一、插入文档
1.1、单条插入
# 语法
db.集合名称.insert({json数据})
# 案例
db.user.insert({
"name":"张三",
"age":23,
"birthday":"1997-07-07"
})
1.2、多条插入
# insertMany语法:
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
参数说明:
document:要写入的文档。
writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
ordered:指定是否按顺序写入,默认 true,按顺序写入。
# 案例:
db.user.insertMany(
[
{
"name":"唐僧",
"age":123
},
{
"id":1,
"name":"孙悟空",
"age":500
},
]
)
===============================================
# 使用insert也可以实现多条插入
db.user.insert(
[
{
"name":"抓八戒",
"age":160
},
{
"id":2,
"name":"沙悟净",
"age":250
},
]
)
1.3、脚本方式
# 语法
for (let i = 0; i < num; i++) {
db.集合名称.insert({"_id":i+10,"name":"李白","age":20+i});
}
# 案例
for (let i = 0; i < 10; i++) {
db.user.insert({"_id":i+10,"name":"李白","age":20+i});
}
二、查询
2.1、语法
db.集合名称.find(query, projection)
参数说明:
query: 可选,使用查询操作符指定查询条件
projection: 可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
如果需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.集合名称.find().pretty()
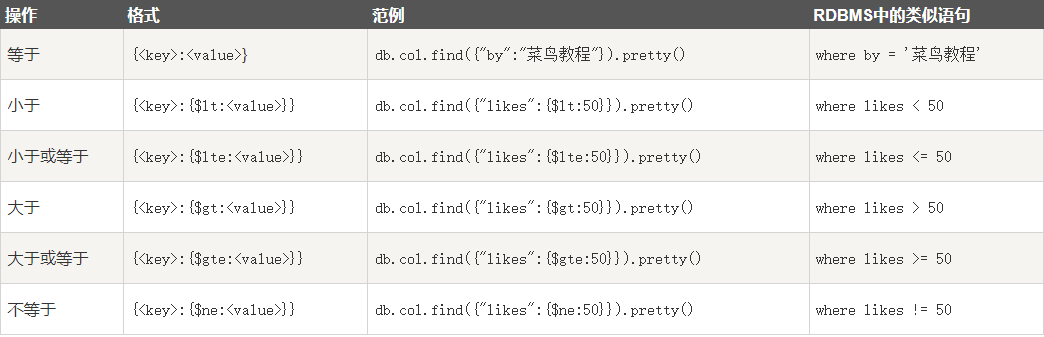
MongoDB vs RDBMS where语句比较
2.2、查询所有
# 语法:
db.集合名称.find()
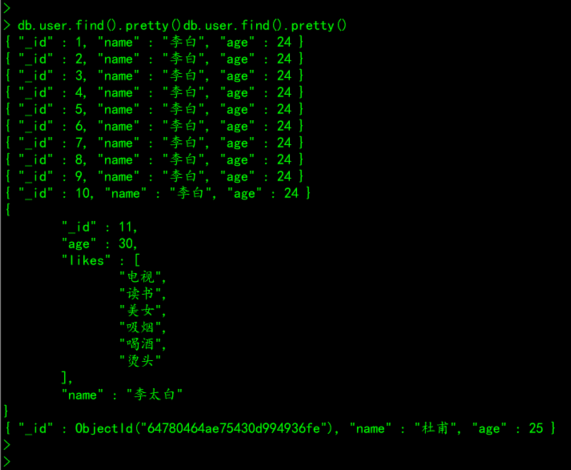
# 案例:查询user表中所有的记录
db.user.find()
db.user.find().pretty()
2.3、等值查询
# 等值查询语法
db.集合名称.find({key:value})
# 案例:查询user集合中,年龄为24的所有文档
db.user.find({age:24}).pretty()
2.4、非等值查询
2.4.1、小于查询
# 语法
db.集合名称.find({key:{$lt:value}}).pretty()
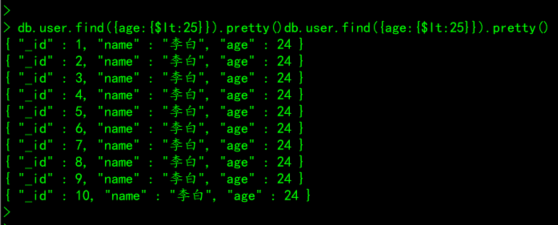
# 案例:查询user集合中,年龄小于25岁的所有文档
db.user.find({age:{$lt:25}}).pretty()
2.4.2、小于等于查询
# 小于等于
db.集合名称.find({key:{$lte:value}}).pretty()
# 案例:查询user集合中,年龄小于等于25岁的所有文档
db.user.find({age:{$lte:25}}).pretty() 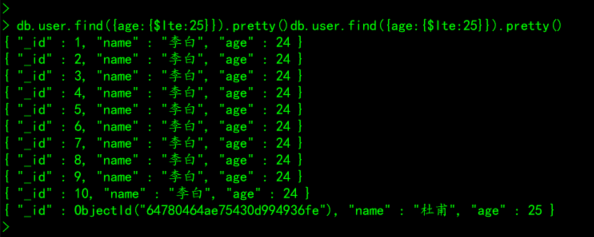
2.4.3、大于查询
# 大于
db.集合名称.find({key:{$gt:value}}).pretty()
# 案例:查询user集合中,年龄大于25岁的所有文档
db.user.find({age:{$gt:25}}).pretty()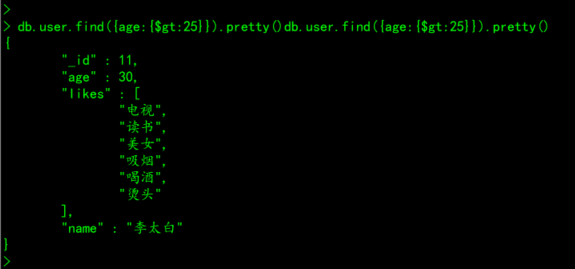
