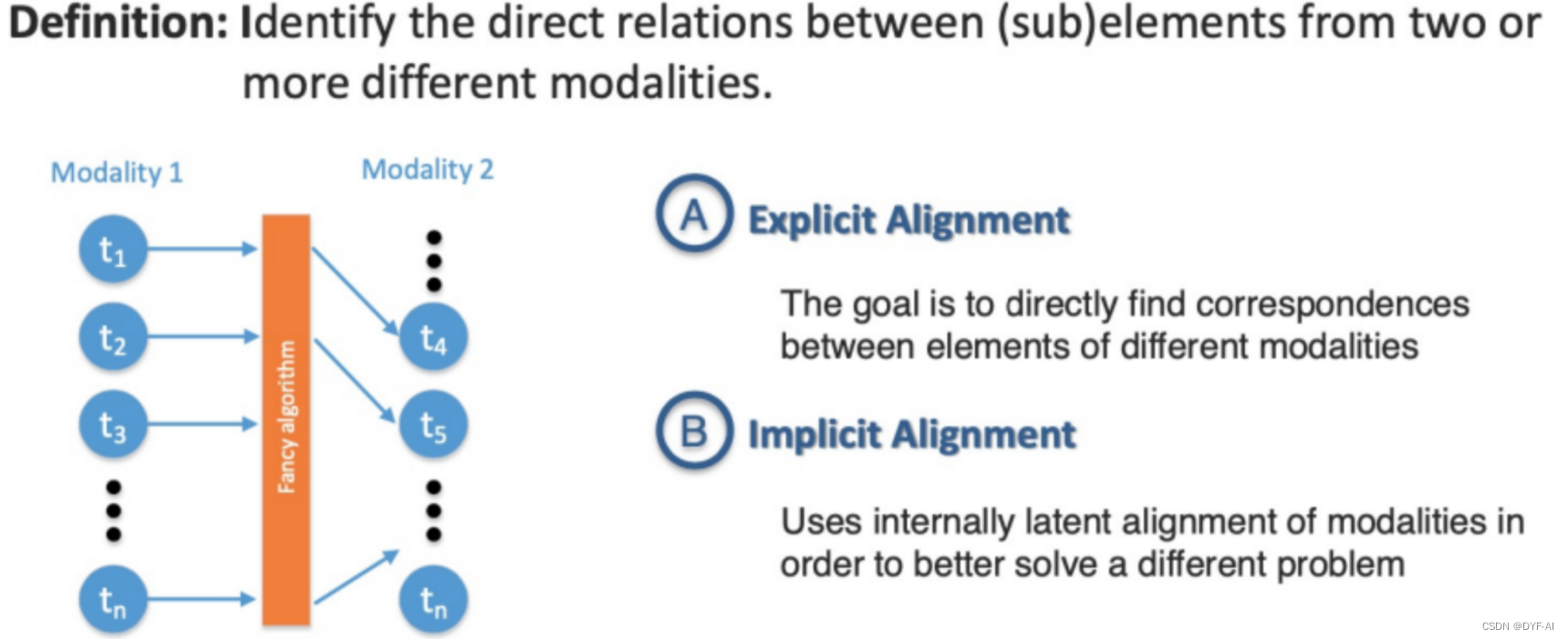
分区副本机制
kafka 从 0.8.0 版本开始引入了分区副本;引入了数据冗余
用CAP理论来说,就是通过副本及副本leader动态选举机制提高了kafka的 分区容错性和可用性
但从而也带来了数据一致性的巨大困难!
6.6.2分区副本的数据一致性困难
kafka让分区多副本同步的基本手段是: follower副本定期向leader请求数据同步!
既然是定期同步,则leader和follower之间必然存在各种数据不一致的情景!
- 问题1:分区副本间动态不一致

