文章目录
- Overview
- Text classification 的主要任务
- Topic Classification
- Sentiment Analysis
- Native Language Identification
- Natural Language Inference
- 如何构造 Text Classifier
- Classification Algorithms
- Bias - Variance Balance
- 朴素贝叶斯
- Logistic Regression
- Support Vector Machines (SVM)
- K-nearest neighbor
- Decision Tree
- Random Forests
- Neural Networks
- 超参数选择
- Evaluation
- ACC
- Recall & Precision
- F1-score
Overview

Text classification 的主要任务

Topic Classification

主题分类(Topic Classification)是NLP中的一项任务,其目标是根据内容将文本(如文章、博客、新闻报道、社交媒体帖子等)分类到预先定义的主题或类别中。
以下是主题分类的一些关键概念和步骤:
-
文本表示: 在进行主题分类之前,通常需要将文本转换为数值形式。常见的方法包括使用词袋模型、TF-IDF、词嵌入(例如 Word2Vec、GloVe)等。这些方法可以帮助捕捉文本中的重要特征和模式。
-
特征选择: 对于主题分类,不是所有的词都是有用的。一些常见的词(例如"is"、“the”、“a”)可能对分类没有太大的帮助,可能需要删除。这可以通过停用词列表来实现。另一方面,一些特定的词可能对特定的主题有很强的预测力,这些词应该被保留。
-
模型训练: 在得到数值表示后,可以使用各种机器学习模型进行训练,包括朴素贝叶斯、支持向量机、逻辑回归、随机森林、神经网络等。每种模型都有其优点和缺点,需要根据具体的任务和数据进行选择。
-
评估: 模型训练后,需要在验证集或测试集上进行评估。常用的评估指标包括准确率、精确率、召回率和F1分数等。
Sentiment Analysis

情感分析(Sentiment Analysis),又称为意见挖掘(Opinion Mining),是自然语言处理、文本挖掘和计算语言学交叉领域的一个任务,目的是确定来源材料的情绪态度。它可以识别和提取在各种文本资源中的主观信息。例如,评论的情绪可能是正面的、负面的或中性的。
以下是情感分析的一些关键概念和技术:
-
粒度级别: 情感分析可以在不同的粒度级别进行,包括文档级别(整个文档或评论的总体情感)、句子级别(单个句子的情感)和实体/方面级别(对某一实体或某一方面的情感)。
-
情感极性: 大多数情感分析任务都关注于分类情感极性(例如,正面、负面、中性)。然而,一些更复杂的任务可能会尝试检测更多的情绪,如快乐、悲伤、愤怒、惊讶等。
-
技术方法: 情感分析的技术方法包括基于词典的方法(依赖情感词典进行评分)、基于机器学习的方法(使用标注数据训练分类器)和深度学习方法(使用神经网络模型,如RNN、CNN和Transformer等)。
-
情感分析的应用: 情感分析广泛应用于许多领域,包括社交媒体监控、在线评论分析、品牌声誉管理和电影或产品评价等。
-
挑战: 情感分析面临的挑战包括讽刺和矛盾的检测、情感强度的度量、多语言和多领域情感分析、以及缺乏大量标注数据等。
Native Language Identification

Native Language Identification (NLI) 是一个研究领域,它关注如何从个体的第二语言(L2)写作中识别他们的母语(L1)。这种识别通常是通过分析文本中的语言使用模式,比如语法结构、词汇选择、拼写错误等等。
这个任务的挑战之一在于,人们在学习和使用第二语言时,他们的母语经常会影响他们的第二语言的使用。这种影响(也被称为转移)在语音、语法、词汇和其他语言层次上都可能出现。NLI 系统需要能够捕捉这些微妙但统计上可检测的模式,以便识别出个体的母语。
NLI 在许多应用中都有潜在的用途,例如:
教育:通过了解学生的母语背景,教师或教育软件可以更好地定制教学方法,特别是针对可能受到母语影响的特定问题。
法匪鉴定:如果嫌疑人在书面威胁或网络犯罪中使用的是他们的第二语言,NLI 可能有助于缩小潜在嫌疑人的范围。
社会语言学:NLI 可以提供有关语言转移和第二语言习得的研究数据。
在实践中,NLI 通常使用机器学习和自然语言处理技术来实现。这可能包括从文本中提取各种语言特征(如 n-grams、POS 标签、句法结构等),然后使用这些特征来训练一个分类模型,如支持向量机、随机森林或神经网络。
Natural Language Inference

