1、数据库约束
关系型数据库的一个重要功能
主要作用是保证数据的完整性,也就是数据的正确性(数据本身是正确的,关联关系也是正确的)
人工检查数据的完整性的工作量非常的大,在数据表定义一些约束,那数据库在写入数据时,帮我们完成这个工作
1.1、约束类型
*NOT NULL -指示某列不能存储NULL值
*UNIQUE -保证某列的每行必须由唯一的值
*DEFAULT -规定没有给列赋值时的默认值
*PRIMARY KEY - NOT NULL和UNIQUE的结合。确保某列(或两个列多个列的结合)唯一的标识,有助于更容易更快速的找到表中的一个特定的记录
*FOREING KEY - 保证一个表中的数据匹配到另一个表中的值的参照完整性
*CHECK - 保证每列的值都符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
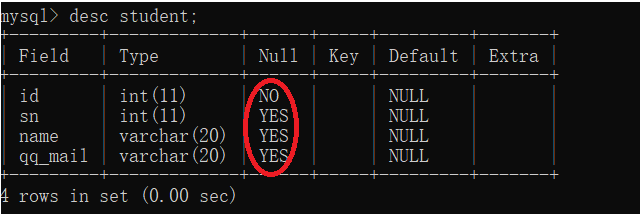
1.2、NULL 约束
*创建表时可以指定某列不能为空
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
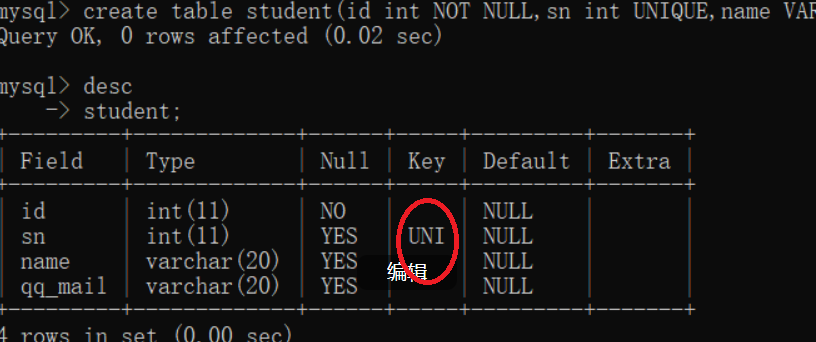
1.3、UNIQUE:唯一约束
保证某列的每一行必须有唯一的值(某一列的值不能重复)
-- 重新设置表结构
DROP TABLE IF EXISTS student;
create table student(
id int NOT NULL,
sn int UNIQUE,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
1.4、DEFAULT:默认值约束
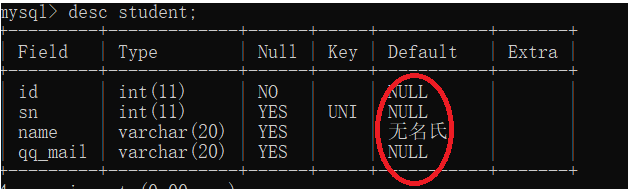
*规定没有给列赋值时的默认值
-- 重新设置表结构
DROP TABLE IF EXISTS student;
create table student(
id int NOT NULL,
sn int UNIQUE,
name VARCHAR(20) DEFAULT '无名氏',
qq_mail VARCHAR(20)
);
1.5、PRIMARY KEY:主键约束
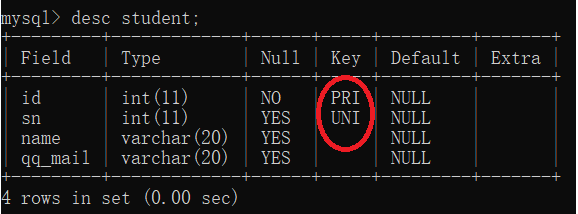
主键帮我们做了两个检验,一个是非空,一个是唯一校验
*指定id列为主键:
-- 重新设置表结构
DROP TABLE IF EXISTS student;
create table student(
id int NOT NULL PRIMARY KEY,
sn int UNIQUE,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
对于整型类型的主键,常搭配auto_increament来使用。插入数据对应字段不给值时,使用最大值+1。
-- 主键是NOT NULL和UNIQUE的结合,可以不使用NOT NULL
id INT PRIMARY KEY auto_increament;
注:
*一个表中不允许有两个主键存在
*一个主键可以包括两个主键(复合主键)
1.6、FOREING KEY:外键约束
表中某个列的值,必须是另一张表中的主键列或是唯一约束列的值,也就是当前表中的值必须在另一张表中存在,且满足主键或唯一约束
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)
示例:
*创建班级表classes,id为主键
-- 创建班级表,有使用MySQL关键字作为字段时,需要使用··来标识
drop table id exists classesl;
create table classes (
id int PRIMARY KEY auto_increment,
name varchar(20),
`desc` VARCHAR(100)
);
*创建学生表,一个学生对应一个班级,一个班级对应多个学生,使用id作为主键,classes_id为外键,关联班级表id
-- 重置学生表结构
drop table if exists student;
create Table student(
id int primary key auto_increment,
sn int UNIQUE,name varchar(20) default '无名氏',
qq_mail varchar(20),
classes_id int,
foreign key(classes_id) references classes(id)
);
2、表的设计
*需要从需求中获取类,类对应的是数据库中的实体,实体在数据库中的表现就是一张一张表,类中的属性就对应数据表中的字段
*根据实体编写SQL语句,DDL,创建具体的数据库,数据表
*设计表的时候会遵循一些范式,一般常说的有三大范式
*分类:第一范式1NF,第二范式2NF,第三范式3NF,BC范式BCNF
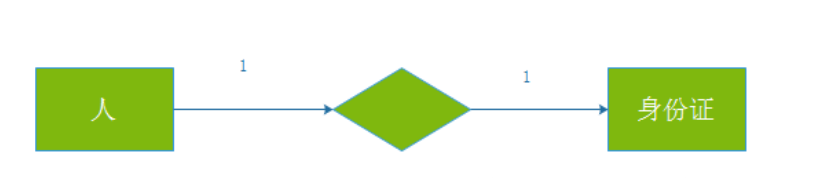
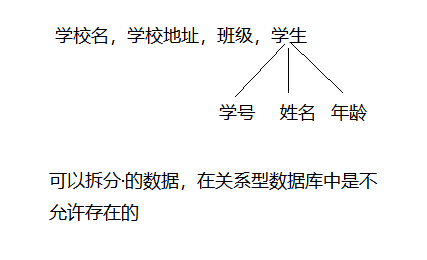
2.1、第一范式(一对一)
关系型数据库的最基本要求,不满足第一范式就不可以称为数据库

