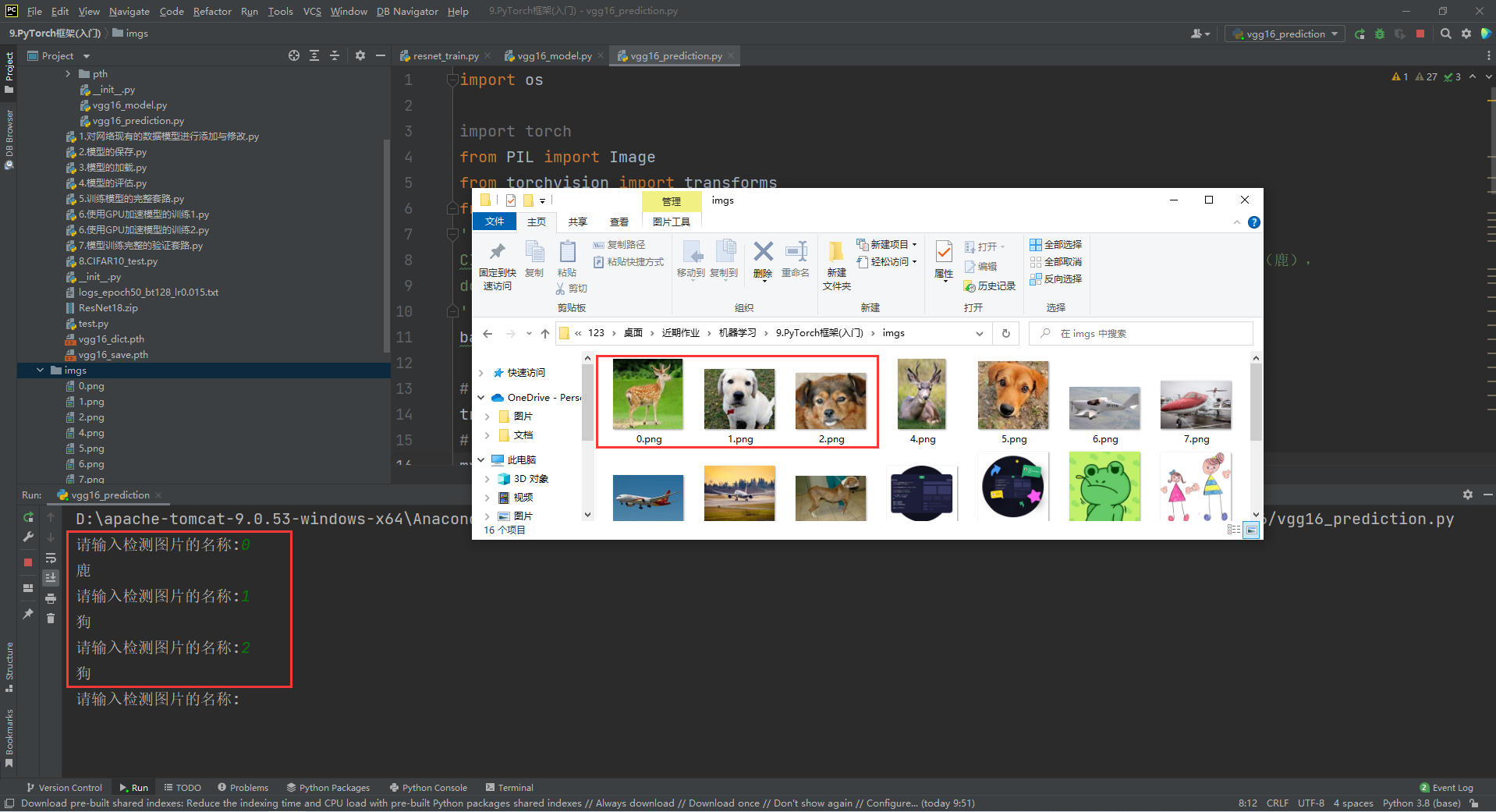
本文使用Pytorch+VGG16+官方CIFAR10数据集完成图像分类。识别效果如下:
文章目录
- 一、VGG16 神经网络结构
- 二、VGG16 模型训练
- 三、预测CIFAR10中的是个类别
一、VGG16 神经网络结构
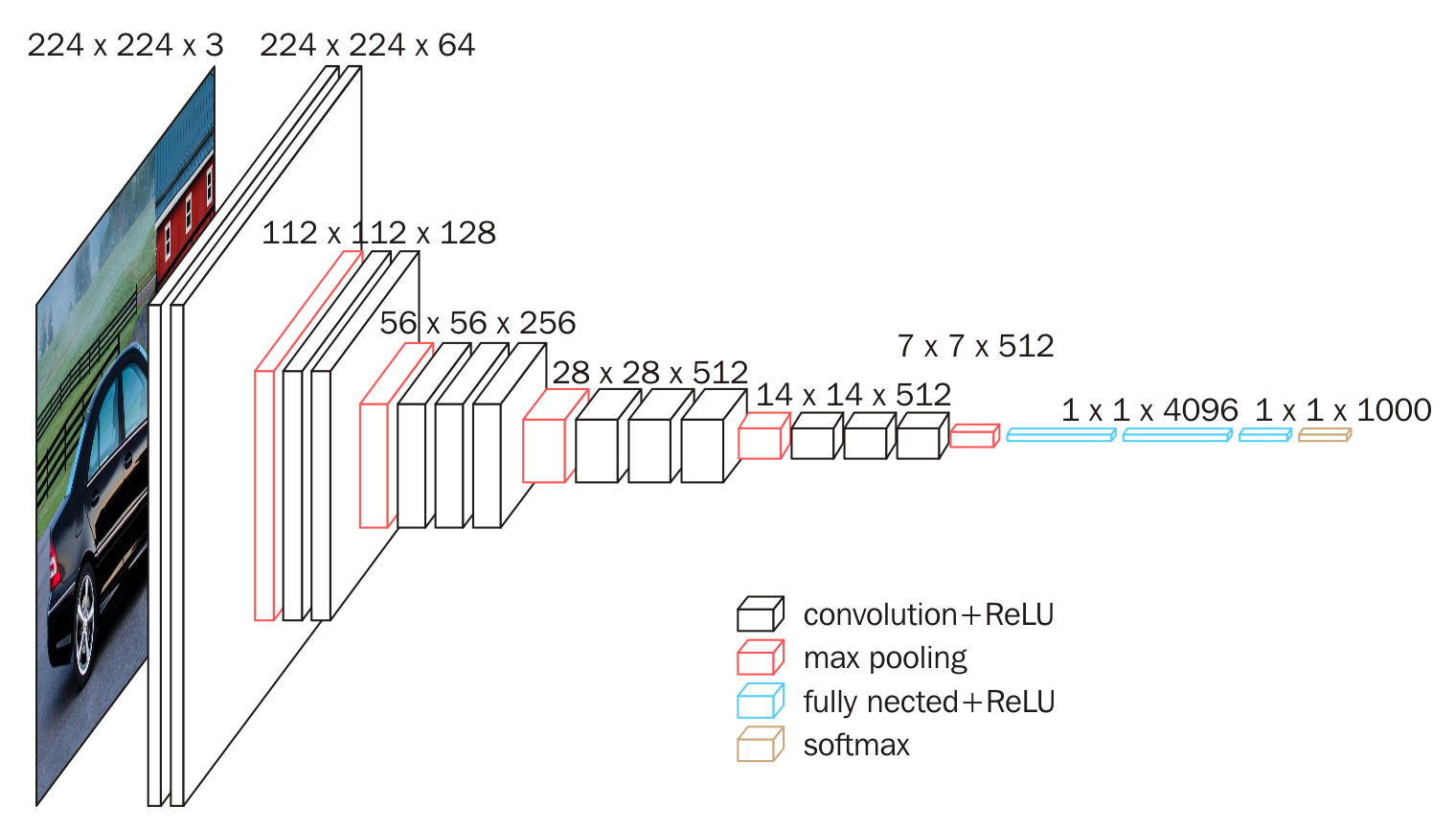
VGG,又叫VGG-16,顾名思义就是有16层,包括13个卷积层和3个全连接层,是由Visual Geometry Group组的Simonyan和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,该模型主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。其年参加了ImageNet图像分类与定位挑战赛,取得了在分类任务上排名第二,在定位任务上排名第一的优异成绩。
下图给出了VGG16的具体结构示意图:
下面给出按照块划分的VGG16的结构图,可以结合上图进行理解:

下图给出了VGG的六种结构配置:
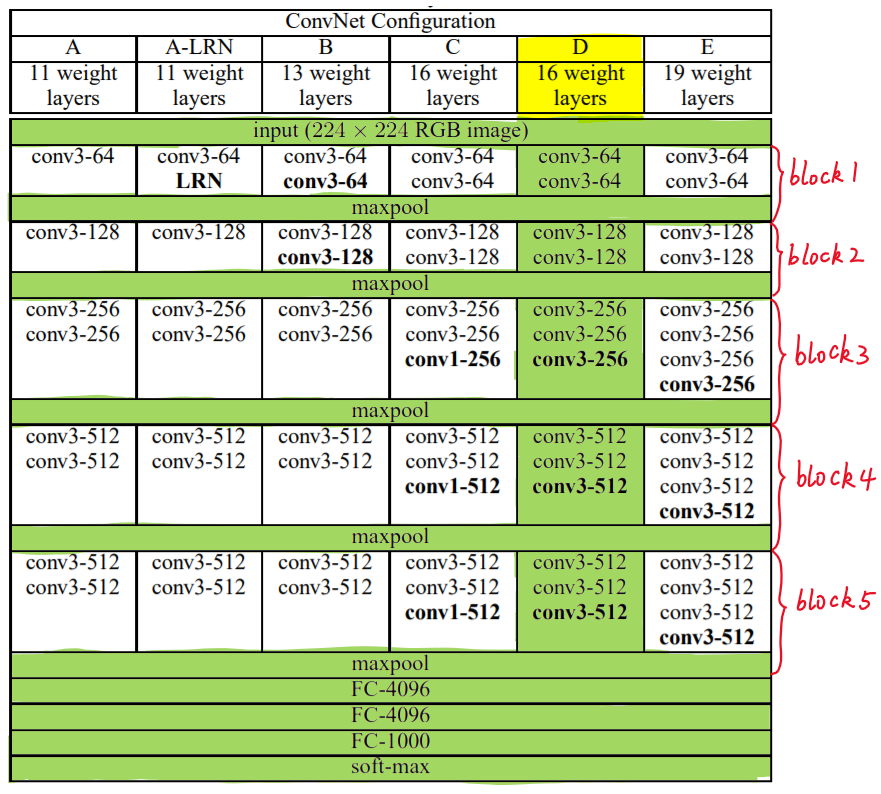
我们针对VGG16进行具体分析发现,VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
import torch
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(3, 64, 3, 1, 1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, 1, 1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2, 2))
self.layer2 = nn.Sequential(nn.Conv2d(64, 128, 3, 1, 1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, 1, 1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2, 2))
self.layer3 = nn.Sequential(nn.Conv2d(128, 256, 3, 1, 1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, 3, 1, 1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, 3, 1, 1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2, 2))
self.layer4 = nn.Sequential(nn.Conv2d(256, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2, 2))