2.4.4、大于等于查询
# 大于等于
db.集合名称.find({key:{$gte:value}}).pretty()
# 案例:查询user集合中,年龄大于等于25岁的所有文档
db.user.find({age:{$gte:25}}).pretty()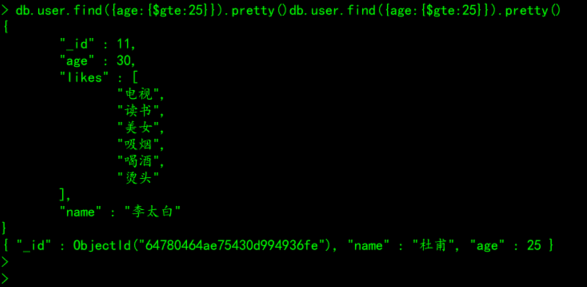
2.4.5、不等于查询
# 不等于
db.集合名称.find({key:{$ne:value}}).pretty()
# 案例:查询user集合中,年龄不等于25岁的所有文档
db.user.find({age:{$ne:25}}).pretty()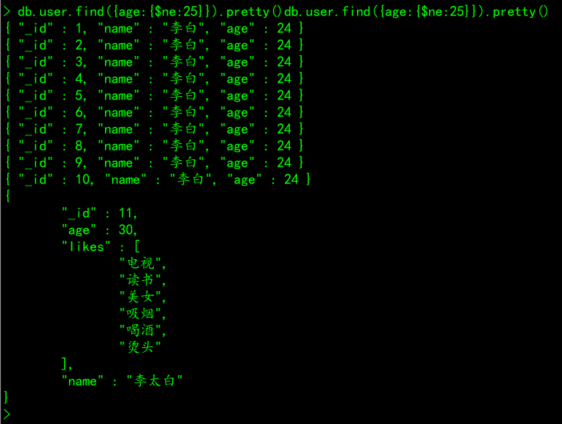
2.5、and查询
# 语法
db.集合名称.find({key1:value1,key2:value2,...}).pretty()
类似于MySQL中的 where key1 = value1 and key2 = value2# 案例:查询user集合中id为10,并且姓名为李白的文档
db.user.find({_id:10,name:"李白"}).pretty()
# 案例:查询user集合中name为李白,并且id大于5的所有文档
db.user.find({name:"李白",_id:{$gt:5}}).pretty()
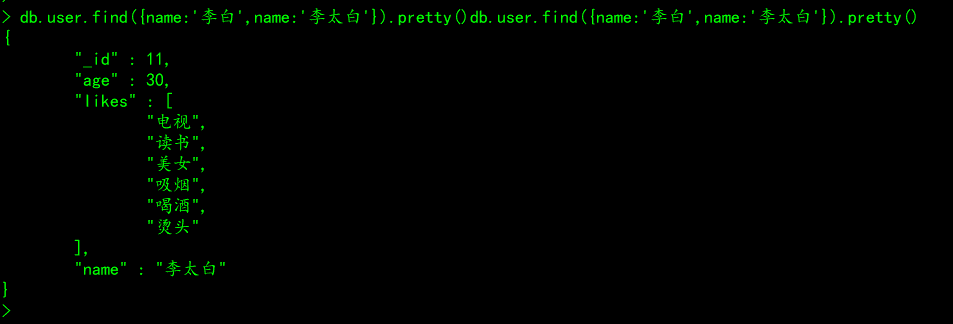
# 案例
查询user集合中name为李白,并且name为李太白的所用文档
db.user.find({name:'李白',name:'李太白'}).pretty()
注意事项:and查询时,同一个字段如果出现了多次,那么后边的将会把前边的条件覆盖掉
2.6、or查询
# 语法
db.集合名称.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()# 案例:查询id为1或者name为李太白的所有文档信息
