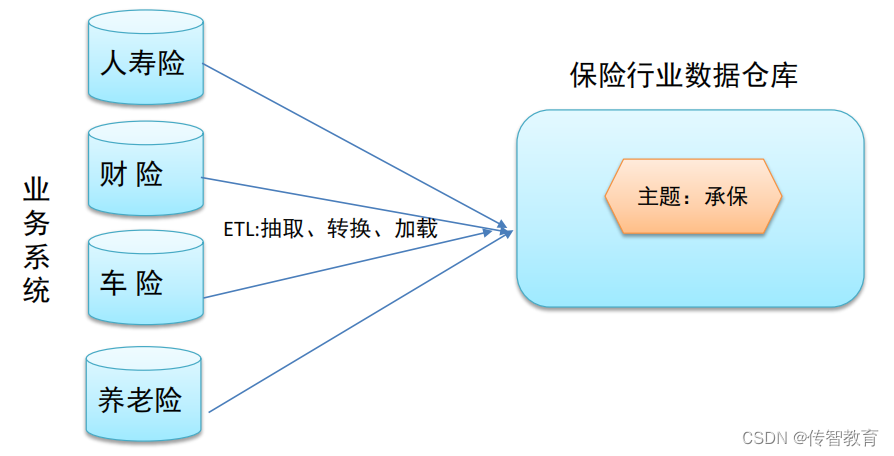
在我们平常的测试盘的过程中,fio是一款业界最为通用的工具,通过Fio可以只知道一个盘具体的带宽,iops,延迟等等.比如下面这段fio的log
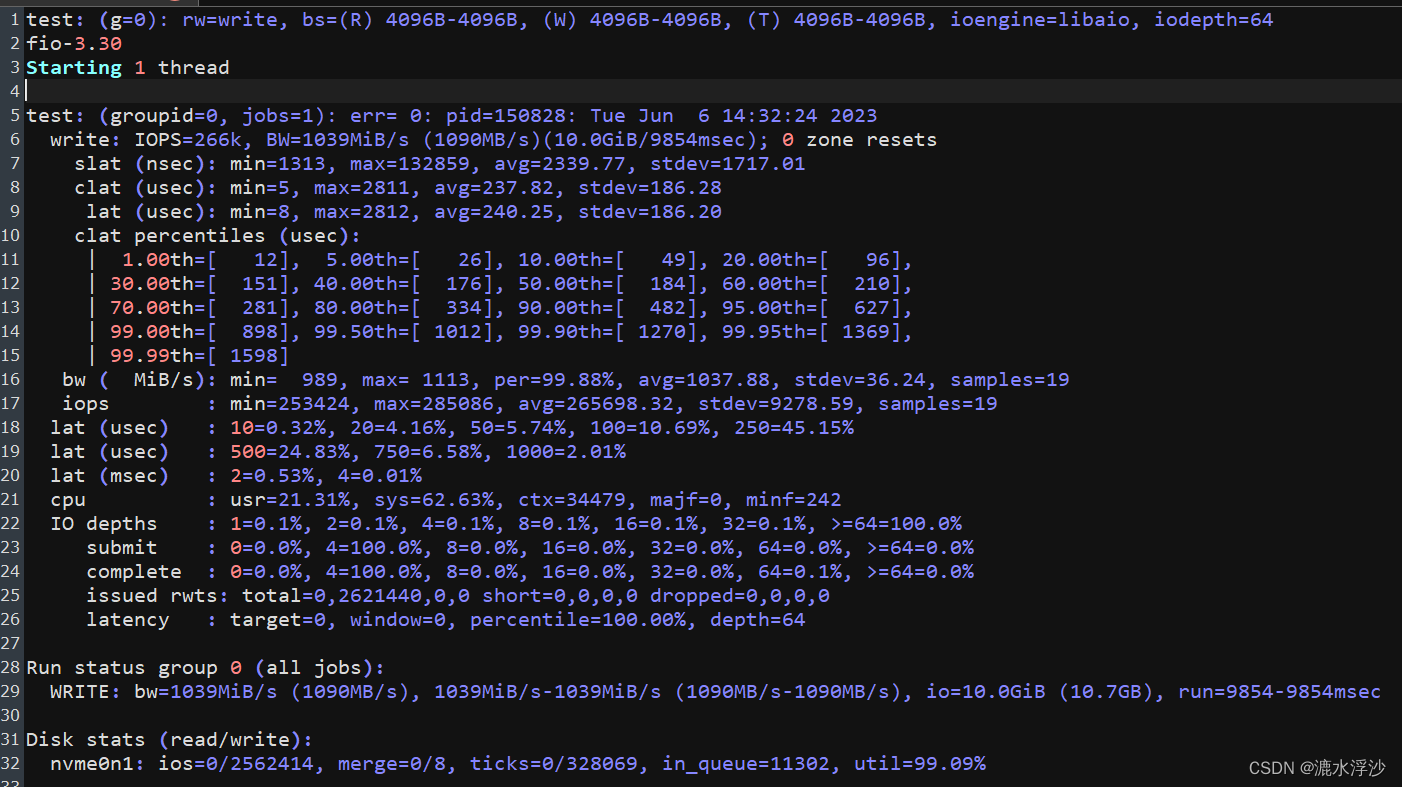
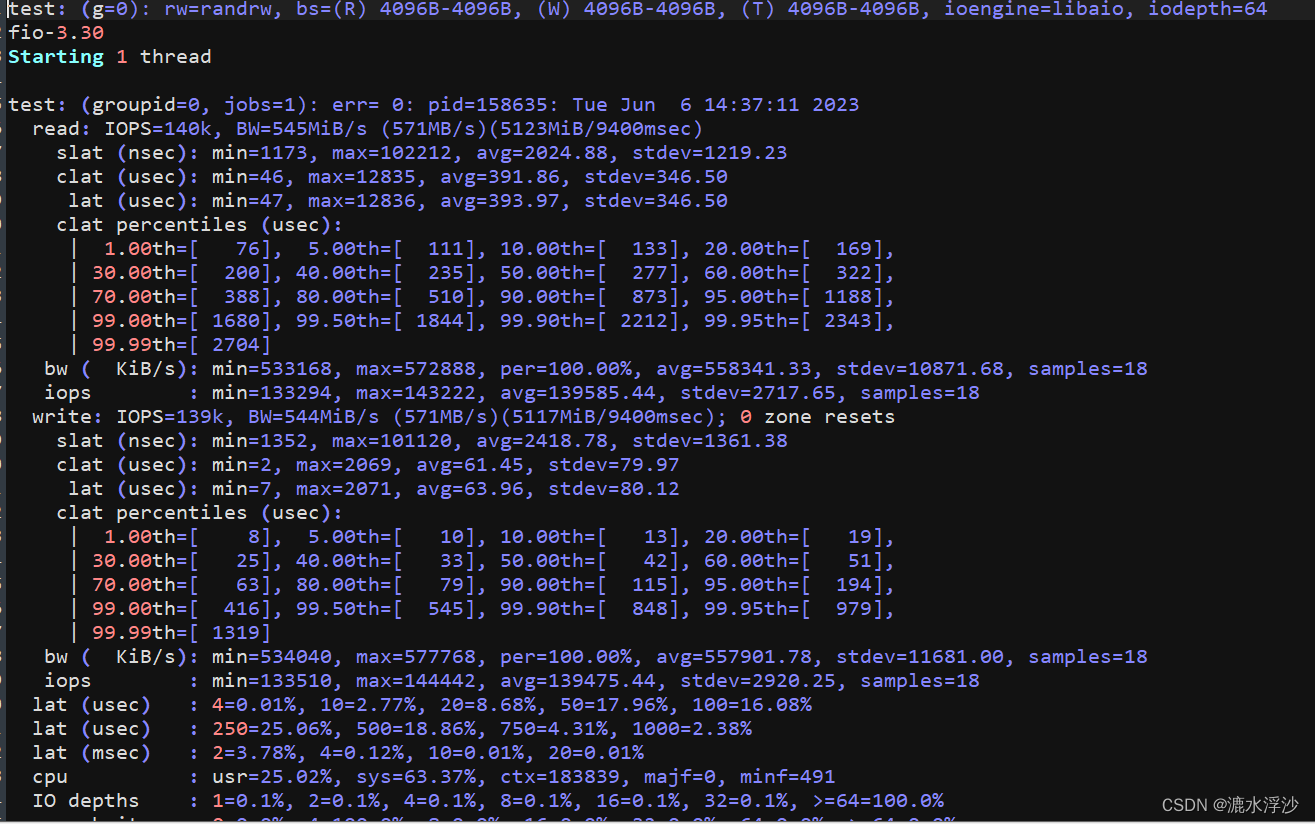
这里边需要拿出log里的一些参数 做成表格 如下:
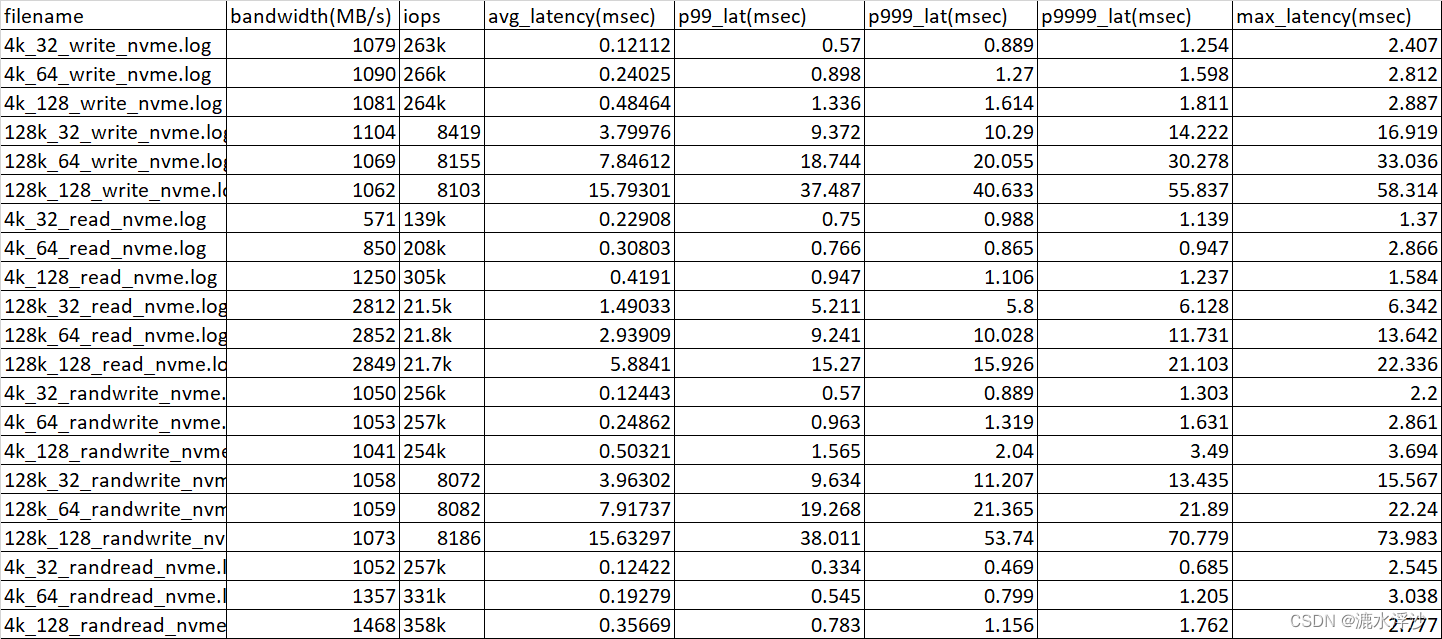
下面说下如何用Python解析log并做成表格
1 同样是用到Python中文件函数open,调用四个模块sys,os,re和argparse模块 如下:
#!/usr/bin/python
import argparse
import sys
import os
import re
sys.argv[n]是传递Python脚本的第几个参数,这里我主要用到三个参数:
inputfile :代表要打开的fio log文件
resultfile:代表要输出的解析结果
rwm: 代表read.write,mix三种读写模式
os 模块:调用Linux指令
re模块: 筛选字符串所用
这里因为要考虑两种读写模式:混合读写和非混合读写模式
因为两种log的格式不一样
2 第二步就是把里边的值筛选出来了
iops = IOPS
bw = 带宽
avg_lat = lat平均延迟
max_lat = lat最大延迟
clat99 = 代表clat99%的点延迟
clat999 = 代表clat99.9%的点延迟
clat9999 =代表clat99.99%的点延迟
clat_unit = clat延迟的单位
(1)IOPS和BW在同一行可以用 ","分割来求出,BW的话需要过滤掉括号,并且按照MB单位进行换算
#!/usr/bin/python
import argparse
import sys
import os
import re
inputfile = sys.argv[1]
resultfile = sys.argv[3]
rwm = sys.argv[2]
def not_mix_fio():
datastr = open(inputfile).read()
data=datastr.split(",")
datalat=datastr.split("\n")
iops = ""
bw = ""
avg_lat = ""
max_lat = ""
clat99 = ""
clat999 = ""
clat9999 = ""
clat_unit = ""
for i in data:
if "IOPS" in i:
iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp=re.findall(r'[(](.*?)[)]', i)
bw=temp[0][:-4]
unit=temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
bw=float(bw)/1000
print("iops=",iops)
print("bw=",bw)
运行如下:

(2)筛选出lat的最大值和平均值 并且单位以ms为准
以换行符分割较为简单
#!/usr/bin/python
import argparse
import sys
import os
import re
inputfile = sys.argv[1]
resultfile = sys.argv[3]
rwm = sys.argv[2]
def not_mix_fio():
datastr = open(inputfile).read()
data=datastr.split(",")
datalat=datastr.split("\n")
iops = ""
bw = ""
avg_lat = ""
max_lat = ""
clat99 = ""
clat999 = ""
clat9999 = ""
clat_unit = ""
for i in data:
if "IOPS" in i:
iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp=re.findall(r'[(](.*?)[)]', i)
bw=temp[0][:-4]
unit=temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
bw=float(bw)/1000