- 问题2:消费者所见不一致
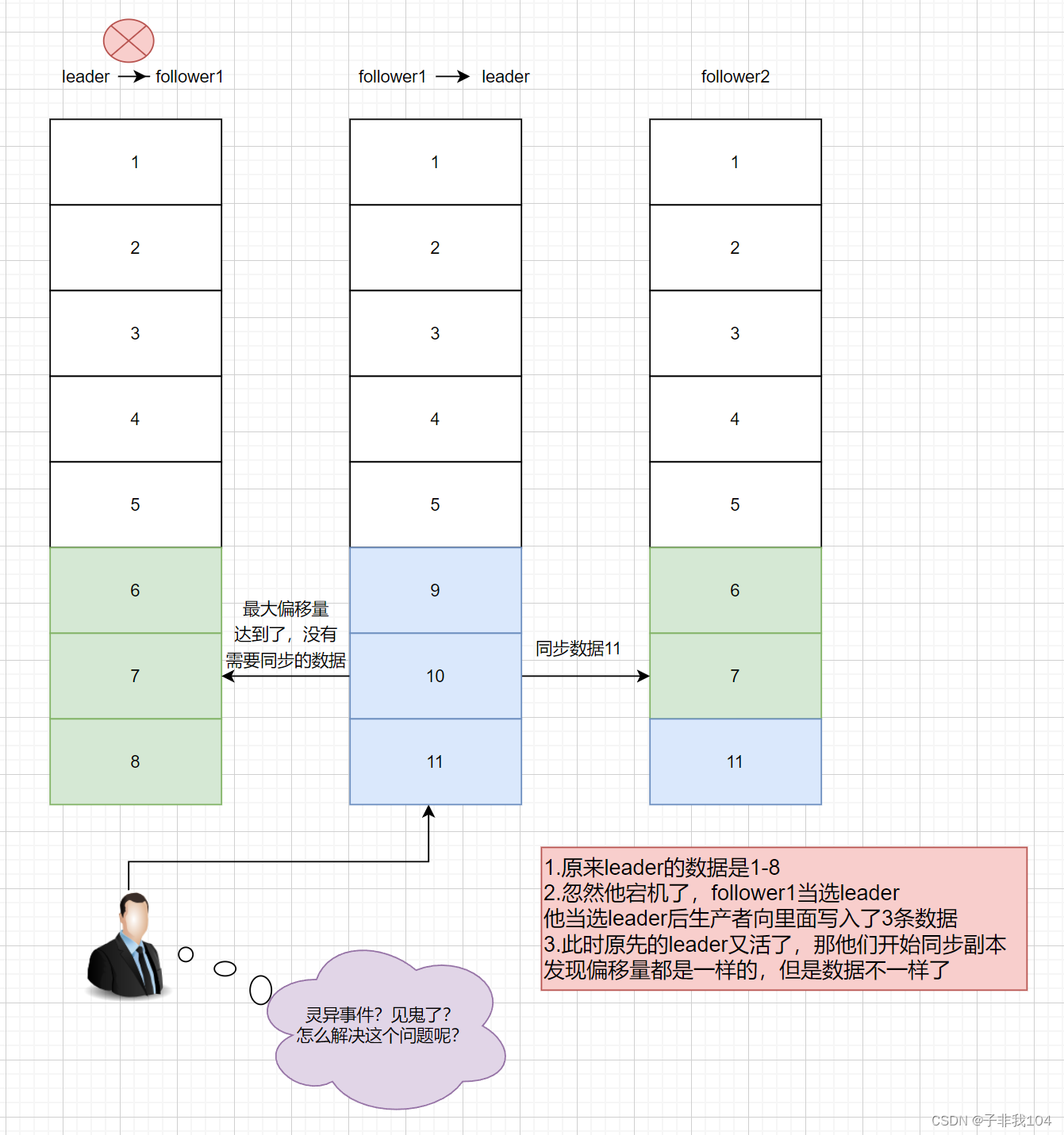
如果此时leader宕机,follower1或follower2被选为新的leader,则leader换届前后,消费者所能读取到的数据发生了不一致;

- 问题3:分区副本间最终不一致
一致性问题解决方案(HW)
动态过程中的副本数据不一致,是很难解决的;
kafka先尝试着解决上述“消费者所见不一致”及“副本间数据最终不一致”的问题;
| 解决方案的核心思想
|
- 解决“消费者所见不一致” (消费者只允许看到HW以下的message)
- 解决“分区副本数据最终不一致” (follower数据按HW截断)

HW方案的天生缺陷
如前所述,看似HW解决了“分区数据最终不一致”的问题,以及“消费者所见不一致”的问题,但其实,这里面存在一个巨大的隐患,导致:
- “分区数据最终不一致”的问题依然存在
- producer设置acks=all后,依然有可能丢失数据的问题
| 产生如上结果的根源是:HW高水位线的更新,与数据同步的进度,存在迟滞! |

