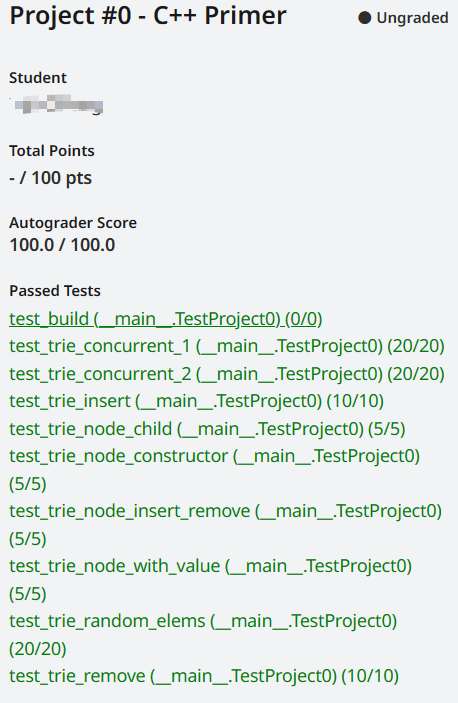
APOLLO视频学习笔记
一、总览
无人驾驶车的运作方式
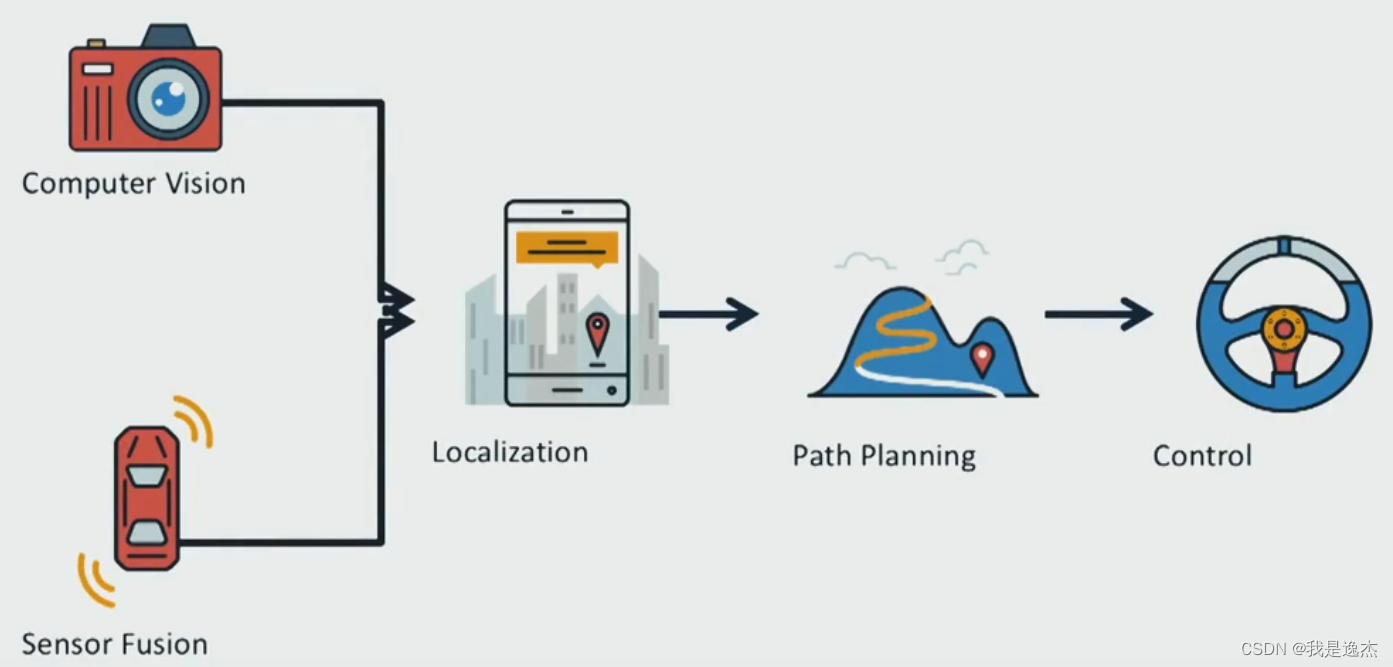
五个核心部件:
- 计算机视觉:弄清楚周围的世界是怎样的
- 传感器融合: 合并来自其他传感器的数据,如激光和雷达,更加深入了了解我们周围的环境
- 定位:精确地确定我在世界所处的位置
- 路径规划:绘制这个世界的路线
- 控制:让我们汽车沿着路径规划期间建立的轨道行驶
二、地图
高精地图
高精地图能够到达厘米级别
无人驾驶车确定自己的位置:先从各类传感器收集数据,(如摄像机图像数据、激光雷达收集的三位点云数据),经过预处理(消除不准确或质量差的数据)、坐标转换(将不同视角的数据转换)和数据融合(各种车辆和传感器数据合并)
高精地图会告知在特定位置寻找停车标志,传感器就可以集中在该位置检测停车标志,这叫感兴趣区域或ROI,可节省资源
高精地图会记录交通信号灯的精确位置和高度,从而大大降低了感知难度,减少计算需求
高精地图构建:
- 数据采集:专门调查车辆采集(GPS、惯性测量单元、激光雷达、摄像机)
- 数据处理:对收集到的数据进行整理分类和清洗
- 对象检测:
- 手动验证
- 地图发布
三、定位
将汽车传感器(测量车辆与静态障碍物之间的距离)所看到的内容与地图显示的内容进行比较
通过三角测量,GPS:卫星、控制站、GPS接收器
惯性导航:IMU
激光雷达定位:运用算法匹配点云,迭代最近点(或ICP)是一种方法;滤波算法消除冗余信息
卡尔曼滤波:用于根据我们在过去的状态和新的传感器测量结果预测我们当前的状态
视觉定位:(优:数据方便获取 缺:缺乏三维信息和对三维地图的依赖)
粒子滤波:使用粒子或点来估计最可能的位置
传感器支持GNSS和LiDAR定位,GNSS定位输出位置和速度信息 LiDAR定位输出位置和行进方向信息
四、感知
