描述
open(name[, mode[, buffering]])函数可以打开诸如txt,csv等格式的文件。
如下定义file_read()函数:
def read_file(file):
"""接收文件名为参数,读取文件中的数据到字符串中,返回字符串"""
with open(file, 'r', encoding='utf-8') as text: # 创建文件对象
txt =text.read() # 读文件为字符串
return txt # 返回字符串
上面的函数read_file(file)可以读取名为file的文件内容,以字符串形式返回txt,请继续编程统计字符串txt中大写字母、小写字母、数字、空格和其它字符的数量。
提示:
ch.isupper()函数判断字符ch是否为大写字母,返回True/False。
ch.islower()函数判断字符ch是否为小写字母,返回True/False。
ch.isdigit()函数判断字符ch是否为数字,返回True/False。
ch.isspace()函数判断字符ch是否为空白字符,包括空格,制表符,换行符,回车符,垂直制表符等,返回True/False。
判断空格可用是否为空格字符串' '
使用upper,lower,digit,space,other五个变量代表不同种类的字符个数,设定初值为0,在循环过程中按照判断结果进行累加。
函数返回时使用return upper, lower, digit, space, other语句,返回值为元组类型。
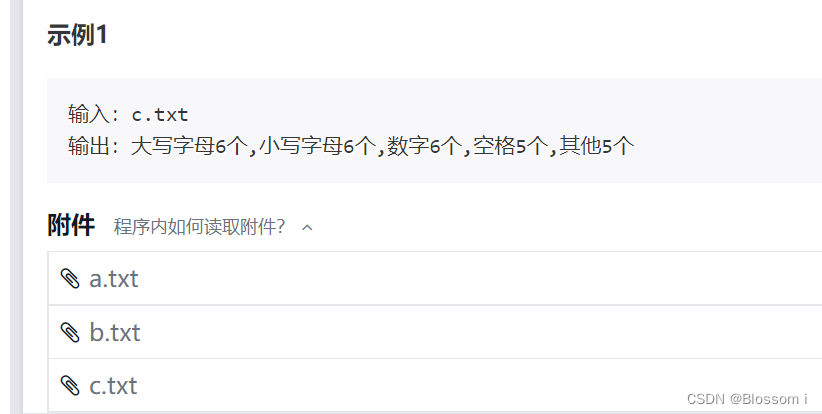
输入格式
输入为一行,是一个文本文件名,如example1.txt。
输出格式
输出为一行,是对名为example1.txt文件的内容进行分类统计后的结果, 输出形如:“ 大写字母m个,小写字母n个,数字o个,空格p个,其他q个 ”,具体格式见示例。
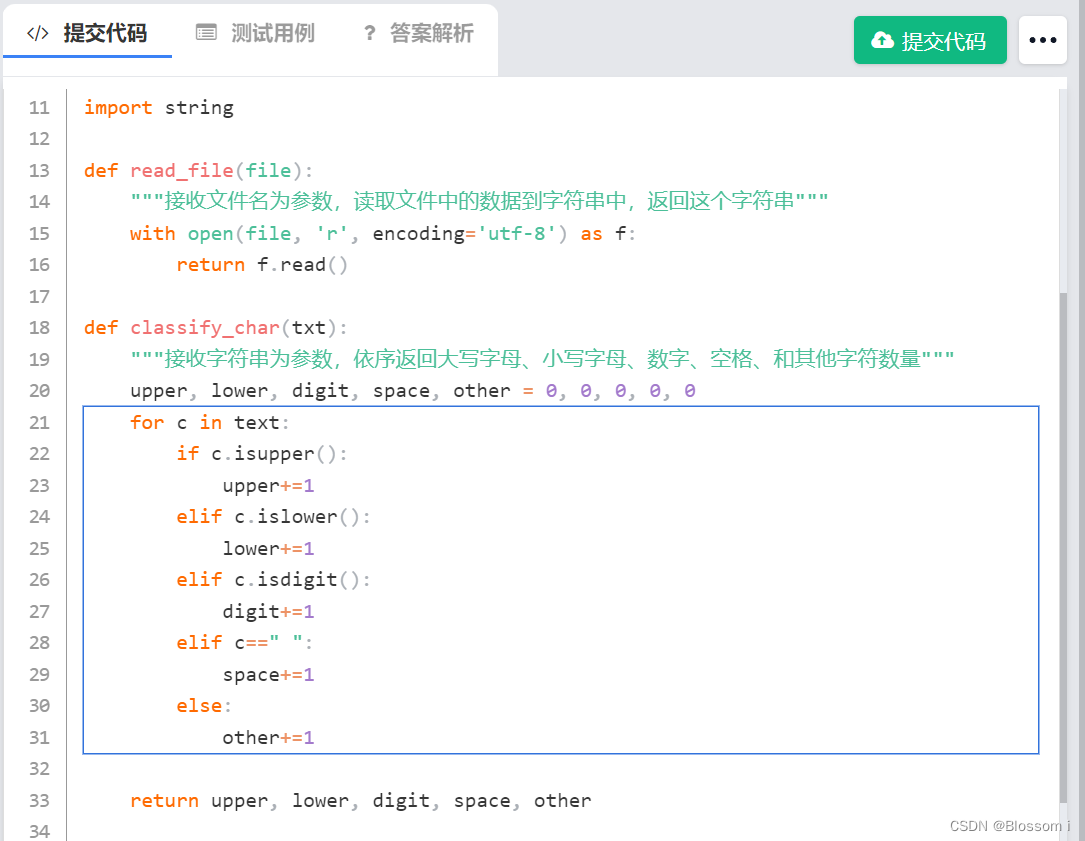

import string
def read_file(file):
"""接收文件名为参数,读取文件中的数据到字符串中,返回这个字符串"""
with open(file, 'r', encoding='utf-8') as f:
return f.read()
def classify_char(txt):
"""接收字符串为参数,依序返回大写字母、小写字母、数字、空格、和其他字符数量"""
upper, lower, digit, space, other = 0, 0, 0, 0, 0
for c in text:
if c.isupper():
upper+=1
elif c.islower():
lower+=1
elif c.isdigit():
digit+=1
elif c==" ":
space+=1
else:
other+=1
return upper, lower, digit, space, other
if __name__ == '__main__':
filename = input() # 读入文件名
text = read_file(filename) # 调用函数读文件中的内容为字符串
classify = classify_char(text) # 调用函数分类统计字符数量
print('大写字母{}个,小写字母{}个,数字{}个,空格{}个,其他{}个'.format(*classify))