文章目录
- torch.utils.data
- 前言
- Dataset
- Dataloader
- 实践
- 参考
torch.utils.data
前言
Pytorch中的 torch.utils.data 提供了两个抽象类:Dataset 和 Dataloader。Dataset 允许你自定义自己的数据集,用来存储样本及其对应的标签。而 Dataloader 则是在 Dataset 的基础上将其包装为一个可迭代对象,以便我们更方便地(小批量)访问数据集。
import torch
from torch.utils.data import Dataset, Dataloader
- 一些必备概念:
Data Size:整个数据集的大小;Batch Size:在训练过程中,我们不可能把所有样本一次性投喂给神经网络,只能分批次投喂。每个小批量的样本个数就是 Batch SizeIteration:将一个 Batch 投喂给神经网络称为一次 Iteration;Epoch:将所有的样本(即所有 Batch)投喂给神经网络后称为一个 Epoch。
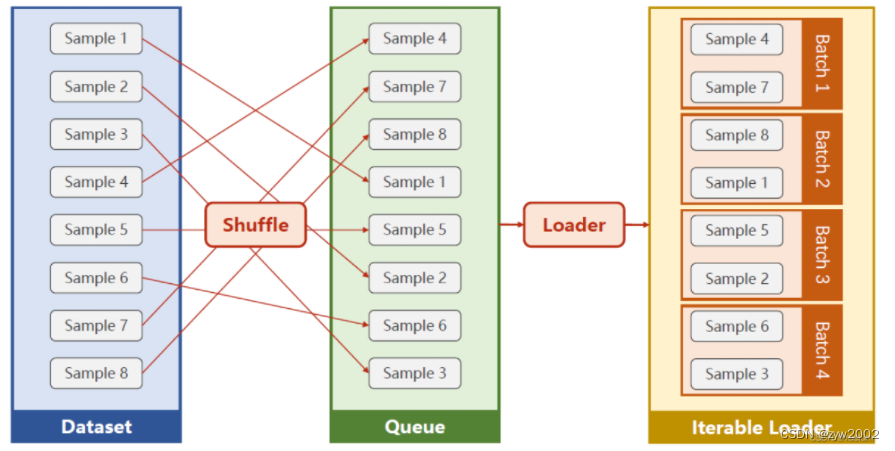
一般来说PyTorch中深度学习训练的流程是这样的:
- 创建
Dateset Dataset传递给DataLoaderDataLoader迭代产生训练数据提供给模型
# 创建Dateset(可以自定义)
dataset = face_dataset # Dataset部分自定义过的face_dataset
# Dataset传递给DataLoader
dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=False,num_workers=8)
# DataLoader迭代产生训练数据提供给模型
for i in range(epoch):
for index,(img,label) in enumerate(dataloader):
pass
到这里应该就PyTorch的数据集和数据传递机制应该就比较清晰明了。Dataset负责建立索引到样本的映射,DataLoader负责以特定的方式从数据集中迭代的产生一个个batch的样本集合。在enumerate过程中实际上是dataloader按照其参数sampler规定的策略调用了其dataset的__getitem__方法。
Dataset
可以看出,Dataset 是一个抽象类,我们自己编写的数据集类必须继承 Dataset,且需重新改写 __getitem__ 和 __len__ 方法。
__getitem__ :传入指定的索引 index 后,该方法能够根据索引返回对应的单个样本及其对应的标签(以元组形式)。
__len__ :返回整个数据集的大小,即前面所说的 Data Size。
若我们自定义的类在继承 Dataset 时没有改写__getitem__ ,则程序会抛出 NotImplementedError 的异常。此外,因为 Dataset 类中提供了 add 方法,所以继承之后我们的数据集也会拥有此方法,从而合并数据集只需使用 + 运算即可。
一般而言,我们自定义的数据集的框架如下:
class MyDataset(Dataset):
def __init__(self):
# 初始化数据集的存储路径
# 载入数据集(转化为tensor格式)
# ...
def __getitem__(self, index):
# 返回单个样本及其标签
pass
def __len__(self):
# 返回整个数据集的大小
pass
Dataloader
绝大多数时候我们需要以 batch 的形式访问数据集。Dataloader这个接口提供了这样的功能,它能够基于我们自定义的数据集将其转换成一个可迭代对象以便我们批量访问。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
参数介绍:
dataset(Dataset) – 定义好的Map式或者Iterable式数据集。batch_size(python:int, optional) – 一个batch含有多少样本 (default: 1)。shuffle(bool, optional) – 每一个epoch的batch样本是相同还是随机 (default: False)。sampler(Sampler, optional) – 决定数据集中采样的方法. 如果有,则shuffle参数必须为False。batch_sampler(Sampler, optional) – 和 sampler 类似,但是一次返回的是一个batch内所有样本的index。和 batch_size, shuffle, sampler, and drop_last 三个参数互斥。num_workers(python:int, optional) – 多少个子程序同时工作来获取数据,多线程。 (default: 0)collate_fn(callable, optional) – 合并样本列表以形成小批量。pin_memory(bool, optional) – 如果为True,数据加载器在返回前将张量复制到CUDA固定内存中。drop_last(bool, optional) – 如果数据集大小不能被batch_size整除,设置为True可删除最后一个不完整的批处理。如果设为False并且数据集的大小不能被batch_size整除,则最后一个batch将更小。(default: False)timeout(numeric, optional) – 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。 (default: 0)worker_init_fn(callable, optional) – 每个worker初始化函数 (default: None)
实践
假设当前工作目录下有一个 data.txt,其内容如下:
1 -14 -15
1 -1 -15
1 -11 -14
1 0 -2
0 -4 2
1 7 -2
1 -7 -17
0 9 12
0 5 -14
1 -13 13
其中每一行都是一个样例。每行中的后两个数字为样本的特征,第一个数字为样本对应的标签。可以看出,我们一共有 10 1010 个样本,它们均位于二维欧式空间中,且问题为二分类问题。
于是数据集的框架可以这样写:
class MyDataset(Dataset):
def __init__(self, path):
self.data = np.loadtxt(path)
self._X = torch.from_numpy(self.data[:, 1:])
self._y = torch.from_numpy(self.data[:, 0])
def __getitem__(self, index):
return self._X[index], self._y[index]
def __len__(self):
return len(self._X)
使用时只需创建实例即可
path = './data.txt'
data = MyDataset(path)
我们可以调用各个方法来观察一下
len(data)
# 10
data[1]
# (tensor([ -1., -15.], dtype=torch.float64), tensor(1., dtype=torch.float64))
事实上,data是一个可迭代对象,我们可以直接使用 for 循环来输出整个数据集:
for feature, label in data:
print(feature, label)
