一、背景
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这
种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主
要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是
和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境
下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
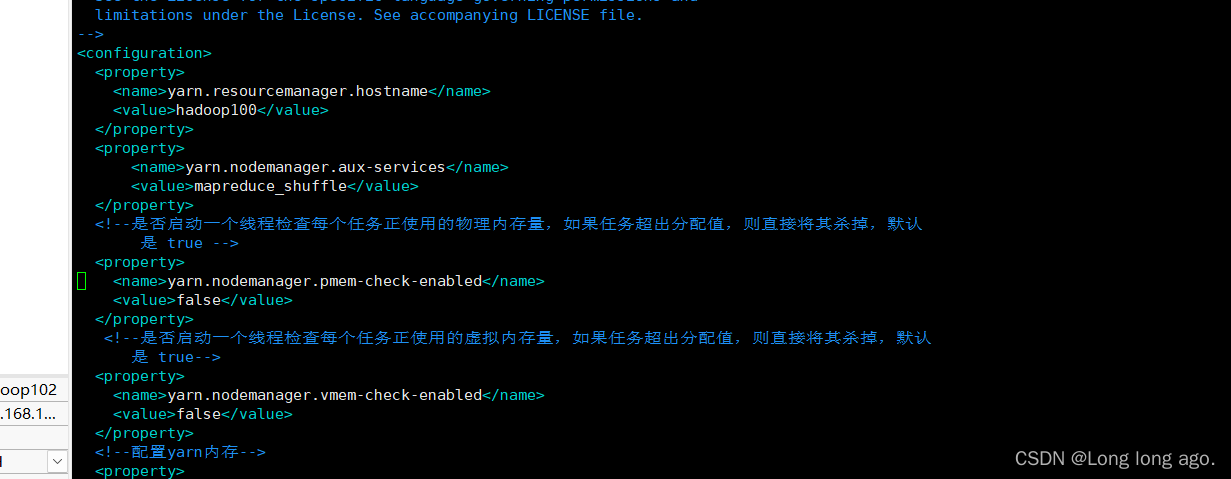
二、修改hadoop yarn配置
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
