priority_queue模拟
首先查看源代码,源代码就在queue剩下的部分中
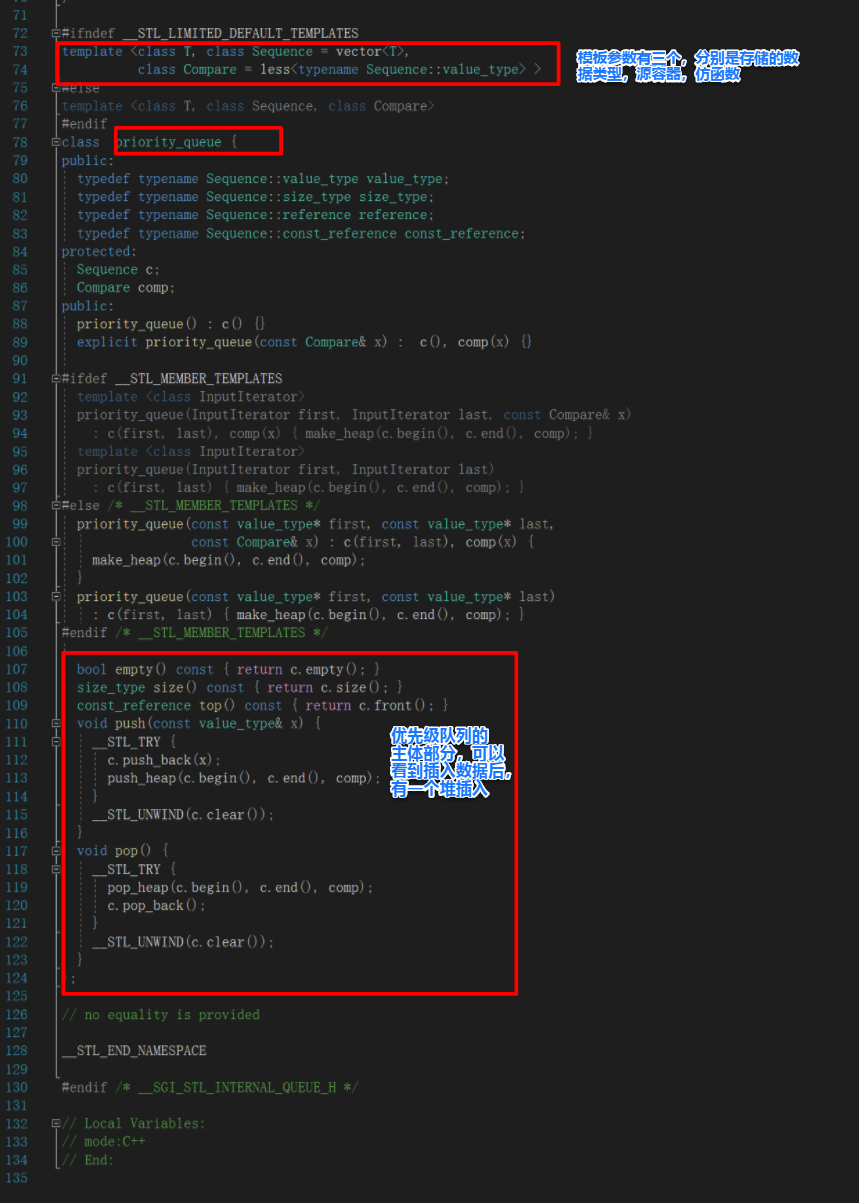
push_heap是STL库中的堆算法,STL库中包装有支持堆的算法,在algorithm.h中:

只要不断用堆的形式插入数据,就会形成堆。
priority_queue模拟——初版
priority_queue.h中
#pragma once
#include<iostream>
#include<vector>
#include<assert.h>
using namespace std;
template<class T, class container = vector<int>>
class myPriority_queue
{
public:
void adjustUp(int lea)
//向上调整算法,在插入数据后,将数据重新调整为堆时使用,lea为尾节点下标
{
if (lea == 0)
return;
size_t fa = (lea - 1) / 2;
while (_con[fa] < _con[lea])
{
swap(_con[fa], _con[lea]);
lea = fa;
fa = (lea - 1) / 2;
}
}
void adjustDown()
//向下调整算法,在删除数据后,使空间重新调整为堆时使用,从根节点开始调整,不需要传入数据
{
size_t ch = 1;
//代表子节点
size_t fa = 0;
//代表父节点
while (ch < _con.size() && _con[fa] < _con[ch])
{
if (ch + 1 < _con.size() && _con[ch] < _con[ch + 1])
//开始默认左子节点大
ch++;
swap(_con[fa], _con[ch]);
fa = ch;
ch = fa * 2 + 1;
}
}
void push(const T& x)
{
_con.push_back(x);
int lea = _con.size() - 1;
adjustUp(lea);
}
void pop()
{
assert(!_con.empty());
size_t tail = _con.size() - 1;
swap(_con[0], _con[tail]);
_con.pop_back();
adjustDown();
}
const T& top()
{
return _con[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
