-------------------------------------------Docker 的数据管理--------------------------------------------
管理 Docker 容器中数据主要有两种方式:数据卷(Data Volumes)和数据卷容器(DataVolumes Containers)。
1.数据卷
数据卷是一个供容器使用的特殊目录,位于容器中。可将宿主机的目录挂载到数据卷上,对数据卷的修改操作立刻可见,并且更新数据不会影响镜像,从而实现数据在宿主机与容器之间的迁移。数据卷的使用类似于 Linux 下对目录进行的 mount 操作。
docker pull centos:7
#宿主机目录/var/www 挂载到容器中的/data1。
注意:宿主机本地目录的路径必须是使用绝对路径。如果路径不存在,Docker会自动创建相应的路径。
docker run -v /var/www:/data1 --name web1 -it centos:7 /bin/bash #-v 选项可以在容器内创建数据卷
ls
echo "this is web1" > /data1/abc.txt
exit
#返回宿主机进行查看
cat /var/www/abc.txt
2.数据卷容器
如果需要在容器之间共享一些数据,最简单的方法就是使用数据卷容器。数据卷容器是一个普通的容器,专门提供数据卷给其他容器挂载使用。
#创建一个容器作为数据卷容器
docker run --name web2 -v /data1 -v /data2 -it centos:7 /bin/bash
echo "this is web2" > /data1/abc.txt
echo "THIS IS WEB2" > /data2/ABC.txt
#使用 --volumes-from 来挂载 web2 容器中的数据卷到新的容器
docker run -it --volumes-from web2 --name web3 centos:7 /bin/bash
cat /data1/abc.txt
cat /data2/ABC.txt
-------------------------------------------------端口映射-----------------------------------------------------
在启动容器的时候,如果不指定对应的端口,在容器外是无法通过网络来访问容器内的服务。端口映射机制将容器内的服务提供给外部网络访问,实质上就是将宿主机的端口映射到容器中,使得外部网络访问宿主机的端口便可访问容器内的服务。
docker run -d --name test1 -P nginx #随机映射端口(从32768开始)
docker run -d --name test2 -p 43000:80 nginx #指定映射端口
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9d3c04f57a68 nginx "/docker-entrypoint.…" 4 seconds ago Up 3 seconds 0.0.0.0:43000->80/tcp test2
b04895f870e5 nginx "/docker-entrypoint.…" 17 seconds ago Up 15 seconds 0.0.0.0:49170->80/tcp test1
浏览器访问:http://192.168.80.10:43000 、http://192.168.80.10:49170
------------------容器互联(使用centos镜像)---------------------------------
容器互联是通过容器的名称在容器间建立一条专门的网络通信隧道。简单点说,就是会在源容器和接收容器之间建立一条隧道,接收容器可以看到源容器指定的信息。
#创建并运行源容器取名web1
docker run -itd -P --name web1 centos:7 /bin/bash
#创建并运行接收容器取名web2,使用--link选项指定连接容器以实现容器互联
docker run -itd -P --name web2 --link web1:web1 centos:7 /bin/bash #--link 容器名:连接的别名
#进web2 容器, ping web1
docker exec -it web2 bash
ping web1
-----------------------------------------Docker 镜像的创建--------------------------------------------
创建镜像有三种方法,分别为基于已有镜像创建、基于本地模板创建以及基于Dockerfile创建。
1.基于现有镜像创建
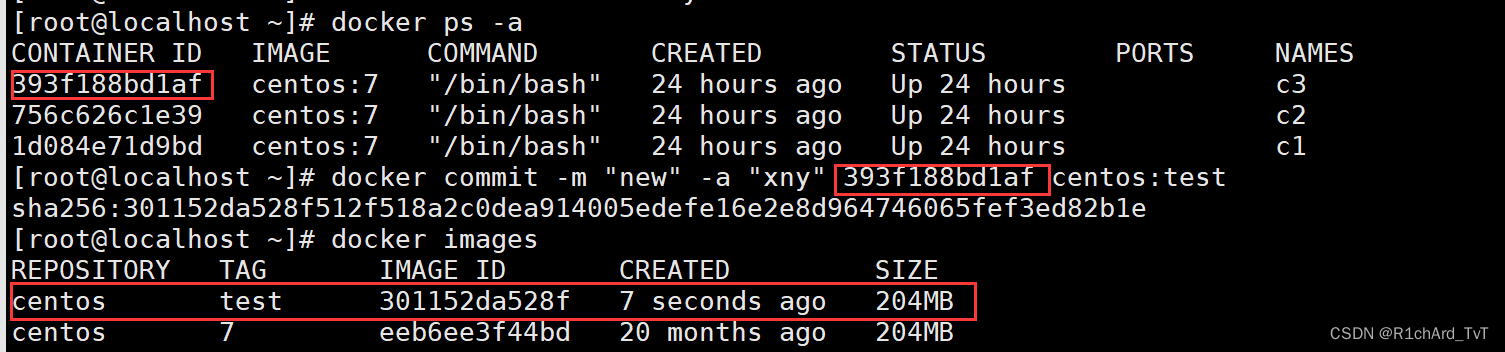
(1)首先启动一个镜像,在容器里做修改
docker create -it centos:7 /bin/bash
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
000550eb36da centos:7 "/bin/bash" 3 seconds ago Created gracious_bassi
(2)然后将修改后的容器提交为新的镜像,需要使用该容器的 ID 号创建新镜像