第一次fetch请求,分leader端和follower端:
leader端:
- 读取底层log数据。
- 根据fetch带过来的offset=0的数据(就是follower的LEO,因为follower还没有写入数据,因此LEO=0),更新remote LEO为0。
- 一轮结束后尝试更新HW,做min(leader LEO,remote LEO)的计算,结果为0。
- 把读取到的三条log数据,加上leader HW=0,一起发给follower副本。
follower端:
- 写入数据到log文件,更新自己的LEO=3。
- 更新HW,做min(leader HW,follower LEO)的计算,由于leader HW=0,因此更新后HW=0。
可以看出,第一次fetch请求后,leader和follower都成功写入了三条消息,但是HW都依然是0,对消费者来说都是不可见的,还需要第二次fetch请求。
第二次fetch请求,分leader端和follower端:
leader端:
- 读取底层log数据。
- 根据fetch带过来的offset=3的数据(上一次请求写入了数据,因此LEO=3),更新remote LEO为3。
- 尝试更新HW,做min(leader LEO,remote LEO)的计算,结果为3。
- 把读取到的log数据(其实没有数据),加上leader HW=3,一起发给follower副本。
follower端:
- 写入数据到log文件,没有数据可以写,LEO依然是3。
- 更新HW,做min(leader HW,follower LEO)的计算,由于leader HW=3,因此更新后HW=3。
这个时候,才完成数据的写入,并且分区HW(分区HW指的就是leader副本的HW)更新为3,代表消费者可以消费offset=0,1,2的三条消息了,上面的过程就是kafka处理消息写入和备份的全流程。
| 从以上步骤可看出,leader 中保存的 remote LEO 值的更新(也即HW的更新)总是需要额外一轮 fetch RPC 请求才 能完成,这意味着在 leader 切换过程中,会存在数据丢失以及数据不一致的问题! |
HW会产生数据丢失和副本最终不一致问题
| 数据丢失的问题(即使produce设置acks=all,依然会发生) |

如上图所示:
- 状态起始:最新消息c已同步,但是水位线还没开始同步
- 在此时leader崩溃(即 follower 没能通过下一轮请求来更新 HW 值)
- follower成为了leader,会自动将 LEO 值调整到之前的 HW 值,即会进行日志截断
- 然后,原来的leader重启上线,会向新的leader发送请求请求,收到 fetch 响应后,拿到 HW 值,并更新本地 HW 值,发现我也要截取,悲剧发生了,数据丢了
| 副本间数据最终不一致的问题(即使produce设置acks=all,依然会发生) |

如上图所示:
- 状态起始:最新消息c已同步,但是水位线还没开始同步
- 在此时leader崩溃(即 follower 没能通过下一轮请求来更新 HW 值)
- follower成为了leader,会自动将 LEO 值调整到之前的 HW 值,即会进行日志截断
- 在截断日志之后,也就是这个d被截断了之后,我又加了一条数据是e
- 然后,原来的leader重启上线,会向新的leader发送请求请求,收到 fetch 响应后,拿到 HW 值,并更新本地 HW 值,发现我的数据和leader的数据一样,好的,我就不用截取了,我更新HW就好了,就这样,一个新的悲剧又发生了,数据不一致了
| 只要新一届leader在老leader重启上线前,接收了新的数据,就可能发生上图中的场景,根源也在于HW的更新落后于数据同步进度 |
Leader-Epoch机制的引入
为了解决 HW 更新时机是异步延迟的,而 HW 又是决定日志是否备份成功的标志,从而造成数据丢失和数据不一致的现象,Kafka 引入了 leader epoch 机制;
在每个副本日志目录下都创建一个 leader-epoch-checkpoint 文件,用于保存 leader 的 epoch 信息;
leader-epoch的含义
如下,leader epoch 长这样:

