初探基因组组装——生信原理第四次实验报告
文章目录
- 初探基因组组装——生信原理第四次实验报告
- 实验目的
- 实验内容
- 实验题目
- 第一题
- 题目
- 用SOAPdenovo 进行基因组组装
- 评估组装质量
- 第二题
- 题目
- Canu组装
- Hifiasm组装
- 基于nucmer的基因组比对
- 过滤比对结果
- 转换为可读性强的tab键分隔的文件, -H去除标题行
- 通过鉴定SNP和Indel,识别两种组装结果的差异
- 统计SNP和Indel的数量
- 讨论
- 调整参数
- 基因组组装的连续性
- 组装差异
- 提高空间
实验目的
1.回顾Linux系统的常用命令的使用
2.掌握常用三代和二代测序组装软件各至少一种的使用,并理解关键参数的含义,熟悉测序数据fastq等格式
3.会编写程序计算N50/L50等组装连续性指标
4.会使用基因组比对工具MUMmer进行序列比对,并寻找SNP等变异
实验内容
1.使用组装软件SOAPdenovo、canu、Hifiasm分别组装大肠杆菌Escherichia coli K12基因组的二代和三代测序数据
2.编写程序计算SOAPdenovo组装contig和scaffold序列的N50/L50等组装质量评估指标
3.使用基因组比对工具MUMmer比较canu组装的contig序列和hifiasm组装的contig序列,并寻找两者之间的序列差异
实验题目
第一题
题目
首先,使用SOAPdenovo软件,组装E.coli基因组二代Illumina测序数据。然后,使用Perl/Python/C++/C/Java…任意一种编程语言编写程序,统计你组装好的E.coli基因组contig和scaffold序列的 N50、N90、L50、 L90、总的碱基数、总的序列数目、最长序列的长度。注意:contig和scaffold序列中长度小于200bp的不要统计在内。
用SOAPdenovo 进行基因组组装
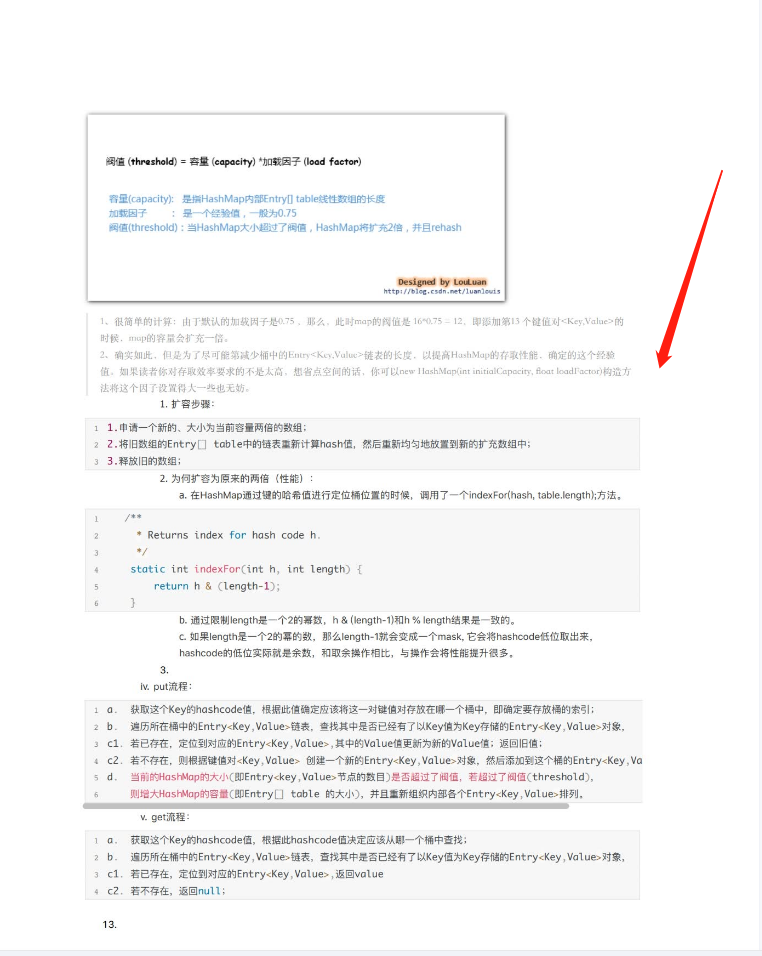
创建好文件夹之后用以下命令进行组装。
SOAPdenovo-63mer all -s /home/uu01/data/ecoli.cfg -K 51 -R -o ecoli-soap &
.contig为组装的contig序列,fasta格式
.scafSeq为组装的scaffold序列,fasta格式
评估组装质量
将组装好的E.coli基因组contig和scaffold序列传输到本地,用python计算相应指标。代码如下:
import pandas as pd
#两个文件选一个
file_path = "D:/00大三上/生信原理/Data/ecoli-soap.contig"
file_path = "D:/00大三上/生信原理/Data/ecoli-soap.scafSeq"
with open(file_path) as fa:
fa_dict = {}
for line in fa:
# 去除末尾换行符
line = line.replace('\n', '')
if line.startswith('>'):
# 去除 > 号
seq_name = line[1:]
fa_dict[seq_name] = ''
else:
# 去除末尾换行符并连接多行序列
fa_dict[seq_name] += line.replace('\n', '')
for name, seq in fa_dict.items():
fa_dict[name] = len(seq)
fa_df = pd.DataFrame.from_dict(fa_dict, orient='index', columns=['Length'])
# 这一行是筛选scaffold序列用的
# fa_df = fa_df[fa_df.index.str.contains('scaffold')]
fa_df = fa_df[fa_df.Length >= 200]
fa_df.sort_values(by='Length',ascending=False, axis=0, inplace=True)
TotalLength=fa_df['Length'].sum()
print(TotalLength)
SeqNumber = fa_df.shape[0]
print(SeqNumber)
MaxLength=fa_df['Length'][0]
print(MaxLength)
sum=0
