ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表
- 从1.7到1.8版本,由于HashEntry从链表 变成了红黑树所以 concurrentHashMap的时间复杂度从O(n)到O(log(n))
- HashEntry最小的容量为2
- Segment的初始化容量是16;
- HashEntry在1.8中称为Node,链表转红黑树的值是8 ,当Node链表的节点数大于8时Node会自动转化为TreeNode,会转换成红黑树的结构
1.7和1.8区别
JDK1.7版本:ReentrantLock+Segment+HashEntry
JDK1.8版本:synchronized+CAS+HashEntry+红黑树
1.JDK1.8降低锁的粒度,JDK1.7锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry
2.JDK1.8使用红黑树来优化链表
3.JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了。
- synchronized之前一直都是重量级的锁,但是后来java官方是对他进`行过升级的,他现在采用的是锁升级的方式去做的。
针对 synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。
所以是一步步升级上去的,最初也是通过很多轻量级的方式锁定的。
可以看出到了jdk1.8 锁的粒度进一步细化,那么为什么能够进一步细化并且使用synchronized替换1.7中的ReentrantLock,还是因为,synchronized锁升级的优化,使得锁在更细粒度下仍然有更好的表现
构造函数
1.7
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// 找的2的整数次幂
int sshift = 0; //ssize从1变成大于等于concurrencyLevel的2次幂需要左移的次数
int ssize = 1;
//依据给定的concurrencyLevel并行度,找到最适合的segments数组的长度,
// 该长度为大于concurrencyLevel的最小的2的n次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
//如果使用默认参数,也就是initialCapacity是16,concurrencyLevel是16,那么ssize也就是16,c是1,下面c++这句就不会执行
if (c * ssize < initialCapacity)
++c;
//最后计算出来的c相当于initialCapacity / ssize向上取整
//cap是每个分段锁中HashEntry数组的长度
int cap = MIN_SEGMENT_TABLE_CAPACITY
while (cap < c)
cap <<= 1;
// 新建segments 数组,初始化 segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
构造方法分析:
参数:
initialCapacity,代表的是HashEntry[]数组的大小,也就是ConcurrentHashMap的大小。初始化默认为16.
loadFactor,负载因子,在判断扩容的时候用到,默认是0.75
concurrencyLevel,并发级别,代表Segment[]数组的大小,也就是分段锁的个数,默认是16(jdk1.8为了兼容jdk1.7也有这个构造参数,但是功能含义已经不一样了)
我们举一个例子,假如new ConcurrentHashMap(32, 0.75, 16)就是新建了一个ConcurrentHashMap,他的容量是32,分段锁的个数是16,也就是每个Segment里面HashEntry[]数组的长度是2。但是new ConcurrentHashMap()时,每个Segment里面HashEntry[]数组的长度也是2,因为ConcurrentHashMap规定了Segment数组中HashEntry数组的长度是2。
下面这段代码保证了Segment数组的大小是大于concurrencyLevel的最小2的整数次幂(每左移一次都相当于乘上2,直到值大于concurrencyLevel才停止左移),ssize是初始化Segment数组的大小。
int ssize = 1;
while (ssize < concurrencyLevel) {
ssize <<= 1;
}
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
Segment数组的大小为2的整数次幂是因为计算hash值的时候采用与运算(key.hashcode & length-1),加快了计算速度,减少了哈希碰撞。
下面这段代码保证了每个HasHashEntry数组的长度也是2的整数次幂。并且数组长度最小为2。如果比2小就取2。
int cap = MIN_SEGMENT_TABLE_CAPACITY //最小值,常量2
while (cap < c)
cap <<= 1;
new HashEntry[cap];
举例:new ConcurrentHashMap(33, 0.75, 16) ,那么Segment数组的大小是16,因为最后一个参数是16,16正好是2的整数次方,而HashEntry数组的长度:
int c = initialCapacity / ssize; // 33/16=2
if (c * ssize < initialCapacity)// 2*16<33
++c; // c=3
//最后计算出来的c相当于initialCapacity / ssize向上取整
//cap是每个分段锁中HashEntry数组的长度
int cap = MIN_SEGMENT_TABLE_CAPACITY
while (cap < c) // 2<3
cap <<= 1; // cap=4
长度为4.
1.8
// concurrencyLevel,并发线程数
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel)
// 初始容量参数小于并发线程数,将初始容量参数赋值为并发线程数
initialCapacity = concurrencyLevel;
// 计算数组长度
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
1.8中concurrencyLevel的作用仅仅是一个判断,要求initialCapacity大于等于concurrencyLevel
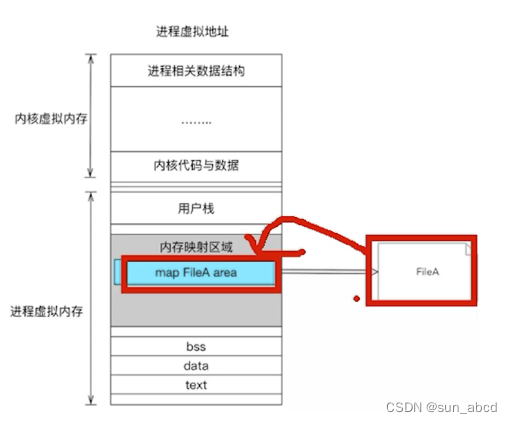
JDK1.7的实现(ReentrantLock+Segment+HashEntry)
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:

Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
Segment的大小ssize默认为 DEFAULT_CONCURRENCY_LEVEL =16
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置。
Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置。
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null
为什么get不加锁可以保证线程安全
首先获取value,我们要先定位到segment,使用了UNSAFE的getObjectVolatile具有读的volatile语义,也就表示在多线程情况下,我们依旧能获取最新的segment.
获取hashentry[],由于table是每个segment内部的成员变量,使用volatile修饰的,所以我们也能获取最新的table.
然后我们获取具体的hashentry,也时使用了UNSAFE的getObjectVolatile具有读的volatile语义,然后遍历查找返回.
总结:我们发现整个get过程中使用了大量的volatile关键字,其实就是保证了可见性(加锁也可以,但是降低了性能),get只是读取操作,所以我们只需要保证读取的是最新的数据即可.
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案
1、第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
2、第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回(美团面试官的问题,多个线程下如何确定size)
rehash操作
ConcurrentHashMap的扩容仅仅是和每个Segment中的HashEntry数组的长度有关。但需要扩容时,只扩容当前Segment中的HashEntry数组即可。也就ConcurrentHashMap中的Segment数组在初始化的时候就确定了,后面扩容不会改变这个长度。
相比较HashMap的resize操作,ConcurrentHashMap的rehash原理类似。但是对其做了一定优化,避免让所有节点进行计算操作。
由于扩容是基于2的幂指来操作,假设扩容前某HashEntry对应到Segment中数组的index为i,数组的容量为capacity,那么扩容后该HashEntry对应到新数组中的index只可能为i或者i+capacity,因此大多数HashEntry节点在扩容前后index可以保持部件。基于此,rehash()方法中会定位第一个后续所有节点在扩容后idnex都保持不变的节点,然后将这个节点之前的所有节点重排即可。
JDK1.8的实现(synchronized+CAS+HashEntry+红黑树)
· 取消segments字段
· table数组+单向链表-----> table数组+ 单向链表+ 红黑树【对于链表个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。】
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作。
Node是ConcurrentHashMap存储结构的基本单元,继承于HashMap中的Entry,用于存储数据
put操作
- 如果没有初始化就先调用initTable()方法对其初始化;
- 对key进行hash计算,求得值没有哈希冲突的话,则利用自旋CAS操作来进行插入数据;
- 如果存在hash冲突,那么就加synchronized锁来保证线程安全
- 如果存在扩容,那么就去协助扩容
- 加完数据之后,再判断是否还需要扩容
get操作
据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
如果正在扩容,且当前节点已经扩容完成,那么根据ForwardingNode查找扩容后的table上的对应数据
如果是红黑树那就按照树的方式获取值。如果不满足那就按照链表的方式遍历获取值。
size操作
在JDK1.8版本中,对于size的计算,在扩容和addCount()方法就已经有处理了,可以注意一下Put函数,里面就有addCount()函数,早就计算好的,然后你size的时候直接给你。JDK1.7是在调用size()方法才去计算,其实在并发集合中去计算size是没有多大的意义的,因为size是实时在变的,只能计算某一刻的大小,但是某一刻太快了,人的感知是一个时间段,所以并不是很精确
transfer扩容
1.8版本的扩容比较复杂,具体可以看哲这篇的解析ConcurrentHashMap 成员、方法分析
helpTransfer 会在put,remove,get时发现当前槽的头节点为MOVE状态时 也就是已经转换为ForwardingNode,代表当前节点已经转移完毕,整个ConcurrentHashMap还正在扩容,说明整个concurrenHashMap正在扩容。那么进入helpTransfer方法,协助进行扩容,直到扩容完成,那么如果当前需要操作的节点还不是ForwardingNode即还没有完成扩容操作,那么会直接使用源tab,进行操作,对于写操作,也就是说,扩容期间,除了锁住头节点的槽,和已经扩容完成的节点,其他节点依然正常读写。不会因为访问这些节点进入协助扩容!,可见ConcurrentHashMap对锁粒度的控制十分细。


![[附源码]Python计算机毕业设计SSM晋中学院教室管理系统(程序+LW)](https://img-blog.csdnimg.cn/db651479d9524dffa6d6f3ca2d75b9a6.png)

![[附源码]计算机毕业设计小太阳幼儿园学生管理系统Springboot程序](https://img-blog.csdnimg.cn/312a5ce167264dd189ed255e4d517b01.png)
![[附源码]Python计算机毕业设计SSM教务管理系统(程序+LW)](https://img-blog.csdnimg.cn/865e25fea1bf46bfb0deac82dc19db31.png)