container _con;
};
test.cpp中
#define _CRT_SECURE_NO_WARNINGS 1
#include"priority_queue.h"
#include<iostream>
#include<vector>
using namespace std;
void test_priority_queue()
{
myPriority_queue<int> pri_qu;
pri_qu.push(8);
pri_qu.push(2);
pri_qu.push(5);
pri_qu.push(1);
pri_qu.push(4);
pri_qu.push(3);
cout << pri_qu.empty() << " " << pri_qu.size() << endl;
while(!pri_qu.empty())
{
cout << pri_qu.top() << " ";
pri_qu.pop();
}
cout << endl;
}
int main()
{
test_priority_queue();
return 0;
}
这样写出来的优先级队列只能排升序,而实际上的优先级队列是可以排升序,也可以排降序的。
实现升序降序控制的叫仿函数,即一开始priority_queue源代码看到的第三个模板参数。
所谓仿函数函数实际上是一个对象,在对象中重载了 '()' 符号,已知 '()' 符号有两种用法,一是(表达式),可以用于数据类型强转,或者控制优先级;一是作函数调用,这里重载的就是函数调用,将类写成一个类似函数的使用方式,所以叫仿函数。也叫函数对象。
下面写一个简单的仿函数:
class less
{
bool operator()(int x, int y)
{
return x < y;
}
};
使用这个类:
less l1;
bool ret = l1(10, 20)
将仿函数修改为泛型:
template<class T>
class less
{
bool operator()(const T& x, const T& y) const
{
return x < y;
//支持的前提条件是类型要支持用 < 符号来进行大小的比较
}
};
仿函数是一个类,是类就可以作为参数传递。
priority_queue模拟——进阶版(只是添加上了仿函数)
priority_queue.h中
#pragma once
#include<iostream>
#include<vector>
#include<assert.h>
using namespace std;
template<class T>
class myless
{
public:
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
template<class T>
class mygreater
{
public:
bool operator()(const T& x, const T& y) const
{
return x > y;
}
};
template<class T, class container = vector<int>, class compare = myless<T>>
//和库中一样,默认为大堆
class myPriority_queue
{
public:
void adjustUp(int lea)
//向上调整算法,在插入数据后,将数据重新调整为堆时使用,lea为尾节点下标
{
compare func;
if (lea == 0)
return;
size_t fa = (lea - 1) / 2;
/*while (_con[fa] < _con[lea])*/
while (func(_con[fa], _con[lea]))
//利用仿函数达到比较的效果
//现在不清楚是大于还是小于了,具体将取决于传入compare的类。
//通过控制仿函数的类型,达到控制大堆还是小堆的效果。
{
swap(_con[fa], _con[lea]);
lea = fa;
fa = (lea - 1) / 2;
}
}
void adjustDown(size_t father = 0)
//向下调整算法,在删除数据后,使空间重新调整为堆时使用
//默认从根节点开始调整,在建堆时使用就需要传入第一个非叶子节点
{
compare func;
size_t fa = father;
//代表父节点
size_t ch = fa * 2 + 1;
//代表子节点
/*while (ch < _con.size() && _con[fa] < _con[ch])*/
while (ch < _con.size() && func(_con[fa], _con[ch]))
{
//if (ch + 1 < _con.size() && _con[ch] < _con[ch + 1])//开始默认左子节点大
if (ch + 1 < _con.size() && func(_con[ch], _con[ch + 1]))
ch++;
swap(_con[fa], _con[ch]);
fa = ch;
ch = fa * 2 + 1;
}
}
//push,pop,top,size,empty部分和上面一样,这里省略
private:
container _con;
};
test.cpp中