self.layer5 = nn.Sequential(nn.Conv2d(512, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, 1, 1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2, 2))
self.fc1 = nn.Sequential(nn.Flatten(),nn.Linear(512, 512),nn.ReLU(),nn.Dropout())
self.fc2 = nn.Sequential(nn.Linear(512, 256),nn.ReLU(),nn.Dropout())
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
if __name__ == '__main__':
VGG16 = VGG16()
input = torch.ones((64, 3, 32, 32))
output = VGG16(input)
print(output.shape)
二、VGG16 模型训练
下面代码给出了使用VGG16网络训练CIFAR10数据集时的代码。
# http://www.syrr.cn/news/10118.html?action=onClick
import torchvision
from torch import optim
from torch.utils.data import DataLoader
import torch.nn as nn
from vgg16_model import *
import matplotlib.pyplot as plt
import time
from torch.utils.tensorboard import SummaryWriter
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data = torchvision.datasets.CIFAR10(root="data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="data", train=False, transform=torchvision.transforms.ToTensor(),download=True)
train_dataloader = DataLoader(train_data, batch_size=128)
test_dataloader = DataLoader(test_data, batch_size=128)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 创建网络模型
vgg16 = VGG16()
vgg16 = vgg16.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 0.015 # 设置学习速率
optimizer = torch.optim.SGD(vgg16.parameters(), lr=learning_rate)
