依据交易数据集 basket_data.csv挖掘数据中购买行为中的关联规则。
问题分析:
- 如和去对一个数据集进行关联规则挖掘,找到数据集中的项集之间的关联性。
处理步骤:
- 首先导入了两个库,pandas 库和 apyori 库。pandas 库是 Python 用来处理数据的非常常用的库,而 apyori 库则是专门用于进行关联规则挖掘的算法库。 apyori 地址
- 接着读取数据集,将其转换为 DataFrame 对象 df。
- 将 df 中每个交易的商品项聚合成一个列表,存储到 transactions 列表中。这一步是为了将 df 转换为 apyori 库可用的格式。
- 使用 apyori 库提供的关联规则挖掘接口
apriori进行挖掘。其中需要设置最小支持度、最小置信度、最小提升度和最小项集长度等参数。这些参数可以根据具体的应用场景进行调整,本代码中使用的参数值为min_support=0.0025, min_confidence=0.2, min_lift=1.5, min_length=2。 - 最后,遍历挖掘出来的关联规则,将关联规则的结果输出到控制台上。
思考:
- 为了实现效果,首先必须将数据集的格式转换为 apyori 库可用的格式,也就是列表的形式。
- 根据实际应用场景,结合数据集的特点和需求,设置关联规则挖掘参数。
- 所有前期工作准备就绪之后,便开始遍历输出关联规则,查看结果并进行分析。根据输出的每条关联规则及其对应的支持度、置信度和提升度等信息,可以对数据集中的商品项之间的关系进行探索和分析。
代码解析
import pandas as pd
from apyori import apriori
导入 pandas 库,用于对数据进行处理;
导入 apyori 库,用于进行关联规则挖掘。
df = pd.read_csv('basket_data.csv', header=0, sep=',')
读取名为 basket_data.csv (当然也可以是其他的数据)的数据集,存储到名为 df 的 DataFrame 对象中。其中,header=0 表示第一行为列名,sep=‘,’ 表示使用逗号作为分隔符。
transactions = []
temp = df.groupby(['Transaction'])['Item'].apply(list)
for transaction, items in temp.items():
transactions.append(items)
使用 groupby 方法,按照'Transaction'这一列进行分组,并将'Item'这一列变成列表形式,然后将每个数据项添加到 transactions 列表中。
rules = apriori(transactions, min_support=0.0025, min_confidence=0.2, min_lift=1.5, min_length=2)
使用apyori库提供的 apriori 函数进行关联规则挖掘。
transactions 是数据集转换后得到的列表对象,min_support、min_confidence、min_lift 和 min_length 是设定的最小支持度、最小置信度、最小提升度和最小项集长度等参数。
for result in rules:
itemset = list(result.items)
items = []
for item in itemset:
items.append(item)
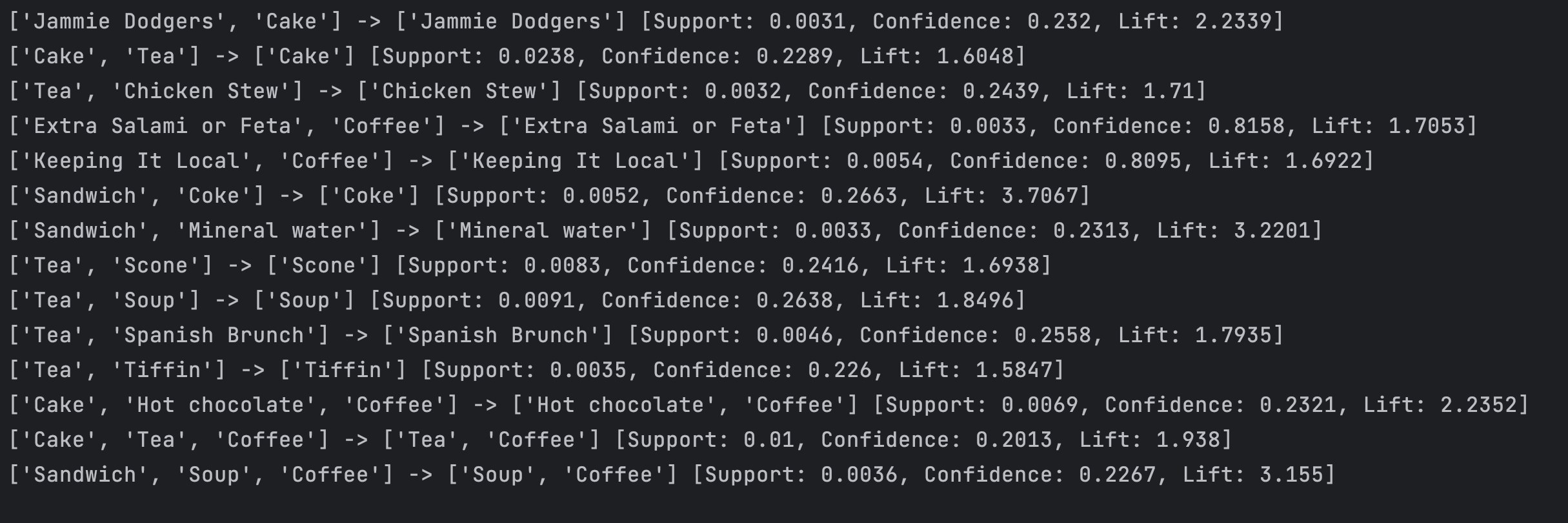
print(str(items) + ' -> ' + str(list(result.ordered_statistics[0].items_base)) + ' [Support: ' + str(round(result.support, 4)) + ', Confidence: ' + str(round(result.ordered_statistics[0].confidence, 4)) + ', Lift: ' + str(round(result.ordered_statistics[0].lift, 4)) + ']')