db.user.find({$or:[{_id:1},{name:'李太白'}]}).pretty()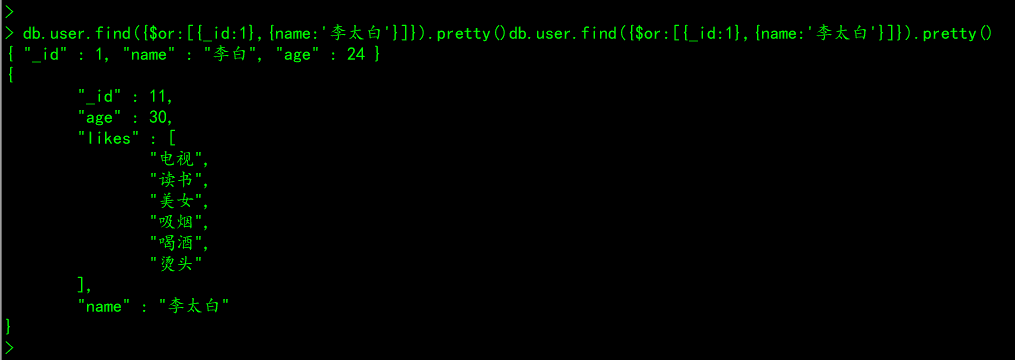
# 案例二:查询user集合中id为1,或者年龄大于24的所有文档集合
db.user.find({$or:[{_id:1},{age:{$gt:24}}]}).pretty()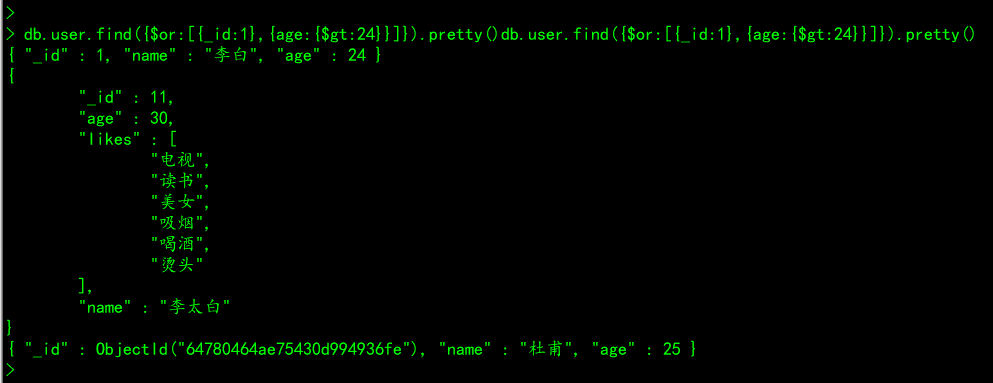
2.7、and和or联合查询
# 语法
db.集合名称.find({key1:value1,$or:[{key2:value2},{key3:value3}]}).pretty()
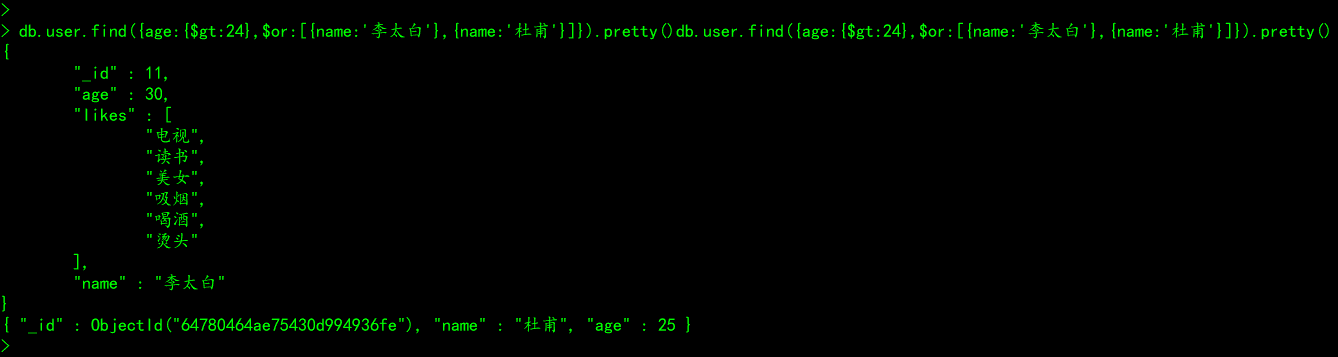
类似于MySQL中的 where age > 50 and (name = '李白' or name = '杜甫')# 案例:查询user集合中age大于24,并且name为李太白或者name为杜甫的所有文档列表
db.user.find({age:{$gt:24},$or:[{name:'李太白'},{name:'杜甫'}]}).pretty()
2.8、数组查询
# 语法
db.集合名称.find({数组名:value}).pretty()# 案例:查询user集合中,兴趣爱好为"读书"的文档记录
db.user.find({likes:'读书'}).pretty()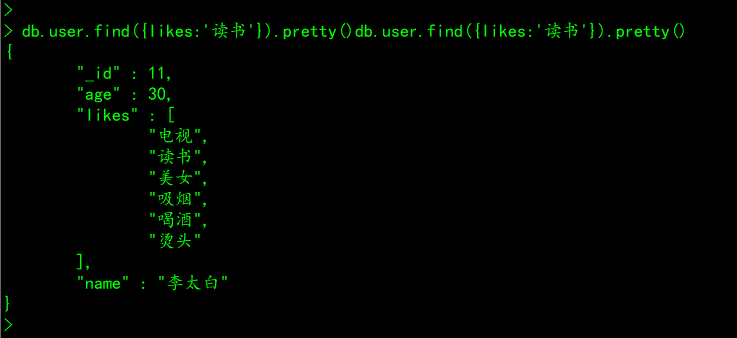
# 案例:查询user集合中,喜好为6的文档列表
db.user.find({likes:{$size:6}}).pretty()
db.user.find({likes:{$size:2}}).pretty() 
2.9、模糊查询
# 语法:
db.集合名称.find({key:/value/}).pretty()
# 注意事项
在MongoDB中使用正则表达式,可以实现近似于模糊查询的功能
