Python 正则表达式识别代码中的中文、英文和数字
- 识别中文
- 识别英文
- 识别数字
- 拓展
在文本处理和数据分析中,有时候需要从代码中提取出其中包含的中文、英文和数字信息。正则表达式是一种强大的工具,可以帮助我们实现这一目标。本文将分三个部分详细介绍如何使用正则表达式在 Python 中识别代码中的中文、英文和数字。
识别中文
在 Python 中,可以使用 Unicode 字符范围来匹配中文字符,其中中文字符的 Unicode 范围是 "\u4e00-\u9fff"。我们可以使用正则表达式模式来匹配中文字符,并提取出来。
import re
def extract_chinese_chars(code):
chinese_pattern = '[\u4e00-\u9fff]+' # 匹配中文字符
chinese_chars = re.findall(chinese_pattern, code)
return chinese_chars
# 测试代码
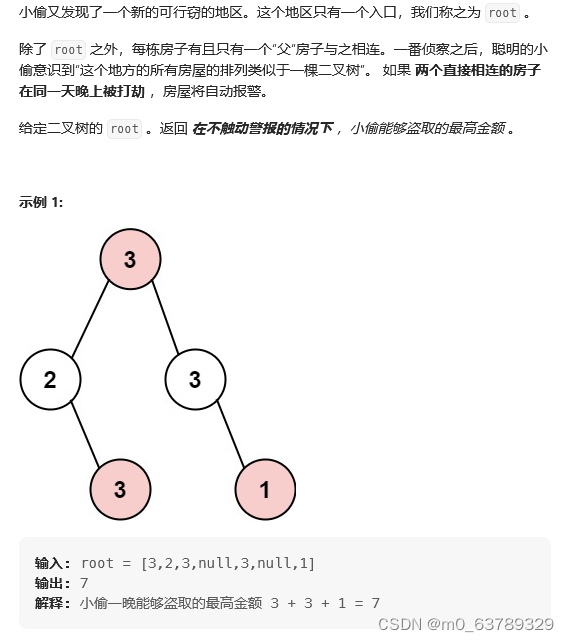
code = '''
在人脸检测方面,一种常见的方法是使用Haar级联分类器。
Haar级联分类器是一种基于机器学习的人脸检测方法,其核心是基于特征的级联分类器。
这种方法需要首先使用训练数据来训练分类器,然后使用它来检测新的图像中的人脸。
在人脸识别方面,另一种常见的方法是使用人脸识别算法,例如Eigenfaces,Fisherfaces和LBPH(Local Binary Pattern Histograms)。
这些算法使用训练数据集中的人脸图像来学习每个人脸的特征,并在新图像中使用这些特征来识别人脸。
'''
chinese_chars = extract_chinese_chars(code)
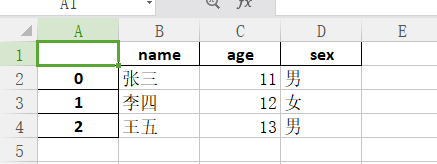
print("中文字符:", chinese_chars)
效果图:

在上述示例中,我们定义了extract_chinese_chars 函数来提取代码中的中文字符。函数内部使用 re.findall 函数和正则表达式模式来匹配中文字符,并将匹配结果返回。通过对示例代码进行测试,我们成功提取了中文字符,并输出了结果。
识别英文
为了识别英文字符,我们可以使用字母字符类进行匹配。在 Python 中,字母字符类可以使用 "[a-zA-Z]" 来表示,如果还包括数字,则可以使用 "[a-zA-Z0-9]"。我们同样可以使用正则表达式模式来匹配英文字符,并提取出来。
import re
def extract_english(code):
english_pattern = '[a-zA-Z]+' # 匹配英文字符
english_chars = re.findall(english_pattern, code)
return english_chars
# 测试代码
code = '''
在人脸检测方面,一种常见的方法是使用Haar级联分类器。
Haar级联分类器是一种基于机器学习的人脸检测方法,其核心是基于特征的级联分类器。
这种方法需要首先使用训练数据来训练分类器,然后使用它来检测新的图像中的人脸。
在人脸识别方面,另一种常见的方法是使用人脸识别算法,例如Eigenfaces,Fisherfaces和LBPH(Local Binary Pattern Histograms)。
这些算法使用训练数据集中的人脸图像来学习每个人脸的特征,并在新图像中使用这些特征来识别人脸。
'''
english_chars = extract_english(code)
print("英文字符:", english_chars)
效果图:

