学习目标:

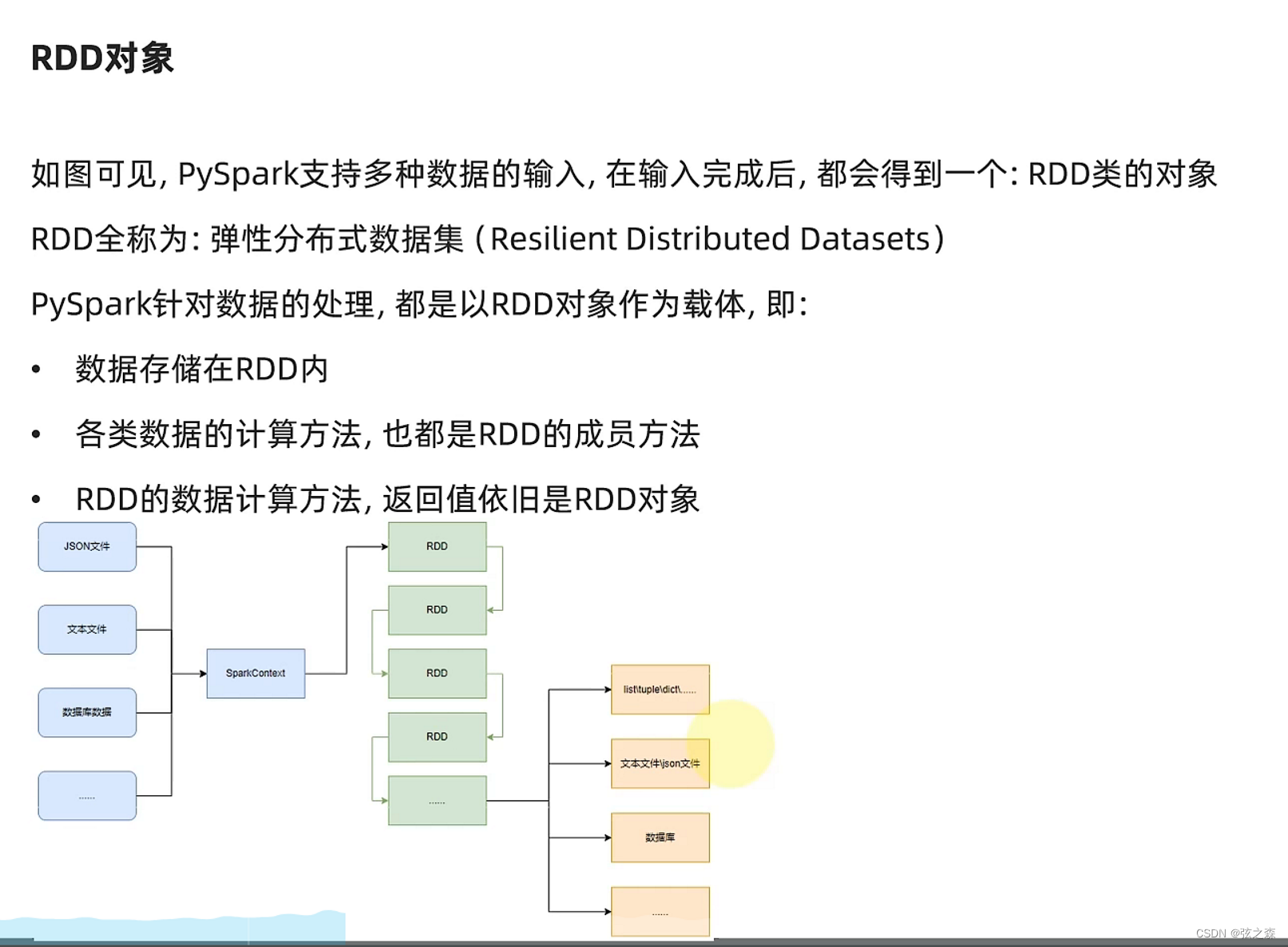
现在只需要知道PDD是一个数据集。


【运行实例(1)】:
from pyspark import SparkConf, SparkContext
# conf:创建对象;Sparkconf:创建入口;setMaster:运行方式;setAppName:赋名
conf=SparkConf().setMaster("local[*]").setAppName("run_test_app")
# 通过conf对象,可以创建SparkContext对象;sc:执行环境入口对象
sc = SparkContext(conf=conf)
# 通过parallelize方法将python对象加载到Spark内,成为RDD对象
RDD1 = sc.parallelize([1, 2, 3, 4, 5, 6, 7])
RDD2 = sc.parallelize((1, 2, 3, 4, 5, 6, 7))
RDD3 = sc.parallelize("1234567")
RDD4 = sc.parallelize({1, 2, 3, 4, 5, 6, 7})
RDD5 = sc.parallelize({"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5, "key6": 6, "key7": 7})
print(RDD1.collect())
print(RDD2.collect())
print(RDD3.collect())
print(RDD4.collect())
print(RDD5.collect())
sc.stop()
【运行实例(2)】:
from pyspark import SparkConf, SparkContext
# conf:创建对象;Sparkconf:创建入口;setMaster:运行方式;setAppName:赋名
conf=SparkConf().setMaster("local[*]").setAppName("run_test_app")
# 通过conf对象,可以创建SparkContext对象;sc:执行环境入口对象
sc = SparkContext(conf=conf)
# 给定文件路径,此处是文本文档,通过sc对象提供的textFile方法,读取本地文本文档中的内容,可以将这个步骤理解为得到RDD0对象的步骤
RDD0 = sc.textFile("D:/python_exe.txt")
# 通过RDD0对象提供的collect方法,读取文件中的具体内容
print(RDD0.collect())
sc.stop()