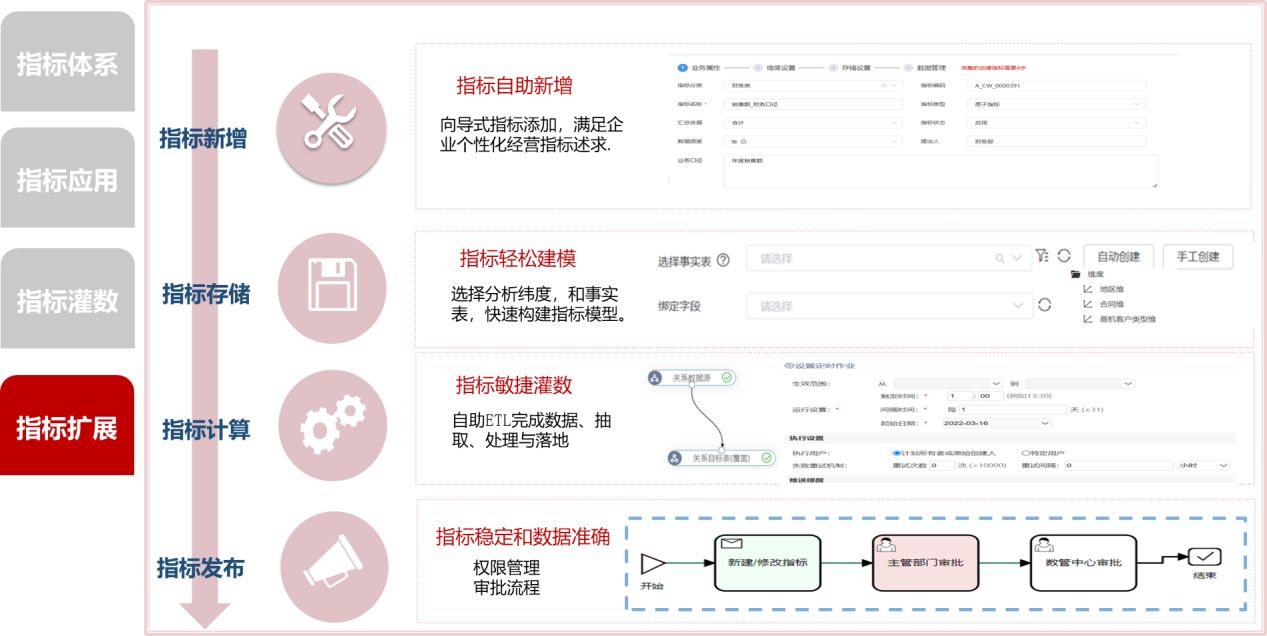
认识数据湖加速器Data Lake Accelerator Goose FileSystem,GooseFS
- 一、产品概述
- 二、产品功能
- 三、产品优势
- 四、快速入门
- 五、使用 GooseFS 预热 Table 中的数据
- 六、使用 GooseFS 进行文件上传和下载操作
- 七、使用 GooseFS 加速文件上传和下载操作
- 八、关闭 GooseFS
- 九、挂载CHDFS
- 十、大数据场景生产环境配置实践
一、产品概述
- 数据湖加速器(Data Lake Accelerator Goose FileSystem,GooseFS),是由腾讯云推出的高可靠、高可用、弹性的数据湖加速服务。依靠对象存储(Cloud Object Storage,COS)作为数据湖存储底座的成本优势,为数据湖生态中的计算应用提供统一的数据湖入口,加速海量数据分析、机器学习、人工智能等业务访问存储的性能;采用了分布式集群架构,具备弹性、高可靠、高可用等特性,为上层计算应用提供统一的命名空间和访问协议,方便用户在不同的存储系统管理和流转数据。
二、产品功能
GooseFS 旨在提供一站式的缓存解决方案,在利用数据本地性和高速缓存,统一存储访问语义等方面具有天然的优势;GooseFS 在腾讯云数据湖生态中扮演着“上承计算,下启存储”的核心角色,如下图所示。
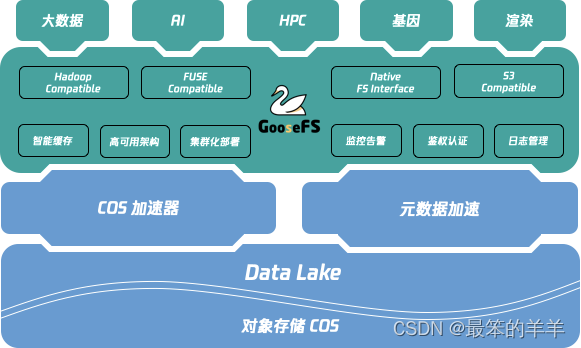
GooseFS 提供了以下功能:
- 缓存加速和数据本地化(Locality):GooseFS 可以与计算节点混合部署提高数据本地性,利用高速缓存功能解决存储性能问题,提高写入 COS 的带宽。
- 融合存储语义:GooseFS 提供 UFS(Unified FileSystem)的语义,可以支持 COS、Hadoop、S3、K8S CSI、 FUSE 等多个存储语义,使用于多种生态和应用场景。
- 统一的腾讯云相关生态服务:包括日志、鉴权、监控,实现了与 COS 操作统一。
- 提供 Namespace 管理能力,针对不同业务、不同的Under File System,提供不同的读写缓存策略以及生命周期(TTL)管理。
- 感知 Table 元数据功能:对于大数据场景下数据 Table,提供 GooseFS Catalog 用于感知元数据 Table ,提供 Table 级别的 Cache 预热。
三、产品优势
GooseFS 在数据湖场景中具有如下几点明显的优势:
数据 I/O 性能
GooseFS 部署提供近计算端的分布式共享缓存,上层计算应用可以透明地、高效地从远端存储将需要频繁访问的热数据缓存到近计算端,加速数据 I/O 性能。GooseFS 提供了元数据缓存功能,可以加速大数据场景下查询文件数据以及列出文件列表等元数据操作的性能。配合大数据存储桶使用,还可进一步加速重命名文件的操作性能。此外,业务可以按需选择 MEM、SSD、NVME 以及 HDD 盘等不同的存储介质,平衡业务成本和数据访问性能。
存储一体化
GooseFS 提供了统一的命名空间,不仅支持了对象存储 COS 存储语义,也支持 HDFS、K8S CSI 以及 FUSE 等语义,为上层业务提供了一体化的融合存储方案,简化业务侧运维配置。存储一体化能够打通不同数据底座的壁垒,方便上层应用管理和流转数据,提升数据利用的效率。
生态亲和性
GooseFS 全兼容腾讯云大数据平台框架,也支持客户侧自定义的本地部署,具备优秀的生态亲和性。业务侧不仅可以在腾讯云弹性 MapReduce 产品中使用 GooseFS 加速大数据业务,也可以便捷地将 GooseFS 本地化部署在公有云 CVM 或者自建 IDC 内。此外,GooseFS 支持透明加速能力,对于已经使用腾讯云 COSN 和 CHDFS 的用户,只需做简单的配置修改,即可实现不修改任何业务代码和访问路径的前提下,自动使用GooseFS 加速 COSN 和 CHDFS 的业务访问。
四、快速入门
本部分主要提供 GooseFS 快速部署、调试的相关指引,提供在本地机器上部署 GooseFS,并将对象存储(Cloud Object Storage,COS)作为远端存储的步骤指引,具体步骤如下:
前提条件
在使用 GooseFS 之前,您还需要准备以下工作:
- 在 COS 服务上创建一个存储桶以作为远端存储,操作指引请参见 控制台快速入门。
- 安装 Java 8 或者更高的版本。
- 安装 SSH,确保能通过 SSH 连接到 LocalHost,并远程登录。
- 在 CVM 服务上购买一台实例,操作指引详见 购买云服务器,并确保磁盘已经挂载到实例上。
下载并配置 GooseFS