汽车感知周围环境,通过计算机视觉(CNN:卷积神经网络)
检测:找出物体在环境中的位置
分类:明确对象是什么
跟踪:随时间的推移观察移动物体
语义分割:将图 像中的每个像素与予以类别进行匹配
无人驾驶使用什么算法对障碍物进行检测和分类?
先使用检测CNN来查找图像中对象位置,对图像中的位置进行定位之后,将图像发给另一个CNN进行分类
追踪:解决遮挡问题,保留身份,以及预测之后的位置和速度
**语义分割:**涉及对图像的每个像素进行分类,用于尽可能地详细了解环境,并确定可行使环境。依赖于FCN(全卷积网络)
卡尔曼滤波用于融合输出,预测更新
卷积神经网络
五、预测
为运动的物体做出预测
实时性、准确性
预测方式:基于模型的预测、数据驱动预测
六、规划
- 路线导航
输入:地图、我们在地图上的位置、目的地
A*路径查找处理算法:从开始节点到候选节点g-value,从候选节点到结束节点h-value,两个value相加,最小的为下一个位置,然后重复计算
轨迹生成:生产由一系列路径点所定义的轨迹
Frenrt框架,s代表沿道路的距离,纵坐标 d代表与纵向线的位移,横坐标
路径规划:生成候选曲线,使用成本函数对每条路径进行评估
速度规划:速度曲线,
成本函数:与车道中心的偏离、与障碍物的距离、速度和曲率的变化
巡航、跟随、停止
ST(纵向偏移、时间坐标) SL(横向偏移、时间坐标)
七、控制
控制是驱使车辆前行的策略,最基本的控制输入为转向、加速和制动
控制器:必须准确、具备可行性、平稳度
控制器预计又两种输入:目标轨迹、车辆状态
PID控制是线性算法(对于非常复杂的系统不行),只需要知道与目标轨迹的误差大小,P表示比例,D致力于使运动处于稳定状态,I表示积分,负责纠正车辆的任何系统性偏差

LQR(线性二次调节器)是基于模型的控制器,使用车辆的状态是误差最小化,Apollo使用LQR横向控制
MPC:
- 建立车辆模型
- 使用优化引擎计算有限时间范围内的控制输入
- 执行第一组控制输入