# tensor([-14., -15.], dtype=torch.float64) tensor(1., dtype=torch.float64)
# tensor([ -1., -15.], dtype=torch.float64) tensor(1., dtype=torch.float64)
# tensor([-11., -14.], dtype=torch.float64) tensor(1., dtype=torch.float64)
# tensor([ 0., -2.], dtype=torch.float64) tensor(1., dtype=torch.float64)
# tensor([-4., 2.], dtype=torch.float64) tensor(0., dtype=torch.float64)
# tensor([ 7., -2.], dtype=torch.float64) tensor(1., dtype=torch.float64)
# tensor([ -7., -17.], dtype=torch.float64) tensor(1., dtype=torch.float64)
# tensor([ 9., 12.], dtype=torch.float64) tensor(0., dtype=torch.float64)
# tensor([ 5., -14.], dtype=torch.float64) tensor(0., dtype=torch.float64)
# tensor([-13., 13.], dtype=torch.float64) tensor(1., dtype=torch.float64)
创建dataloader :
dataloader = DataLoader(data, batch_size=3, shuffle=False, drop_last=False)
该代码将创建一个可迭代对象,我们将其列表化来观察一下:
list(dataloader)
# [[tensor([[-14., -15.],
# [ -1., -15.],
# [-11., -14.]], dtype=torch.float64),
# tensor([1., 1., 1.], dtype=torch.float64)],
# [tensor([[ 0., -2.],
# [-4., 2.],
# [ 7., -2.]], dtype=torch.float64),
# tensor([1., 0., 1.], dtype=torch.float64)],
# [tensor([[ -7., -17.],
# [ 9., 12.],
# [ 5., -14.]], dtype=torch.float64),
# tensor([1., 0., 0.], dtype=torch.float64)],
# [tensor([[-13., 13.]], dtype=torch.float64),
# tensor([1.], dtype=torch.float64)]]
可以看出,列表化后,每一个 batch 均以列表的形式存储。这说明我们可以通过 for 循环来遍历所有的 batch,具体做法如下:
for inputs, labels in dataloader:
print(inputs, labels)
# tensor([[-14., -15.],
# [ -1., -15.],
# [-11., -14.]], dtype=torch.float64) tensor([1., 1., 1.], dtype=torch.float64)
# tensor([[ 0., -2.],
# [-4., 2.],
# [ 7., -2.]], dtype=torch.float64) tensor([1., 0., 1.], dtype=torch.float64)
# tensor([[ -7., -17.],
# [ 9., 12.],
# [ 5., -14.]], dtype=torch.float64) tensor([1., 0., 0.], dtype=torch.float64)
# tensor([[-13., 13.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
有些时候,我们需要记录每个 batch 的索引(即 iteration),则需要用到 enumerate函数(这里为了方便展示将 batch_size设为了1):
dataloader = DataLoader(data, batch_size=1, shuffle=True, drop_last=True)
for batch_idx, (inputs, labels) in enumerate(dataloader):
print(batch_idx, end=' ')
print(inputs, labels)
# 0 tensor([[-4., 2.]], dtype=torch.float64) tensor([0.], dtype=torch.float64)
# 1 tensor([[ -1., -15.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 2 tensor([[ 0., -2.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 3 tensor([[ 7., -2.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 4 tensor([[ 9., 12.]], dtype=torch.float64) tensor([0.], dtype=torch.float64)
# 5 tensor([[ 5., -14.]], dtype=torch.float64) tensor([0.], dtype=torch.float64)
# 6 tensor([[-11., -14.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 7 tensor([[-14., -15.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 8 tensor([[ -7., -17.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
# 9 tensor([[-13., 13.]], dtype=torch.float64) tensor([1.], dtype=torch.float64)
若要使用 Dataloader 进行神经网络训练,则需要将特征转化为 torch.float32
型,标签转化为 torch.int64型。
参考
PyTorch学习笔记(三)–Dataset和DataLoader_Lareges的博客-CSDN博客_dataset和dataloader
Pytorch之Dataset与DataLoader


![[阶段4 企业开发进阶] 3. 消息队列--RabbitMQ](https://img-blog.csdnimg.cn/3b2dca96cac045d386d56ecb257cd6fb.png#pic_center)
![[附源码]计算机毕业设计校刊投稿系统Springboot程序](https://img-blog.csdnimg.cn/54f724cde166462cb9ad7f65e0a165e5.png)
![[附源码]计算机毕业设计线上社区管理系统Springboot程序](https://img-blog.csdnimg.cn/5536eb21df34473bba4ddf46f2e94b8f.png)


![[附源码]JAVA毕业设计框架的企业机械设备智能管理系统的设计与实现(系统+LW)](https://img-blog.csdnimg.cn/a1d56a0926054c0b8eaff5b13ed87295.png)