1.新建本地目录并进入该目录下(您也可以按需选择其他目录),从官方仓库下载 GooseFS 安装包到本地。安装包 Github 地址:goosefs-1.4.2-bin.tar.gz。
$ cd /usr/local
$ mkdir /service
$ cd /service
$ wget https://downloads.tencentgoosefs.cn/goosefs/1.4.2/release/goosefs-1.4.2-bin.tar.gz
2.执行如下命令,对安装包进行解压,解压后进入安装包目录下。
$ tar -zxvf goosefs-1.4.2-bin.tar.gz
$ cd goosefs-1.4.2
解压后,得到 goosefs-1.4.2,即 GooseFS 的主目录。下文将以 ${GOOSEFS_HOME} 代指该目录的绝对路径。
3.在 ${GOOSEFS_HOME}/conf 的目录下,创建 conf/goosefs-site.properties 的配置文件。GooseFS 提供 AI 和大数据两个场景的配置模板,可以使用任意上述内置模板,然后进入编辑模式修改配置:
(1)使用 AI 场景模板
$ cp conf/goosefs-site.properties.ai_template conf/goosefs-site.properties
$ vim conf/goosefs-site.properties
(2)使用大数据场景模板。
$ cp conf/goosefs-site.properties.bigdata_template conf/goosefs-site.properties
$ vim conf/goosefs-site.properties
4.在配置文件 conf/goosefs-site.properties 中,调整如下配置项:
# Common properties
# 调整Master节点host信息
goosefs.master.hostname=localhost
goosefs.master.mount.table.root.ufs=${goosefs.work.dir}/underFSStorage
# Security properties
# 调整权限配置
goosefs.security.authorization.permission.enabled=true
goosefs.security.authentication.type=SIMPLE
# Worker properties
# 调整worker节点配置,指定本地缓存介质、缓存路径和缓存容量大小
goosefs.worker.ramdisk.size=1GB
goosefs.worker.tieredstore.levels=1
goosefs.worker.tieredstore.level0.alias=SSD
goosefs.worker.tieredstore.level0.dirs.path=/data
goosefs.worker.tieredstore.level0.dirs.quota=80G
# User properties
# 指定文件读写缓存策略
goosefs.user.file.readtype.default=CACHE
goosefs.user.file.writetype.default=MUST_CACHE
注意:
配置 goosefs.worker.tieredstore.level0.dirs.path 该路径参数前,需要先新建这一路径。
启用 GooseFS
1.启用 GooseFS 前,需要进入到 GooseFS 目录下执行启动指令:
$ cd /usr/local/service/goosefs-1.4.2
$ ./bin/goosefs-start.sh all
执行该指令后,可以看到如下页面:
该命令执行完毕后,可以访问 http://localhost:9201 和 http://localhost:9204,分别查看 Master 和 Worker 的运行状态。
使用 GooseFS 挂载 COS(COSN) 或腾讯云 HDFS(CHDFS)
如果 GooseFS 需要挂载 COS(COSN)或腾讯云 HDFS(CHDFS)到 GooseFS 的根路径上,则需要先在 conf/core-site.xml 配置中指定 COSN 或 CHDFS 的必需配置项,其中包括但不限于:fs.cosn.impl 、 fs.AbstractFileSystem.cosn.impl 以及 fs.cosn.userinfo.secretId 和 fs.cosn.userinfo.secretKey 等,如下所示:
<!-- COSN related configurations -->