它的格式为 (epoch offset),epoch指的是 leader 版本,它是一个单调递增的一个正整数值,每次 leader 变更,epoch 版本都会 +1,offset 是每一代 leader 写入的第一条消息的位移值,比如:
(0,0)
(1,300)
以上第2个版本是从位移300开始写入消息,意味着第一个版本写入了 0-299 的消息。
leader epoch 具体的工作机制
- 当副本成为 leader 时:
这时,如果此时生产者有新消息发送过来,会首先更新leader epoch 以及LEO ,并添加到 leader-epoch-checkpoint 文件中;
- 当副本变成 follower 时:
发送LeaderEpochRequest请求给leader副本,该请求包括了follower中最新的epoch 版本;
leader返回给follower的响应中包含了一个LastOffset,如果 follower last epoch = leader last epoch(纪元相同),则 LastOffset = leader LEO,否则取follower last epoch 中最小的 leader epoch 的 start offset 值;
| 举个例子:假设 follower last epoch = 1,此时 leader 有 (1, 20) (2, 80) (3, 120),则 LastOffset = 80; |
follwer 拿到 LastOffset 之后,会对比当前 LEO 值是否大于 LastOffset,如果当前 LEO 大于 LastOffset,则从 LastOffset 截断日志;
follower 开始发送 fetch 请求给 leader 保持消息同步。
leader epoch 如何解决HW的备份缺陷
- 解决数据丢失和数据不一致的问题

如上图所示:
follower当选leader后,收到纪元消息,发现 LastOffset等于当前 LEO 值,故不用进行日志截断。
follower重启后同步消息,发现自己也不用截取,数据一致,齐活儿
当然,如果说后来增加消息以后,也不需要截取,直接同步数据就行(当ack=-1)
LEO/HW/LSO等相关术语速查
LEO:(last end offset)就是该副本中消息的最大偏移量的值+1 ;
HW:(high watermark)各副本中LEO的最小值。这个值规定了消费者仅能消费HW之前的数据;
LW:(low watermark)一个副本的log中,最小的消息偏移量; 应该是和log里面的偏移量有关系
LSO:(last stable offset) 最后一个稳定的offset;对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同;

LEO与HW 与数据一致性密切相关;

如图,各副本中最小的LEO是3,所以HW是3,所以,消费者此刻最多能读到Msg2;
不清洁选举[了解]
不清洁选举,是指允许“非ISR副本”可以被选举为leader;非ISR副本被选举为leader,将极大增加数据丢失及数据不一致的可能性!由参数 unclean.leader.election.enable=false(默认) 控制;
- 初始状态: follower2严重落后于leader,并且不属于ISR副本
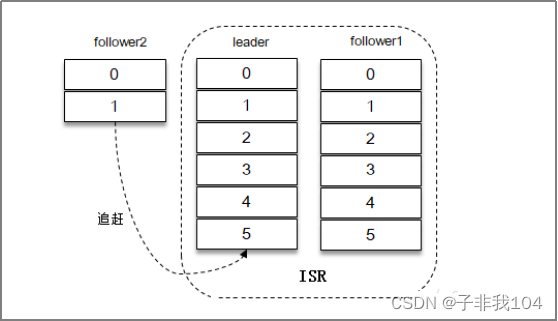
- 此刻,所有ISR副本宕机:

- Follower2成为新的leader,并接收数据

- 之前宕机副本重启,按照最新leader的最新leo进行截断,产生数据丢失及不一致

幂等性
幂等性要点
Kafka 0.11.0.0 版本开始引入了幂等性与事务这两个特性,以此来实现 EOS ( exactly once
semantics ,精确一次处理语义)
生产者在进行发送失败后的重试时(retries),有可能会重复写入消息,而使用 Kafka幂等性功能之后就可以避免这种情况。
| 开启幂等性功能,只需要显式地将生产者参数 enable.idempotence设置为 true (默认值为 false): props.put("enable.idempotence",true); |
在开启幂等性功能时,如下几个参数必须正确配置:
- retries > 0
- max.in.flight.requests.per.connection<=5
- acks = -1
如有违反,则会抛出ConfigException异常;
kafka幂等性实现机制
1)每一个producer在初始化时会生成一个producer_id,并为每个目标分区维护一个“消息序列号”;
2)producer每发送一条消息,会将<producer_id,分区>对应的“序列号”加1
3)broker端会为每一对{producer_id,分区}维护一个序列号,对于每收到的一条消息,会判断服务端的SN_OLD和接收到的消息中的SN_NEW进行对比:
- 如果SN_OLD + 1 == SN_NEW,正常;
- 如果SN_NEW<SN_OLD+1,说明是重复写入的数据,直接丢弃
- 如果SN_NEW>SN_OLD+1,说明中间有数据尚未写入,或者是发生了乱序,或者是数据丢失,将抛出严重异常:OutOfOrderSequenceException