遍历输出每一条关联规则,其中对于每一条关联规则,将其转换为列表格式并打印出来。
使用ordered_statistics属性获取关联规则的统计信息,并将其转换为字符串形式输出到控制台上。
这些统计信息包括支持度、置信度和提升度等。
完整代码
import pandas as pd
from apyori import apriori
# 读取数据集
df = pd.read_csv('basket_data.csv', header=0, sep=',')
# 转换数据格式
transactions = []
temp = df.groupby(['Transaction'])['Item'].apply(list)
for transaction, items in temp.items():
transactions.append(items)
# 挖掘关联规则
rules = apriori(transactions, min_support=0.0025, min_confidence=0.2, min_lift=1.5, min_length=2)
# 输出关联规则
for result in rules:
# 将结果转换为列表
itemset = list(result.items)
items = []
for item in itemset:
items.append(item)
print(str(items) + ' -> ' + str(list(result.ordered_statistics[0].items_base)) + ' [Support: ' + str(round(result.support, 4)) + ', Confidence: ' + str(round(result.ordered_statistics[0].confidence, 4)) + ', Lift: ' + str(round(result.ordered_statistics[0].lift, 4)) + ']')
运行效果截图
依据数据集 类型预测数据集.csv 进行类型标签预测,标签列为illness。
问题分析
- 读取数据集并进行预处理
- 划分训练集和测试集
- 建立决策树模型并训练模型
- 接收用户输入的特征值
- 对输入的特征值进行编码
- 使用训练好的模型进行预测并输出结果
处理步骤:
-
导入必要的库:
pandas、sklearn.preprocessing中的LabelEncoder和OneHotEncoder、sklearn.tree中的DecisionTreeClassifier和sklearn.model_selection中的train_test_split。然后读取数据集并进行预处理,将标签属性illness转化为数字类型,并对类别属性Sex、BP和Cholesterol进行编码。 -
使用
train_test_split函数将数据集划分为训练集和测试集。这里将数据集的20%作为测试集,并设置随机种子为0,以保证每次运行结果的一致性。 -
建立一个决策树分类器模型
clf,并使用fit函数对模型进行训练。在这里,我们仅使用了默认参数。如果需要更好的预测效果,可以调整模型的参数。 -
通过while循环接收用户输入的特征值,这里涉及到年龄、性别、血压和胆固醇水平以及
Na_to_K(猜测应该是纳钾比例)等属性。这里要注意的是, 用户输入时可能会存在非法输入,例如输入字母或符号,因此需要添加异常处理语句进行捕捉。 -
接下来,对于刚才输入的特征值,我们需要进行编码。
-
使用之前
fit过的OneHotEncoder对象oh_enc对输入数据进行编码,并将其转化为DataFrame格式方便后续的操作。 -
接下来我们用训练好的模型对输入的病人特征值进行预测,并使用
inverse_transform函数将结果转换为标签名,输出到控制台上.