<property>
<name>fs.cosn.impl</name>
<value>org.apache.hadoop.fs.CosFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.cosn.impl</name>
<value>com.qcloud.cos.goosefs.CosN</value>
</property>
<property>
<name>fs.cosn.userinfo.secretId</name>
<value></value>
</property>
<property>
<name>fs.cosn.userinfo.secretKey</name>
<value></value>
</property>
<property>
<name>fs.cosn.bucket.region</name>
<value></value>
</property>
<!-- CHDFS related configurations -->
<property>
<name>fs.AbstractFileSystem.ofs.impl</name>
<value>com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter</value>
</property>
<property>
<name>fs.ofs.impl</name>
<value>com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter</value>
</property>
<property>
<name>fs.ofs.tmp.cache.dir</name>
<value>/data/chdfs_tmp_cache</value>
</property>
<!--appId-->
<property>
<name>fs.ofs.user.appid</name>
<value>1250000000</value>
</property>
下面将介绍一下如何通过创建 Namespace 来挂载 COS 或 CHDFS 的方法和步骤。
1.创建一个命名空间 namespace 并挂载 COS:
$ goosefs ns create myNamespace cosn://bucketName-1250000000/ \
--secret fs.cosn.userinfo.secretId=AKXXXXXXXXXXX \
--secret fs.cosn.userinfo.secretKey=XXXXXXXXXXXX \
--attribute fs.cosn.bucket.region=ap-xxx \
注意:
创建挂载 COSN 的 namespace 时,必须使用 –-secret 参数指定访问密钥,并且使用 --attribute 指定 Hadoop-COS(COSN)所有必选参数,具体的必选参数可参考 Hadoop 工具。
创建 Namespace 时,如果没有指定读写策略(rPolicy/wPolicy),默认会使用配置文件中指定的 read/write type,或使用默认值(CACHE/CACHE_THROUGH)。
同理,也可以创建一个命名空间 namespace 用于挂载腾讯云 HDFS:
goosefs ns create MyNamespaceCHDFS ofs://xxxxx-xxxx.chdfs.ap-guangzhou.myqcloud.com/ \
--attribute fs.ofs.user.appid=1250000000
--attribute fs.ofs.tmp.cache.dir=/tmp/chdfs
2.创建成功后,可以通过 ls 命令列出集群中创建的所有 namespace:
$ goosefs ns ls
namespace mountPoint ufsPath creationTime wPolicy rPolicy TTL ttlAction
myNamespace /myNamespace cosn://bucketName-125xxxxxx/3TB 03-11-2021 11:43:06:239 CACHE_THROUGH CACHE -1 DELETE
myNamespaceCHDFS /myNamespaceCHDFS ofs://xxxxx-xxxx.chdfs.ap-guangzhou.myqcloud.com/3TB 03-11-2021 11:45:12:336 CACHE_THROUGH CACHE -1 DELETE
3.执行如下命令,指定 namespace 的详细信息。
