ERNIE: Enhanced Representation through Knowledge Integration是百度在2019年4月的时候,基于BERT模型,做的进一步优化,在中文的NLP任务上得到了state-of-the-art的结果。
ERNIE 是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE 在工业界得到了大规模应用,如搜索引擎、新闻推荐、广告系统、语音交互、智能客服等。
ERNIE 1.0主要做了以下三方面的改进:
1.在mask的机制上做了改进,在pretrainning阶段增加了外部的知识。
2.使用了多样的预训练语料。
3.DLM (Dialogue Language Model) task
1 Knowledge Masking
ERNIE 1.0主要是在mask的机制上做了改进,它的mask不是基本的word piece的mask,而是在pretrainning阶段增加了外部的知识。使用先验知识来增强预训练的语言模型,因此提出了一种多阶段知识屏蔽策略,将短语和实体级知识集成到语言表示中。由三种level的mask组成,分别是basic-level masking(word piece)+ phrase level masking(WWM style) + entity level masking。
模型在预测未知词的时候,没有考虑到外部知识。但是如果我们在mask的时候,加入了外部的知识,模型可以获得更可靠的语言表示。
例如:哈利波特是J.K.罗琳写的小说。
- 单独预测 哈[MASK]波特 或者 J.K.[MASK]琳 对于模型都很简单,仅仅需要通过局部共现关系,完全不需要上下文的帮助;
- 但是模型不能学到哈利波特和J.K. 罗琳的关系。
如果把哈利波特直接MASK掉的话,那模型可以根据作者,就预测到小说这个实体,实现了知识的学习。这些知识的学习是在训练中隐性地学习,而不是直接将外部知识的embedding加入到模型结构中(ERNIE-TsingHua[4]的做法),模型在训练中学习到了更长的语义联系,例如说实体类别,实体关系等,这些都使得模型可以学习到更好的语言表达。

ERNIE的mask的策略通过三个阶段学习的,在第一个阶段,采用的是BERT的模式,用的是basic-level masking,然后再加入词组的mask(phrase-level masking), 然后再加入实体级别entity-level的mask。
1-1 Basic level masking
第一阶段,采用基本层级的masking,使用与BERT一样的基础Mask机制,同样是15%的Mask概率,随机mask掉中文中的一个字。
在这个阶段,模型难以获得高级别的语义知识的建模能力。
1-2 Phrase level masking
第二阶段,采用词组(短语)级别的MASK机制,对于英文文本,使用lexical analysis工具获取短语的边界,对于中文或者其他语言的文本,使用对应语言的分词/分段工具,来得到单词/短语。mask掉句子中一部分词组,然后让模型预测这些词组。