# 设置训练网络的参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 50
# 添加tensorboard画图可视化
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("--------第{}轮训练开始---------".format(i + 1))
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = vgg16(imgs)
loss = loss_fn(outputs, targets)
# 梯度调0
optimizer.zero_grad()
# 反向传播 梯度
loss.backward()
# 调优
optimizer.step()
#记录训练次数
total_train_step = total_train_step + 1
# 每100打印loss
if total_train_step % 100 ==0:print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试,没梯度没有调优代码
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs=imgs.cuda()
targets=targets.cuda()
outputs = vgg16(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
# 计算整体测试集上的正确率
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:".format(total_test_loss))
# 使用/进行的tensor整数除法不再支持,可以使用true_divide代替
print("整体测试集上的正确率:{}".format(total_accuracy.true_divide(test_data_size)))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step = total_test_step + 1
# 可视化正确率
writer.add_scalar("test_accuracy", total_accuracy.true_divide(test_data_size), total_test_step)
# 保存每一轮的模型 这是第一种保存方式非官方推荐
torch.save(vgg16, "pth/vgg16_{}.pth".format(i+1))
print("模型已保存")
writer.close()
训练日志如下(具体大家自行训练):
训练数据集的长度为:50000
测试数据集的长度为:10000
--------第1轮训练开始---------
训练次数:100,Loss:1.8452614545822144
训练次数:200,Loss:1.3886604309082031
训练次数:300,Loss:1.4469469785690308