$ goosefs ns stat myNamespace
NamespaceStatus{name=myNamespace, path=/myNamespace, ttlTime=-1, ttlAction=DELETE, ufsPath=cosn://bucketName-125xxxxxx/3TB, creationTimeMs=1615434186076, lastModificationTimeMs=1615436308143, lastAccessTimeMs=1615436308143, persistenceState=PERSISTED, mountPoint=true, mountId=4948824396519771065, acl=user::rwx,group::rwx,other::rwx, defaultAcl=, owner=user1, group=user1, mode=511, writePolicy=CACHE_THROUGH, readPolicy=CACHE}
五、使用 GooseFS 预热 Table 中的数据
1.GooseFS 支持将 Hive Table 中的数据预热到 GooseFS 中,在预热之前需要先将相关的 DB 关联到 GooseFS 上,相关命令如下:
$ goosefs table attachdb --db test_db hive thrift://
172.16.16.22:7004 test_for_demo
注意:命令中的 thrift 需要填写实际的 Hive Metastore 的地址。
2.添加完 DB 后,可以通过 ls 命令查看当前关联的 DB 和 Table 的信息:
$ goosefs table ls test_db web_page
OWNER: hadoop
DBNAME.TABLENAME: testdb.web_page (
wp_web_page_sk bigint,
wp_web_page_id string,
wp_rec_start_date string,
wp_rec_end_date string,
wp_creation_date_sk bigint,
wp_access_date_sk bigint,
wp_autogen_flag string,
wp_customer_sk bigint,
wp_url string,
wp_type string,
wp_char_count int,
wp_link_count int,
wp_image_count int,
wp_max_ad_count int,
)
PARTITIONED BY (
)
LOCATION (
gfs://172.16.16.22:9200/myNamespace/3000/web_page
)
PARTITION LIST (
{
partitionName: web_page
location: gfs://172.16.16.22:9200/myNamespace/3000/web_page
}
)
3.通过 load 命令预热 Table 中的数据:
$ goosefs table load test_db web_page
Asynchronous job submitted successfully, jobId: 1615966078836
预热 Table 中的数据是一个异步任务,因此会返回一个任务 ID。可以通过 goosefs job stat <Job Id> 命令查看预热作业的执行进度。当状态为 “COMPLETED” 后,则整个预热过程完成。
六、使用 GooseFS 进行文件上传和下载操作
1.GooseFS 支持绝大部分文件系统操作命令,可以通过以下命令来查询当前支持的命令列表:
$ goosefs fs
2.可以通过 ls 命令列出 GooseFS 中的文件,以下示例展示如何列出根目录下的所有文件:
$ goosefs fs ls /
3.可以通过 copyFromLocal 命令将数据从本地拷贝到 GooseFS 中:
$ goosefs fs copyFromLocal LICENSE /LICENSE
Copied LICENSE to /LICENSE
$ goosefs fs ls /LICENSE
-rw-r--r-- hadoop supergroup 20798 NOT_PERSISTED 03-26-2021 16:49:37:215 0% /LICENSE
4.可以通过 cat 命令查看文件内容:
$ goosefs fs cat /LICENSE
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
...
