参考书籍:《Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition (Aurelien Geron [Géron, Aurélien])》
代码有修改,已测通。
简单顺序结构
这次得数据集比之前得简单,只包含数字型特征,没有ocean_proximity,也没有缺失值。
如果 sklearn.datasets.fetch_california_housing 报错 urllib.error.HTTPError: HTTP Error 403: Forbidden,那么下载文件cal_housing_py3.pkz放到 sklearn.datasets.get_data_home()下,这里是 C:\Users\用户名\scikit_learn_data
参考:https://blog.csdn.net/qq_44644355/article/details/107054585
from sklearn.datasets import fetch_california_housing, get_data_home
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def load_housing_data():
housing = fetch_california_housing()
# 默认划分是3:1,aka 75%train, 25%test
X_train_full, X_test, y_train_full, y_test = train_test_split(
housing.data, housing.target)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_full, y_train_full)
scaler = StandardScaler()
# fit_transform会计算数据的均值和方差,transform不会
# 而且前者一般只在训练集进行,后者则是在训练集和测试集都可以用
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
return X_train, X_valid, X_test, y_train, y_valid, y_test
#print(get_data_home())
X_train, X_valid, X_test, y_train, y_valid, y_test = load_housing_data()
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1)
])
model.compile(loss="mean_squared_error", optimizer="sgd")
history = model.fit(X_train, y_train, epochs=30, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
print(mse_test)
X_new = X_test[:3]
y_pred = model.predict(X_new)
print(y_pred)
复杂结构
单输入
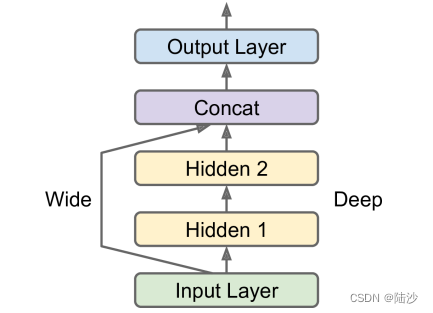
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate(inputs=[input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.Model(inputs=[input_], outputs=[output])
#model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
多输入
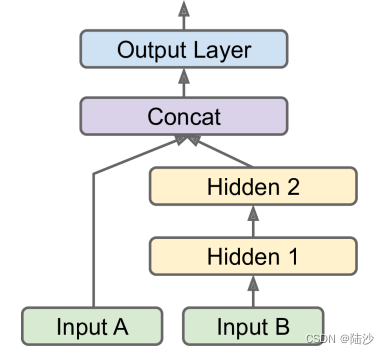
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="output")(concat)
model = keras.Model(inputs=[input_A, input_B], outputs=[output])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
# 划分数据。0-4是输入wide_input的,2-最后是输入deep_input的
X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:]
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:]
X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:]
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3]
# 训练
history = model.fit((X_train_A, X_train_B), y_train, epochs=30,
validation_data=((X_valid_A, X_valid_B), y_valid))
mse_test = model.evaluate((X_test_A, X_test_B), y_test)
print(mse_test)
y_pred = model.predict((X_new_A, X_new_B))
print(y_pred)
如果需要增加一个输出,如下图所示,可以这样改:
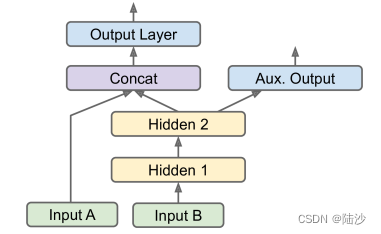
# 其他保持不变
aux_output = keras.layers.Dense(1, name="aux_output")(hidden2)
model = keras.Model(inputs=[input_A, input_B], outputs=[output, aux_output])
model.compile(loss=["mse","mse"], loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(lr=1e-3))
# 假设aux_output预测的也是同样的东西
history = model.fit([X_train_A, X_train_B], [y_train, y_train], epochs=30,
validation_data=([X_valid_A, X_valid_B], [y_valid, y_valid]))
# 此时有总loss和每个输出的loss
total_loss, main_loss, aux_loss = model.evaluate([X_test_A, X_test_B], [y_test, y_test])
print((total_loss, main_loss, aux_loss))
# 预测结果也会有多个
y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])
print((y_pred_main, y_pred_aux))
如果需要动态调整网络,比如在某些情况下需要进入循环或者分支,那可以写一个新的类,如下面所示。这样的好处是网络组织更加灵活,而且summary()只能打印层的列表,不能传递层之间的连接方式;缺点是不能clone或者保存(不能用hdf5格式,只能save_weights和load_weights勉强保存一下),有时候也可能出错。
class WideAndDeepModel(keras.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs) # handles standard args (e.g., name)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
# 这里可以写loop if什么的
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel()
保存模型可以用pickle或者joblib的dump,也可以直接:
model.save("xxx.h5")
这里使用HDF5格式保存架构、超参数和每层的参数,也会保存optimizer。等再载入到时候可以用:
model = keras.models.load_model("xxx.h5")
有时候需要早点停止,可以加Callbacks。比如ModelCheckpoint就保存了某些时间点模型的checkpoints。默认是每个epoch结束时。
# build and compile the model
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5", save_best_only=True)
history = model.fit(X_train, y_train, epochs=10,
alidation_data=(X_valid, y_valid), callbacks=[checkpoint_cb])
model = keras.models.load_model("my_keras_model.h5") # roll back to best model
此时model只保存了最好的模型。
另外,也可以使用EarlyStopping,指如果在验证集上,若干个(patience参数)epoch没有进步了,就停止训练。也可以同时使用checkpoints和earlystopping。
early_stopping_cb = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100, validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, early_stopping_cb])
也可以写自定义的callbacks。可以选的时间点有:on_train_begin(), on_train_end(), on_epoch_begin(), on_epoch_end(), on_batch_begin(), and on_batch_end()。还可以在test和predict种插入callbacks,前者是evaluate()调用的,后者是predict()调用的。
class PrintValTrainRatioCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
print("\nval/train: {:.2f}".format(logs["val_loss"] / logs["loss"]))