print("iops=",iops)
print("bw=",bw)
for line in datalat:
if "lat" in line and "clat" not in line and "slat" not in line and "max" in line and "avg" in line:
if "max" in line:
max_lat = line.split("max=")[1].split(",")[0].strip()
if "K" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000)
if "M" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000000)
if "usec" in line:
max_lat = str(float(max_lat)/1000)
if "nsec" in line:
max_lat = str(float(max_lat)/1000000)
if "avg" in line:
avg_lat = line.split("avg=")[1].split(",")[0].strip()
if "K" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000)
if "M" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000000)
if "usec" in line:
avg_lat = str(float(avg_lat)/1000)
if "nsec" in line:
avg_lat = str(float(avg_lat)/1000000)
print("avg_lat=",avg_lat)
print("max_lat=",max_lat)
sys.exit(1)
打印如下:
 (3)求出99 999 和999的值 单位仍然以ms为主
(3)求出99 999 和999的值 单位仍然以ms为主
#!/usr/bin/python
import argparse
import sys
import os
import re
inputfile = sys.argv[1]
resultfile = sys.argv[3]
rwm = sys.argv[2]
def not_mix_fio():
datastr = open(inputfile).read()
data=datastr.split(",")
datalat=datastr.split("\n")
iops = ""
bw = ""
avg_lat = ""
max_lat = ""
clat99 = ""
clat999 = ""
clat9999 = ""
clat_unit = ""
for i in data:
if "IOPS" in i:
iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp=re.findall(r'[(](.*?)[)]', i)
bw=temp[0][:-4]
unit=temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
bw=float(bw)/1000
print("iops=",iops)
print("bw=",bw)
for line in datalat:
if "lat" in line and "clat" not in line and "slat" not in line and "max" in line and "avg" in line:
if "max" in line:
max_lat = line.split("max=")[1].split(",")[0].strip()
if "K" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000)
if "M" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000000)
if "usec" in line:
max_lat = str(float(max_lat)/1000)
if "nsec" in line:
max_lat = str(float(max_lat)/1000000)
if "avg" in line:
avg_lat = line.split("avg=")[1].split(",")[0].strip()
