一 HTTP编码杂谈
① 知识铺垫
1) 编码的英文叫'encode' --> 常见'HTTP URL'编码、'Base64'编码等
目的: 转变为'二进制的stream(字节流)',便于'网络传输'
备注: 一般都是基于'utf-8'编码
2) 解码叫'decode'
3) 乱码的根源: '编码'和'解码'的方式不一致
4) 'url编码'和我们'日常所说编码'不是一回事
5) 写这篇文章最初的灵感: 想从'图裂'探究'url编码',稍微有点'偏'题了哈URI
URI编码 URL编码
BASE64编码
字符编码
编码和转义的区别
Java中字符编码相关的问题解析
如何在URL中传递中文
编码、解码、序列化及反序列化的含义与区别
② URL编码
浏览器的URL编码原理 说说http协议中的编码和解码
1) 爱宝的妍 --> "原始中文"
2) %E7%88%B1%E5%AE%9D%E7%9A%84%E5%A6%8D --> 'UTF-8编码','ASCII 2进制'转化为16进制
备注: 一个'中文'字符[charset]'UTF-8'编码对应'3个字节[bytes]',一个字节对应'8[bit]位'
特点: 每个'字节8bit',前面用%表示是'16进制'
3) %B0%AE%B1%A6%B5%C4%E5%FB --> 'GBK 编码'
备注: 一个'中文'字符[charset]'GBK'编码对应'2个字节[bytes]',一个字节对应'8[bit]位'
备注: xdd -u --> 十六进制输出时使用'大写'字母,'默认'是'小写'字母
强调: URL默认是用'UTF-8'编码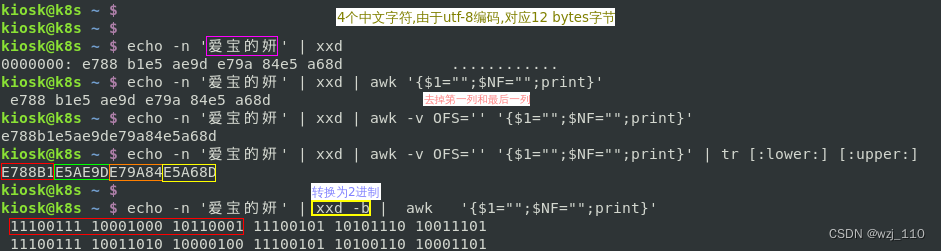
ngx_http_charset_module


![]()
对比:不同的'客户端'测试现象不一样,'curl'和'浏览器'
思考: 同时设置这种'行为'? --> "推荐分开设置"
default_type 'text/html;charset=utf-8'; --> 指的是'自己回传数据的编码'
charset utf-8; --> 指的是'nginx'的编码
关注点: Java中用于URL编解码的'类'有java.net包中的'URLEncoder'、'URLDecoder'
补充: 浏览器有一个'独特'的现象,'utf-8'编码后的字符放到浏览器中会'自动解析'![]()
curl解码技巧
③ 从前端裂图探究URL编码
++++++++++++++ "裂图的常见原因" ++++++++++++++
1) 本质上是'资源无法访问','裂图'只是'表像'
2) 无法访问的若干'原因':
[1]、域名无法解析、网络或防火墙不通 --> "直接访问资源形式验证"
[2]、资源'不完整(有损)',比如格式'被破坏',丢失'部分'数据
[3]、层层转发导致'url'发生变化,不是对应资源的'uri' --> "直接访问资源形式验证"
[4]、URL编码'导致' --> "常见" --> "下面案例讲解"
[5]、资源确实'不存在':可能是'上传错'地方或者'访问错'地方,或者被'误'删除 --> "常见"
[6]、权限'不足'导致
[7]、盗链被'发现',也即引入'第三方'资源被发现,然后被加入到'黑名单'导致
[8]、Content-Security-Policy 响应头'限制'导致对象存储服务OBS的基本概念