# 案例一、查询user集合中name字段中包含 白 的所有文档信息
db.user.find({name:/白/}).pretty()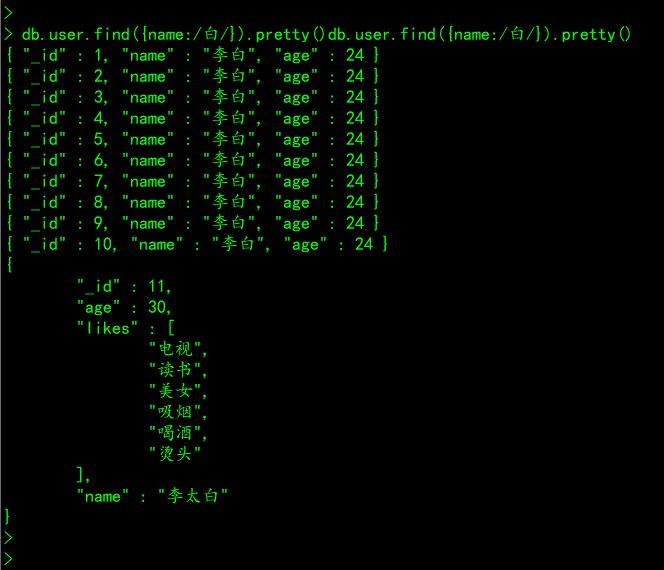
2.10、排序查询
# 语法
db.集合名称.find().sort({key1:1,key2:-1,...}).pretty()
说明:
1:升序,类似于MySQL中的asc
-1:降序,类似于MySQL中的desc# 案例:查询user集合中的所有文档,按照id降序排序
db.user.find().sort({_id:-1}).pretty()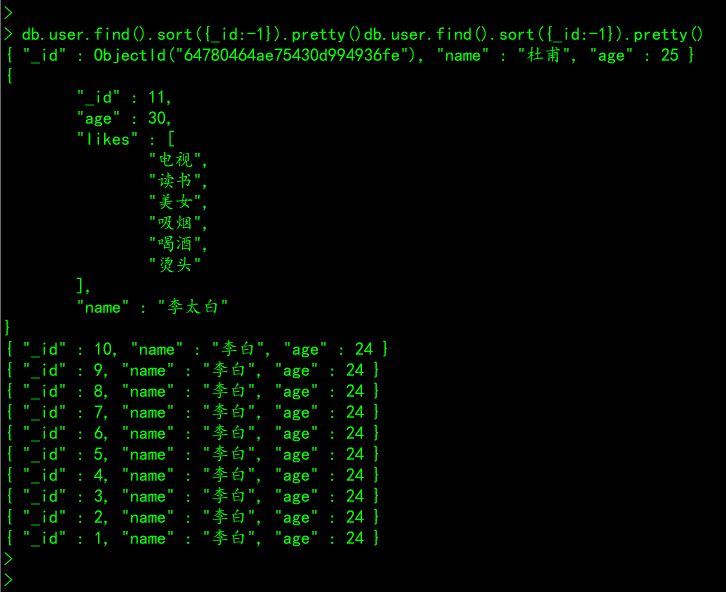
2.11、分页查询
# 语法
db.集合名称.find().skip(跳过的记录数).limit(size)
类似于SQL语句:limit start,rows
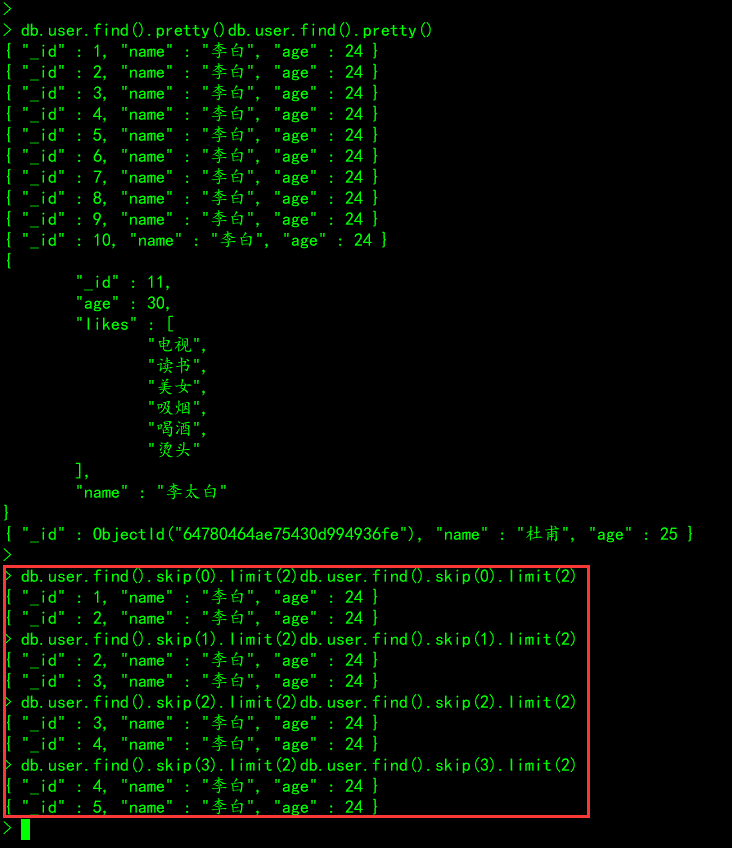
# 案例1:查询user集合中的前2条记录
db.user.find().skip(0).limit(2)
# 案例2:查询user集合中的第3、4条记录
db.user.find().skip(2).limit(2)
2.12、总条数查询
# 语法
db.集合名称.count();
db.集合名称.find({key:value}).count();
类似于SQL语句:select count(id) from ...
# 初始化SQL脚本
for (let i = 1; i <= 100000; i++) {
db.orders.insert({
_id: i,
name: 'order_' + i
});
}
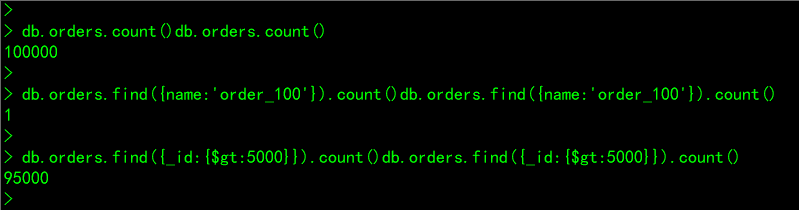
# 案例一:查询orders集合中共有多少条记录
db.orders.count()
# 案例二:查询orders集合中,name为order_100的文档共有多少个
db.orders.find({name:'order_100'}).count()
