目录
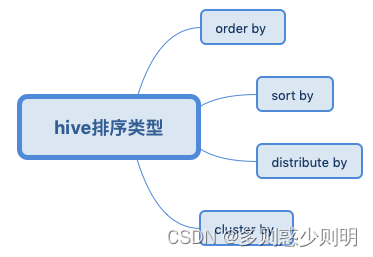
排序函数
1、order by
2、sort by
3、distribute by
4、cluster by
总结
排序类型
1、order by
order by是与关系型数据库的用法是一样的。select * from emp order by empno desc;
针对全局数据进行排序,所以最终只会有1个reduce,因为一个reduce对应一个输出文件,全局排序的话只能有一个输出文件,这个是不受hive的参数控制的。如果要查询的结果集数据量比较大的话,只有一个reduce运行,那么效率会非常低,所以在实际应用中一定要谨慎使用order by。
2、sort by
对每一个reduce内部进行排序,而对全局结果集来说是没有进行排序的。
1)一般在实际使用中会比较经常使用sort by。
2)需要先设置reduce的数量; 设置执行时reduce的个数: set mapreduce.job.reduces=<number> 查询语句为: select * from emp sort by empno asc;
3)每个输出结果的文件中的数据都是按empno进行排好序的。
3、distribute by
类似于MapReduce中的partition的功能,对数据进行分区排序,一般和sort by结合进行使用。 以员工表为例,按照部门进行排序的查询语句写法如下: insert overwrite local directory '/opt/datas/distby-res' select * from emp distribute by deptno sort by empno asc
注意,distribute by必须要在sort by之前,原因是要先进行分区,然后才能进行排序。
例子:
第一个文件的部门编号是30,第二个文件的部门编号是10,第三个部门编号是20。然后每个部门的员工数据都是按照员工编号进行升序排列的。
4、cluster by
cluster by是sort by和distribute by的组合,当sort by和distribute by的字段相同的时候,可以使用cluster by替代。
1)参考查询语句如下: insert overwrite local directory '/opt/datas/clustby-res' select * from emp cluster by empno ;
2)注意,cluster by 后面不能指定desc或者asc,否则会报错。
总结
order by : 全局排序,一个reduce。可能性能会比较差
sort by: 每个reduce内部排序,全局不排序。一般在实际使用中会比较经常使用sort by
distribute by:分区排序,需要结合sort by使用
cluster by: 当sort by和distribute by的字段相同的时候使用。但是cluster by默认是升序,不能指定排序方向;