for i in range(SeqNumber):
sum+=fa_df.Length[i]
if sum/TotalLength>0.5:
N50=fa_df.Length[i]
L50=i+1
break
print(N50)
print(L50)
sum=0
for i in range(SeqNumber):
sum+=fa_df.Length[i]
if sum/TotalLength>0.9:
N90=fa_df.Length[i]
L90=i+1
break
print(N90)
print(L90)
最终结果如下
| 评估指标 | Contig | Scaffold |
|---|---|---|
| N50 | 736 | 110687 |
| N90 | 292 | 27697 |
| L50 | 1880 | 14 |
| L90 | 5733 | 49 |
| 总碱基数 | 4491283 | 4890792 |
| 总序列数目 | 7603 | 107 |
| 最长序列的长度 | 4660 | 326711 |
第二题
题目
首先,使用canu软件, 组装E.coli基因组的Nanopore测序数据;然后,使用hifiasm软件,组装E.coli基因组的PacBio HiFi测序数据。最后,利用MUMmer软件包,比较canu组装的contig序列和hifiasm组装的contig序列两者之间的差异(需要统计有多少SNP, 多少Indel)。
Canu组装
创建完文件夹后,用如下命令进行组装:
canu -p ecoli-ont -d ./ genomeSize=4.8m -nanopore /home/uu01/data/ont.fastq &
Hifiasm组装
这个首先得解压,解压命令如下:
tar zxvf pacbio.fastq.tar.gz
解压到自己文件夹之后进行组装
hifiasm -o ecoli-hifi -t 1 ./hifi.fastq &
接着通过awk进行提取contig序列
awk '/^S/{print ">"$2;print $3}' ecoli-hifi.bp.p_ctg.gfa> ecoli-hifi.p_ctg.fa
基于nucmer的基因组比对
比对hifiasm和canu的组装序列
nucmer --maxmatch ../hifiasm/ecoli-hifi.p_ctg.fa ../canu-ont/ecoli-ont.contigs.fasta &
过滤比对结果
delta-filter -i 90 -l200 -r -q out.delta >out.filter
转换为可读性强的tab键分隔的文件, -H去除标题行
show-coords -H -T -r out.filter > out.flt.tab
通过鉴定SNP和Indel,识别两种组装结果的差异
show-snps -r -T -x 5 out.filter >out.snps
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VVdKGlKn-1670180460088)(D:/typora%E5%9B%BE%E7%89%87/image-20221205002123986.png)]](https://img-blog.csdnimg.cn/6429207bea864d35a613292a3cca1074.png)
统计SNP和Indel的数量
SNP:Single-nucleotide polymorphism,单核苷酸多态性在此数据文件中表现为第二列和第三列都是字母且不一样。
Indel:Insertion-deletion,插入或缺失,表现为第二列或第三列是.。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aTqpuo2M-1670180460088)(D:/typora%E5%9B%BE%E7%89%87/image-20221205002348301.png)]](https://img-blog.csdnimg.cn/c99dc454edfd416d958cf308a10001c5.png)
统计SNP和Indel的代码如下:
library(data.table)
data<-fread("D:/00大三上/生信原理/Data/out.snps")
Indel <- sum(data[,2]=='.' | data[,3]=='.')