完整代码
# 导入必要的库
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 读取数据集
data = pd.read_csv('类型预测数据集.csv')
# 将标签转换为数字类型
le = LabelEncoder()
data['illness'] = le.fit_transform(data['illness'])
# 对类别属性进行编码
oh_enc = OneHotEncoder(sparse=False)
encoded_cols = oh_enc.fit_transform(data[['Sex', 'BP', 'Cholesterol']])
encoded_cols_df = pd.DataFrame(encoded_cols, columns=oh_enc.get_feature_names_out(['Sex', 'BP', 'Cholesterol']))
data = pd.concat([data, encoded_cols_df], axis=1).drop(['Sex', 'BP', 'Cholesterol'], axis=1)
# 划分训练集和测试集
X = data.drop('illness', axis=1)
y = data['illness']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立决策树模型并训练模型
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X_train, y_train)
# 获取用户输入的属性值,并将其转换为大写字母
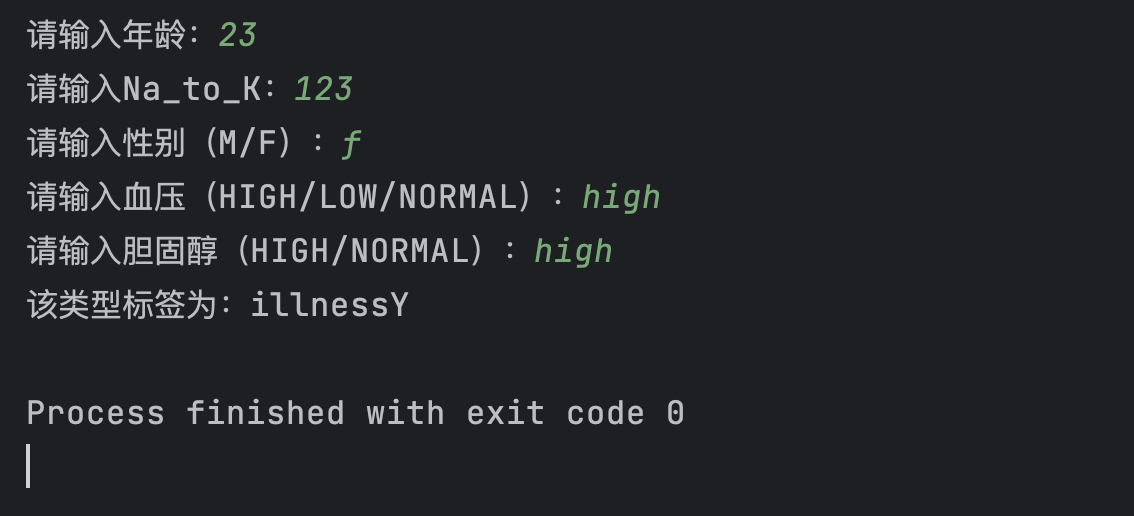
while True:
try:
age = int(input('请输入年龄:'))
na_k = float(input('请输入Na_to_K:'))
break
except ValueError:
print("您的输入无效,请重新输入数字!")
while True:
sex = input('请输入性别(M/F):').upper()
if sex not in ['M', 'F']:
print("您的输入无效,请重新输入!")
else:
break
while True:
bp = input('请输入血压(HIGH/LOW/NORMAL):').upper()
if bp not in ['HIGH', 'LOW', 'NORMAL']:
print("您的输入无效,请重新输入!")
else:
break
while True:
chol = input('请输入胆固醇(HIGH/NORMAL):').upper()
if chol not in ['HIGH', 'NORMAL']:
print("您的输入无效,请重新输入!")
else:
break
# 构造数据行并进行编码
predict_data_row = pd.DataFrame({'Age': [age], 'Sex': [sex], 'BP': [bp],
'Cholesterol': [chol], 'Na_to_K': [na_k]})
predict_data_row = oh_enc.transform(predict_data_row[['Sex', 'BP', 'Cholesterol']])
predict_data_row_df = pd.DataFrame(predict_data_row, columns=oh_enc.get_feature_names_out(['Sex', 'BP', 'Cholesterol']))
predict_data_row = pd.concat([predict_data_row_df, pd.DataFrame({'Age': age, 'Na_to_K': na_k}, index=[0])],
axis=1)[X.columns]
# 预测类型标签
y_pred = clf.predict(predict_data_row)
# 将预测结果转换为标签名
y_pred_name = le.inverse_transform(y_pred)[0]
# 输出预测结果
print('该类型标签为:{}'.format(y_pred_name))
运行结构
警告说明
运行代码是 会有一行警告 如下:

原因是在scikit-learn 1.2版本中,'sparse'参数已被重命名为'sparse_output',并且建议使用'sparse_output'参数代替'sparse'参数 , 所以才会有这个警告, 不过没关系…
数据资料
链接: https://pan.baidu.com/s/1zMZfjYLeEmEHMprP6RwILw 提取码: jxim
–来自百度网盘超级会员v6的分享