自然语言推理(Natural Language Inference, NLI)是一项自然语言处理(NLP)任务,其目标是确定一段文本(假设)是否可以从另一段文本(前提)中推导出来。在这个任务中,给定一对前提和假设,需要确定这对之间的关系,这种关系通常被分类为:
-
蕴含(Entailment):如果前提的真实性确保假设的真实性,那么就存在蕴含关系。例如,前提 “The dog is barking loudly” 蕴含 “The dog is making noise”。
-
矛盾(Contradiction):如果前提的真实性确保假设的假性,那么就存在矛盾关系。例如,前提 “The cat is sleeping” 和假设 “The cat is running” 之间就存在矛盾。
-
中立(Neutral):如果前提的真实性不能确保假设的真实性或假性,那么这两者之间的关系就是中立的。例如,前提 “The woman is reading a book” 和假设 “The woman is enjoying the book” 之间的关系就是中立的,因为我们无法从前提中确定她是否喜欢这本书。
NLI 是一项在NLP中有着广泛应用的任务,包括问答系统、信息提取和文本摘要等。理解和模型化自然语言之间的这种复杂关系对于实现真正的语言理解至关重要。
在实现上,可以使用各种机器学习技术来处理NLI任务,包括传统的机器学习方法(如支持向量机)和深度学习方法(如递归神经网络和Transformer)。最近的研究主要集中在深度学习方法上,因为它们在处理这种任务时表现出了优秀的性能。
如何构造 Text Classifier

Classification Algorithms

Bias - Variance Balance
在机器学习中,偏差(Bias)和方差(Variance)是两个重要的概念,它们是用来描述模型在预测时所犯错误类型和程度的。
-
偏差(Bias): 偏差是指模型预测的平均值与实际值之间的差异。高偏差可能会导致模型在训练数据上表现不佳,这通常是由于模型过于简单(即欠拟合),无法捕捉到数据的真实结构。例如,如果你试图使用一条直线(线性模型)来拟合非线性数据,你可能会得到高偏差。
-
方差(Variance): 方差是指模型预测的变化范围或分散程度。高方差可能会导致模型在训练数据上表现良好,但在新的、未见过的数据上表现较差,这通常是由于模型过于复杂(即过拟合),以至于捕捉到了数据的噪声。例如,如果你使用一个过于复杂的多项式来拟合数据,你可能会得到高方差。
偏差和方差在机器学习中形成了一个重要的权衡问题:即我们既希望模型能够尽可能地接近数据(低偏差),又希望模型对数据的微小变化不敏感(低方差)。在实际应用中,选择适当的模型复杂度和进行适当的正则化可以帮助我们在偏差和方差之间找到一个好的平衡。这种权衡被称为偏差-方差权衡(Bias-Variance Tradeoff)。
朴素贝叶斯


Logistic Regression

逻辑回归(Logistic Regression)是一种用于解决二元分类问题的机器学习模型。虽然其名字中包含“回归”,但实际上它是用于分类任务的。
逻辑回归预测的是 某一事件发生的概率,其输出值介于0和1之间。这是通过使用逻辑函数(或称为sigmoid函数)实现的,该函数能够将任何值都映射到一个介于0和1之间的值。
逻辑回归模型的形式通常如下:
P ( Y = 1 ∣ X ) = 1 / ( 1 + e ( − ( b 0 + b 1 ∗ X 1 + b 2 ∗ X 2 + . . . + b n ∗ X n ) ) ) P(Y=1|X) = 1 / (1 + e^{(-(b_0 + b_1*X_1 + b_2*X_2 + ... + b_n*X_n))}) P(Y=1∣X)=1/(1+e(−(b0+b1∗X1+b2∗X2+...+bn∗Xn)))
在这个公式中, P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X) 代表给定输入特征 X X X 时,目标变量 Y Y Y 等于 1 1 1 的概率。 X 1 X_1 X1 至 X n X_n Xn 代表输入特征, b 0 b_0 b0 至 b n b_n bn 代表模型参数,其中 b 0 b_0 b0 通常被称为偏置项(bias term), b 1 b_1 b1 至 b n b_n bn 是与各个特征相对应的权重。
逻辑回归的参数通常通过 最大化对数似然函数(Log-Likelihood Function)来估计,可以使用梯度下降等优化算法来实现。
虽然逻辑回归主要用于二元分类,但它也可以通过某些技术(如“一对多”策略)来用于多类别分类。
逻辑回归的一个重要优点是其预测结果不仅是类别标签,还是事件发生的概率,这对于许多需要概率预测的任务来说非常有用。此外,如果特征与目标之间的关系较为线性,逻辑回归往往可以得到不错的效果。