docker commit -m "new" -a "centos" 000550eb36da centos:test
#常用选项:
-m 说明信息;
-a 作者信息;
-p 生成过程中停止容器的运行。
docker images

2.基于本地模板创建
通过导入操作系统模板文件可以生成镜像,模板可以从 OPENVZ 开源项目下载,下载地址为http://openvz.org/Download/template/precreated
wget http://download.openvz.org/template/precreated/debian-7.0-x86-minimal.tar.gz
#导入为镜像
cat debian-7.0-x86-minimal.tar.gz | docker import - debian:test
3.基于Dockerfile 创建
//联合文件系统(UnionFS)
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。AUFS、OverlayFS 及 Devicemapper 都是一种 UnionFS。
Union文件系统是Docker镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。
我们下载的时候看到的一层层的就是联合文件系统。
//镜像加载原理
Docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统就是UnionFS。
bootfs主要包含bootloader和kernel,bootloader主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统。
在Docker镜像的最底层是bootfs,这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs,在bootfs之上。包含的就是典型Linux系统中的/dev,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
我们可以理解成一开始内核里什么都没有,操作一个命令下载debian,这时就会在内核上面加了一层基础镜像;再安装一个emacs,会在基础镜像上叠加一层image;接着再安装一个apache,又会在images上面再叠加一层image。最后它们看起来就像一个文件系统即容器的rootfs。在Docker的体系里把这些rootfs叫做Docker的镜像。但是,此时的每一层rootfs都是read-only的,我们此时还不能对其进行操作。当我们创建一个容器,也就是将Docker镜像进行实例化,系统会在一层或是多层read-only的rootfs之上分配一层空的read-write的rootfs。
//为什么Docker里的centos的大小才200M?
因为对于精简的OS,rootfs可以很小,只需要包含最基本的命令、工具和程序库就可以了,因为底层直接用宿主机的kernel,自己只需要提供rootfs就可以了。由此可见对于不同的linux发行版,bootfs基本是一致的,rootfs会有差别,因此不同的发行版可以公用bootfs。
//Dockerfile
Docker镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。
镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
Dockerfile是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。有了Dockerfile,当我们需要定制自己额外的需求时,只需在Dockerfile上添加或者修改指令,重新生成 image 即可, 省去了敲命令的麻烦。
除了手动生成Docker镜像之外,可以使用Dockerfile自动生成镜像。Dockerfile是由多条的指令组成的文件,其中每条指令对应 Linux 中的一条命令,Docker 程序将读取Dockerfile 中的指令生成指定镜像。
Dockerfile结构大致分为四个部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令。Dockerfile每行支持一条指令,每条指令可携带多个参数,支持使用以“#“号开头的注释。
#Docker 镜像结构的分层
镜像不是一个单一的文件,而是有多层构成。容器其实是在镜像的最上面加了一层读写层,在运行容器里做的任何文件改动,都会写到这个读写层。如果删除了容器,也就删除了其最上面的读写层,文件改动也就丢失了。Docker使用存储驱动管理镜像每层内容及可读写层的容器层。
(1)Dockerfile 中的每个指令都会创建一个新的镜像层;
(2)镜像层将被缓存和复用;
(3)当Dockerfile 的指令修改了,复制的文件变化了,或者构建镜像时指定的变量不同了,对应的镜像层缓存就会失效;
(4)某一层的镜像缓存失效,它之后的镜像层缓存都会失效;
(5)镜像层是不可变的,如果在某一层中添加一个文件,然后在下一层中删除它,则镜像中依然会包含该文件,只是这个文件在 Docker 容器中不可见了。
#Dockerfile 操作常用的指令:
(1)FROM 镜像
指定新镜像所基于的基础镜像,第一条指令必须为FROM 指令,每创建一个镜像就需要一条 FROM 指令
(2)MAINTAINER 名字
