1.Spark简介
1.1 Spark介绍
开源集群计算系统,致力于更快的处理数据
Both fast to run and fast to wrtie Spark
是专为大规模数据处理而设计的快速通用的计算引擎
Spark 可以完成各种运算,包括 SQL 查询、文本处理、机器学习等
Spark由Scala语言开发,能够和Scala紧密结合
1.2 Spark组件
Spark Core 核心底层部分 基于RDD 支持多种语言
Spark SQL 基于DataFrame 结构化数据查询
Spark Streming 流处理
Spark MLLib 机器学习
Spark GraphX 图计算
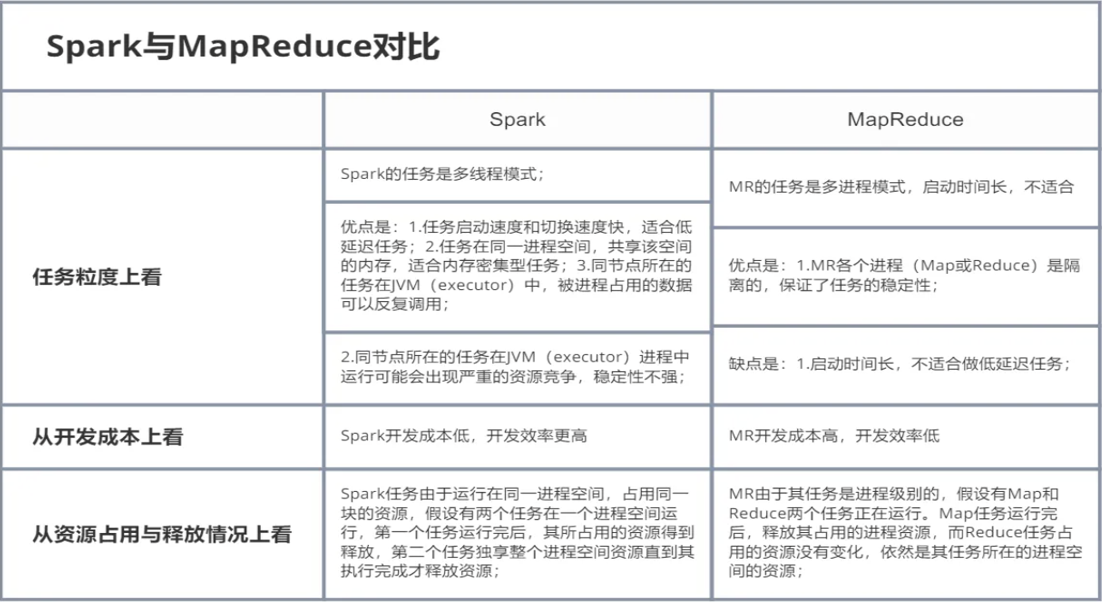
1.3 Spark和MapReduce对比
MapReduce为什么慢?Spark为什么快?
MapReduce:额外的复制 序列化 磁盘IO开销 细粒度资源调度
Spark:基于内存 DAG有向无环图 粗粒度资源调度
Spark提供使用 Java、Scala、Python 和 R 语言的开发 API,当然还可以使用SQL进行结构化查询
2.Spark部署
Spark支持多种部署模式
Local本地模式 多用于开发、本地测试
Standalone Spark自带的资源管理框架 可独立于其他大数据组件运行
Mesos 开源的资源管理系统 支持各种应用
Kubernetes Google开源的一个容器编排引擎 可移植、可拓展、自动化
Yarn Hadoop自带资源管理框架 贴合大数据生态 更具前景
2.1 Local模式
主要用于本地开发测试
由本地提供资源 简单方便,可设置线程数
local local[4] local[*]
搭建方式:
1.打开IDEA,创建Maven项目
2.在IDEA设置中安装Scala插件
3.在pom.xml文件中添加Scala依赖
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>4.在pom.xml中添加Scala编译插件
需要加在build->plugins标签下
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>5.在pom.xml文件中添加Spark-Core依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>然后编写代码进行执行
常见错误
-
windows环境下运行任务通常会有如下报错
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
-
原因分析
-
Spark程序运行时找不到winutils.exe程序或依赖
-
-
解决方法
-
下载winutils.exe程序
-
在任意无中文路径位置新建bin目录,例如
目录路径位置随意,但一定不要有中文目录
D:/shujia/bigdata/hadoop-2.7.6/bin
-
将winutils.exe程序放入上述bin目录中
-
在系统环境变量中增加一项HADOOP_HOME配置
-
将
D:/shujia/bigdata/hadoop-2.7.6/目录作为HADOOP_HOME的值注意不要将bin目录包含在其中
-
重启IDEA
-
重新运行程序,检查错误是否消失
-
2.2 Standalone模式
-
1、上传解压
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/soft mv spark-2.4.5-bin-hadoop2.7 spark-2.4.5
-
2、修改配置文件
# 重命名文件 cp spark-env.sh.template spark-env.sh cp slaves.template slaves
增加配置:
vim spark-env.shmaster相当于RM worker相当于NM
export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=2g export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
增加从节点配置:
vim slaves以node1、node2作为从节点
node1 node2
-
3、复制到其它节点
cd /usr/local/soft/ scp -r spark-2.4.5 node1:`pwd` scp -r spark-2.4.5 node2:`pwd`
-
4、配置环境变量
-
vim /etc/profile SPARK_HOME=/usr/local/soft/spark-2.4.5/ export PATH=$PATH:$SPARK_HOME/bin
-
5、在主节点执行启动命令
注意:start-all.sh 与Hadoop的sbin目录中的启动命令有冲突
cd /usr/local/soft/spark-2.4.5/ ./sbin/start-all.sh
-