在这个阶段,词组的信息就被encoding到word embedding中了。
1-3 Entity level masking
在第三阶,使用实体级别的Mask机制,如:人名,机构名,商品名等,在这个阶段被mask掉。
在这个阶段,首先会解析出句子中的所有实体(应该是通过命名实体识别模型,论文未明确说明),然后Mask掉某些实体,并进行预测。模型在训练完成后,也就学习到了这些实体的信息。
通过这三个阶段的预训练学习,模型可以通过更丰富的语义信息,得到增强的词表征。

从整个语料库中抽取10%的训练数据来验证知识掩蔽策略的有效性。结果如表所示。在基线词级屏蔽的基础上增加短语级屏蔽可以提高模型的性能。在此基础上,增加了实体级屏蔽策略,模型的性能得到了进一步提高。此外,结果还显示,在预训练数据集规模大10倍的情况下,在XNLI测试集上实现了0.8%的性能提升。
2 Heterogeneous Corpus Pre-training
ERNIE 1.0 借助百度在中文社区的强大能力,使用了各种异质(Heterogeneous)的数据集进行预训练。抽取了混合语料库中文维基百科(Chinese Wikepedia)、百度百科(Baidu Baike)、百度新闻(Baidu news)和百度贴吧(Baidu Tieba )。句子的数量分别为21M、51M、47M、54M。
百度百科包含了用正式语言编写的百科全书文章,作为语言建模的有力基础。百度新闻提供有关电影名称、演员名称、足球队名称等最新信息。百度贴吧是一个类似于Reddits的开放式讨论区,每个帖子都可以被视为一个对话线程。贴吧语料库被用于我们的DLM任务,这将在下一节讨论。
对汉字进行繁体到简体的转换,并对英文字母进行大写到小写的转换。最终词表大小为17,964个unicode字符的共享词汇。
3 DLM (Dialogue Language Model) task
百度贴吧属于对话类型的数据,对话数据对语义表征是很重要的,因为一个问题下的回答通常下是相似的。为了适应多轮的贴吧数据,ERNIE在Query-Response的对话结构下,使用一种新的DLM (Dialogue Language Model) 任务。DLM还增加了任务来判断这个多轮对话是真的还是假的。
对话的数据对语义表示很重要,因为对于相同回答的提问一般都是具有类似语义的,不同于BERT的输入形式,ERNIE能够使用多轮对话的形式,采用的是三个句子的组合,与BERT添加标志的方式一致,采用[CLS]和[SEP]完成对句子的区分,形成S1[SEP]S2[SEP]S3[SEP] 的格式。
这种组合可以表示多轮对话,例如QRQ,QRR,QQR。Q:提问,R:回答。
为了表示dialog的属性,句子添加了dialog embedding组合,这个和segment embedding很类似。
负样本会随机替换掉句子的问题或者回答,模型需要预测它是正样本还是负样本,类似于NSP和SOP。