#define _CRT_SECURE_NO_WARNINGS 1
#include"priority_queue.h"
#include<iostream>
#include<vector>
using namespace std;
void test_priority_queue()
{
myPriority_queue<int,vector<int>, mygreater<int>> pri_qu;
//通过传仿函数控制为小堆,默认为大堆。
//剩下的部分一样,这里省略
}
int main()
{
test_priority_queue();
return 0;
}
利用模板实现不同比较的调用过程。
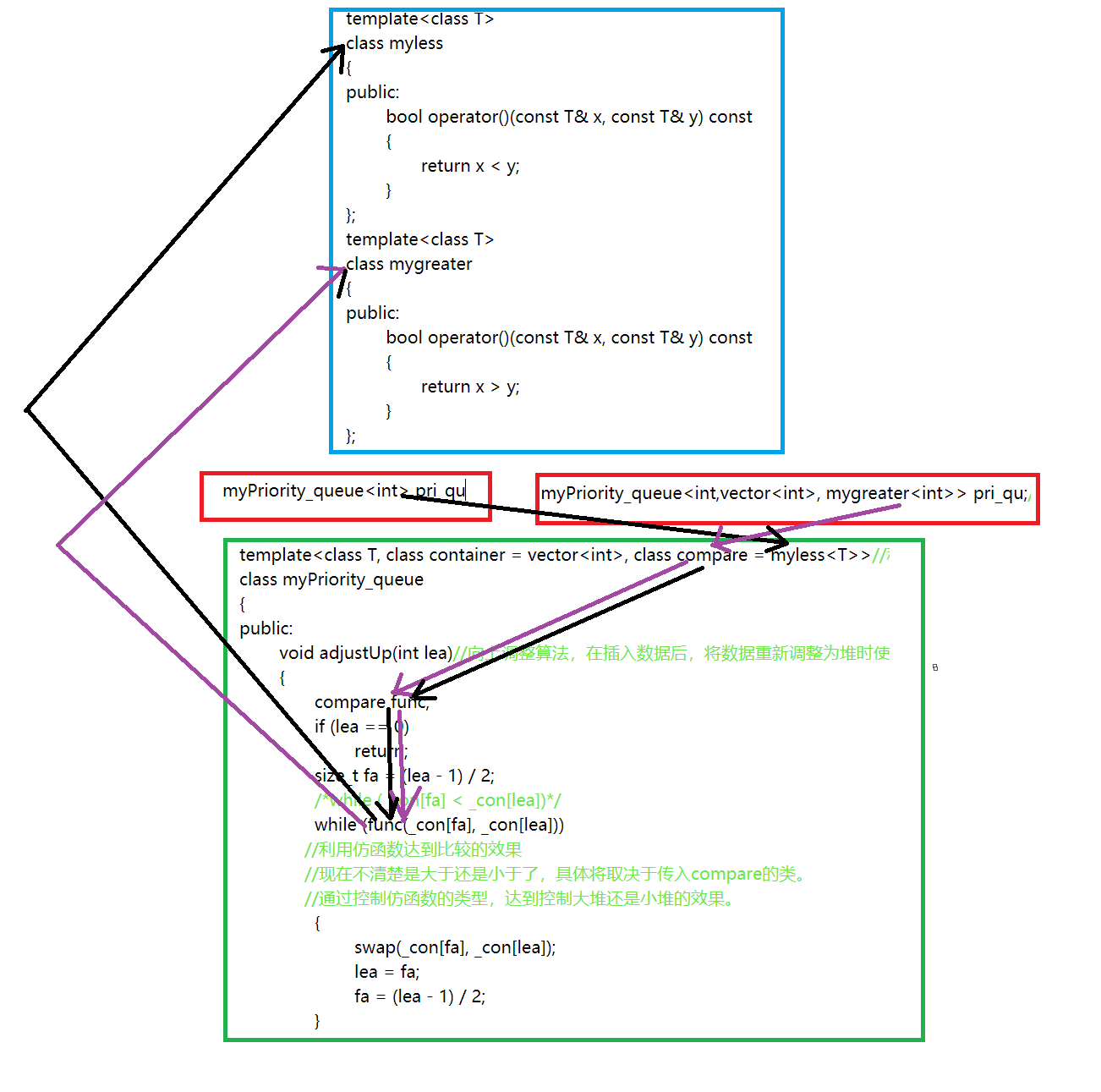
当使用默认传参时,compare被myless<T>赋值,compare创建的func对象,是myless的对象,func(_con[fa], _con[lea])会调用myless类中的成员函数,完成比较。当使用mygreater<T>传参时,compare被mygreater<T>赋值,compare创建的func对象,是mygreater的对象,func(_con[fa], _con[lea])会调用mygreater类中的成员函数,完成比较。
下面函数指针的内容了解就可以:
less和greater都是在库中包装好的仿函数,使用需要包头文件<functional>。一般利用仿函数的优势来替换函数指针。如果myPriority_queue传给compare的不是仿函数,而是函数指针会如何?
准备知识:
1.对函数指针解引用,找到对应函数,调用参数,和直接使用函数指针调用参数是一样的,即(*函数指针)(函数参数1.函数参数2)与函数指针(函数参数1,函数参数2)等价,代表函数指针可以直接使用()操作符,这样就能通过函数指针指向对应的比较函数,完成比较。
2.模板会自动推导类型,传什么就是什么,不会构造成单成员变量的类。
先来看一下函数指针的应用:

这是一个函数,*和()相比,()优先级更高,函数名与()结合,为函数。括号内的内容,即函数参数为void (*f)(),f是名称,与*结合,是函数指针,指向一个返回值为void,没有参数的函数。最后剩下:static void(* )()是返回值,即函数的返回值是一个函数指针,指针指向的类型为无参,返回值为static void。
模板具备自动推导的功能,可以兼容使用函数指针完成比较。
bool comIntLess(int x, int y)
{
return x > y;
}
myPriority_queue<int,vector<int>, bool(* )(int, int)> pri_qu;