说明新镜像的维护人信息
(3)RUN 命令
在所基于的镜像上执行命令,并提交到新的镜像中
(4)ENTRYPOINT ["要运行的程序", "参数 1", "参数 2"]
设定容器启动时第一个运行的命令及其参数。
可以通过使用命令docker run --entrypoint 来覆盖镜像中的ENTRYPOINT指令的内容。
(5)CMD ["要运行的程序", "参数1", "参数2"]
上面的是exec形式,shell形式:CMD 命令 参数1 参数2
启动容器时默认执行的命令或者脚本,Dockerfile只能有一条CMD命令。如果指定多条命令,只执行最后一条命令。
如果在docker run时指定了命令或者镜像中有ENTRYPOINT,那么CMD就会被覆盖。
CMD 可以为 ENTRYPOINT 指令提供默认参数。
java -jar xxxxxxx.jar
(6)EXPOSE 端口号
指定新镜像加载到 Docker 时要开启的端口
(7)ENV 环境变量 变量值
设置一个环境变量的值,会被后面的 RUN 使用
linxu PATH=$PATH:/opt
ENV PATH $PATH:/opt
(8)ADD 源文件/目录 目标文件/目录
将源文件复制到镜像中,源文件要与 Dockerfile 位于相同目录中,或者是一个 URL
有如下注意事项:
1、如果源路径是个文件,且目标路径是以 / 结尾, 则docker会把目标路径当作一个目录,会把源文件拷贝到该目录下。
如果目标路径不存在,则会自动创建目标路径。
2、如果源路径是个文件,且目标路径是不以 / 结尾,则docker会把目标路径当作一个文件。
如果目标路径不存在,会以目标路径为名创建一个文件,内容同源文件;
如果目标文件是个存在的文件,会用源文件覆盖它,当然只是内容覆盖,文件名还是目标文件名。
如果目标文件实际是个存在的目录,则会源文件拷贝到该目录下。 注意,这种情况下,最好显示的以 / 结尾,以避免混淆。
3、如果源路径是个目录,且目标路径不存在,则docker会自动以目标路径创建一个目录,把源路径目录下的文件拷贝进来。
如果目标路径是个已经存在的目录,则docker会把源路径目录下的文件拷贝到该目录下。
4、如果源文件是个归档文件(压缩文件),则docker会自动帮解压。
URL下载和解压特性不能一起使用。任何压缩文件通过URL拷贝,都不会自动解压。
(9)COPY 源文件/目录 目标文件/目录
只复制本地主机上的文件/目录复制到目标地点,源文件/目录要与Dockerfile 在相同的目录中
(10)VOLUME [“目录”]
在容器中创建一个挂载点
(11)USER 用户名/UID
指定运行容器时的用户
(12)WORKDIR 路径
为后续的 RUN、CMD、ENTRYPOINT 指定工作目录
(13)ONBUILD 命令
指定所生成的镜像作为一个基础镜像时所要运行的命令。
当在一个Dockerfile文件中加上ONBUILD指令,该指令对利用该Dockerfile构建镜像(比如为A镜像)不会产生实质性影响。
但是当编写一个新的Dockerfile文件来基于A镜像构建一个镜像(比如为B镜像)时,这时构造A镜像的Dockerfile文件中的ONBUILD指令就生效了,在构建B镜像的过程中,首先会执行ONBUILD指令指定的指令,然后才会执行其它指令。
注:请各位自己在生产中如果有的是别的dockerfile 请自习阅读,否则后果自付
(14)HEALTHCHECK
健康检查
在编写 Dockerfile 时,有严格的格式需要遵循:
●第一行必须使用 FROM 指令指明所基于的镜像名称;
●之后使用 MAINTAINER 指令说明维护该镜像的用户信息;
●然后是镜像操作相关指令,如 RUN 指令。每运行一条指令,都会给基础镜像添加新的一层。
●最后使用 CMD 指令指定启动容器时要运行的命令操作。
--------Dockerfile 案例--------
#建立工作目录
mkdir /opt/apache
cd /opt/apache
vim Dockerfile
#基于的基础镜像
FROM centos:7
#维护镜像的用户信息
MAINTAINER this is apache image <hmj>
#镜像操作指令安装apache软件
RUN yum -y update
RUN yum -y install httpd
#开启 80 端口
EXPOSE 80
#复制网站首页文件
ADD index.html /var/www/html/index.html
//方法一:
#将执行脚本复制到镜像中
ADD run.sh /run.sh
RUN chmod 755 /run.sh
#启动容器时执行脚本
CMD ["/run.sh"]
//方法二:
ENTRYPOINT [ "/usr/sbin/apachectl" ]
CMD ["-D", "FOREGROUND"]
//准备执行脚本
vim run.sh
#!/bin/bash
rm -rf /run/httpd/* #清理httpd的缓存
/usr/sbin/apachectl -D FOREGROUND #指定为前台运行
#因为Docker容器仅在它的1号进程(PID为1)运行时,会保持运行。如果1号进程退出了,Docker容器也就退出了。//准备网站页面
echo "this is test web" > index.html
//生成镜像
docker build -t httpd:centos . #注意别忘了末尾有"."