5.GooseFS 默认使用本地磁盘作为底层文件系统,默认文件系统路径为 ./underFSStorage,可以通过 persist 命令将文件持久化存储到本地文件系统中:
$ goosefs fs persist /LICENSE
persisted file /LICENSE with size 26847
七、使用 GooseFS 加速文件上传和下载操作
1.检查文件存储状态,确认文件是否已被缓存。文件状态 PERSISTED 代表文件已在内存中,文件状态 NOT_PERSISTED 则代表文件不在内存中:
$ goosefs fs ls /data/cos/sample_tweets_150m.csv
-r-x------ staff staff 157046046 NOT_PERSISTED 01-09-2018 16:35:01:002 0% /data/cos/sample_tweets_150m.csv
2.统计文件中有多少单词 “tencent”,并计算操作耗时:
$ time goosefs fs cat /data/s3/sample_tweets_150m.csv | grep-c tencent
889
real 0m22.857s
user 0m7.557s
sys 0m1.181s
3.将该数据缓存到内存中可以有效提升查询速度,详细示例如下:
$ goosefs fs ls /data/cos/sample_tweets_150m.csv
-r-x------ staff staff 157046046
ED 01-09-2018 16:35:01:002 0% /data/cos/sample_tweets_150m.csv
$ time goosefs fs cat /data/s3/sample_tweets_150m.csv | grep-c tencent
889
real 0m1.917s
user 0m2.306s
sys 0m0.243s
可见,系统处理延迟从1.181s减少到了0.243s,得到了10倍的提升。
八、关闭 GooseFS
通过如下命令可以关闭 GooseFS:
$ ./bin/goosefs-stop.sh local
九、挂载CHDFS
创建 CHDFS 及挂载点后,可以通过挂载点挂载 CHDFS,本部分详细介绍如何挂载 CHDFS。
前提条件
- 确保挂载的机器或者容器内安装了 Java 1.8。
- 确保挂载的机器或者容器其 VPC,与挂载点指定 VPC 相同。
- 确保挂载的机器或者容器其 VPC IP,与挂载点指定权限组中有一条权限规则授权地址匹配。
操作步骤
- 下载 CHDFS-Hadoop JAR 包。
- 将 JAR 包放置对应的目录下,对于 EMR 集群,可同步到所有节点的 /usr/local/service/hadoop/share/hadoop/common/lib/目录下。
- 编辑 core-site.xml 文件,新增以下基本配置:
<!--chdfs 的实现类-->
<property>
<name>fs.AbstractFileSystem.ofs.impl</name>
<value>com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter</value>
</property>
<!--chdfs 的实现类-->
<property>
<name>fs.ofs.impl</name>
<value>com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter</value>
</property>
<!--本地 cache 的临时目录, 对于读写数据, 当内存 cache 不足时会写入本地硬盘, 这个路径若不存在会自动创建-->
<property>
<name>fs.ofs.tmp.cache.dir</name>
<value>/data/chdfs_tmp_cache</value>
</property>
<!--用户的 appId, 可登录腾讯云控制台(https://console.cloud.tencent.com/developer)查看-->
<property>
<name>fs.ofs.user.appid</name>
<value>1250000000</value>
</property>
<!--flush 语义, 默认 false(异步刷盘), 请参考下图数据可见性与持久化详细说明 -->
<property>
<name>fs.ofs.upload.flush.flag</name>
<value>false</value>
</property>
4.将 core-site.xml 同步到所有 hadoop 节点上。
5.使用 hadoop fs 命令行工具,运行 hadoop fs -ls ofs://
m
o
u
n
t
p
o
i
n
t
/
命令,这里
m
o
u
n
t
p
o
i
n
t
为挂载地址。如果正常列出文件列表,则说明已经成功挂载
C
H
D
F
S
。
6.