背景和现象:
1) 上传带'中文'名称的'图片资源'后,上传到'OBS对象存储桶'里面是'中文字符'的图片资源
备注: 上传'英文名称'的图片无此现象
2) 同时将'图片'的文件名以'utf-8'编码形式保存在'数据库'
2) Java代码从数据库中查询该'昵称'对应关联的'图片资源名称'
3) 将该名称['utf-8'编码]作为查询字符串形式'?name=xxx'形式'发起'请求,发现是'裂图'
验证方式: 直接'访问资源[中文名称]','不通过'数据库的方式 --> ok
原因: Java代码在发起'url'请求的时候,会主动进行'url'编码,导致'资源名称被二次'编码
解决方式: Java代码通过数据库查询的'资源名称',进行'decode'解码
遗留: minio与S3的'区别'? -->同一个租户的'ak/sk'一致,obsutils'访问'需要这些信息windows上传资源到linux服务器上导致乱码 S3的中文编码问题及修复方案
form表单上传文件指定编码 表单上传中文文件乱码 form表单上传中文文件乱码
python请求multipart/form-data上传文件名含中文报错 文件上传全过程
<form action="/upload" method="post" enctype="multipart/form-data">
选择文件:
<input type="file" name="picture">
<input type="submit" value="提交">
</form>
Content-Disposition: form-data; name="file"; filename="chrome.png"
备注:关于'文件名',抓包'观察'
Content-Type: image/png
常见: form表单'上传'文件的时候,上传的'文件名称'是'乱码' --> "编码和解码"不一致
需求: linux下查看'文件内容'编码,也即'文件编码'
file -i 文件名 #可查看到文件编码格式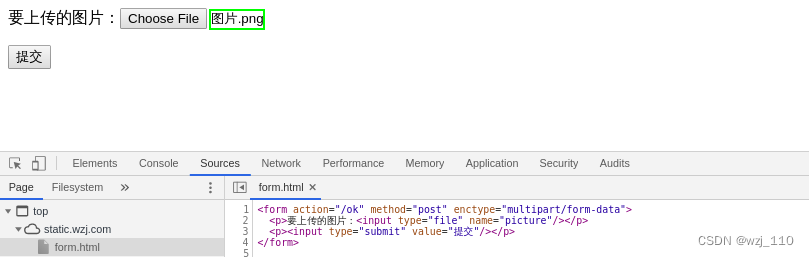
细节点: 利用'form'表单上传文件名为'中文'的图片,暂时没有发现'中文文件名字符被utf-8'编码场景
当时一个'奇怪'现象: '图片.png通过'file'上传后,显示的是'utf-8编码'.png,而'不是'下面的
思考: 可能是在'上传文件'前,'前端'做了'utf-8特殊'处理导致'文件名'被utf-8编码![]()
④ base64编码
分析: 使用 base64 对'图片'进行编码和解码的过程
'编码'流程: --> 编码的目的是为了'网络传输'
1) 先对图片进行 'utf-8 编码' 生成 '二进制'
2) 然后 base64 再对 二进制进行编码,生成 'base64' 字符串
3) linux下 常见 'base64 wzj.jpg' 来实现'图片的base64'编码
其它:
[1]、echo -n 'string' | base64 --> "base64编码"
[2]、echo -n `echo -n 'string' | base64` | base64 -d --> "base64解码"
'解码'流程: --> 编码的目的是为了'可读性展示'
1) 先对 base64字符串 解码 生成 '二进制'
2) 然后使用 utf-8 解码生成'图片'
备注: Java中用于Base64编解码的类有java.util包下的'Base64类'data:协议 Data URL资源base64编码


Data URL scheme 支持的类型
⑤ base64案例
案例1: '基本认证' --> 'Authorization: Basic xxx'
案例2: 'html中嵌入资源' --> "本文讲解复杂的案例"
逻辑: 代码'base64'编码传输,然后'客户端'base64解码执行
玩转图片Base64编码
++++++++++++++++++ "分割线" ++++++++++++++++++
备注: www.google.com 的首页'搜索框右侧的搜索小图标'使用的就是'base64'编码
补充: 迅雷'thunder://'的"专用地址"也是用 Base64 加密的
说明: 这里假定'图片'使用'相对路径'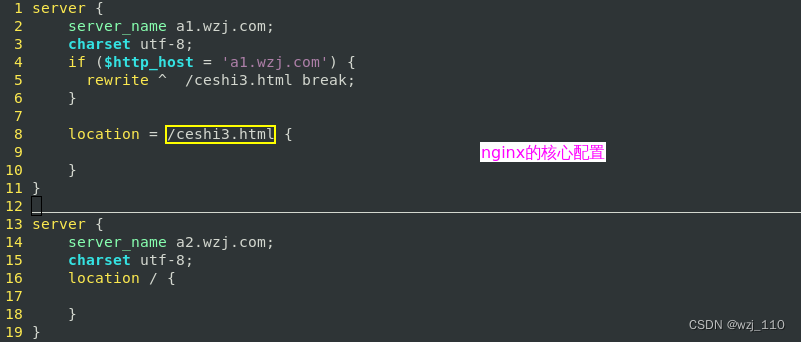
+++++++++ "相关说明" +++++++++
1) 由于使用'internal'内部重定向,产生的'结果'
[1]、在'9s'内不主动点击,地址栏没有'跳转'
[2]、返回了预期的'公告'页面
2) 时间'到了'或者用户'主动点击'进入,产生的'效果'
[1]、前端发起了网络请求,地址栏'发生'变化,也即'域名'跳转重新发起请求
3) ceshi3.html页面在'root'下,内容粗略如下
备注: 这里应该用'随机的字符[不可被碰撞]'代替,然后文件名同该'独一无二'的字符![]()

测试说明: 做好'a1.wzj.com、a2.wzj.com'域名解析,大致效果如下:
⑥ 转义
1) 编码与转义有时容易'混淆',但其实是'不同'的
2) 转义的英文叫'escape';反转义叫unescape
[1]、如C语言中的\n、\t
[2]、以及 HTML、XML 中'特殊符号转义成实体' --> "重点讲解Html中的转义"
强调: html转义是'将特殊字符或html标签'转换为与之对应的浏览器'(HHTP规范)'能识别的'字符'
常见: HTML中将'空格、>、<、&'等符号转换成对应的'HTML实体',称为 'HTML escape'
说明: 实体有实体'名称'和实体'编号'两种形式,它们都是'以&开头','以;结尾'
1、实体名称的形式为'&str;',其中str为字母串 --> "常见"
优点: 易于理解与记忆;
缺点: 浏览器支持'不太好'.如空格的实体名称是 ,>的实体名称是<
2、实体编号的形式为'&#num;',其中num为十进制数字
优点: 是浏览器的支持好,但是不太容易记忆.如空格的实体编号是 ,>的实体名称是>
[3]、mysql的`反引号`转义、正则转义
3) 转义是为了'削除歧义'为什么要转义字符串 html转义字符大全
⑦ 开胃小菜
ps -ef 不显示自己
从抄书到开源之巅:章亦春的程序人生