Support Vector Machines (SVM)
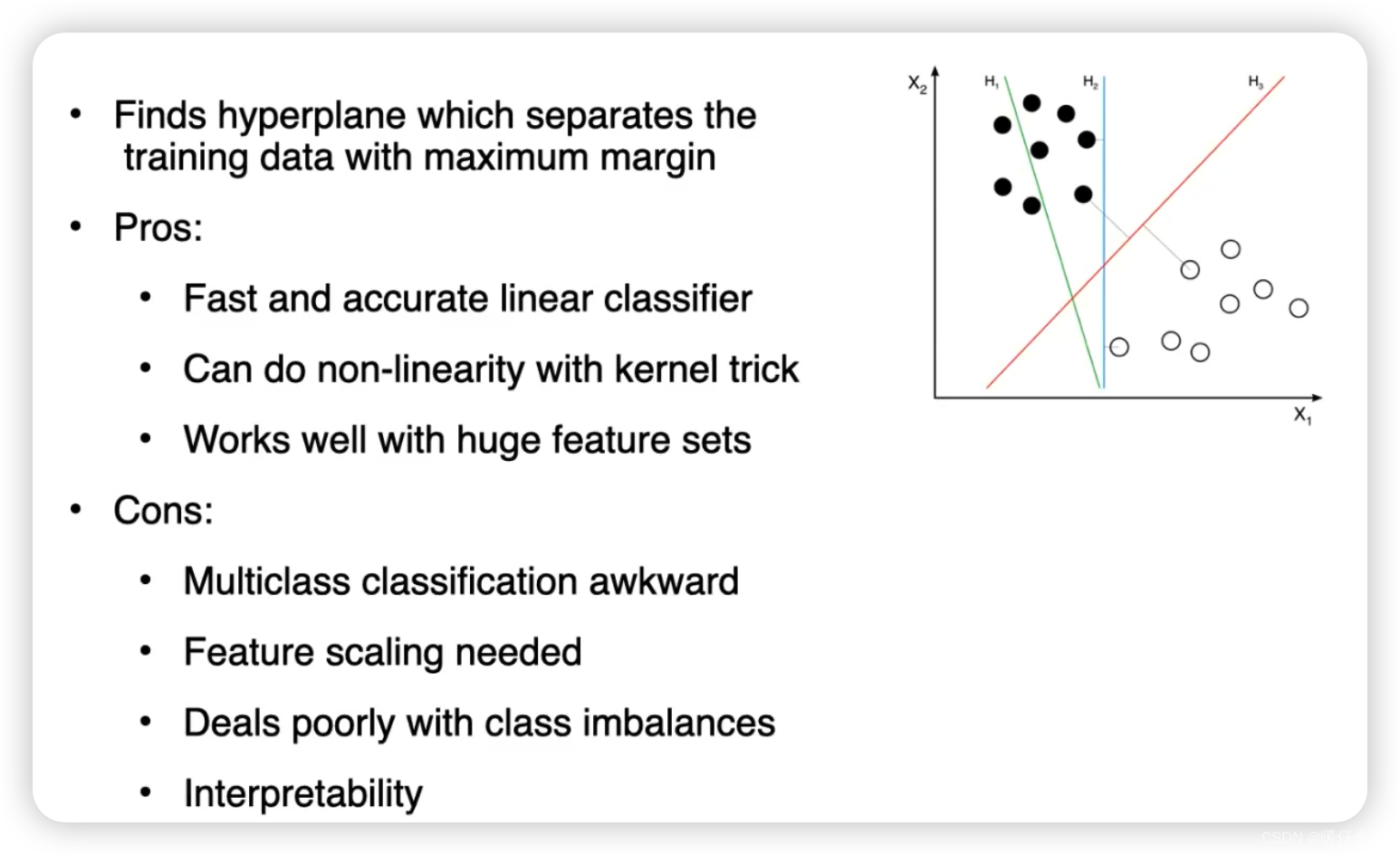
以下是为什么SVM适合在NLP领域使用的几个原因:
-
高维数据处理能力: 在NLP任务中,常见的做法是将文本数据转换为高维的向量空间(比如使用词袋模型),这就需要机器学习模型能有效处理高维数据。SVM由于其间隔最大化的特性,能有效地处理高维数据,对应到高维空间中的超平面可以很好地进行分类。
-
稀疏性: 在NLP中,特征经常是稀疏的(即大部分特征值为零)。例如,一个词可能只在少数几个文档中出现,但在大多数文档中不出现。SVM能够很好地处理这种稀疏性,因为它主要关注分类边界附近(即支持向量对应的)的数据点,而忽略远离边界的数据点。