用户也可使用
h
a
d
o
o
p
其他配置项,或者
m
r
任务在
C
H
D
F
S
上运行数据任务。对于
m
r
任务,可以通过
−
D
f
s
.
d
e
f
a
u
l
t
F
S
=
o
f
s
:
/
/
{mountpoint}/命令,这里 mountpoint 为挂载地址。如果正常列出文件列表,则说明已经成功挂载 CHDFS。 6. 用户也可使用 hadoop 其他配置项,或者 mr 任务在 CHDFS 上运行数据任务。对于 mr 任务,可以通过 -Dfs.defaultFS=ofs://
mountpoint/命令,这里mountpoint为挂载地址。如果正常列出文件列表,则说明已经成功挂载CHDFS。6.用户也可使用hadoop其他配置项,或者mr任务在CHDFS上运行数据任务。对于mr任务,可以通过−Dfs.defaultFS=ofs://{mountpoint}/将本次任务的默认输入输出 FS 改为 CHDFS。
十、大数据场景生产环境配置实践
数据加速器 GooseFS 提供了多种部署方式,支持 自建部署,在 TKE 上部署 以及在 EMR 上部署 等。在大数据场景中,通常使用集群模式部署,并且采用高可用架构以满足业务连续性的要求,本文重点介绍基于 Zookeeper 和基于 Raft 的高可用部署配置。
高可用架构指多个 Master 节点的主备多活架构。多个 Master 节点中只有一个会作为主(Leader)节点对外提供服务,其他的备(Standby)节点通过同步共享日志(Journal)来保持与主节点相同的文件系统状态。当主节点故障宕机后,会从当前的备节点中自动选择一个接替主节点继续对外提供服务,这样就消除了系统的单点故障,实现了整体高可用架构。目前 GooseFS 支持基于 Raft 日志和 Zookeeper 两种方式来实现主备节点状态的强一致性。
基于 Zookeeper 的高可用架构部署配置
配置 Zookeeper 服务搭建 GooseFS 的高可用架构需要满足如下条件:
- 已建立 Zookeeper 集群。GooseFS Master 使用 Zookeeper 进行 Leader 选取,GooseFS 的客户端和 Worker 节点则通过 Zookeeper 查询主 Master 节点。
- 已准备好高可用强一致的共享存储系统,并且保证所有 GooseFS 的 Master 节点均可以访问到。主 Master 节点会将日志写入到该存储系统上,备(Standby)节点则会不断地从共享存储系统上读取日志,并且重放来保持与主节点的状态一致性。一般情况,该共享存储系统,推荐设置为 HDFS 或 COS。例如,hdfs://10.0.0.1:9000/goosefs/journal 或 cosn://bucket-1250000000/journal。
当您已经完成前置条件后,您可以参考如下推荐配置,并将该配置项复制粘贴到 goosefs-site.properties 文件中,完成您的高可用架构配置:
# GooseFS Master HA 部署配置
goosefs.zookeeper.enabled=true
goosefs.zookeeper.address=<zk_quorum_1>:<zk_client_port>,<zk_quorum_2>:<zk_client_port>,<zk_quorum_3>:<zk_client_port>
goosefs.underfs.hdfs.configuration=${HADOOOP_HOME}/etc/hadoop/core-site.xml:${HADOOP_HOME}/hadoop/etc/hadoop/hdfs-site.xml
goosefs.master.journal.type=UFS
goosefs.master.journal.folder=hdfs://HDFSXXXX/goosefs
# Master 元数据存储方式,推荐使用 Heap + RocksDB 方式,可以支撑上亿规模的元数据
goosefs.master.metastore=ROCKS
goosefs.master.metastore.block=ROCKS
goosefs.master.metastore.block.locations=ROCKS
# GooseFS 的元数据存储目录建议选择高 IOPS 存储介质的目录
goosefs.master.metastore.dir=/data/goosefs/metastore
#元数据交换方式,默认是 RANDOM,如果有明显最近热数据访问的,可设置为考虑 LRU;
# goosefs.master.metastore.cache.type=LRU
# 关闭启动时候校验孤儿 block 的流程,可以降低选主时间
goosefs.master.startup.block.integrity.check.enabled=false
# 同时可以根据实际情况关闭周期性地校验孤儿 block 的逻辑
# goosefs.master.periodic.block.integrity.check.interval=-1
# 如果不使用 TTL 功能,也可以考虑关闭周期性的文件过期检查
goosefs.master.ttl.checker.interval.ms=-1
# 可以考虑关闭数据副本检查,减小 Master 的开销
goosefs.master.replication.check.interval=-1
# Worker 相关的配置
goosefs.worker.tieredstore.levels=1
goosefs.worker.tieredstore.level0.alias=SSD
goosefs.worker.tieredstore.level0.dirs.path=/data1/goosefsWorker,/data2/goosefsWorker
# 以下 Quota 值根据实际情况设置
# goosefs.worker.tieredstore.level0.dirs.quota=2000G,2000G
goosefs.worker.block.heartbeat.interval.ms=10sec
goosefs.worker.tieredstore.free.ahead.bytes=134217728