# indel的个数
Indel
# snp的个数
dim(data)[1] - Indel
| SNP | Indel |
|---|---|
| 1010 | 4700 |
讨论
调整参数
尝试调整参数,结果有什么改变?为什么会出现这种变化?
我调整了SOAPdenovo的-K参数,也即是调整了组装kmer的大小,我调整为该参数的最大值和最小值。
SOAPdenovo-63mer all -s /home/uu01/data/ecoli.cfg -K 63 -R -o ecoli-soap &
SOAPdenovo-63mer all -s /home/uu01/data/ecoli.cfg -K 13 -R -o ecoli-soap &
当K为63时,运行时间为1min,k=13时运行时间为6min。
我们在选取K-mer的大小时,应该能够使得每一个K-mer都唯一的比对到基因在上。除了试,还可以用一些工具帮助我们觉得K-mer大小,比如KmerGenie等软件。
KmerGenie (psu.edu)
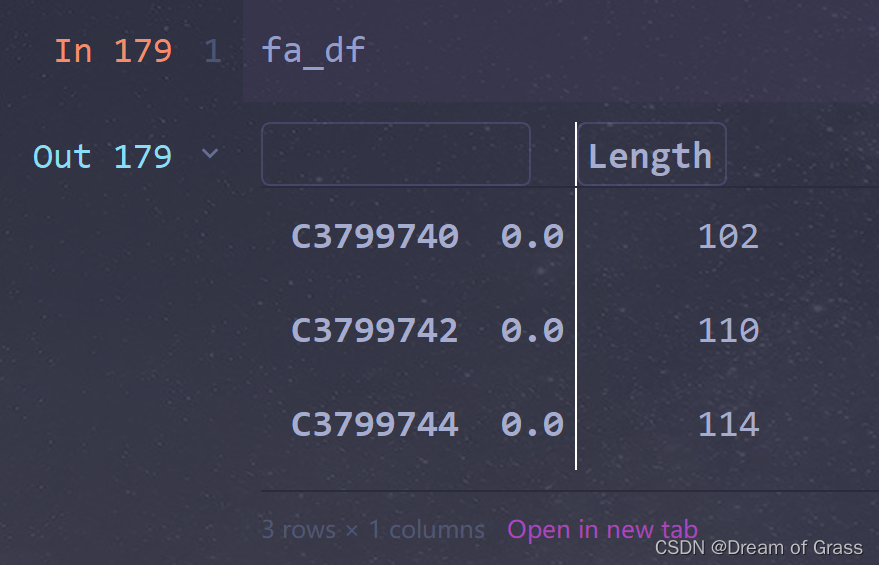
K=13时,config最长为114,连接config没有得到scaffold。
K=63时评估指标如下
| 评估指标 | Contig | Scaffold |
|---|---|---|
| N50 | 2421 | 224796 |
| N90 | 670 | 45410 |
| L50 | 629 | 8 |
| L90 | 2135 | 27 |
| 总碱基数 | 5081564 | 5006149 |
| 总序列数目 | 3529 | 63 |
| 最长序列的长度 | 17032 | 607906 |
在组装时,由于机器读长的限制,直接采用overlap进行组装的算法效果并不好,为了提升组装效果,基于kmer的算法流行了起来。
kmer 是一段固定长度的序列,这个长度是自己定义的。
kmer大小越大,就越有可能避免图中相似区域(重复、错误等)之间的歧义。如果kmer在基因组中多次存在,就会产生歧义。因此理论上较大的kmer大小会增加N50。然而,大的kmer尺寸对测序错误、杂合性和覆盖率更敏感。
基因组组装的连续性
哪个基因组组装的连续性最好?为什么它的连续性最好?