-
有效的核函数: 在处理文本数据时,线性模型可能不足以捕捉到复杂的关系。SVM的一个主要优势在于,它可以利用核函数将数据映射到高维空间,从而在这个高维空间中找到一个线性的分类边界。这使得SVM能够捕捉到更复杂的、非线性的关系。
-
强大的泛化能力: SVM被设计为控制过拟合的风险,即使在维度数大于样本数的情况下也能保持良好的性能。这使得SVM在面对NLP任务时具有强大的泛化能力。
以上这些特性使得SVM在NLP中得到了广泛的应用,例如在情感分析、文本分类、信息检索等任务中。
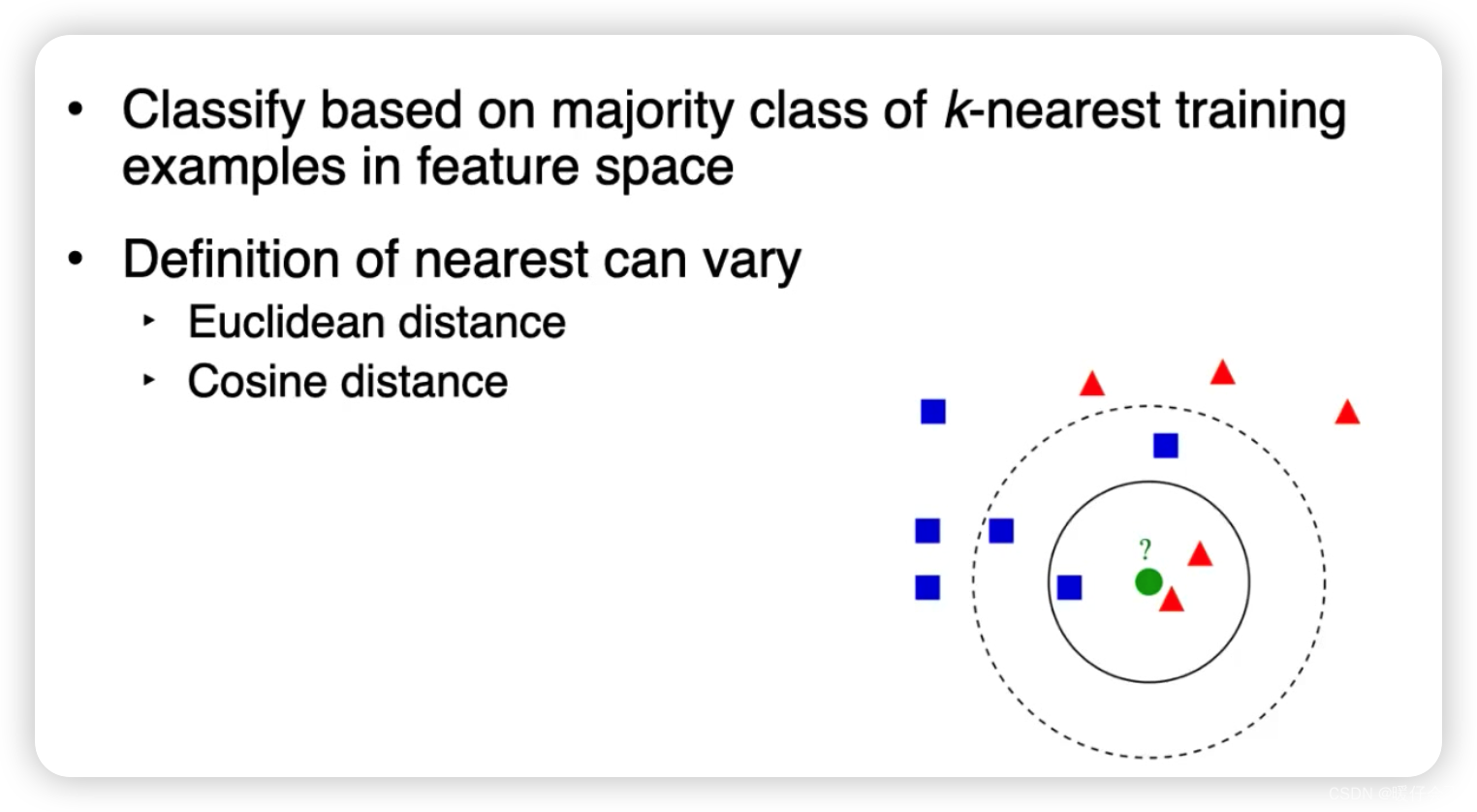
K-nearest neighbor