//模板参数要传类型
按照想象,应该是传入函数指针,compare推导出指针类型,创建func函数指针变量,func(参数1,参数2)调用comIntLess函数。
但是直接这样替换myPriority_queue<int,vector<int>, greater<int>> pri_qu;会出错。
因为compare推导出函数指针类型后,compare func创建的变量是一个没有初始化的函数指针变量,函数指针指向未知。传过去的是类型,没有指向具体函数,不知道调用哪个函数。
要用函数指针,需要在构造的地方传入。同时要兼顾仿函数的传入,这就需要在一些地方做修改:简单来说就是把负责比较的类变成成员变量。
1.添加一个成员变量_comfunc
2.写myPriority_queue的构造函数
myPriority_queue(const compare& x = compare())
:_comfunc(x)
{}
//传给compare为仿函数类时,x是类,传给compare为函数指针时,x是指针。类创建的_comfunc对象可以调用类的成员函数
//这样是方便传入函数指针,即使不写构造函数,仿函数依然能正常使用,自定义类型为成员变量时会自动调用构造函数,也就是compare()。单凭模板是无法将函数地址传入myPriority_queue中。
//即使这样也不能在传模板参数的时候传入函数指针,而是通过构造函数完成指针的传值。
3.将所有func改为_comfunc
4.在创建优先级队列的地方将函数指针传入:myPriority_queue<int,vector<int>, bool(* )(int, int)> pri_qu(comIntLess)
总之,函数指针也能达到仿函数的效果,但比仿函数复杂,这还只是一个简单函数的情况下。
大多数情况下库中的仿函数就够用,在一些情况下需要自己写。
以c++sort为例:

可以看见,sort中也是有仿函数的。
运行如下程序,及其运行结果:
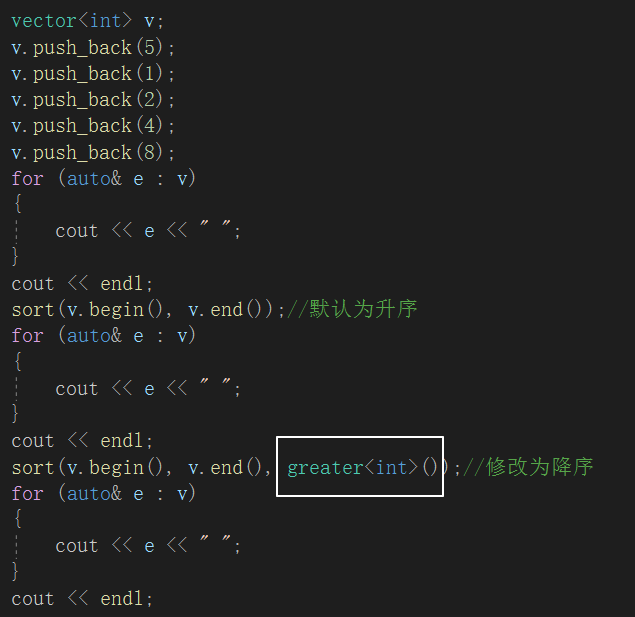
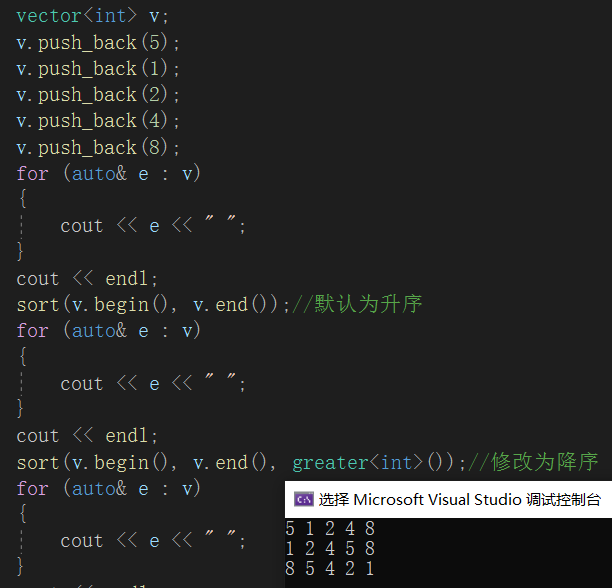
sort的传参和优先级队列仿函数传参不同的是多了一个(),原因在于优先级队列传的是模板参数,这里传的是对象,优先级队列是在内部创建对象,sort是将创建好的对象传入sort使用。sort是一个函数模板(优先级队列是类模板),传递的是函数的参数,所以这里传的应该是对象,而不是类型。
当需要对自定义类型进行排序的时候,就需要自己写仿函数了,有点类似运算符重载。
sort可以对数组进行排序吗?