整体测试集上的loss:
整体测试集上的正确率:0.5472999821172485
--------第2轮训练开始---------
训练次数:400,Loss:1.108359356482321
训练次数:500,Loss:1.1589107513427734
训练次数:600,Loss:1.156502604484558
训练次数:700,Loss:0.886533796787262
整体测试集上的loss:
整体测试集上的正确率:0.6538000106811523
--------第3轮训练开始---------
训练次数:800,Loss:0.884425163269043
训练次数:900,Loss:0.8080787062644958
训练次数:1000,Loss:0.7888829112052917
训练次数:1100,Loss:0.6955403081231316
整体测试集上的loss:
整体测试集上的正确率:0.7230999660491943
三、预测CIFAR10中的是个类别
import os
import torch
from PIL import Image
from torchvision import transforms
from vgg16_model import *
'''
CIFAR10包含哪几类 这10类分别是airplane (飞机),automobile(汽车),bird(鸟),cat(猫),deer(鹿),
dog(狗),frog(青蛙),horse(马),ship(船)和truck(卡车)
'''
basepath=os.path.split(os.path.split(os.getcwd())[0])[0]
# 定义加载图片的方式
transformed=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])
# 加载模型
myModel=torch.load("pth/vgg16_50.pth",map_location="cpu")
while 1:
img_path=input("请输入检测图片的名称:")
img=Image.open(basepath+rf"\imgs\{img_path}.png")
img=img.convert("RGB")
img=transformed(img)
img=torch.reshape(img,(1,3,32,32))
myModel.eval()
with torch.no_grad():
output=myModel(img)
x=output.argmax(1)
if x==0:
print("飞机")
elif x==1:
print("汽车")
elif x==2:
print("鸟")
elif x==3:
print("猫")
elif x==4:
print("鹿")
elif x==5:
print("狗")
elif x==6:
print("青蛙")
elif x==7:
print("马")
elif x==8:
print("船")
elif x==9:
print("卡车")
预测结果在文章开头。