# 案例三:查询orders集合中,id大于5000的文档共有多少个
db.orders.find({_id:{$gt:5000}}).count()
2.13、去重查询
# 语法
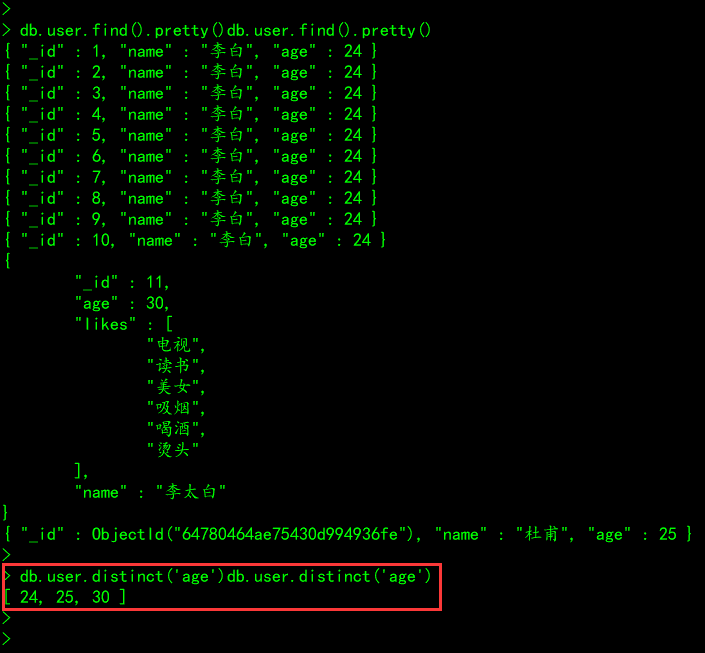
db.集合名称.distinct('字段')
# 案例
user集合中按照age去重查询
2.14、返回指定字段
# 语法
db.集合名称.find({条件},{name:1,age:1})
参数2: 1返回、0不返回 注意:1和0不能同时使用# 案例一:查询所有
db.user.find({},{})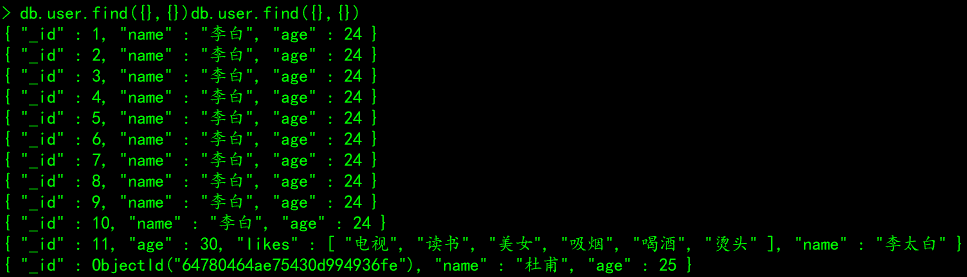
# 案例二:返回name字段,注意默认情况下,_id是唯一标识,会自动返回
db.user.find({},{name:1})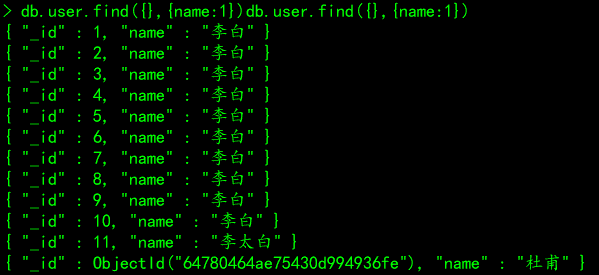
# 案例三:_id不要返回,其他字段都返回
db.user.find({},{_id:0}) 
# 案例四:_id和age不要返回,其他字段都返回
db.user.find({},{_id:0,age:0})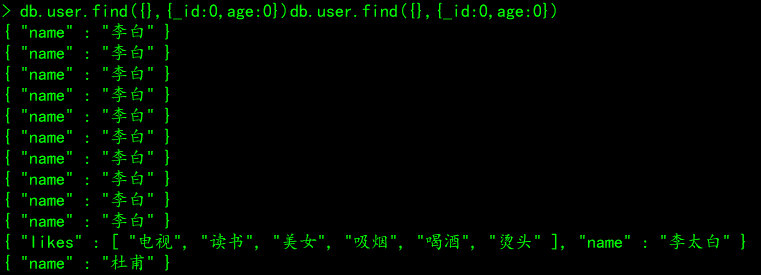
# 案例五、_id不返回,name返回
db.user.find({},{_id:0,name:1}) 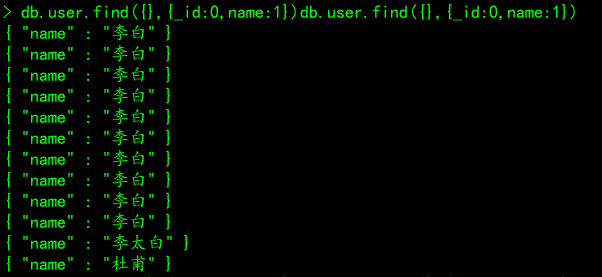
# 案例六(错误演示):name返回,age不返回
db.user.find({},{age:0,name:1}) 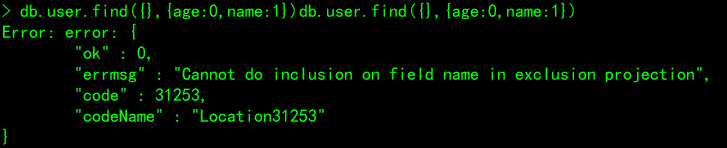
三、删除
3.1、删除所有
# 语法
db.集合名称.remove({})
# 案例:删除user集合中所有的文档
db.user.remove({})3.2、按条件删除