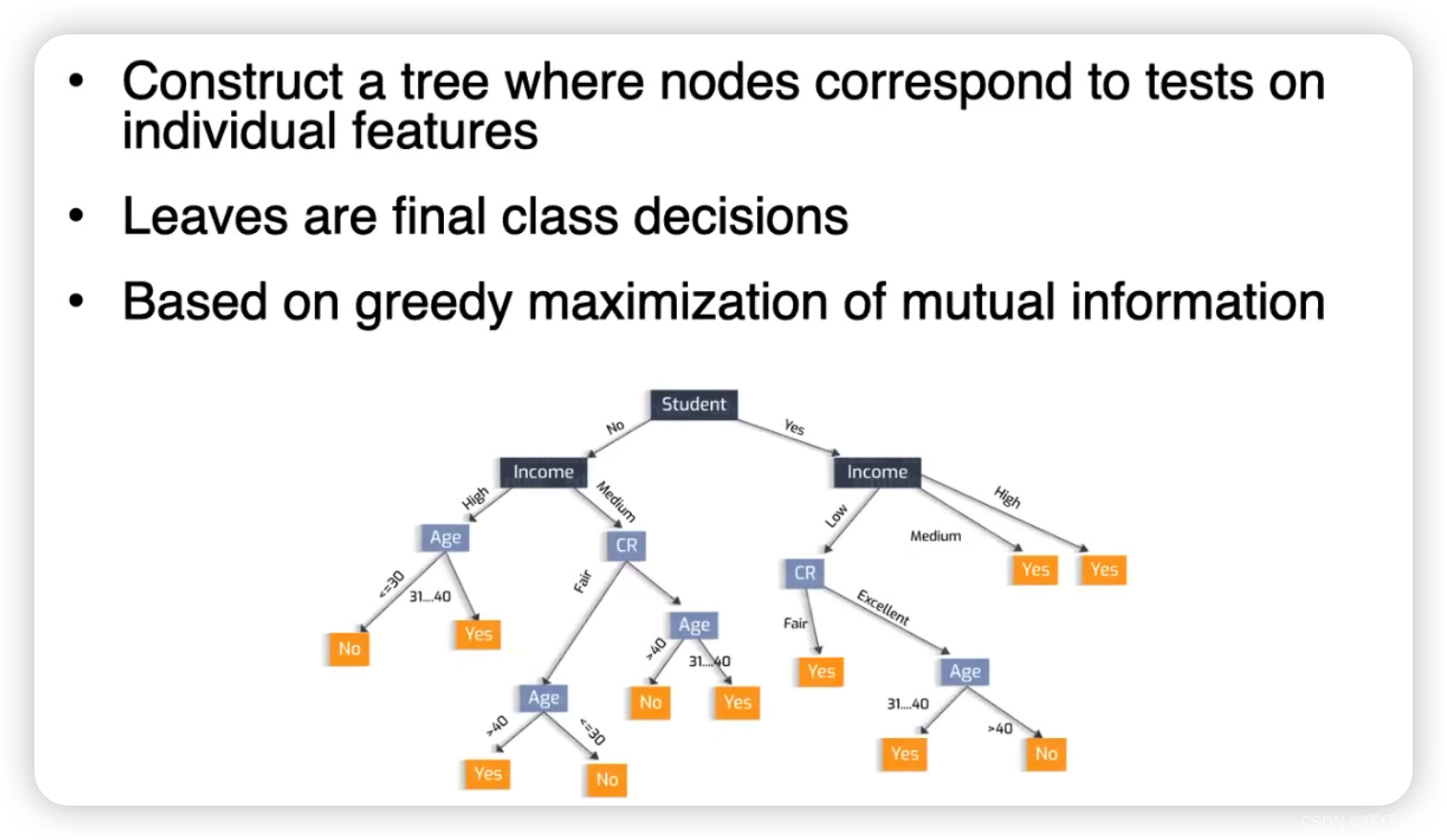
Decision Tree