if "K" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000)
if "M" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000000)
if "usec" in line:
avg_lat = str(float(avg_lat)/1000)
if "nsec" in line:
avg_lat = str(float(avg_lat)/1000000)
print("avg_lat=",avg_lat)
print("max_lat=",max_lat)
#sys.exit(1)
if "clat percentiles" in line and "usec" in line:
clat_unit = "usec"
if "clat percentiles" in line and "nsec" in line:
clat_unit = "nsec"
if "99.00th" in line:
clat99 = line.split("99.00th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
clat999 = line.split("99.90th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
if "99.99th" in line:
clat9999=line.split("99.99th=")[1].split("[")[1].split("]")[0].strip()
if clat_unit == "usec":
clat9999 = str(float(clat9999)/1000)
clat999 = str(float(clat999) / 1000)
clat99 = str(float(clat99) / 1000)
if clat_unit == "nsec":
clat9999 = str(float(clat9999)/1000000)
clat999 = str(float(clat999) / 1000000)
clat99 = str(float(clat99) / 1000000)
print("clat99=",clat99)
print("clat999=",clat999)
print("clat9999=",clat9999)
sys.exit()
打印如下:

(4)接下来就是把这些值放在CSV里,还是调用open函数
#!/usr/bin/python
import argparse
import sys
import os
import re
inputfile = sys.argv[1]
resultfile = sys.argv[3]
rwm = sys.argv[2]
def not_mix_fio():
datastr = open(inputfile).read()
data=datastr.split(",")
datalat=datastr.split("\n")
iops = ""
bw = ""
avg_lat = ""
max_lat = ""
clat99 = ""
clat999 = ""
clat9999 = ""
clat_unit = ""
for i in data:
if "IOPS" in i:
iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp=re.findall(r'[(](.*?)[)]', i)
bw=temp[0][:-4]
unit=temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
bw=float(bw)/1000
print("iops=",iops)
print("bw=",bw)
for line in datalat:
if "lat" in line and "clat" not in line and "slat" not in line and "max" in line and "avg" in line:
if "max" in line:
max_lat = line.split("max=")[1].split(",")[0].strip()
if "K" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000)
if "M" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000000)