DLM任务可以让ERNIE学习对话之间的内在关系,这也可以提升模型语义表征的学习能力。
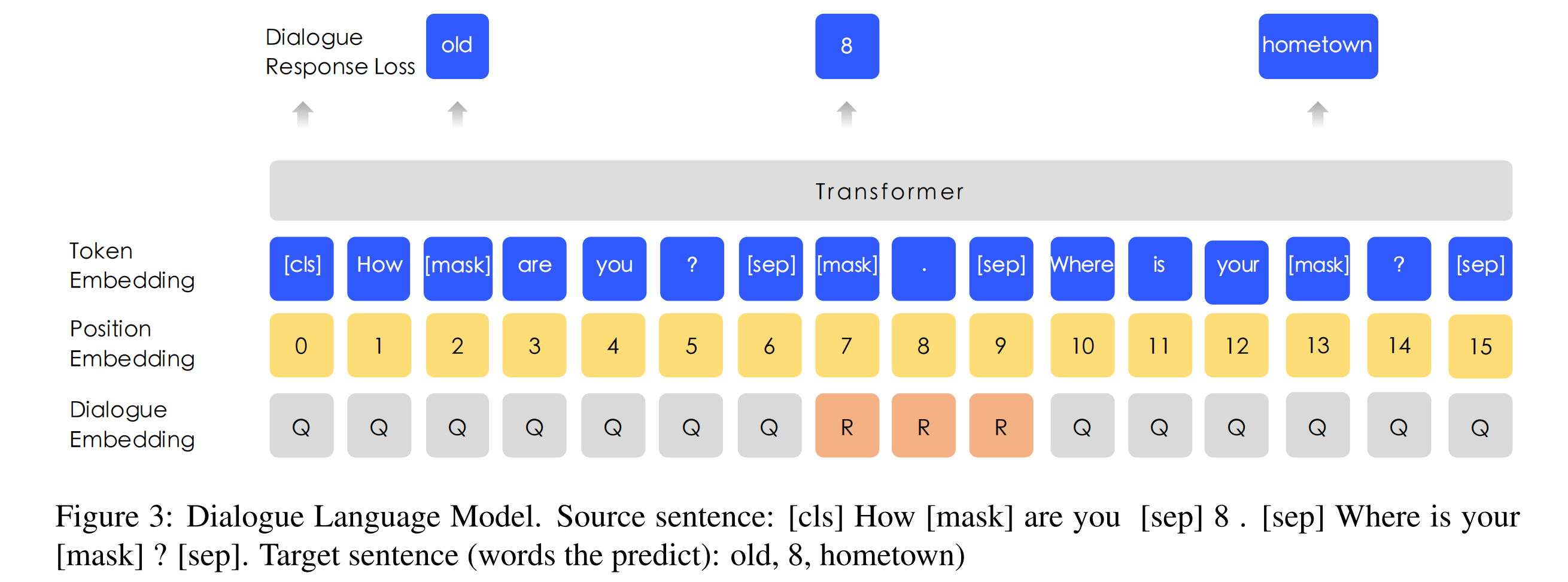
对话语言模型。源句:[cls] How [mask] are you [sep] 8 . [sep] Where is your [mask] ?[sep]. 目标句子(预测的词):old,8,hometown)
像BERT中的MLM一样,应用掩码来强制模型预测以查询和回应为条件的缺失词。此外,我们通过用随机选择的句子替换查询或回应来产生虚假样本。
DLM任务帮助ERNIE学习对话中的隐含关系,这也增强了模型学习语义表征的能力。DLM任务的模型结构与MLM任务的结构兼容,因此它与MLM任务交替进行预训练。
使用所有训练语料的10%,以不同的比例来说明DLM任务对XNLI开发集的贡献。我们在这些数据集上从头开始预训练ERNIE,并报告5次随机重启微调对XNLI任务的平均结果。详细的实验设置和开发集结果见表3,在这个DLM任务上,开发/测试的准确率提高了0.7%/1.0%。

4 实验结果
ERNIE被应用于5个中文NLP任务,包括自然语言推理、语义相似度、命名实体识别、情感分析和问题回答。
1.自然语言推理
跨语言自然语言推理(XNLI)语料库是MultiNLI语料库的一个众包集合。 这些对子都有文本导出的注释,并被翻译成包括中文在内的14种语言。标签包含矛盾、中性和蕴涵的内容。
2.语义相似性
大型中文问题匹配模型(LCQMC)旨在识别两个句子是否具有相同的意图。 数据集中的每一对句子都与一个二进制标签相关联,表明这两个句子是否有相同的意图,该任务可以被形式化为预测二进制标签。
3.命名实体识别
MSRA-NER数据集是为命名实体识别而设计的,它由微软亚洲研究院发布。实体包含几种类型,包括人名、地名、组织名称等。这个任务可以被看作是一个序列标签任务。
4.情感分析
ChnSentiCorp(Song-bo)是一个数据集,旨在判断一个句子的情感。它包括几个领域的评论,如酒店、书籍和电子计算机。这个任务的目标是判断句子是积极还是消极的。
5.检索问题回答
NLPCC-DBQA数据集的目标是选择相应问题的答案。这个数据集的评价方法包括MRR和F1得分。
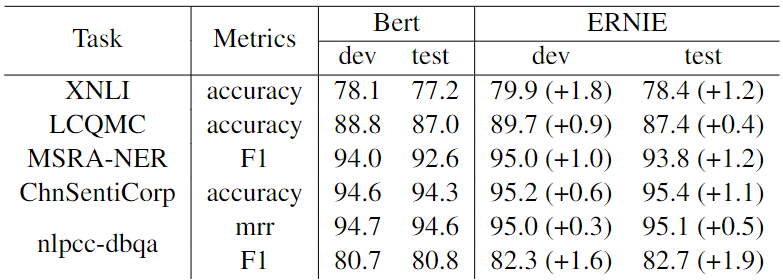
下表展示了5个汉语NLP任务的测试结果。可以看出,ERNIE 1.0在所有任务上的表现都优于BERT,在这些中文NLP任务上创造了新的最先进的结果。在XNLI、MSRA-NER、ChnSentiCorp和NLPCC-DBQA任务中,ERNIE比BERT获得了超过1%的绝对准确率。
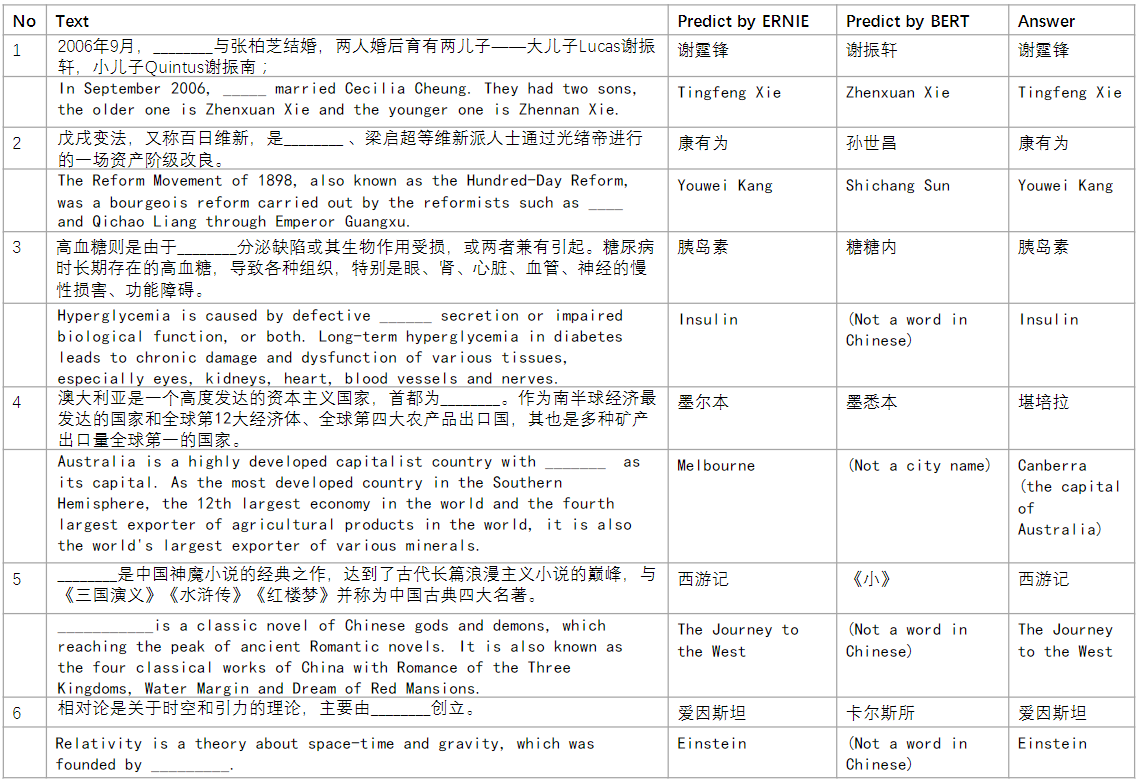
为了验证ERNIE1.0的知识学习能力,使用了几个完形填空测试样本来检验该模型。在实验中,名字实体被从段落中删除,模型需要推断出它是什么。如下表比较了BERT和ERNIE的预测答案。
Reference:
详解百度ERNIE进化史及典型应用场景