数组空间连续,其迭代器本质就是指针,完全可以用sort对数组进行排序。
sort排序的基本原则之一就是要知道要排序对象的大小关系。或者说被排序的对象要有大小的比较规则。
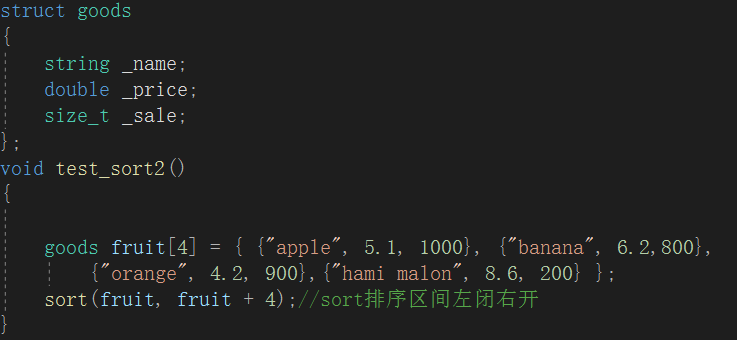
这样的排序是会报错的,因为没有goods类的比较规则。当传入两个goods类的对象到less仿函数中,struct中没有对<的重载,也就无法比较大小,实现升序排序;要进行降序排序也需要对>进行重载。
所以要加上比较方式:
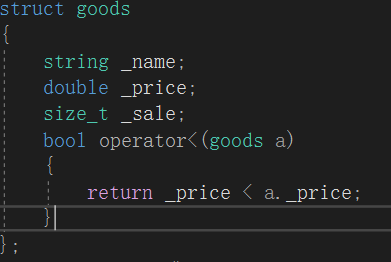
排序前:
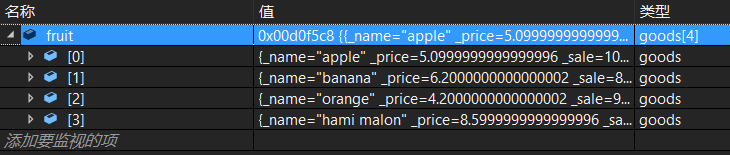
排序后:

按照价格升序进行排列。但是也有没解决的问题,如果要按照销量进行排序呢?
<可以被重载两次吗?当然可以,但是要如何解决参数类型不同的问题呢?less中的比较是两个goods对象的比较,即<重载的函数参数就固定为两个goods对象。
这时候仿函数就有用了,就是比较麻烦。当然,这个麻烦是有解决方案的。解决方案需要以后的知识(c++11中)。

将仿函数传给compare作为比较方式。升序的排序方式也是需要仿函数手动实现的,所以说比较麻烦。
重载<和仿函数的区别在于:
重载<函数是被库中用于比较的less仿函数调用的,less在比大小时,调用了operator<;
而手动仿函数则是取代less,完成比较的目的(compare类型为lessPrice,在sort中创建一个lessPrice对象,这个对象来对传入的两个goods对象比大小)。
补充一点:优先级队列有靠区间构造的方式,这个还是很有用的,比如需要对一个数字进行TopK问题的解决,这时用数组的区间构造一个优先级队列就能解决。
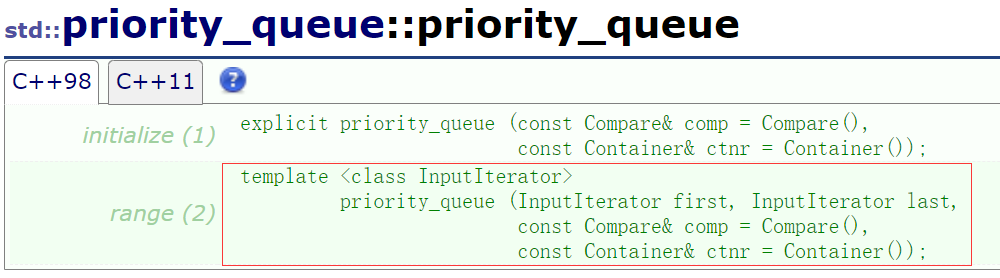
在兼容函数指针的版本下继续修改:即新写一个构造函数要支持传迭代器完成建堆
myPriority_queue(InputIterator first, InputIterrator last, const compare& x = compare())
//这里是构造函数,所以没有Container
:_comfunc(x)
{
while(first != last)
{
_con.push_back(*first);
first++;
}
for(size_t i = (_con.size() - 1 - 1) / 2; i >= 0; i--)
//_con.size() - 1是尾节点,(尾节点-1)/2得到第一个非叶子节点
{
adjustdown(i);
}
}