if "usec" in line:
max_lat = str(float(max_lat)/1000)
if "nsec" in line:
max_lat = str(float(max_lat)/1000000)
if "avg" in line:
avg_lat = line.split("avg=")[1].split(",")[0].strip()
if "K" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000)
if "M" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000000)
if "usec" in line:
avg_lat = str(float(avg_lat)/1000)
if "nsec" in line:
avg_lat = str(float(avg_lat)/1000000)
print("avg_lat=",avg_lat)
print("max_lat=",max_lat)
#sys.exit(1)
if "clat percentiles" in line and "usec" in line:
clat_unit = "usec"
if "clat percentiles" in line and "nsec" in line:
clat_unit = "nsec"
if "99.00th" in line:
clat99 = line.split("99.00th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
clat999 = line.split("99.90th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
if "99.99th" in line:
clat9999=line.split("99.99th=")[1].split("[")[1].split("]")[0].strip()
if clat_unit == "usec":
clat9999 = str(float(clat9999)/1000)
clat999 = str(float(clat999) / 1000)
clat99 = str(float(clat99) / 1000)
if clat_unit == "nsec":
clat9999 = str(float(clat9999)/1000000)
clat999 = str(float(clat999) / 1000000)
clat99 = str(float(clat99) / 1000000)
print("clat99=",clat99)
print("clat999=",clat999)
print("clat9999=",clat9999)
#sys.exit()
write_line = "filename,bandwidth(MB/s),iops,avg_latency(msec),p99_lat(msec),p999_lat(msec),p9999_lat(msec),max_latency(msec)\n"
fd = open(resultfile + ".csv","a")
if not os.path.getsize(resultfile + ".csv"):
fd.write(write_line)
fd.close()
write_line = "%s,%s,%s,%s,%s,%s,%s,%s\n" %(inputfile.split("/")[-1],bw,iops,avg_lat,clat99,clat999,clat9999,max_lat)
fd=open(resultfile + ".csv","a")
fd.write(write_line)
fd.close()
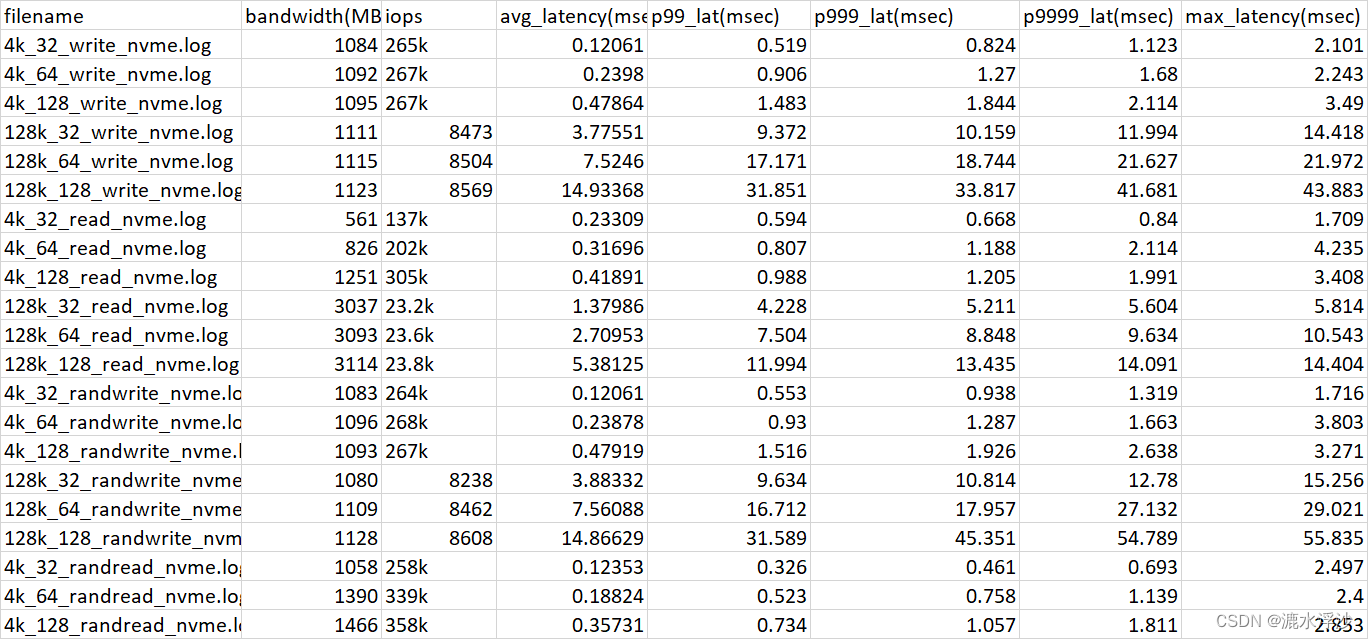
表格如下:

3 后面把混合读写解析方法补上几乎类似.这里我是用split(“write:”)来分割read和write
#!/usr/bin/python
import argparse
import sys
import os
import re
inputfile = sys.argv[1]
resultfile = sys.argv[3]
rwm = sys.argv[2]
def not_mix_fio():
datastr = open(inputfile).read()