我们总共用了三种方法进行组装:SOAPdenovo、Canu和hifiasm。
我们可以用N50/N90和L50/L90评估组装连续性,如果N50/N90越大,L50/L90越小,则组装连续性越高,预示着组装质量越好。
| 组装方法 | N50/N90 | L50/L90 |
|---|---|---|
| SOAPdenovo K=51 | 4.00 | 0.16 |
| SOAPdenovo K=63 | 4.95 | 0.09 |
从连续性上来看,SOAPdenovo 方法中K取51更好。
canu和hifiasm最终的结果都是一条序列,其长度分别为4633371和4662761。
从原理上来看hifiasm连续型最好,Hifiasm使用了graph-binning的策略对此进行了改进。它不预先划分reads,而是在string-graph中对reads进行标记。因此在一个较长的bubble中,即使只有一小部分reads被正确标记,hifiasm也可以正确地将其定相。通过这种方式,可以避免因为reads划分错误而引入的错误位点和组装断裂,从而获得更完整和更准确的单倍体组装结果。
单倍体组装工具Hifiasm简介及基本运行命令(一) - 哔哩哔哩 (bilibili.com)
组装差异
同样的基因组,为什么Canu的组装序列和hifiasm的组装序列会有差异?
二者原理不同。
hifiasm的分析流程如下,主要分为3个阶段
第一阶段:通过所有序列的相互比对,对前在测序错误进行纠正。如果一个位置只存在两种碱基类型,且每个碱基类型至少有3条read支持,那么这个位置会被当作杂合位点,否则,视作测序错误,将被纠正。
第二阶段:根据序列之间的重叠关系,构建分型的字符串图(phased string graph)。其中调整朝向的序列作为顶点(vertex),一致重叠作为边(edge)。字符串图中的气泡(bubble)则是杂合位点。
第三阶段:如果没有额外的信息,hifiasm会随机选择气泡的一边构建primary assembly,另一边则是alternate assembly. 该策略和HiCanu,Falcon-Unzip一样。对于杂合基因组而言,由于存在一个以上的纯合haplotype,因此primary assembly可能还会包含haplotigs。HiCanu依赖于第三方的purge_dups, 而hifiasm内部实现了purge_dups算法的变种,简化了流程。如果有额外的信息,那么hifiasm就可以正确的对haplotype进行分型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2pAcQye-1670180460089)(D:/typora%E5%9B%BE%E7%89%87/image-7b5344ff6ef24f789babd6da65f27cf4.png)]](https://img-blog.csdnimg.cn/d0641243e9044cfbac58439abc4e0ef7.png)
Canu的流程分为三个步骤,前两步是原始输入的纠错,最后一步是基于纠错后的reads来构建contigs。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1nI7m226-1670180460089)(D:/typora%E5%9B%BE%E7%89%87/image-20191206100241398-c5b8e2076fcb4120a969dea2ad203eda.png)]](https://img-blog.csdnimg.cn/3e6dca36773b4802990f09ce5b20d536.png)
hifiasm对HiFi PacBio进行组装(xuzhougeng.top)
Canu的graph和contig生成过程(xuzhougeng.top)
提高空间
SOAPdenovo、Canu或者hifiasm组装序列的质量(连续性、准确率、完整性),是否有进一步提高的空间?有什么办法可以提高?
由于现有的Hi-C或Strand-seq分箱算法从一个折叠装配开始,它们可能不能很好地工作在初始装配中表示的高度杂合区域。而且对多倍体植物仍然具有挑战性。
一种可能的解决办法是将Hi-C或Strand-seq数据映射到hifiasm组装图上,用图的拓扑结构将单元格分组并排序到染色体长的支架上,然后沿着支架将杂合子事件分阶段。
Cheng, Haoyu et al. “Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm.” Nature methods vol. 18,2 (2021): 170-175. doi:10.1038/s41592-020-01056-5

![[附源码]计算机毕业设计校园帮平台管理系统Springboot程序](https://img-blog.csdnimg.cn/d6f9d1048cbf4c6f97b181ca4a091cd8.png)