添加以下配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true-->
<property>
三、修改spark配置(需要根据自己情况修改)
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
四、重启yarn和hdfs
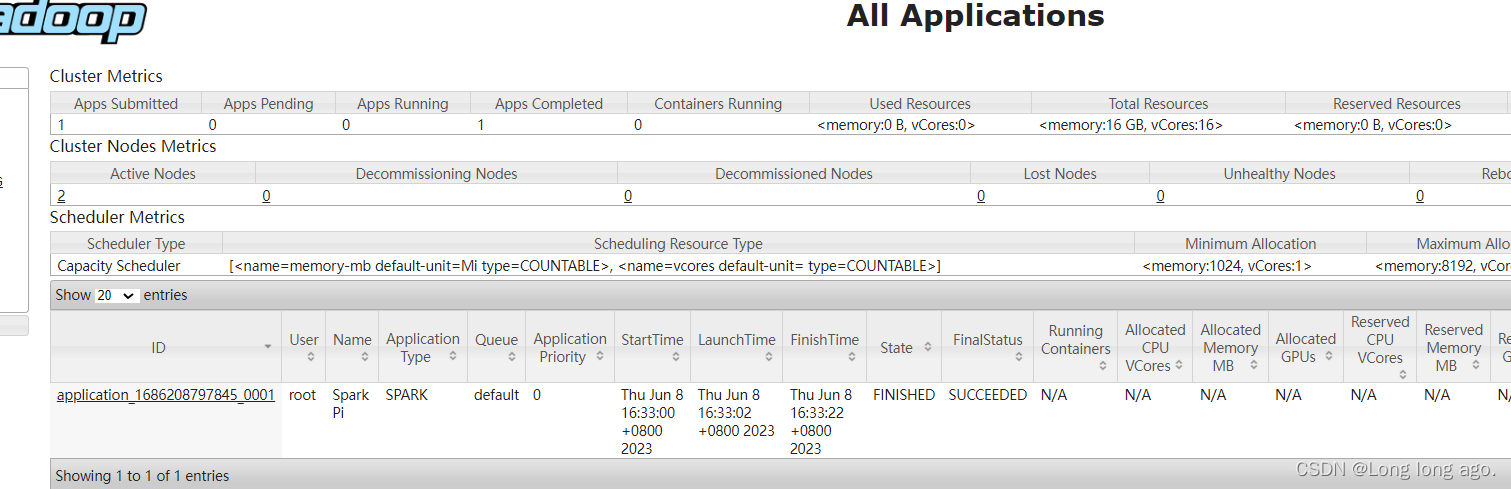
五、提交应用
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.12-3.0.0.jar 10
注意
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.12-3.0.0.jar 10
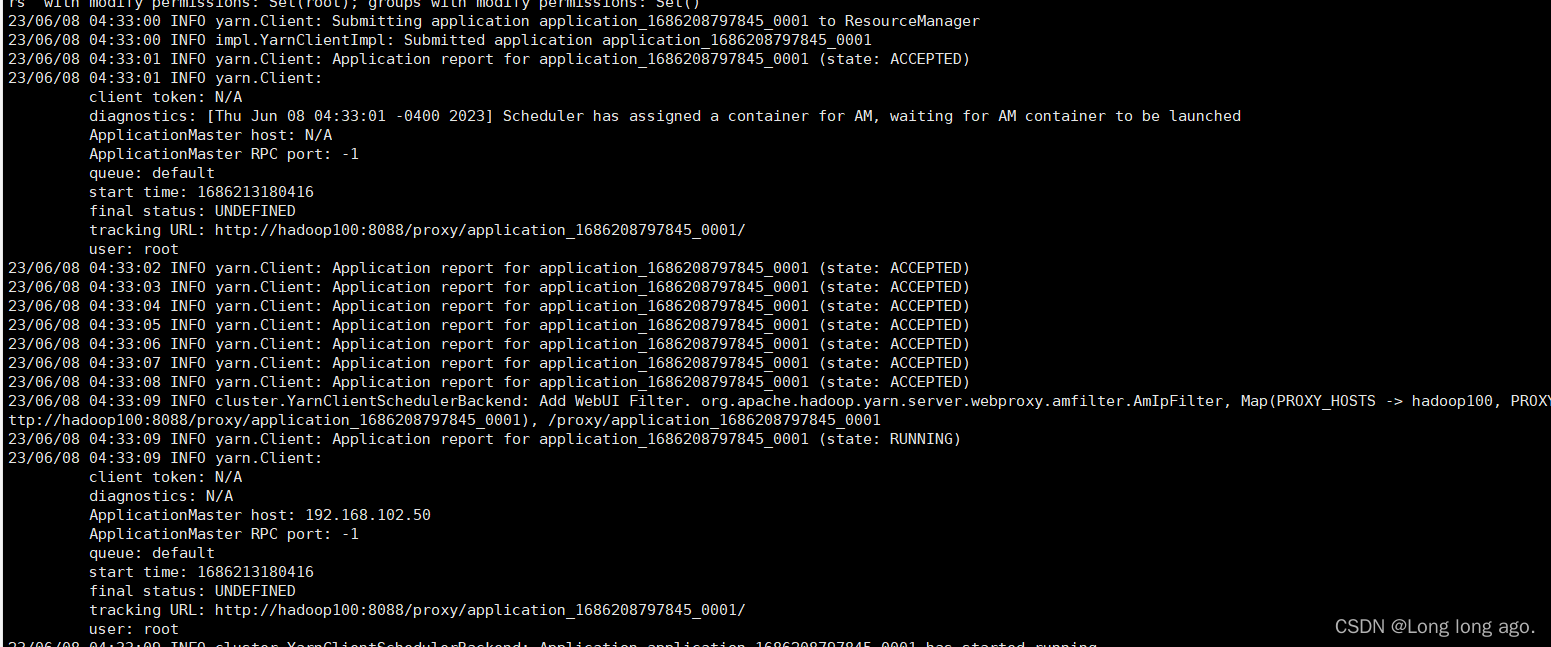
可在hadoop看到历史