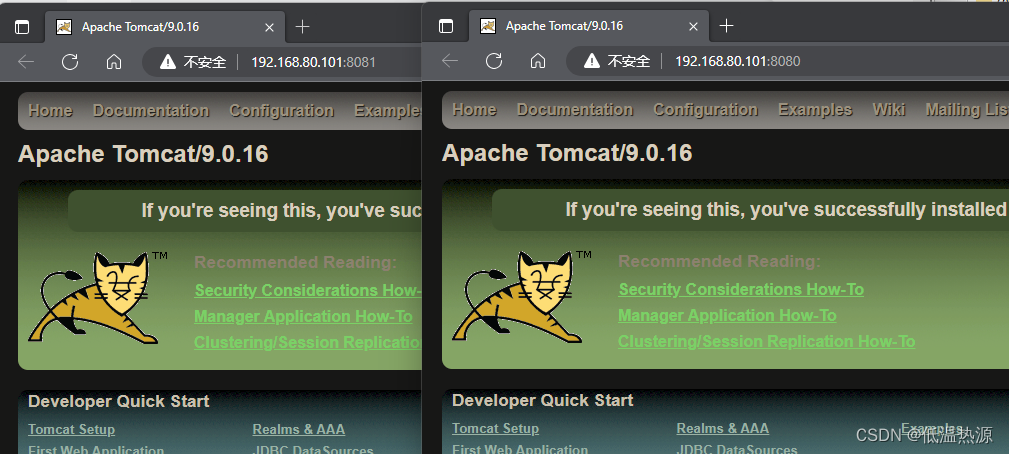
6、访问Spark Web UI
http://master:8080/
-
7、测试及使用
切换目录:
cd /usr/local/soft/spark-2.4.5/examples/jarsstandalone client模式 :日志在本地输出,一般用于上线前测试
-
提交自带的SparkPi任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 100
standalone cluster模式:上线使用,不会在本地打印日志
-
提交自带的SparkPi任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-examples_2.11-2.4.5.jar 100
-
-
8、其他运行方式
-
spark-shell spark 提供的一个交互式的命令行,可以直接写代码
spark-shell master spark://master:7077
-
2.3 On Yarn模式
在公司一般不适用standalone模式
因为公司一般已经有yarn 不需要搞两个资源管理框架
Spark整合yarn只需要在一个节点整合, 可以删除node1 和node2中所有的Spark 文件
-
1、停止Spark Standalone模式集群
# 切换目录 cd /usr/local/soft/spark-2.4.5/ # 停止集群 ./sbin/stop-all.sh
-
2、增加hadoop 配置文件地址
vim spark-env.sh # 增加HADOOP_CONF_DIR export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop
-
3、关闭Yarn
stop-yarn.sh
-
4、修改Yarn配置
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/ vim yarn-site.xml # 加入如下配置 <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
-
5、同步到其他节点
scp -r yarn-site.xml node1:`pwd` scp -r yarn-site.xml node2:`pwd`
-
6、启动Yarn
start-yarn.sh
-
7、测试及使用
切换目录:
cd /usr/local/soft/spark-2.4.5/examples/jarsSpark on Yarn Client模式:日志在本地输出,一班用于上线前测试
-
提交自带的SparkPi任务
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 512M --num-executors 2 spark-examples_2.11-2.4.5.jar 100
Spark on Yarn Cluster模式:上线使用,不会在本地打印日志
-
提交自带的SparkPi任务
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 512m --num-executors 2 --executor-cores 1 spark-examples_2.11-2.4.5.jar 100
-
获取yarn程序执行日志 执行成功之后才能获取到
yarn logs -applicationId application_1685630398461_0005
-
-
8、开启Spark On Yarn的WEB UI
修改配置文件:
# 切换目录 cd /usr/local/soft/spark-2.4.5/conf # 去除后缀 cp spark-defaults.conf.template spark-defaults.conf # 修改spark-defaults.conf vim spark-defaults.conf # 加入以下配置 spark.eventLog.enabled true spark.eventLog.dir hdfs://master:9000/user/spark/applicationHistory spark.yarn.historyServer.address master:18080 spark.eventLog.compress true spark.history.fs.logDirectory hdfs://master:9000/user/spark/applicationHistory spark.history.retainedApplications 15
创建HDFS目录用于存储Spark History日志
hdfs dfs -mkdir -p /user/spark/applicationHistory
启动Spark History Server
cd /usr/local/soft/spark-2.4.5/ ./sbin/start-history-server.sh