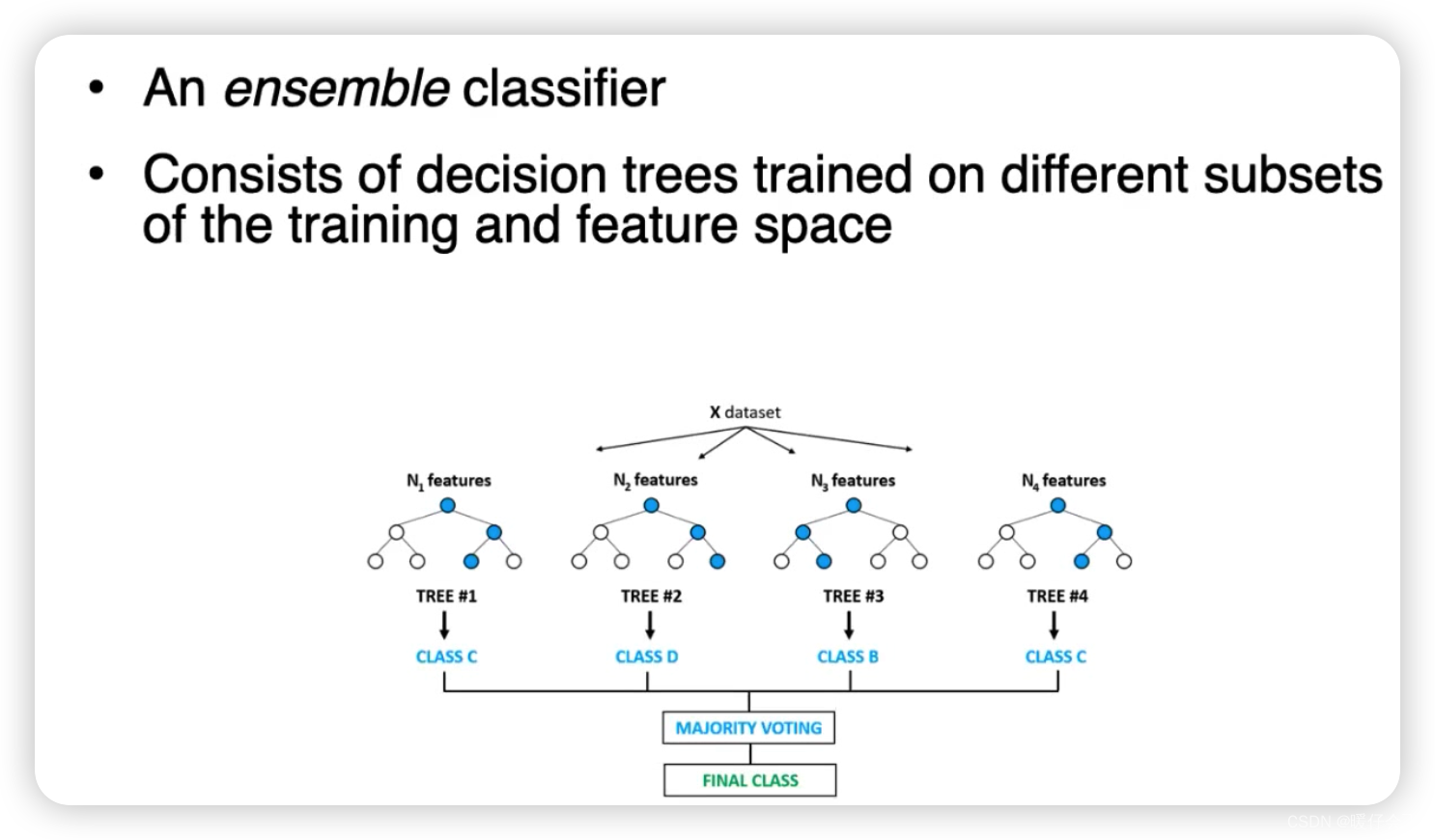
Random Forests

Neural Networks