producer.send(“aaa”) 消息aaa就拥有了一个唯一的序列号
如果这条消息发送失败,producer内部自动重试(retry),此时序列号不变;
producer.send(“bbb”) 消息bbb拥有一个新的序列号
| 注意:kafka只保证producer单个会话中的单个分区幂等; |
kafka事务(伪事务)
事务要点知识
- Kafka的事务控制原理
主要原理: 开始事务-->发送一个ControlBatch消息(事务开始)
提交事务-->发送一个ControlBatch消息(事务提交)
放弃事务-->发送一个ControlBatch消息(事务终止)
- 开启事务的必须配置参数(我不支持数据得回滚,但是我能做到,一荣俱荣,一损俱损)
| Java |
事务控制的代码模板
| Java |

消费者api是会拉取到尚未提交事务的数据的;只不过可以选择是否让用户看到!
是否让用户看到未提交事务的数据,可以通过消费者参数来配置:
isolation.level=read_uncommitted(默认值)
isolation.level=read_committed
- kafka还有一个“高级”事务控制,只针对一种场景:
用户的程序,要从kafka读取源数据,数据处理的结果又要写入kafka
kafka能实现端到端的事务控制(比起上面的“基础”事务,多了一个功能,通过producer可以将consumer的消费偏移量绑定到事务上提交)
| Java |
事务api示例
为了实现事务,应用程序必须提供唯一transactional.id,并且开启生产者的幂等性
| Java |
kafka生产者中提供的关于事务的方法如下:

“消费kafka-处理-生产结果到kafka”典型场景下的代码结构示例:
| Java |
6.8.3事务实战案例
在实际数据处理中,consume-transform-produce是一种常见且典型的场景;

在此场景中,我们往往需要实现,从“读取source数据,至业务处理,至处理结果写入kafka”的整个流程,具备原子性:
| 要么全流程成功,要么全部失败! |
(处理且输出结果成功,才提交消费端偏移量;处理或输出结果失败,则消费偏移量也不会提交)
要实现上述的需求,可以利用Kafka中的事务机制:
它可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理,即使该生产或消费会跨多个topic分区;
在消费端有一个参数isolation.level,与事务有着莫大的关联,这个参数的默认值为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。
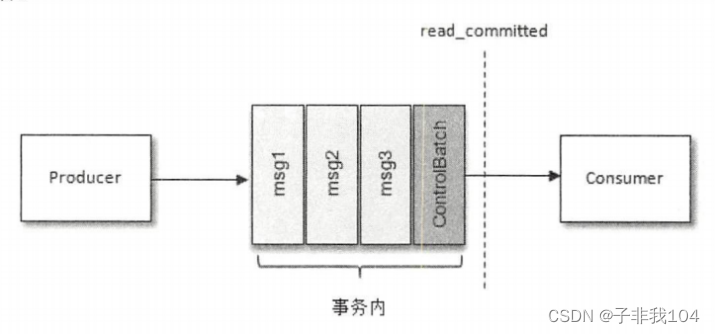
| 控制消息(ControlBatch:COMMIT/ABORT)表征事务是被提交还是被放弃 |
分区数与吞吐量
Kafka本身提供用于生产者性能测试的kafka-producer-perf-test.sh 和用于消费者性能测试的 kafka-consumer-perf-test. sh,主要参数如下:
- topic 用来指定生产者发送消息的目标主题;
- num-records 用来指定发送消息的总条数
- record-size 用来设置每条消息的字节数;
- producer-props 参数用来指定生产者的配置,可同时指定多组配置,各组配置之间以空格分隔与 producer-props 参数对应的还有一个 producer-config参数,它用来指定生产者的配置文件;
- throughput 用来进行限流控制,当设定的值小于0时不限流,当设定的值大于0时,当发送的吞吐量大于该值时就会被阻塞一段时间。
| 经验:如何把kafka服务器的性能利用到最高,一般是让一台机器承载( cpu线程数*2~3 )个分区 测试环境: 节点3个,cpu 2核2线程,内存8G ,每条消息1k 测试结果: topic在12个分区时,写入、读取的效率都是达到最高 写入: 75MB/s ,7.5万条/s 读出: 310MB/s ,31万条/s 当分区数>12 或者 <12 时,效率都比=12时要低! |