在上述示例中,我们定义了 extract_english 函数来提取代码中的英文字符。函数内部使用 re.findall 函数和正则表达式模式来匹配英文字符,并将匹配结果返回。通过对示例代码进行测试,我们成功提取了英文字符,并输出了结果。
识别数字
要识别代码中的数字,可以直接使用数字字符类进行匹配。在 Python 中,数字字符类可以使用 "[0-9]" 来表示。我们同样可以使用正则表达式模式来匹配数字,并提取出来。
import re
def extract_numbers(code):
number_pattern = '[0-9]+' # 匹配数字
numbers = re.findall(number_pattern, code)
return numbers
# 测试代码
code = '''
在人脸检测方面,一种常见的方法是使用Haar级联分类器。
Haar级联分类器是一种基于机器学习的人脸检测方法,其核心是基于特征的级联分类器。
这种方法[5003]需要首先使用训练数据来训练分类器,然后使用它来检测新的图像中的人脸。
在人脸识别方面,另一种常见的方法(123456)是使用人脸识别算法,例如Eigenfaces,Fisherfaces和LBPH(Local Binary Pattern Histograms)。
这些算法使用训练--13141516-数据集中的人脸图像来学习每个人脸的特征,并在新图像中使用这些特征来识别人脸。
'''
numbers = extract_numbers(code)
print("数字:", numbers)
效果图:

在上述示例中,我们定义了 extract_numbers 函数来提取代码中的数字。函数内部使用 re.findall 函数和正则表达式模式来匹配数字,并将匹配结果返回。通过对示例代码进行测试,我们成功提取了数字,并输出了结果。
拓展
正则表达式(Regular Expression)是一种强大的文本模式匹配工具,它可以用来在字符串中进行高级的搜索、匹配、替换和提取操作。正则表达式由一系列字符和特殊符号组成,这些字符和符号形成了一种规则,描述了我们希望匹配的文本模式。
下面是正则表达式的一些强大功能的简介:
1、匹配文本模式: 正则表达式可以使用特定的模式来匹配字符串中的文本。例如,可以使用正则表达式来匹配电子邮件地址、URL、电话号码等特定的文本模式。
2、搜索和替换: 正则表达式可以在字符串中搜索指定的模式,并将其替换为其他内容。这对于批量替换、字符串处理和文本清洗非常有用。
3、字符类和量词: 正则表达式提供了字符类和量词的功能,用于指定匹配的字符集合和匹配次数。例如,可以使用字符类来匹配字母、数字或特定范围的字符,使用量词来指定匹配的次数,如匹配零次或多次。
4、边界匹配: 正则表达式支持边界匹配,例如匹配单词的边界、字符串的开头或结尾等。这对于精确匹配特定位置的文本很有用。
5、分组和捕获: 正则表达式可以使用括号来创建分组,并将匹配的部分捕获到变量中。这使得可以对匹配的结果进行进一步处理或提取特定部分。
6、非贪婪匹配: 正则表达式默认使用贪婪匹配,即尽可能多地匹配文本。但可以使用非贪婪匹配来匹配尽可能少的文本。这在需要匹配最短的字符串时很有用。
7、后向引用: 正则表达式允许使用后向引用来引用之前捕获的内容。这可以用于查找重复的模式,例如匹配重复的单词、标签等。
8、预查机制: 正则表达式支持预查机制,用于在匹配时向前或向后查找特定的模式,而不进行实际匹配。这对于在匹配时进行条件判断或限制非匹配部分很有用。
喜欢的点个赞❤吧!