data=datastr.split(",")
datalat=datastr.split("\n")
iops = ""
bw = ""
avg_lat = ""
max_lat = ""
clat99 = ""
clat999 = ""
clat9999 = ""
clat_unit = ""
for i in data:
if "IOPS" in i:
iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp=re.findall(r'[(](.*?)[)]', i)
bw=temp[0][:-4]
unit=temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
bw=float(bw)/1000
for line in datalat:
if "lat" in line and "clat" not in line and "slat" not in line and "max" in line and "avg" in line:
if "max" in line:
max_lat = line.split("max=")[1].split(",")[0].strip()
if "K" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000)
if "M" in max_lat.upper():
max_lat = str(float(max_lat[:-1])*1000000)
if "usec" in line:
max_lat = str(float(max_lat)/1000)
if "nsec" in line:
max_lat = str(float(max_lat)/1000000)
if "avg" in line:
avg_lat = line.split("avg=")[1].split(",")[0].strip()
if "K" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000)
if "M" in avg_lat.upper():
avg_lat = str(float(avg_lat[:-1])*1000000)
if "usec" in line:
avg_lat = str(float(avg_lat)/1000)
if "nsec" in line:
avg_lat = str(float(avg_lat)/1000000)
if "clat percentiles" in line and "usec" in line:
clat_unit = "usec"
if "clat percentiles" in line and "nsec" in line:
clat_unit = "nsec"
if "99.00th" in line:
clat99 = line.split("99.00th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
clat999 = line.split("99.90th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
if "99.99th" in line:
clat9999=line.split("99.99th=")[1].split("[")[1].split("]")[0].strip()
if clat_unit == "usec":
clat9999 = str(float(clat9999)/1000)
clat999 = str(float(clat999) / 1000)
clat99 = str(float(clat99) / 1000)
if clat_unit == "nsec":
clat9999 = str(float(clat9999)/1000000)
clat999 = str(float(clat999) / 1000000)
clat99 = str(float(clat99) / 1000000)
write_line = "filename,bandwidth(MB/s),iops,avg_latency(msec),p99_lat(msec),p999_lat(msec),p9999_lat(msec),max_latency(msec)\n"
fd = open(resultfile + ".csv","a")
if not os.path.getsize(resultfile + ".csv"):