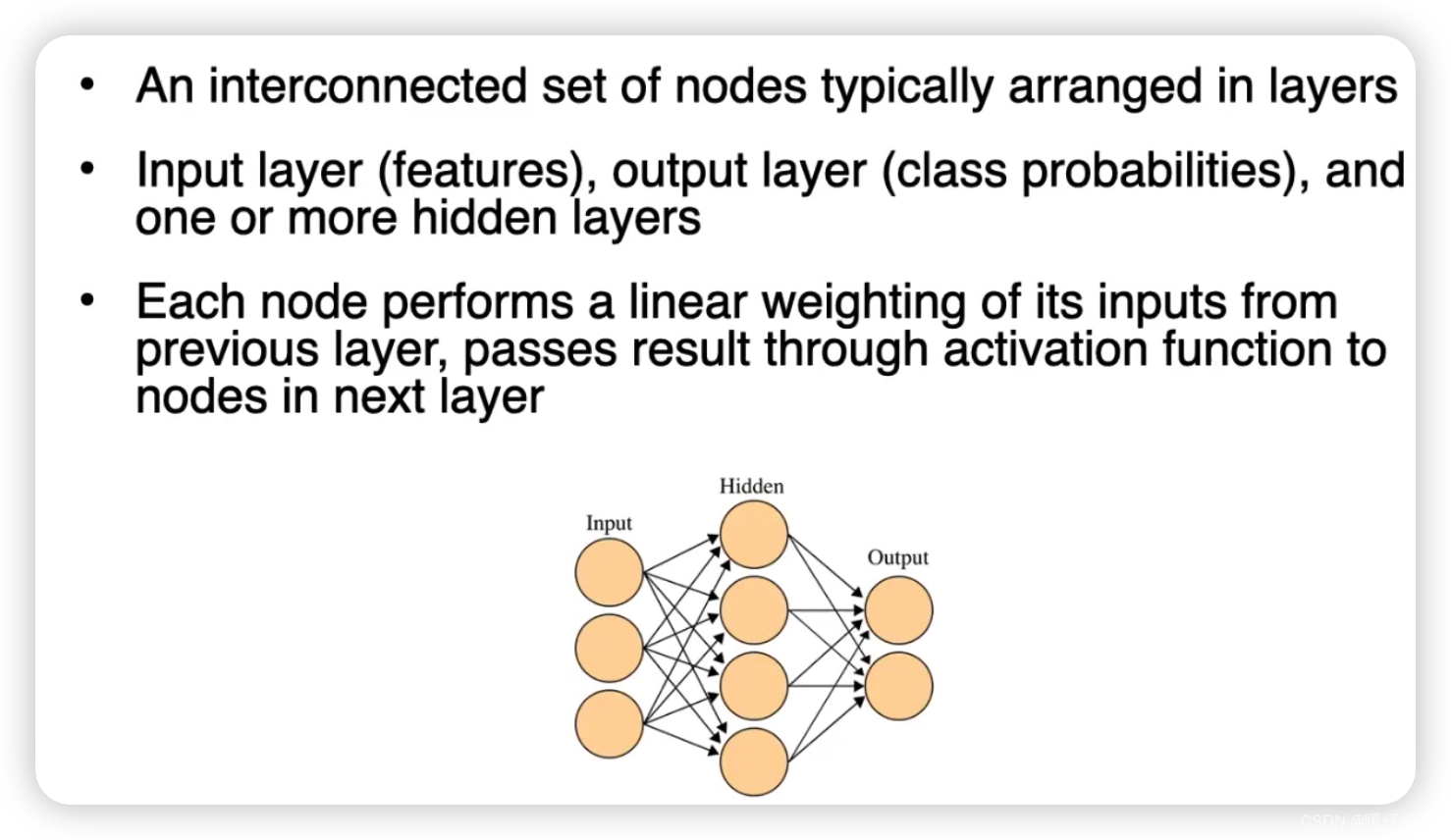

超参数选择

Evaluation
ACC

