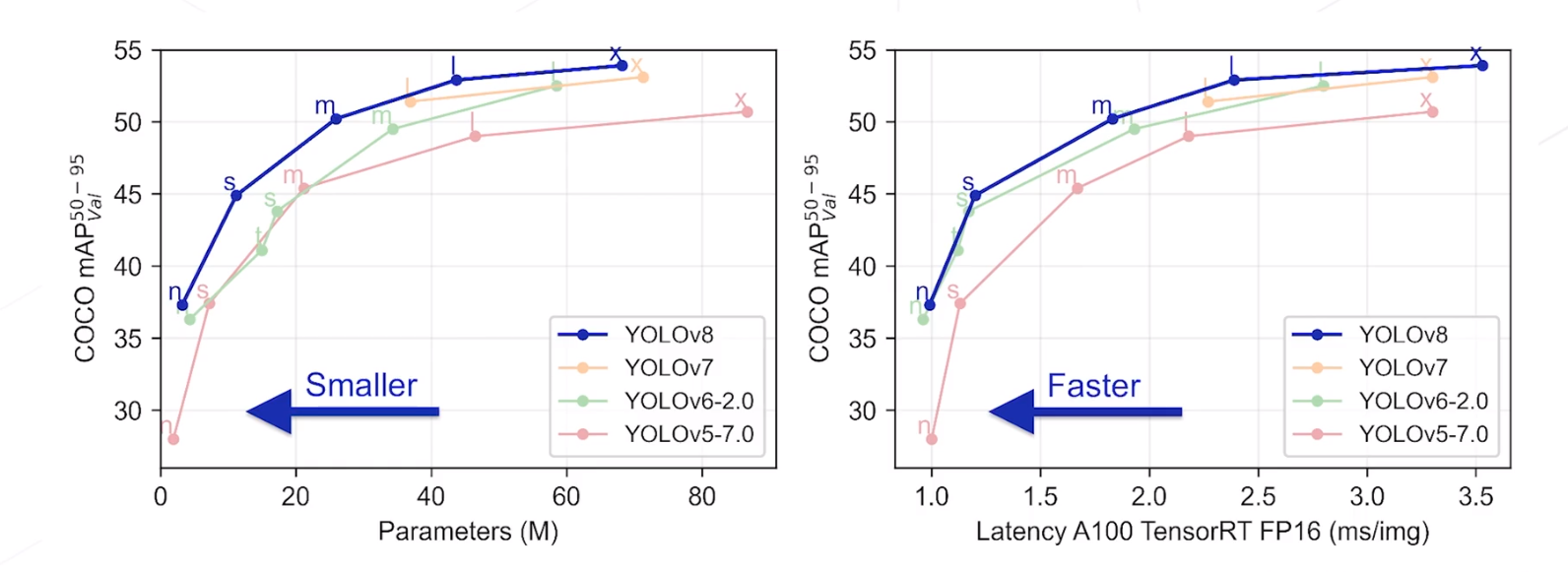
YoloV8
单阶段算法和元铓框算法的总结