目录
- ROUGE
- 核心思想
- 评价标准
- ROUGE-N
- ROUGE-L
ROUGE
ROUGE的全称是Recall-Oriented Understudy for Gisting Evaluation, 是一种基于召回率指标的评价算法.
核心思想
由多个专家分别生成人工摘要, 构成标准摘要集.
将模型生成的自动摘要和人工摘要做对比, 通过统计两者之间重叠的基本单元的数量, 来评价模型摘要的表现.
通过多条人类专家的摘要做对比, 提高了评价系统的稳定性和健壮性.
评价标准
- ROUGE-N评价:
主要统计n-gram上的召回率, 比较人工摘要和模型摘要分别计算n-gram的结果. - ROUGE-L评价:
L指最长公共子序列(Longest Common Subsequence, LCS), 比较人工摘要和模型摘要的最长公共子序列.
ROUGE-N

示例:
机器摘要C: a cat is on the table
人工摘要S1: there is a cat on the table
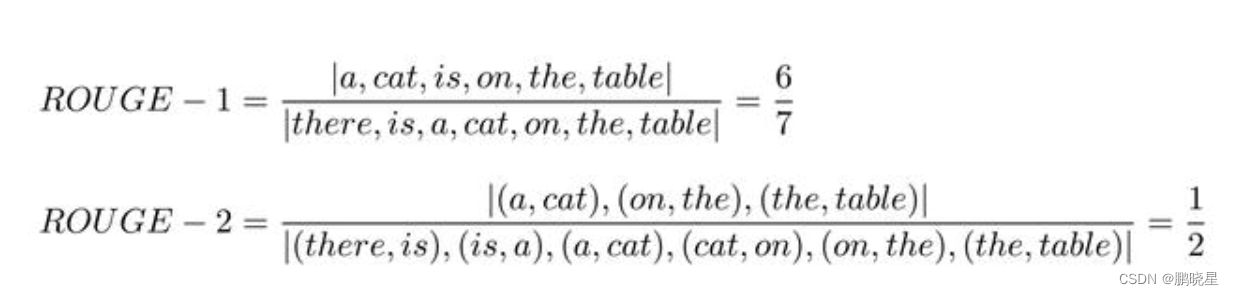
优点: 直观, 简洁, 能反应文本的词序.