# 语法(适用于MongoDB2.6以后的版本)
db.集合名称.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
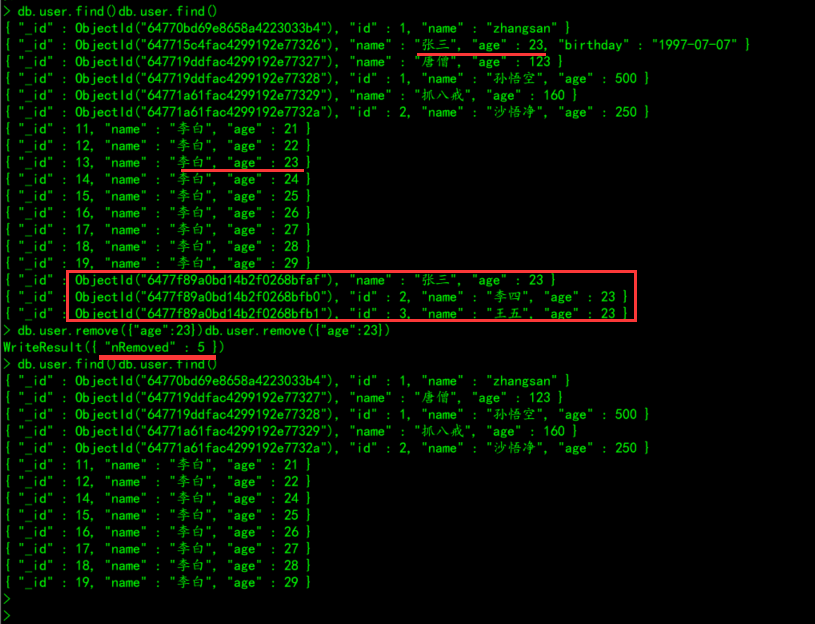
writeConcern :(可选)抛出异常的级别。3.2.1、根据id删除文档
# 案例:删除user集合中id为10的文档(这里的id是创建文档时指定的id)
db.user.remove({"_id":10})
![]()
# 案例:删除user集合中id为 ObjectId("64770bd69e8658a4223033b4")的文档,说明:此id为Mongo自动生成的id
db.user.remove({"_id":"64770bd69e8658a4223033b4"})

3.2.2、根据字段名称删除所有符合条件的文档
# 往user集合中出入age相同的三条数据进行测试
db.user.insert(
[
{
"name":"张三",
"age":23
},
{
"_id":2,
"name":"李四",
"age":23
},
{
"_id":3,
"name":"王五",
"age":23
}
]
)
# 删除age为23的文档记录
db.user.remove({"age":23})
四、更新文档
4.1、update更新
# 语法
db.集合名称.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。4.1.1、数据初始化
# 数据初始化
1、清空user集合中所有的数据
db.user.remove({})
2、数据初始化
for (let i = 0; i < 10; i++) {
db.user.insert({"_id":i+1,"name":"李白","age":20+i});
}
db.user.insert({"_id":11,"name":"李太白","age":35})
3、当前user集合中的文档结构