goosefs.user.block.worker.client.pool.max=512
# 安全认证和用户模拟相关
goosefs.security.authorization.permission.enabled=true
goosefs.security.authentication.type=SIMPLE
# goosefs.security.login.username=hadoop
# goosefs.master.security.impersonation.hadoop.users=*
# goosefs.security.login.impersonation.username=_HDFS_USER_
# Client 相关的配置
goosefs.user.client.transparent_acceleration.scope=GFS_UFS
goosefs.user.client.transparent_acceleration.enabled=true
goosefs.user.file.readtype.default=CACHE
goosefs.user.file.writetype.default=CACHE_THROUGH
goosefs.user.metrics.collection.enabled=true
基于 Raft 的高可用架构部署配置
基于 Raft 嵌入式日志的部署方案依赖于 copycat 的 Leader 选举机制。因此,Raft 的高可用部署架构不可与 Zookeeper 相互混用。如果您计
# GooseFS Master Raft 部署配置
goosefs.master.rpc.addresses=<master1>:9200,<master2>:9200,<master3>:9200
goosefs.master.embedded.journal.addresses=<master1>:9202,<master2>:9202,<master3>:9202
#元数据 checkpoint 间隔,默认为2000000,实际速率可根据实际生产环境元数据生产速度设置
goosefs.master.journal.checkpoint.period.entries=xxxx
# GooseFS 的 Journal 数据存储位置
goosefs.master.journal.folder=/data/goosefs/journal
# Master 元数据存储方式,推荐使用 Heap + RocksDB 方式,可以支撑上亿规模的元数据
goosefs.master.metastore=ROCKS
goosefs.master.metastore.block=ROCKS
goosefs.master.metastore.block.locations=ROCKS
# GooseFS 的元数据存储目录建议选择高 IOPS 存储介质的目录
goosefs.master.metastore.dir=/data/goosefs/metastore
#元数据交换方式,默认是 RANDOM,如果有明显最近热数据访问的,可设置为考虑 LRU;
# goosefs.master.metastore.cache.type=LRU
# 关闭启动时候校验孤儿 block 的流程,可以降低选主时间
goosefs.master.startup.block.integrity.check.enabled=false
# 同时可以根据实际情况关闭周期性地校验孤儿 block 的逻辑
# goosefs.master.periodic.block.integrity.check.interval=-1
# 如果不使用 TTL 功能,也可以考虑关闭周期性的文件过期检查
goosefs.master.ttl.checker.interval.ms=-1
# 可以考虑关闭数据副本检查,减小 Master 的开销
goosefs.master.replication.check.interval=-1
# Worker 相关的配置
goosefs.worker.tieredstore.levels=1
goosefs.worker.tieredstore.level0.alias=SSD
goosefs.worker.tieredstore.level0.dirs.path=/data1/goosefsWorker,/data2/goosefsWorker
# 以下 Quota 值根据实际情况设置
# goosefs.worker.tieredstore.level0.dirs.quota=2000G,2000G
goosefs.worker.block.heartbeat.interval.ms=10sec
goosefs.worker.tieredstore.free.ahead.bytes=134217728
goosefs.user.block.worker.client.pool.max=512
# 安全认证和用户模拟相关
goosefs.security.authorization.permission.enabled=true
goosefs.security.authentication.type=SIMPLE
# goosefs.security.login.username=hadoop
# goosefs.master.security.impersonation.hadoop.users=*
# goosefs.security.login.impersonation.username=_HDFS_USER_
# Client 相关的配置
goosefs.user.client.transparent_acceleration.scope=GFS_UFS
goosefs.user.client.transparent_acceleration.enabled=true
goosefs.user.file.readtype.default=CACHE
goosefs.user.file.writetype.default=CACHE_THROUGH
goosefs.user.metrics.collection.enabled=true