2.2、第二范式(一对多)
在满足第一范式的基础上,不存在非关键字段对任意候选字段的部分函数依赖(存在复合主键的情况下)



不满足第二范式可能会出现的问题
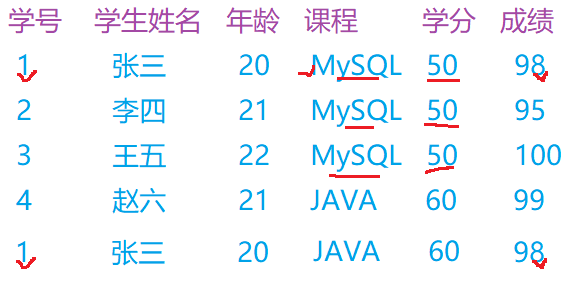
*数据冗余: 学分和学生的姓名年龄都出现了,造成了大量的数据冗余。
*更新异常:如果要调整MySQL的学分,那么就需要更新所有的记录中关于MySQL的条目,如果一旦某些记录更新成功,某些更新失败,那么就会造成同一门课程出现不同分数的情况,数据不一致
*插入异常:每一门课都与学生都有对应的关系,只有同学选修并且通过考试获得了成绩,才可能生成一条记录,也就是一门新课程没有同学出成绩之前是无法写入数据的。
*删除异常:把毕业的同学考试成绩都删除了,删除记录的同时,课程和学分的信息也会被一块删除,导致一段时间内是没有课程和学分的数据信息。
2.3、第三范式(多对多)
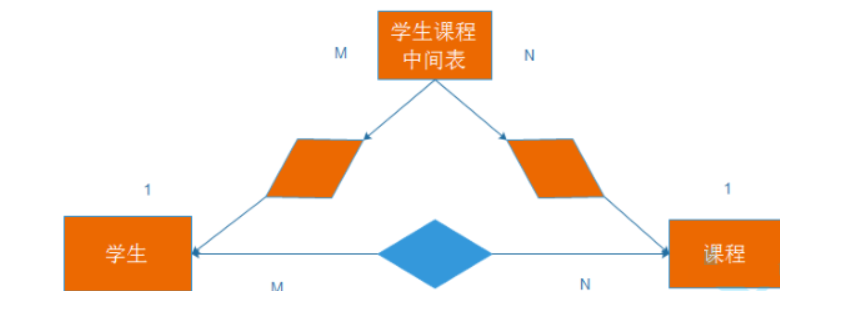
在第二范式的基础上,不存在非关键字段,对任意候选键(可以理解为主键,外键)的传递依赖


满足第三范式对于插入,更新,删除来说都是比较友好的,但是查询效率明显降低
比如说,要查询同学在那个学院,首先要查出来学生记录,再通过学生记录中的学员编号,再去数据库中查询学院信息
*创建课程表
-- 创建课程表
DROP TABLE IF EXISTS course;
CREATE TABLE course (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
*创建学生课程中间表,考试成绩表
DROP TABLE IF EXISTS score;
CREATE TABLE score (
id INT PRIMARY KEY auto_increment,
score DECIMAL(3, 1),
student_id int,
course_id int,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);