db.user.find()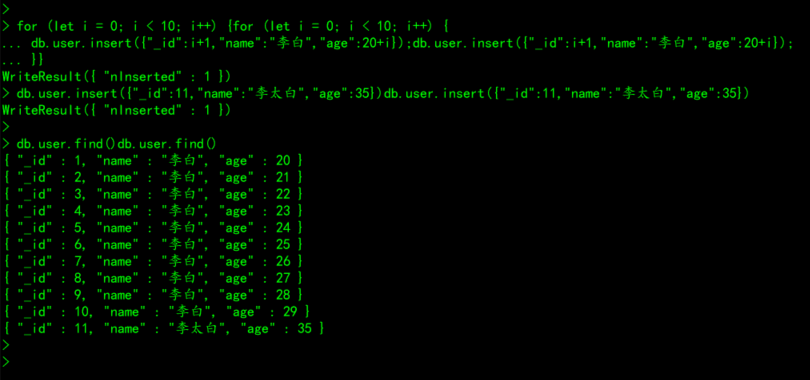
4.1.2、将id为11的文档,age修改为30
db.user.update({"_id":11},{"age":30}) 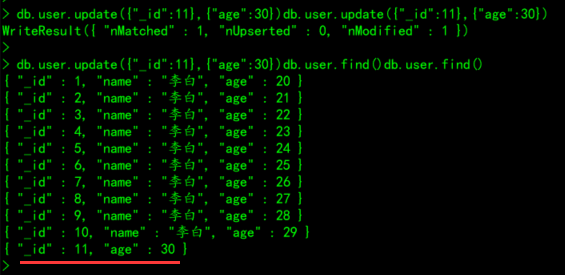
4.1.3、保留原始更新
# 案例
db.user.update({"_id":11},{$set:{"name":"李太白","age":30,"likes":["电视","读书","美女"]}})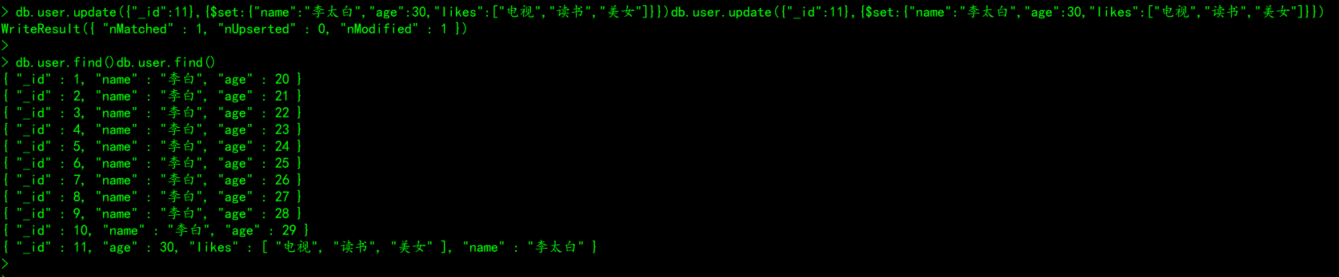
# 案例
db.user.update({"_id":11},{$set:{"likes":["电视","读书","美女","吸烟","喝酒","烫头"]}})
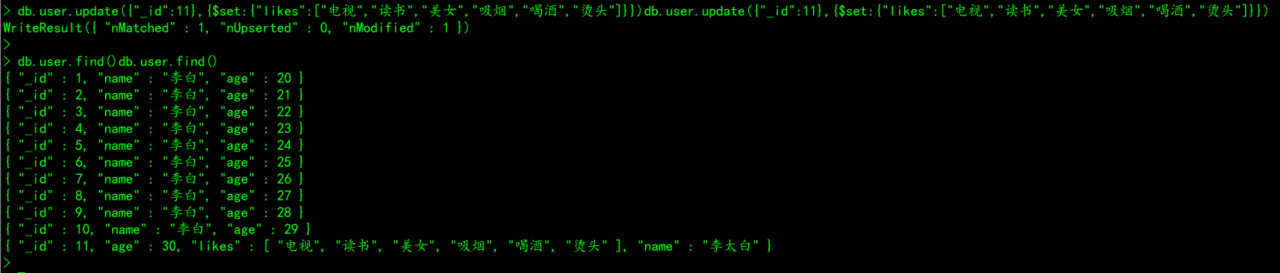
4.1.4、批量更新(保留原始更新&更新条件存在)
# 批量将name为李白的文档,年龄统一修改为24
db.user.update({"name":"李白"},{$set:{"age":24}},{multi:true})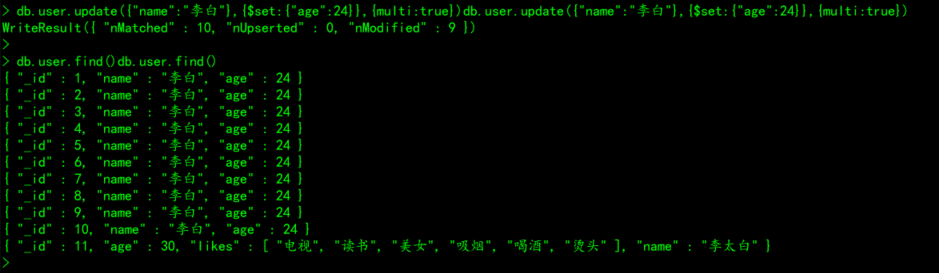
4.1.5、批量更新(保留原始更新&更新条件不存在,upsert为默认值)
# 批量更新name为杜甫的文档,将年龄统一修改为25
db.user.update({"name":"杜甫"},{$set:{"age":25}},{multi:true})
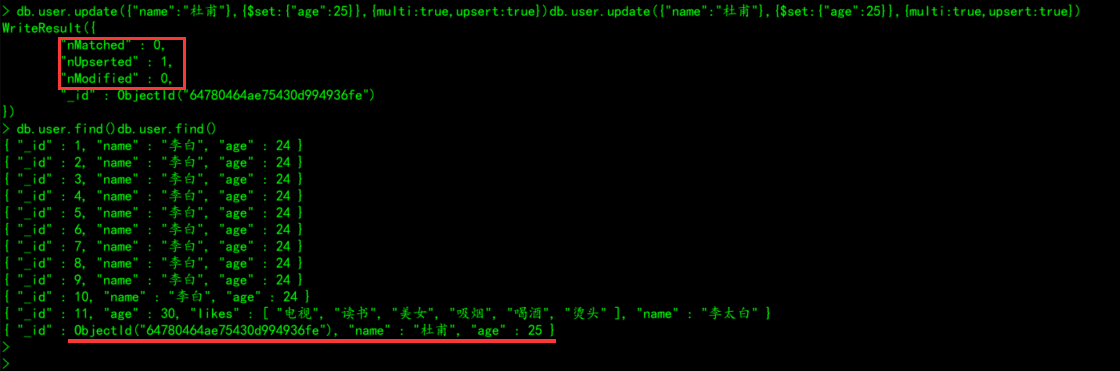
4.1.6、批量更新(保留原始更新&更新条件不存在,upsert为true)
# 批量更新name为杜甫的文档,将年龄统一修改为25
db.user.update({"name":"杜甫"},{$set:{"age":25}},{multi:true,upsert:true})
说明:upsert设置为true,当匹配不到文档时,将会插入一条新文档