fd.write(write_line)
fd.close()
write_line = "%s,%s,%s,%s,%s,%s,%s,%s\n" %(inputfile.split("/")[-1],bw,iops,avg_lat,clat99,clat999,clat9999,max_lat)
fd=open(resultfile + ".csv","a")
fd.write(write_line)
fd.close()
def mix_fio():
datastr = open(inputfile).read()
data = datastr.split("write:")
read_data = data[0].split("\n")
write_data = data[1].split("\n")
read_iops = ""
read_bw = ""
read_avg_lat = ""
read_max_lat = ""
read_clat99 = ""
read_clat999 = ""
read_clat9999 = ""
read_clat_unit = ""
write_iops = ""
write_bw = ""
write_avg_lat = ""
write_max_lat = ""
write_clat99 = ""
write_clat999 = ""
write_clat9999 = ""
write_clat_unit = ""
for i in data[0].split(","):
if "IOPS" in i:
read_iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp = re.findall(r'[(](.*?)[)]', i)
read_bw = temp[0][:-4]
unit = temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
read_bw = float(read_bw) / 1000
for line in read_data:
if "lat" in line and "clat" not in line and "slat" not in line and "max" in line and "avg" in line:
if "max" in line:
read_max_lat = line.split("max=")[1].split(",")[0].strip()
if "K" in read_max_lat.upper():
read_max_lat = str(float(read_max_lat[:-1]) * 1000)
if "M" in read_max_lat.upper():
read_max_lat = str(float(read_max_lat[:-1]) * 1000000)
if "usec" in line:
read_max_lat = str(float(read_max_lat) / 1000)
if "nsec" in line:
read_max_lat = str(float(read_max_lat) / 1000000)
if "avg" in line:
read_avg_lat = line.split("avg=")[1].split(",")[0].strip()
if "K" in read_avg_lat.upper():
read_avg_lat = str(float(read_avg_lat[:-1]) * 1000)
if "M" in read_avg_lat.upper():
read_avg_lat = str(float(read_avg_lat[:-1]) * 1000000)
if "usec" in line:
read_avg_lat = str(float(read_avg_lat) / 1000)
if "nsec" in line:
read_avg_lat = str(float(read_avg_lat) / 1000000)
if "clat percentiles" in line and "usec" in line:
read_clat_unit = "usec"
if "clat percentiles" in line and "nsec" in line:
read_clat_unit = "nsec"
if "99.00th" in line:
read_clat99 = line.split("99.00th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
read_clat999 = line.split("99.90th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
if "99.99th" in line:
read_clat9999 = line.split("99.99th=")[1].split("[")[1].split("]")[0].strip()
if read_clat_unit == "usec":
read_clat9999 = str(float(read_clat9999) / 1000)
read_clat999 = str(float(read_clat999) / 1000)
read_clat99 = str(float(read_clat99) / 1000)
if read_clat_unit == "nsec":
read_clat9999 = str(float(read_clat9999) / 1000000)
read_clat999 = str(float(read_clat999) / 1000000)
read_clat99 = str(float(read_clat99) / 1000000)
for i in data[1].split(","):
if "IOPS" in i:
write_iops = i.split("IOPS=")[1].strip()
if "BW" in i:
temp = re.findall(r'[(](.*?)[)]', i)
write_bw = temp[0][:-4]
unit = temp[0][-4:]
if unit == "kB/s" or unit == "KB/s":
write_bw = float(write_bw) / 1000
for line in write_data:
if "lat" in line and "clat" not in line and "slat" not in line and "max" in line and "avg" in line:
if "max" in line:
write_max_lat = line.split("max=")[1].split(",")[0].strip()
if "K" in write_max_lat.upper():
write_max_lat = str(float(write_max_lat[:-1]) * 1000)
if "M" in write_max_lat.upper():
write_max_lat = str(float(write_max_lat[:-1]) * 1000000)
if "usec" in line:
write_max_lat = str(float(write_max_lat) / 1000)
if "nsec" in line:
write_max_lat = str(float(write_max_lat) / 1000000)
if "avg" in line:
write_avg_lat = line.split("avg=")[1].split(",")[0].strip()
if "K" in write_avg_lat.upper():
write_avg_lat = str(float(write_avg_lat[:-1]) * 1000)
if "M" in write_avg_lat.upper():
write_avg_lat = str(float(write_avg_lat[:-1]) * 1000000)
if "usec" in line:
write_avg_lat = str(float(write_avg_lat) / 1000)
if "nsec" in line:
write_avg_lat = str(float(write_avg_lat) / 1000000)
if "clat percentiles" in line and "usec" in line:
write_clat_unit = "usec"
if "clat percentiles" in line and "nsec" in line:
write_clat_unit = "nsec"
if "99.00th" in line:
write_clat99 = line.split("99.00th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