缺点: 区分度不高, 且当N > 3时, ROUGE-N值通常很小.
ROUGE-L
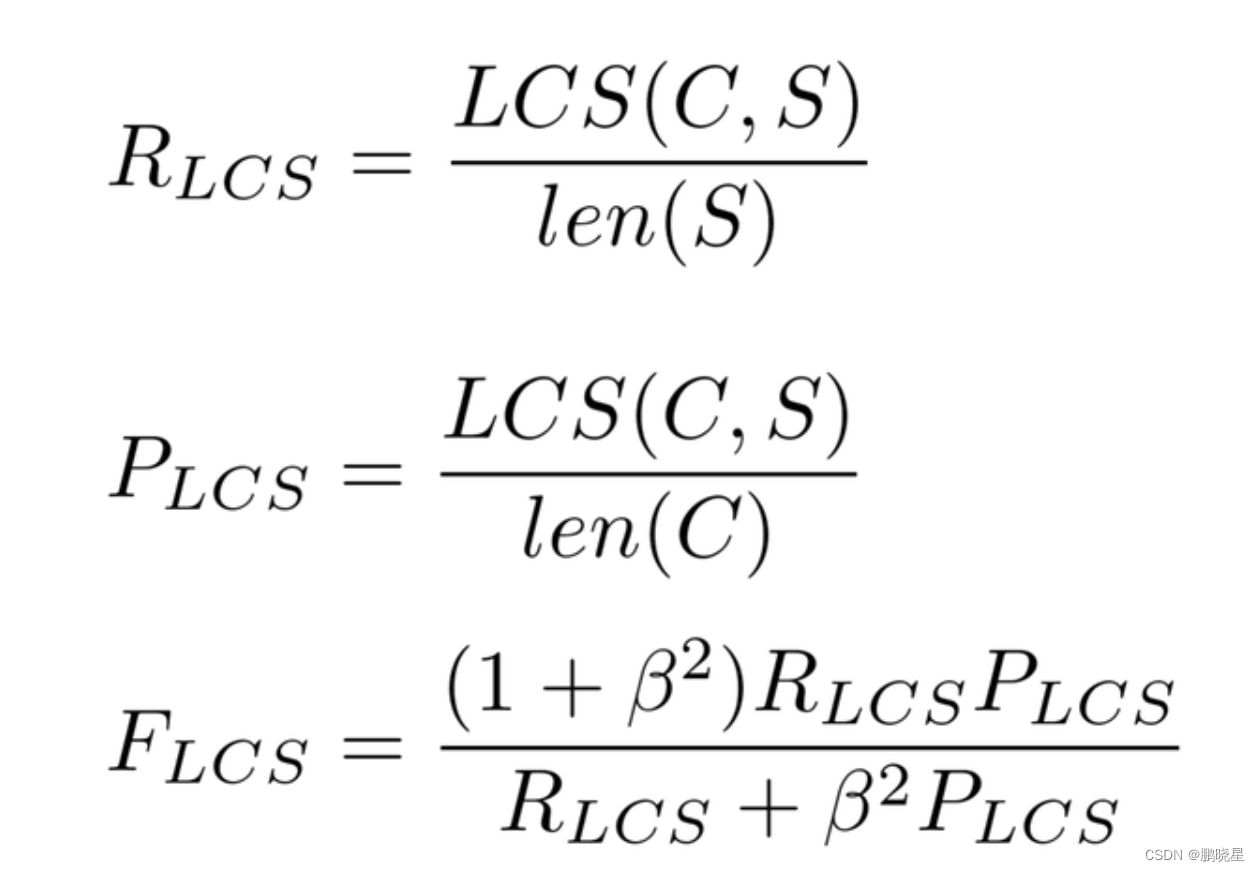
- R_LCS: 表示召回率.
- P_LCS: 表示精确率.
- F_LCS: 表示ROUGE-L分数.
化简后:
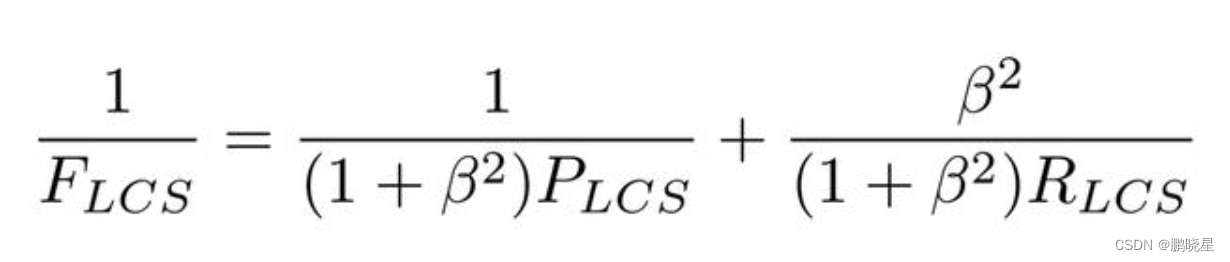
通常beta超参值很大,第一项可以忽略
示例:
机器摘要C: a cat is on the table
人工摘要S1: there is a cat on the table
按照公式R_LCS计算,
分母len(S1) = 7,
分子LCS(C, S1) = 5 (a cat on the table),
R_LCS = 5/7, 即ROUGE-L分数等于5/7.
优点: 不要求词的连续匹配, 只要求按词的出现顺序匹配即可, 能够像n-gram一样反应句子级别的词序. 自动匹配最长公共子序列, 不需要预定义n-gram的长度超参数.
缺点: 只计算一个最长子序列, 最终的值忽略了其他备选的最长子序列及较短子序列的特征和影响.
心得:初步了解了ROUGE,简单记录一下,还有ROUGE-W和ROUGE-S两个标准,暂不记录