//新镜像运行容器
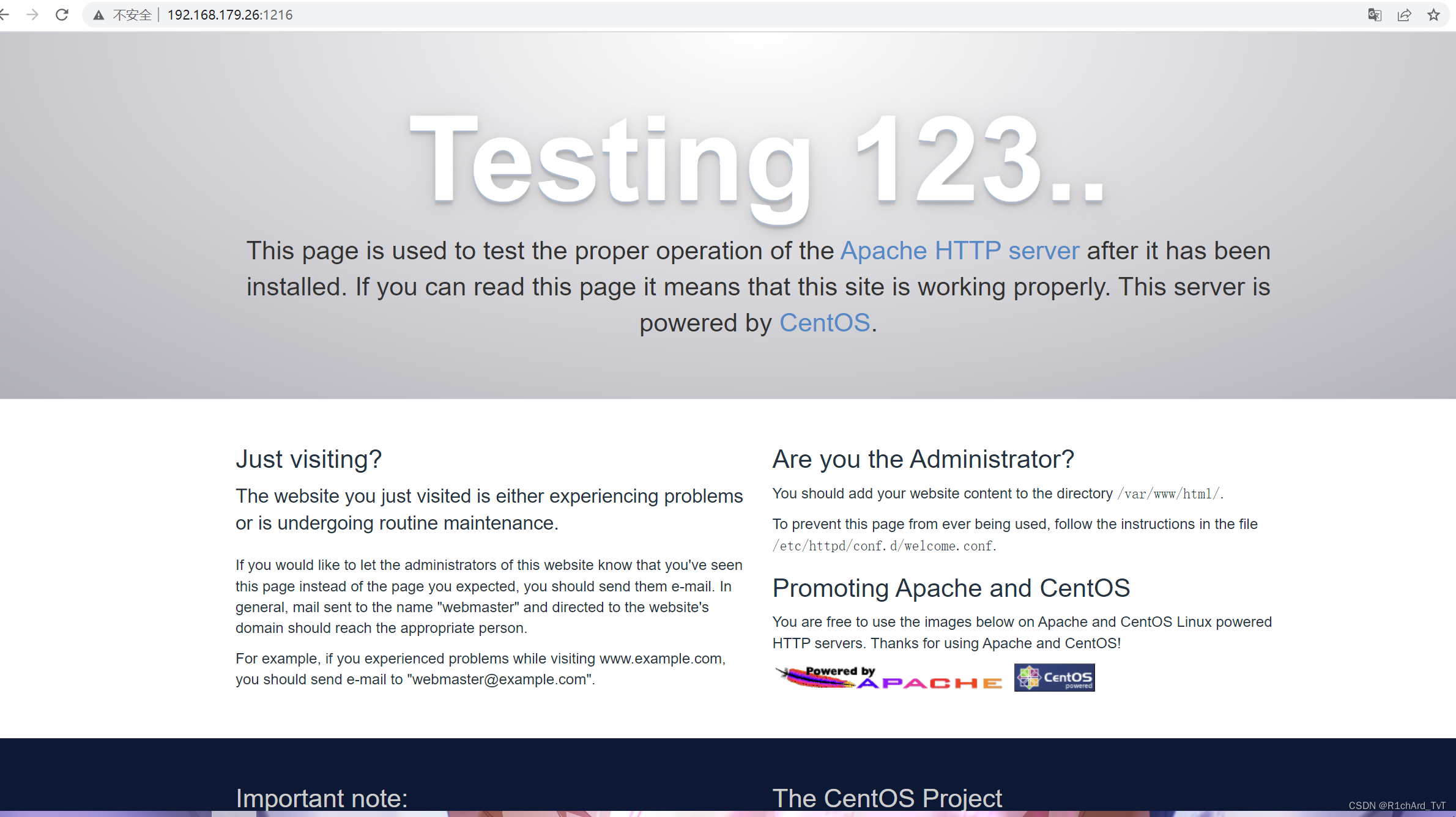
docker run -d -p 1216:80 httpd:centos

//测试
http://192.168.179.26:1216/
########如果有网络报错提示########
[Warning] IPv4 forwarding is disabled. Networking will not work.
解决方法:
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
sysctl -p
systemctl restart network
systemctl restart docker