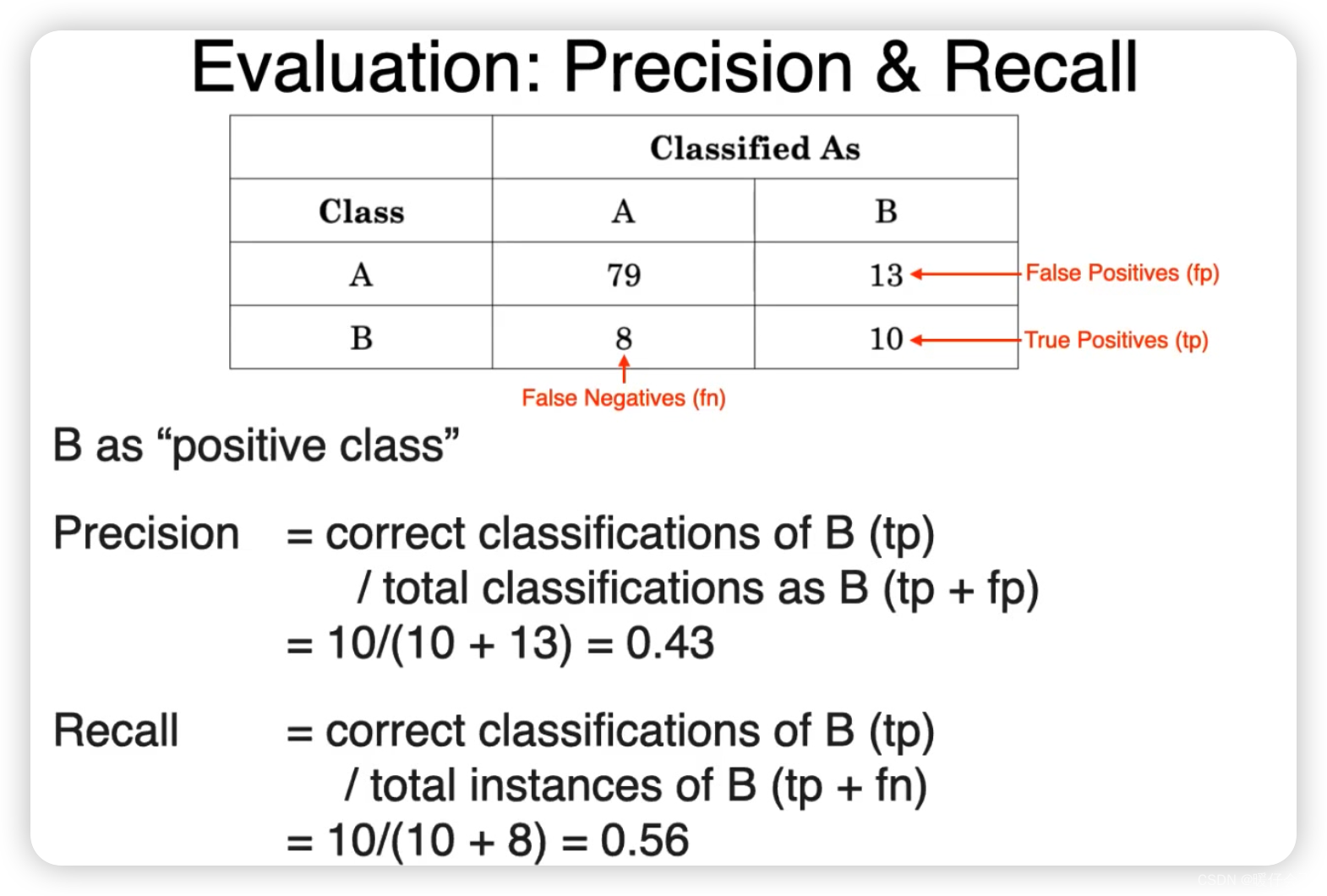
Recall & Precision
F1-score