1.问题
在中文情感分析任务中,已有方法仅从单极、单尺度来考虑情感特征,无法充分挖掘和利用情感特征信息,模型性能不理想。
单级单尺度:只从一个方面学习文本的特征
多级多尺度:应该是分别从不同方面学习文本的特征,最后进行一个融合。比如此论文中从单词、短语、句子三个方面来综合学习文本的特征。
2.解决方法
论文中提出了一种多级多尺度特征提取的 CNN-BiLSTM 模型。该模型首先利用预训练好的中文词向量模型并结合嵌入层微调来获取词级特征;然后利用多尺度短语级特征表征模块和句子级特征表征模块来分别获取短语级和句子级特征,在多尺度短语级特征表征模块中,使用具有不同卷积核尺寸的卷积网络来获取不同尺度的短语级特征;最后使用多级特征融合方法将词级特征、不同尺度的短语级特征以及句子级特征进行融合形成多级联合特征。
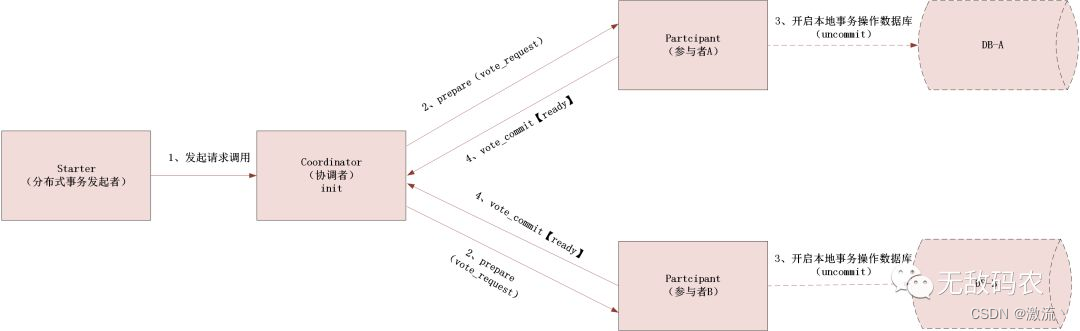
3. 多级、多尺度特征提取的 CNN-BiLSTM 模型

3.1 词级表征
首先通过预处理将一段文本映射成为对应的词向量矩阵,然后通过最大池化层对此词向量矩阵进行池化操作。
为了方便后续的多级特征融合,不同维度的多级特征将通过多层感知机(MLP)统一映射到S空间。
3.2 短语级特征表征
仅依靠词级信息尚不足以表达文本的情感信息,模型对情感极性的预测结果较差。相比词,短语往往能提供更丰富的语义和情感信息。
模型中设置了两个具有不同卷积核大小的卷积来分别提取不同距离的短语级特征,为了尽可能地减少参数量,降低模型复杂度,在确保能有效提取不同尺度的短语级特征的情况下,将卷积核的大小分别设置为3和5。为了保证在卷积操作前后输入和输出长度不变,在进行卷积之前,我们使用0来对词嵌入进行填充,然后使用最大池化获取每一个时间步上的短语级嵌入特征,最后使用 MLP 将短语级特征的空间维度统一映射到S空间。
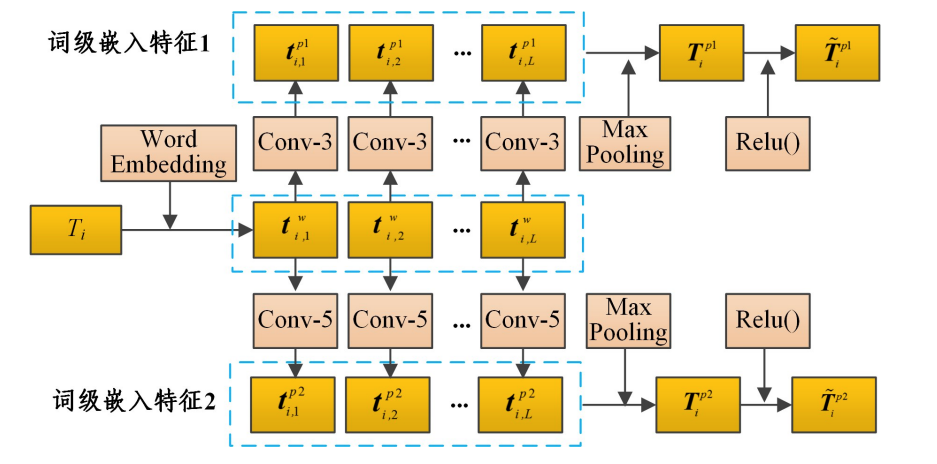
最后使用 MLP 将短语级特征的空间维度统一映射到S空间。
3.3 句子级特征表征
为了更好地理解文本描述,仅依靠局部特征信息是不充分的。因此,论文利用 Bi-LSTM 来学习词嵌入序列的全局特征以获取句子级特征。
3.4 多级特征融合
多级特征融合会将提取到的词级特征、多尺度短语级特征以及句子级特征进行多级特征融合以获取文本的联合特征。论文中使用逐元素相加的方法来进行多级特征融合

其中,![]() 表示逐元素相加。
表示逐元素相加。
然后,对于融合后的联合特征Fi,我们使用 MLP来进行学习,可表示为:
![]()
其中,Wmlp表示 MLP的参数。在 MLP中一共设置了两个隐藏层并且均使用 Relu作为非线性激活函数。最后,将学习到的联合特征输入softmax分类器中 进行情感预测。
4.实验
4.1 数据集
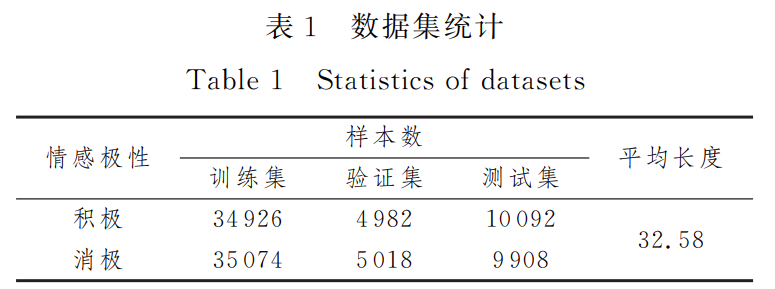
数据集来自当当网的10000条评论组成的中文数据集,并且每条评论分别对应一个积极或消极情感极性。表一显示了数据集的分布情况。
4.2 评估指标
论文中采用了Accuracy、Precision、Recall以及F1-score这4个被广泛用于情感分析任务中的评估指标。Accuracy表示情感极性预测正确的样本占样本总数的比例,Precision表示在正类中情感极性预测正确的样本数占所有样本中预测为正类样本数的比例,Recall 表示在正类样本中情感极性预测正确的样本数占所有正类样本数的比例,F1-score为 Precision和 Recall的调和值。
4.3 实验结果

由上表可知,与包括SVM 在内的8种模型相比,论文中的方法取得了最好的性能,这表明多级多尺度方法更能充分提取和利用情感特征。



![[BigGAN] Large Scale GAN Training for High Fidelity Natural Image Synthesis](https://img-blog.csdnimg.cn/be48b3fd3c264c20ba953a95f6c787ae.png)