write_clat999 = line.split("99.90th=")[1].split(",")[0].split("[")[1].split("]")[0].strip()
if "99.99th" in line:
write_clat9999 = line.split("99.99th=")[1].split("[")[1].split("]")[0].strip()
if write_clat_unit == "usec":
write_clat9999 = str(float(write_clat9999) / 1000)
write_clat999 = str(float(write_clat999) / 1000)
write_clat99 = str(float(write_clat99) / 1000)
if write_clat_unit == "nsec":
write_clat9999 = str(float(write_clat9999) / 1000000)
write_clat999 = str(float(write_clat999) / 1000000)
write_clat99 = str(float(write_clat99) / 1000000)
write_line = "filename,read,bandwidth(MB/s),iops,avg_latency(msec),p99_lat(msec),p999_lat(msec),p9999_lat(msec),max_latency(msec),write,bandwidth(MB/s),iops,avg_latency(msec),p99_lat(msec),p999_lat(msec),p9999_lat(msec),max_latency(msec)\n"
fd = open(resultfile + ".csv", "a")
if not os.path.getsize(resultfile + ".csv"):
fd.write(write_line)
fd.close()
write_line = "%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n" % (
inputfile.split("/")[-1], "read", read_bw, read_iops, read_avg_lat, read_clat99, read_clat999, read_clat9999, read_max_lat,
"write", write_bw, write_iops, write_avg_lat, write_clat99, write_clat999, write_clat9999, write_max_lat)
fd = open(resultfile + ".csv", "a")
fd.write(write_line)
fd.close()
if rwm == "mix":
mix_fio()
else:
not_mix_fio()
表格如下: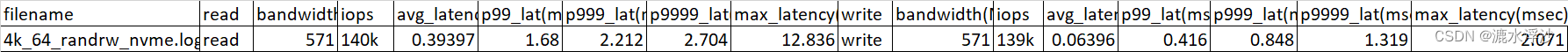
4 Python部分已经完成,接下来可以写一个shell小脚本跑下fio, 我用的是一个用dd写的大小为10G的文件来跑Fio
#!/bin/bash
for type in write read rw randwrite randread randrw;do
for bs in 4k 128k;do
for qd in 32 64 128;do
fio --name=test --filename=/home/xuetao/daili12/test --ioengine=libaio --direct=1 --thread=1 --numjobs=1 --iodepth=$qd --rw=$type --bs=$bs --size=100%>${bs}_${qd}_${type}_nvme.log
if [ "$type" == "rw" -o "$type" == "randrw" ];then
python3 fio.py ${bs}_${qd}_${type}_nvme.log mix nvme_mix_table
else
python3 fio.py ${bs}_${qd}_${type}_nvme.log $type nvme_table
fi
done
done
done
运行如下:
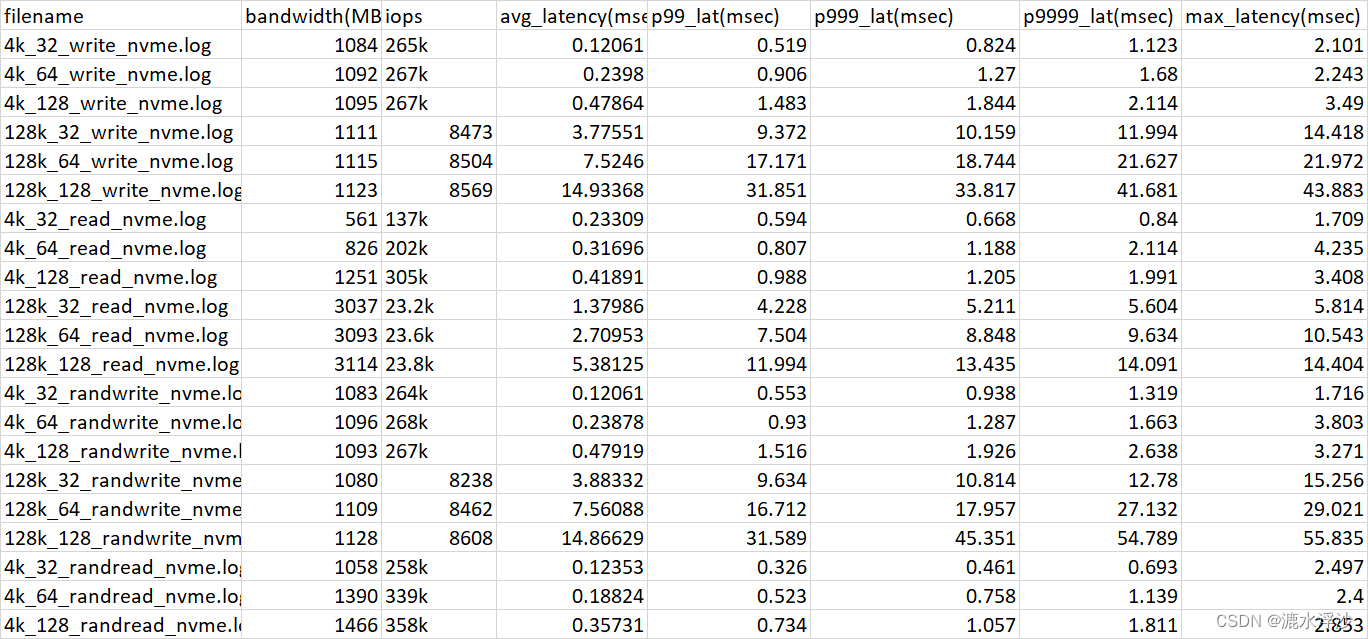
混合读写: