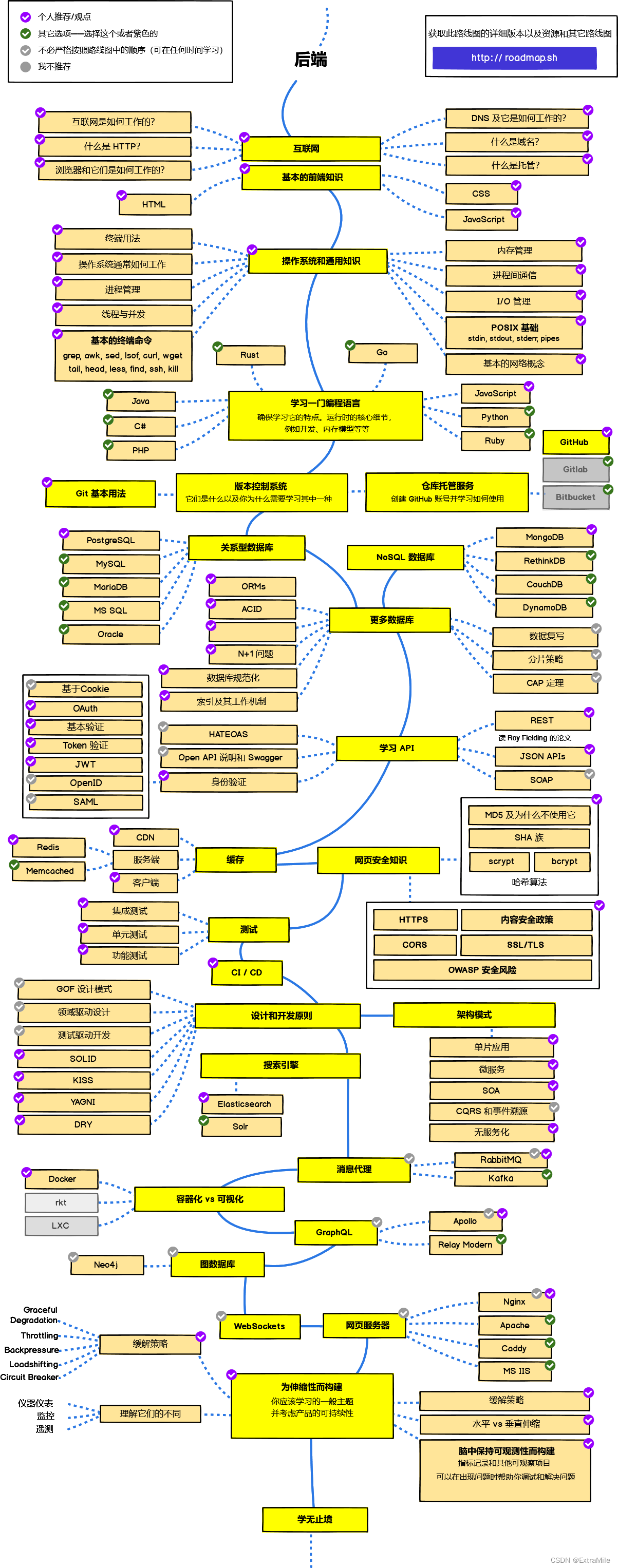
1、Kerberos部署
1.1、Kerberos概述
1.1.1、什么是Kerberos
Kerberos是一种计算机网络认证协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。这个词又指麻省理工学院为这个协议开发的一套计算机软件。软件设计上采用客户端/服务器结构,并且能够进行相互认证,即客户端和服务器端均可对对方进行身份认证。可以用于防止窃听、防止重放攻击、保护数据完整性等场合,是一种应用对称密钥体制进行密钥管理的系统。
1.1.2、Kerberos相关术语
Kerberos中有以下一些概念需要了解:
- KDC(Key Distribute Center):密钥分发中心,负责存储用户信息,管理发放票据。
- Realm:Kerberos所管理的一个领域或范围,称之为一个Realm。
- Principal:Kerberos所管理的一个用户或者一个服务,可以理解为Kerberos中保存的一个账号,其格式通常如下:
primary/instance@realm - keytab:Kerberos中的用户认证,可通过密码或者密钥文件证明身份,keytab指密钥文件。
1.1.3、Kerberos认证原理
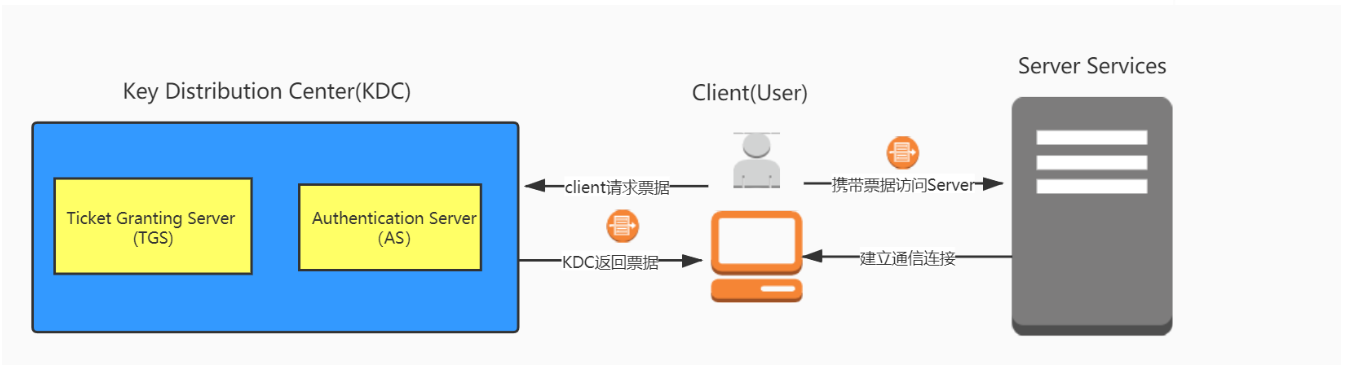
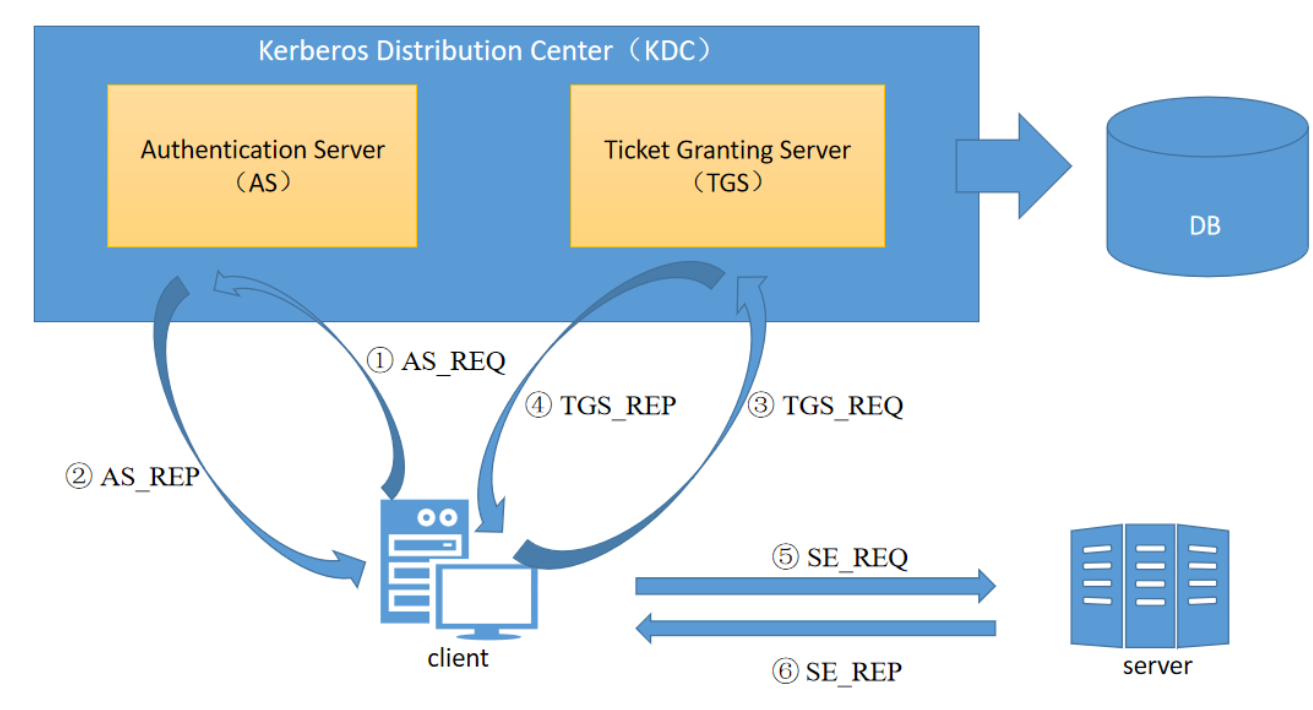
1.1.3.1、Kerberos协议的组成角色
- 客户端(client):发送请求的一方
- 服务端(Server):接收请求的一方
- 密钥分发中心(Key Distribution Center,KDC),而密钥分发中心一般又分为两部分,分别是:
- AS(Authentication Server):认证服务器,专门用来认证客户端的身份并发放客户用于访问TGS的TGT(票据授予票据)
- TGS(Ticket Granting Ticket):票据授予服务器,用来发放整个认证过程以及客户端访问服务端时所需的服务授予票据(Ticket)
1.1.3.2、Kerberos协议的认证流程
所以整个kerberos认证流程大致分为两个阶段,大致描述如下:
客户端在访问想要访问的网络服务时,它需要携带一个专门用于访问该服务并且能够证明自己身份的票据,当服务端收到了该票据他才能认定客户端身份正确,向客户端提供服务。所以整个认证流程可简化为两大步:
- 客户端向KDC请求获取想要访问的目标服务的服务授予票据(Ticket);
- 客户端拿着从KDC获取的服务授予票据(Ticket)访问相应的网络服务;
- 问题1. KDC怎么知道你(客户端)就是真正的客户端?凭什么给你发放服务授予票据(Ticket)呢?
- 问题2. 服务端怎么知道你带来的服务授予票据(Ticket)就是一张真正的票据呢?
整个Kerberos认证的过程更加细致的可以分为三个阶段,也就是三次通信,上面提到整个流程可以简化为两大步,但其实在第一步中共做了两件事,这两件事解决了上述问题中的问题1;然后第二步解决了问题2,最终结束认证过程建立通信。
在具体描述整个认证流程之前,我们需要知道几个Kerberos认证的前提条件:
- kerberos协议他是一个“限权”的认证协议,kerberos中会自带一个数据库,这个数据库会由创建kerberos的运维人员提前在库中添加好整个系统中拥有使用kerberos认证权限的用户和网络服务。在后续的认证中也是根据数据库中是否存在该用户和服务来判断该对象是否能够通过认证服务的。
- 所有使用kerberos协议的用户和网络服务,在他们添加进kerberos系统中时,都会根据自己当前的密码(用户密码,人为对网络服务随机生成的密码)生成一把密钥存储在kerberos数据库中,且kerberos数据库也会同时保存用户的基本信息(例如用户名,用户IP地址等)和网络服务的基本信息(IP,Server Name)
- kerberos中存在的三个角色,只要是发生了两两之间的通信,那么都需要先进行身份的认证。
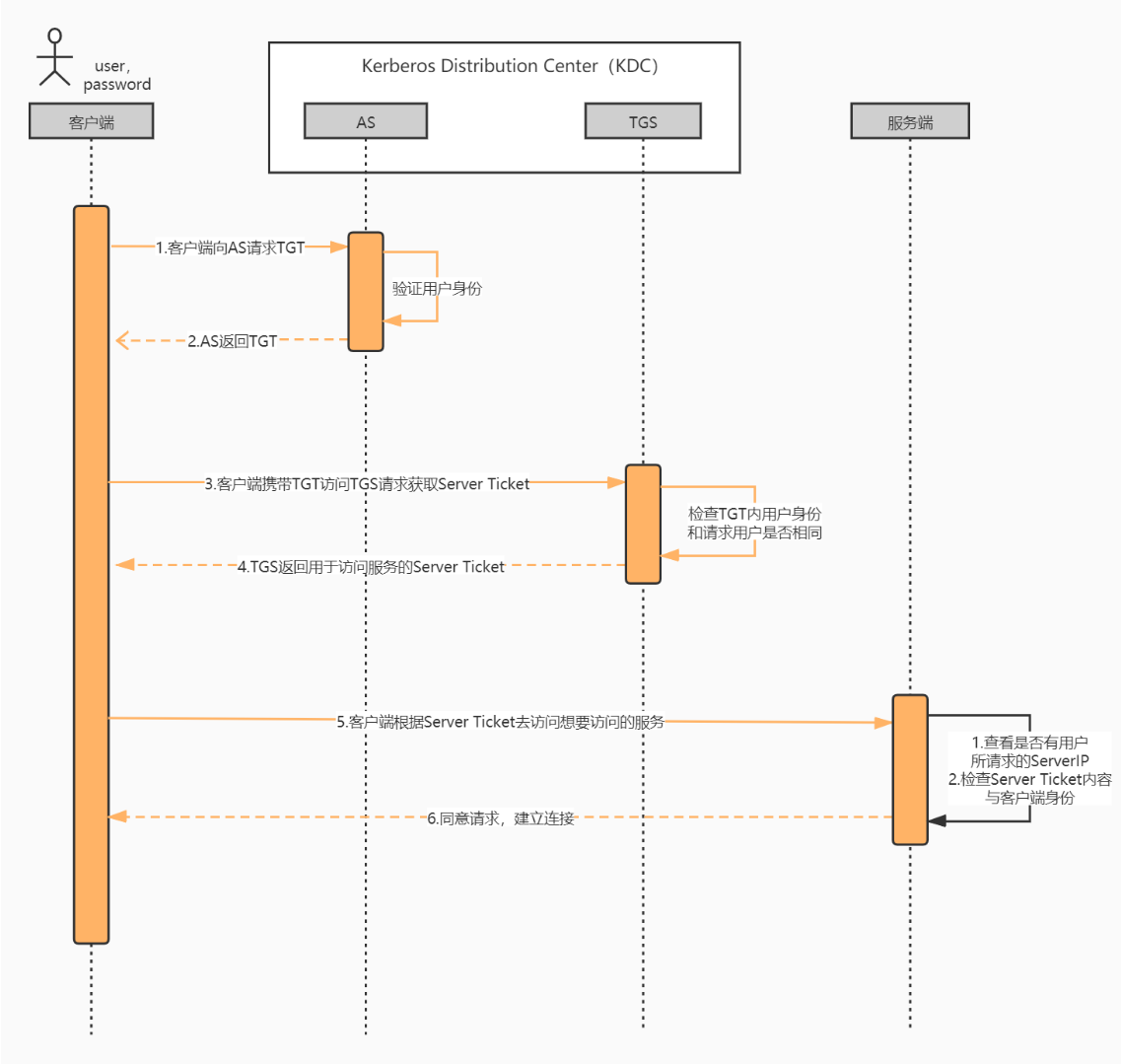
1.1.3.2.1、第一次通信
为了获得能够用来访问服务端服务的票据,客户端首先需要来到KDC获得服务授予票据(Ticket)。由于客户端是第一次访问KDC,此时KDC也不确定该客户端的身份,所以第一次通信的目的为KDC认证客户端身份,确认客户端是一个可靠且拥有访问KDC权限的客户端,过程如下: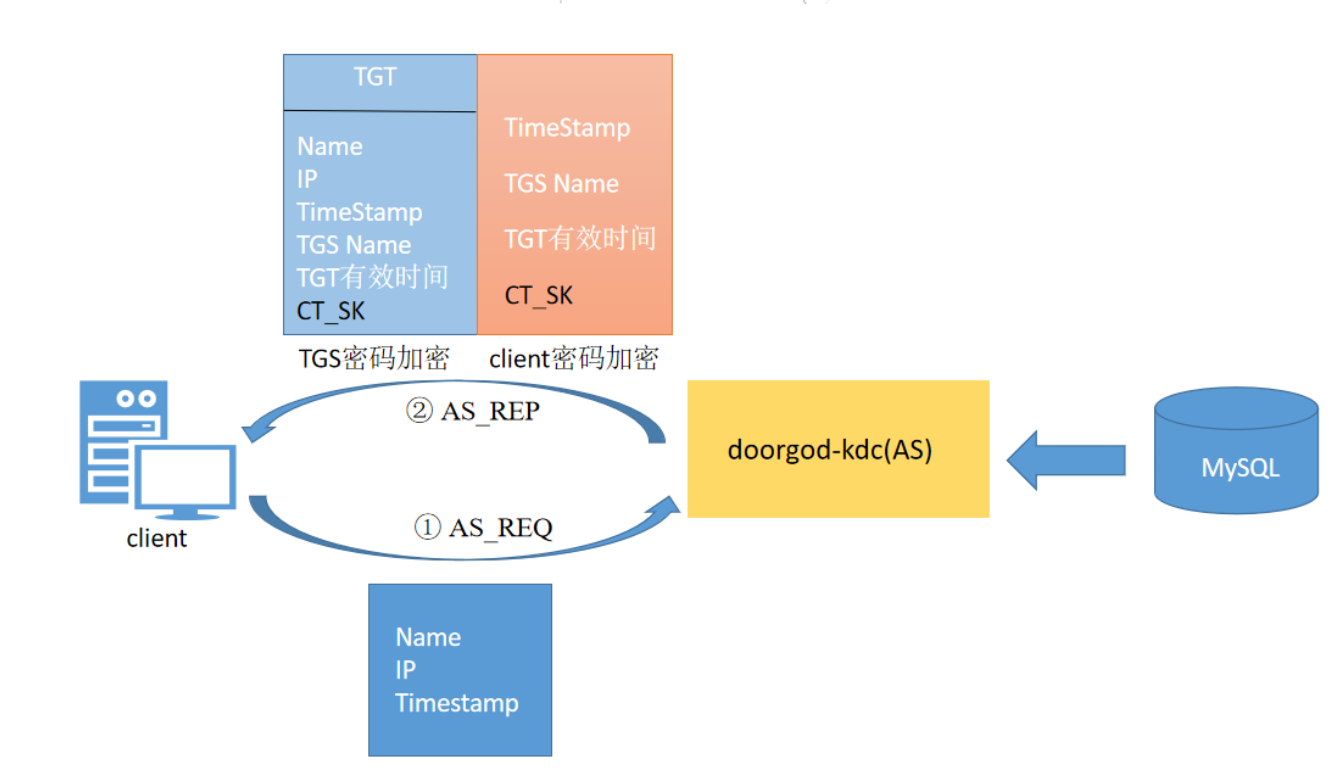
-
客户端用户向KDC以明文的方式发起请求。该次请求中携带了自己的用户名,主机IP,和当前时间戳;
-
KDC当中的AS(Authentication Server)接收请求(AS是KDC中专门用来认证客户端身份的认证服务器)后去kerberos认证数据库中根据用户名查找是否存在该用户,此时只会查找是否有相同用户名的用户,并不会判断身份的可靠性;
-
如果没有该用户名,认证失败,服务结束;如果存在该用户名,则AS认证中心便认为用户存在,此时便会返回响应给客户端,其中包含两部分内容:
- 第一部分内容称为TGT,他叫做票据授予票据,客户端需要使用TGT去KDC中的TGS(票据授予中心)获取访问网络服务所需的Ticket(服务授予票据),TGT中包含的内容有kerberos数据库中存在的该客户端的Name,IP,当前时间戳,客户端即将访问的TGS的Name,TGT的有效时间以及一把用于客户端和TGS间进行通信的Session_key(CT_SK)。整个TGT使用TGS密钥加密,客户端是解密不了的,由于密钥从没有在网络中传输过,所以也不存在密钥被劫持破解的情况。
- 第二部分内容是使用客户端密钥加密的一段内容,其中包括用于客户端和TGS间通信的Session_key(CT_SK),客户端即将访问的TGS的Name以及TGT的有效时间,和一个当前时间戳。该部分内容使用客户端密钥加密,所以客户端在拿到该部分内容时可以通过自己的密钥解密。如果是一个假的客户端,那么他是不会拥有真正客户端的密钥的,因为该密钥也从没在网络中进行传输过。这也同时认证了客户端的身份,如果是假客户端会由于解密失败从而终端认证流程,第一次通信完成。
1.1.3.2.2、第二次通信
此时的客户端收到了来自KDC(其实是AS)的响应,并获取到了其中的两部分内容。此时客户端会用自己的密钥将第二部分内容进行解密,分别获得时间戳,自己将要访问的TGS的信息,和用于与TGS通信时的密钥CT_SK。首先他会根据时间戳判断该时间戳与自己发送请求时的时间之间的差值是否大于5分钟,如果大于五分钟则认为该AS是伪造的,认证至此失败。如果时间戳合理,客户端便准备向TGS发起请求,
其次请求的主要目的是为了获取能够访问目标网络服务的服务授予票据Ticket(进入动物园需要的门票)。 在第二次通信请求中,客户端将携带三部分内容交给KDC中的TGS,第二次通信过程具体如下所述:
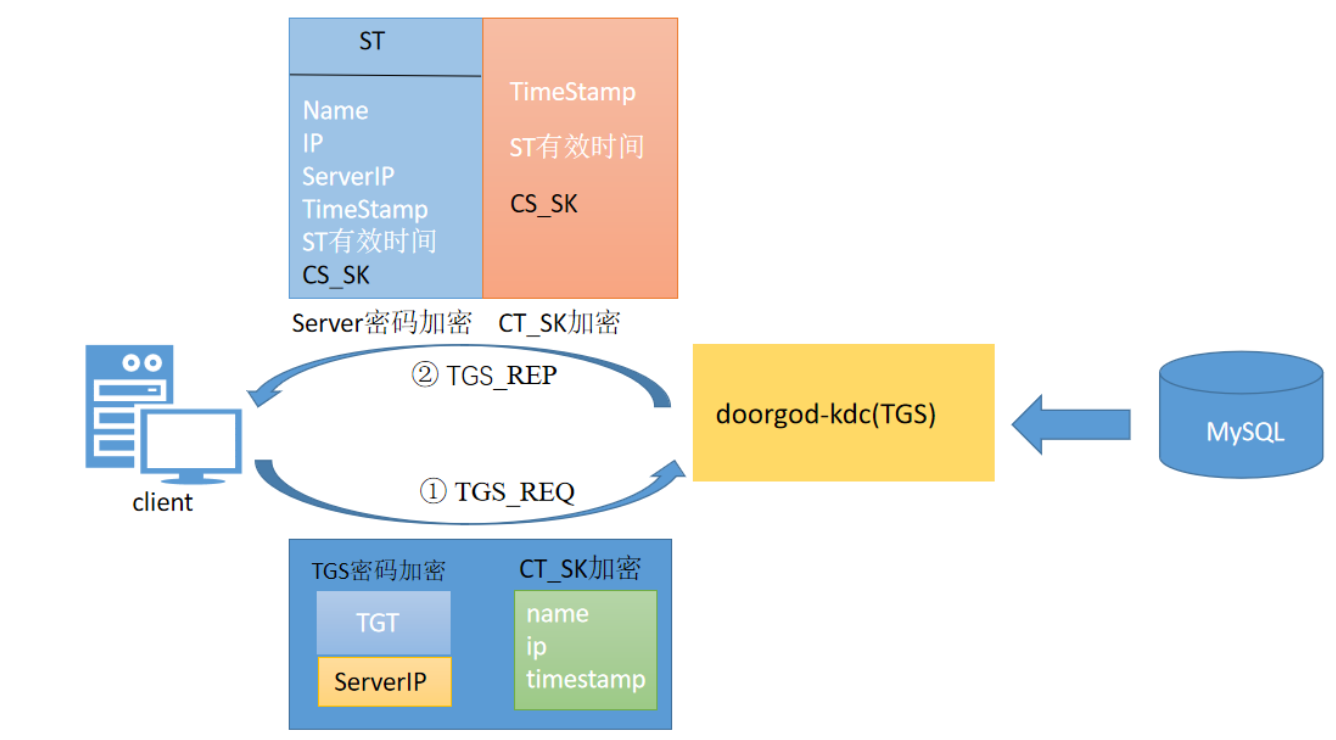
客户端行为:
- 客户端使用CT_SK加密将自己的客户端信息发送给KDC,其中包括客户端名,IP,时间戳;
- 客户端将自己想要访问的Server服务以明文的方式发送给KDC;
- 客户端将使用TGS密钥加密的TGT也原封不动的也携带给KDC;
TGS行为:
- 此时KDC中的TGS(票据授予服务器)收到了来自客户端的请求。他首先根据客户端明文传输过来的Server服务IP查看当前kerberos系统中是否存在可以被用户访问的该服务。如果不存在,认证失败结束,。如果存在,继续接下来的认证。
- TGS使用自己的密钥将TGT中的内容进行解密,此时他看到了经过AS认证过后并记录的用户信息,一把Session_KEY即CT_SK,还有时间戳信息,他会现根据时间戳判断此次通信是否真是可靠有无超出时延。
- 如果时延正常,则TGS会使用CK_SK对客户端的第一部分内容进行解密(使用CT_SK加密的客户端信息),取出其中的用户信息和TGT中的用户信息进行比对,如果全部相同则认为客户端身份正确,方可继续进行下一步。
- 此时KDC将返回响应给客户端,响应内容包括:
- 第一部分:用于客户端访问网络服务的使用Server密码加密的ST(Servre Ticket),其中包括客户端的Name,IP,需要访问的网络服务的地址Server IP,ST的有效时间,时间戳以及用于客户端和服务端之间通信的CS_SK(Session Key)。
- 第二部分:使用CT_SK加密的内容,其中包括CS_SK和时间戳,还有ST的有效时间。由于在第一次通信的过程中,AS已将CT_SK通过客户端密码加密交给了客户端,且客户端解密并缓存了CT_SK,所以该部分内容在客户端接收到时是可以自己解密的。至此,第二次通信完成。
1.1.3.2.3、第三次通信
此时的客户端收到了来自KDC(TGS)的响应,并使用缓存在本地的CT_SK解密了第二部分内容(第一部分内容中的ST是由Server密码加密的,客户端无法解密),检查时间戳无误后取出其中的CS_SK准备向服务端发起最后的请求。
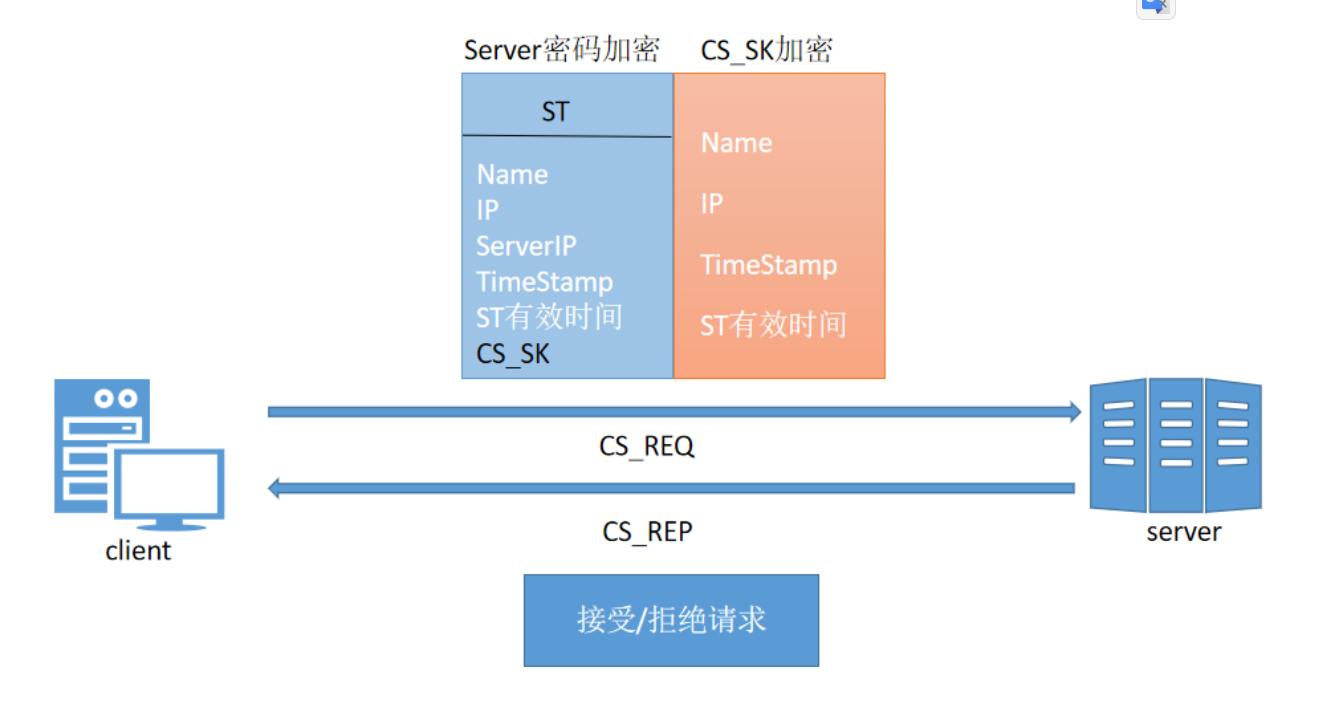
-
客户端:客户端使用CK_SK将自己的主机信息和时间戳进行加密作为交给服务端的第一部分内容,然后将ST(服务授予票据)作为第二部分内容都发送给服务端。
-
服务端:服务器此时收到了来自客户端的请求,他会使用自己的密钥,即Server密钥将客户端第二部分内容进行解密,核对时间戳之后将其中的CS_SK取出,使用CS_SK将客户端发来的第一部分内容进行解密,从而获得经过TGS认证过后的客户端信息,此时他将这部分信息和客户端第二部分内容带来的自己的信息进行比对,最终确认该客户端就是经过了KDC认证的具有真实身份的客户端,是他可以提供服务的客户端。此时服务端返回一段使用CT_SK加密的表示接收请求的响应给客户端,在客户端收到请求之后,使用缓存在本地的CS_ST解密之后也确定了服务端的身份(其实服务端在通信的过程中还会使用数字证书证明自己身份)。
至此,第三次通信完成。此时也代表着整个kerberos认证的完成,通信的双方都确认了对方的身份,此时便可以放心的进行整个网络通信了。
1.1.3.4、Kerberos协议的认证总结
整个kerberos认证的过程较为复杂,三次通信中都使用了密钥,且密钥的种类一直在变化,并且为了防止网络拦截密钥,这些密钥都是临时生成的Session Key,即他们只在一次Session会话中起作用,即使密钥被劫持,等到密钥被破解可能这次会话都早已结束,这为整个kerberos认证过程保证了较高的安全性。
- kerberos认证的整体流图
- kerberos认证的时序图
1.2、Kerberos安装
1.2.1、安装Kerberos相关服务
选择集群中的一台主机(hadoop102)作为Kerberos服务端,安装KDC,所有主机都需要部署Kerberos客户端。
服务端主机执行以下安装命令
[root@hadoop102 ~]# yum install -y krb5-server
客户端主机执行以下安装命令
[root@hadoop102 ~]# yum install -y krb5-workstation krb5-libs
[root@hadoop103 ~]# yum install -y krb5-workstation krb5-libs
[root@hadoop104 ~]# yum install -y krb5-workstation krb5-libs
1.2.2、修改配置文件
- 服务端主机(hadoop102),修改
/var/kerberos/krb5kdc/kdc.conf文件,内容如下
[root@hadoop102 ~]# vim /var/kerberos/krb5kdc/kdc.conf
修改如下内容
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
EXAMPLE.COM = {
#master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal camellia256-cts:normal camellia128-cts:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
}
- 客户端主机(所有主机),修改/etc/krb5.conf文件
[root@hadoop102 ~]# vim /etc/krb5.conf
[root@hadoop103 ~]# vim /etc/krb5.conf
[root@hadoop104 ~]# vim /etc/krb5.conf
内容如下
# Configuration snippets may be placed in this directory as well
includedir /etc/krb5.conf.d/
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
pkinit_anchors = FILE:/etc/pki/tls/certs/ca-bundle.crt
default_realm = EXAMPLE.COM
#default_ccache_name = KEYRING:persistent:%{uid}
[realms]
EXAMPLE.COM = {
kdc = hadoop102
admin_server = hadoop102
}
[domain_realm]
# .example.com = EXAMPLE.COM
# example.com = EXAMPLE.COM
1.2.3、初始化KDC数据库
在服务端主机(hadoop102)执行以下命令,并根据提示输入密码。
[root@hadoop102 ~]# kdb5_util create -s
1.2.4、 修改管理员权限配置文件
在服务端主机(hadoop102)修改/var/kerberos/krb5kdc/kadm5.acl文件,内容如下
*/admin@EXAMPLE.COM *
1.2.5、启动Kerberos相关服务
在主节点(hadoop102)启动KDC,并配置开机自启
[root@hadoop102 ~]# systemctl start krb5kdc
[root@hadoop102 ~]# systemctl enable krb5kdc
在主节点(hadoop102)启动Kadmin,该服务为KDC数据库访问入口
[root@hadoop102 ~]# systemctl start kadmin
[root@hadoop102 ~]# systemctl enable kadmin
1.2.6、创建Kerberos管理员用户
在KDC所在主机(hadoop102),执行以下命令,并按照提示输入密码
[root@hadoop102 ~]# kadmin.local -q "addprinc admin/admin"
1.3、Kerberos使用概述
1.3.1、Kerberos数据库操作
1.3.1.1、登录数据库
- 本地登录(无需认证)
[root@hadoop102 ~]# kadmin.local
Authenticating as principal root/admin@EXAMPLE.COM with password.
kadmin.local:
- 远程登录(需进行主体认证,认证操作见下文)
[root@hadoop102 ~]# kadmin
Authenticating as principal admin/admin@EXAMPLE.COM with password.
Password for admin/admin@EXAMPLE.COM:
kadmin:
退出输入:exit
2. 创建Kerberos主体
登录数据库,输入以下命令,并按照提示输入密码
kadmin.local: addprinc test
也可通过以下shell命令直接创建主体
[root@hadoop102 ~]# kadmin.local -q"addprinc test"
- 修改主体密码
kadmin.local :cpw test
- 查看所有主体
kadmin.local: list_principals
K/M@EXAMPLE.COM
admin/admin@EXAMPLE.COM
kadmin/admin@EXAMPLE.COM
kadmin/changepw@EXAMPLE.COM
kadmin/hadoop105@EXAMPLE.COM
kiprop/hadoop105@EXAMPLE.COM
krbtgt/EXAMPLE.COM@EXAMPLE.COM
1.3.2、Kerberos认证操作
1.3.2.1、密码认证
- 使用kinit进行主体认证,并按照提示输入密码
[root@hadoop102 ~]# kinit test
Password for test@EXAMPLE.COM:
- 查看认证凭证
[root@hadoop102 ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: test@EXAMPLE.COM
Valid starting Expires Service principal
10/27/2019 18:23:57 10/28/2019 18:23:57 krbtgt/EXAMPLE.COM@EXAMPLE.COM
renew until 11/03/2019 18:23:57
1.3.2.2、密钥文件认证
- 生成主体test的keytab文件到指定目录/root/test.keytab
[root@hadoop102 ~]# kadmin.local -q "xst -norandkey -k /root/test.keytab test@EXAMPLE.COM"
注:-norandkey的作用是声明不随机生成密码,若不加该参数,会导致之前的密码失效。
- 使用keytab进行认证
[root@hadoop102 ~]# kinit -kt /root/test.keytab test
- 查看认证凭证
[root@hadoop102 ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: test@EXAMPLE.COM
Valid starting Expires Service principal
08/27/19 15:41:28 08/28/19 15:41:28 krbtgt/EXAMPLE.COM@EXAMPLE.COM
renew until 08/27/19 15:41:28
1.3.2.3、销毁凭证
[root@hadoop102 ~]# kdestroy
[root@hadoop102 ~]# klist
klist: No credentials cache found (ticket cache FILE:/tmp/krb5cc_0)
2、创建Hadoop系统用户
为Hadoop开启Kerberos,需为不同服务准备不同的用户,启动服务时需要使用相应的用户。须在所有节点创建以下用户和用户组。
| User:Group | Daemons |
|---|---|
| hdfs:hadoop | NameNode, Secondary NameNode, JournalNode, DataNode |
| yarn:hadoop | ResourceManager, NodeManager |
| mapred:hadoop | MapReduce JobHistory Server |
创建hadoop组
[root@hadoop102 ~]# groupadd hadoop
[root@hadoop103 ~]# groupadd hadoop
[root@hadoop104 ~]# groupadd hadoop
创建各用户并设置密码
[root@hadoop102 ~]# useradd hdfs -g hadoop
[root@hadoop102 ~]# echo hdfs | passwd --stdin hdfs
[root@hadoop102 ~]# useradd yarn -g hadoop
[root@hadoop102 ~]# echo yarn | passwd --stdin yarn
[root@hadoop102 ~]# useradd mapred -g hadoop
[root@hadoop102 ~]# echo mapred | passwd --stdin mapred
[root@hadoop103 ~]# useradd hdfs -g hadoop
[root@hadoop103 ~]# echo hdfs | passwd --stdin hdfs
[root@hadoop103 ~]# useradd yarn -g hadoop
[root@hadoop103 ~]# echo yarn | passwd --stdin yarn
[root@hadoop103 ~]# useradd mapred -g hadoop
[root@hadoop103 ~]# echo mapred | passwd --stdin mapred
[root@hadoop104 ~]# useradd hdfs -g hadoop
[root@hadoop104 ~]# echo hdfs | passwd --stdin hdfs
[root@hadoop104 ~]# useradd yarn -g hadoop
[root@hadoop104 ~]# echo yarn | passwd --stdin yarn
[root@hadoop104 ~]# useradd mapred -g hadoop
[root@hadoop104 ~]# echo mapred | passwd --stdin mapred
3、Hadoop Kerberos配置
3.1、为Hadoop各服务创建Kerberos主体(Principal)
主体格式如下:ServiceName/HostName@REALM,例如 dn/hadoop102@EXAMPLE.COM
3.1.1、各服务所需主体如下
环境:3台节点,主机名分别为hadoop102,hadoop103,hadoop104
| 服务 | 所在主机 | 主体(Principal) |
|---|---|---|
| User:Group | Daemons | |
| NameNode | hadoop102 | nn/hadoop102 |
| DataNode | hadoop102 | dn/hadoop102 |
| DataNode | hadoop103 | dn/hadoop103 |
| DataNode | hadoop104 | dn/hadoop104 |
| Secondary NameNode | hadoop104 | sn/hadoop104 |
| ResourceManager | hadoop103 | rm/hadoop103 |
| NodeManager | hadoop102 | nm/hadoop102 |
| NodeManager | hadoop103 | nm/hadoop103 |
| NodeManager | hadoop104 | nm/hadoop104 |
| JobHistory Server | hadoop102 | jhs/hadoop102 |
| Web UI | hadoop102 | HTTP/hadoop102 |
| Web UI | hadoop103 | HTTP/hadoop103 |
| Web UI | hadoop104 | HTTP/hadoop104 |
3.1.2、创建主体说明
- 路径准备,为服务创建的主体,需要通过密钥文件keytab文件进行认证,故需为各服务准备一个安全的路径用来存储keytab文件。
[root@hadoop102 ~]# mkdir /etc/security/keytab/
[root@hadoop102 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop102 ~]# chmod 770 /etc/security/keytab/
- 管理员主体认证,为执行创建主体的语句,需登录Kerberos 数据库客户端,登录之前需先使用Kerberos的管理员用户进行认证,执行以下命令并根据提示输入密码。
[root@hadoop102 ~]# kinit admin/admin
- 登录数据库客户端
[root@hadoop102 ~]# kadmin
- 执行创建主体的语句
kadmin: addprinc -randkey test/test
kadmin: xst -k /etc/security/keytab/test.keytab test/test
说明:
- addprinc test/test:作用是新建主体
- addprinc:增加主体
- -randkey:密码随机,因hadoop各服务均通过keytab文件认证,故密码可随机生成
- test/test:新增的主体
- xst -k /etc/security/keytab/test.keytab test/test:作用是将主体的密钥写入keytab文件
- xst:将主体的密钥写入keytab文件
- -k /etc/security/keytab/test.keytab:指明keytab文件路径和文件名
- test/test:主体
- 为方便创建主体,可使用如下命令
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey test/test"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/test.keytab test/test"
说明:
- -p:主体
- -w:密码
- -q:执行语句
- 操作主体的其他命令,可参考官方文档,地址如下:
http://web.mit.edu/kerberos/krb5-current/doc/admin/admin_commands/kadmin_local.html#commands
3.1.3、创建主体
- 在所有节点创建keytab文件目录
[root@hadoop102 ~]# mkdir /etc/security/keytab/
[root@hadoop102 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop102 ~]# chmod 770 /etc/security/keytab/
[root@hadoop103 ~]# mkdir /etc/security/keytab/
[root@hadoop103 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop103 ~]# chmod 770 /etc/security/keytab/
[root@hadoop104 ~]# mkdir /etc/security/keytab/
[root@hadoop104 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop104 ~]# chmod 770 /etc/security/keytab/
- 以下命令在hadoop102节点执行
- NameNode(hadoop102)
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey nn/hadoop102"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nn.service.keytab nn/hadoop102"
- DataNode(hadoop102)
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey dn/hadoop102"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/dn.service.keytab dn/hadoop102"
- NodeManager(hadoop102)
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey nm/hadoop102"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nm.service.keytab nm/hadoop102"
- JobHistory Server(hadoop102)
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey jhs/hadoop102"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/jhs.service.keytab jhs/hadoop102"
- Web UI(hadoop102)
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey HTTP/hadoop102"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/spnego.service.keytab HTTP/hadoop102"
- 以下命令在hadoop103执行
- ResourceManager(hadoop103)
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey rm/hadoop103"
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/rm.service.keytab rm/hadoop103"
- DataNode(hadoop103)
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey dn/hadoop103"
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/dn.service.keytab dn/hadoop103"
- NodeManager(hadoop103)
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey nm/hadoop103"
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nm.service.keytab nm/hadoop103"
- Web UI(hadoop103)
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey HTTP/hadoop103"
[root@hadoop103 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/spnego.service.keytab HTTP/hadoop103"
- 以下命令在hadoop104执行
- DataNode(hadoop104)
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey dn/hadoop104"
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/dn.service.keytab dn/hadoop104"
- Secondary NameNode(hadoop104)
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey sn/hadoop104"
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/sn.service.keytab sn/hadoop104"
- NodeManager(hadoop104)
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey nm/hadoop104"
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nm.service.keytab nm/hadoop104"
- Web UI(hadoop104)
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey HTTP/hadoop104"
[root@hadoop104 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/spnego.service.keytab HTTP/hadoop104"
- 修改所有节点keytab文件的所有者和访问权限
[root@hadoop102 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop102 ~]# chmod 660 /etc/security/keytab/*
[root@hadoop103 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop103 ~]# chmod 660 /etc/security/keytab/*
[root@hadoop104 ~]# chown -R root:hadoop /etc/security/keytab/
[root@hadoop104 ~]# chmod 660 /etc/security/keytab/*
3.2、修改Hadoop配置文件
需要修改的内容如下,修改完毕需要分发所改文件。
- core-site.xml
[root@hadoop102 ~]# vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
增加以下内容
<!-- Kerberos主体到系统用户的映射机制 -->
<property>
<name>hadoop.security.auth_to_local.mechanism</name>
<value>MIT</value>
</property>
<!-- Kerberos主体到系统用户的具体映射规则 -->
<property>
<name>hadoop.security.auth_to_local</name>
<value>
RULE:[2:$1/$2@$0]([ndj]n\/.*@EXAMPLE\.COM)s/.*/hdfs/
RULE:[2:$1/$2@$0]([rn]m\/.*@EXAMPLE\.COM)s/.*/yarn/
RULE:[2:$1/$2@$0](jhs\/.*@EXAMPLE\.COM)s/.*/mapred/
DEFAULT
</value>
</property>
<!-- 启用Hadoop集群Kerberos安全认证 -->
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<!-- 启用Hadoop集群授权管理 -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<!-- Hadoop集群间RPC通讯设为仅认证模式 -->
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
</property>
- hdfs-site.xml
[root@hadoop102 ~]# vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
增加以下内容
<!-- 访问DataNode数据块时需通过Kerberos认证 -->
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<!-- NameNode服务的Kerberos主体,_HOST会自动解析为服务所在的主机名 -->
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>nn/_HOST@EXAMPLE.COM</value>
</property>
<!-- NameNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.namenode.keytab.file</name>
<value>/etc/security/keytab/nn.service.keytab</value>
</property>
<!-- Secondary NameNode服务的Kerberos主体 -->
<property>
<name>dfs.secondary.namenode.keytab.file</name>
<value>/etc/security/keytab/sn.service.keytab</value>
</property>
<!-- Secondary NameNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.secondary.namenode.kerberos.principal</name>
<value>sn/_HOST@EXAMPLE.COM</value>
</property>
<!-- NameNode Web服务的Kerberos主体 -->
<property>
<name>dfs.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- WebHDFS REST服务的Kerberos主体 -->
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- Secondary NameNode Web UI服务的Kerberos主体 -->
<property>
<name>dfs.secondary.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- Hadoop Web UI的Kerberos密钥文件路径 -->
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/etc/security/keytab/spnego.service.keytab</value>
</property>
<!-- DataNode服务的Kerberos主体 -->
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>dn/_HOST@EXAMPLE.COM</value>
</property>
<!-- DataNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.datanode.keytab.file</name>
<value>/etc/security/keytab/dn.service.keytab</value>
</property>
<!-- 配置NameNode Web UI 使用HTTPS协议 -->
<property>
<name>dfs.http.policy</name>
<value>HTTPS_ONLY</value>
</property>
<!-- 配置DataNode数据传输保护策略为仅认证模式 -->
<property>
<name>dfs.data.transfer.protection</name>
<value>authentication</value>
</property>
- yarn-site.xml
[root@hadoop102 ~]# vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
增加以下内容
<!-- Resource Manager 服务的Kerberos主体 -->
<property>
<name>yarn.resourcemanager.principal</name>
<value>rm/_HOST@EXAMPLE.COM</value>
</property>
<!-- Resource Manager 服务的Kerberos密钥文件 -->
<property>
<name>yarn.resourcemanager.keytab</name>
<value>/etc/security/keytab/rm.service.keytab</value>
</property>
<!-- Node Manager 服务的Kerberos主体 -->
<property>
<name>yarn.nodemanager.principal</name>
<value>nm/_HOST@EXAMPLE.COM</value>
</property>
<!-- Node Manager 服务的Kerberos密钥文件 -->
<property>
<name>yarn.nodemanager.keytab</name>
<value>/etc/security/keytab/nm.service.keytab</value>
</property>
- mapred-site.xml
[root@hadoop102 ~]# vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
增加以下内容
<!-- 历史服务器的Kerberos主体 -->
<property>
<name>mapreduce.jobhistory.keytab</name>
<value>/etc/security/keytab/jhs.service.keytab</value>
</property>
<!-- 历史服务器的Kerberos密钥文件 -->
<property>
<name>mapreduce.jobhistory.principal</name>
<value>jhs/_HOST@EXAMPLE.COM</value>
</property>
- 分发以上修改的配置文件
[root@hadoop102 ~]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[root@hadoop102 ~]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
[root@hadoop102 ~]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
[root@hadoop102 ~]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
3.3、配置HDFS使用HTTPS安全传输协议
3.3.1、生成密钥对
Keytool是java数据证书的管理工具,使用户能够管理自己的公/私钥对及相关证书。
- -keystore 指定密钥库的名称及位置(产生的各类信息将存在.keystore文件中)
- -genkey(或者-genkeypair) 生成密钥对
- -alias 为生成的密钥对指定别名,如果没有默认是mykey
- -keyalg 指定密钥的算法 RSA/DSA 默认是DSA
- 生成 keystore的密码及相应信息的密钥库
[root@hadoop102 ~]# keytool -keystore /etc/security/keytab/keystore -alias jetty -genkey -keyalg RSA
输入密钥库口令:
再次输入新口令:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的省/市/自治区名称是什么?
[Unknown]:
该单位的双字母国家/地区代码是什么?
[Unknown]:
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown是否正确?
[否]: y
输入 <jetty> 的密钥口令
(如果和密钥库口令相同, 按回车):
再次输入新口令:
- 修改keystore文件的所有者和访问权限
[root@hadoop102 ~]# chown -R root:hadoop /etc/security/keytab/keystore
[root@hadoop102 ~]# chmod 660 /etc/security/keytab/keystore
注意:
- 密钥库的密码至少6个字符,可以是纯数字或者字母或者数字和字母的组合等等
- 确保hdfs用户(HDFS的启动用户)具有对所生成keystore文件的读权限
- 将该证书分发到集群中的每台节点的相同路径
[root@hadoop102 ~]# xsync /etc/security/keytab/keystore
- 修改hadoop配置文件
ssl-server.xml.example,
该文件位于$HADOOP_HOME/etc/hadoop目录,修改文件名为ssl-server.xml
[root@hadoop102 ~]# mv $HADOOP_HOME/etc/hadoop/ssl-server.xml.example $HADOOP_HOME/etc/hadoop/ssl-server.xml
修改以下内容
[root@hadoop102 ~]# vim $HADOOP_HOME/etc/hadoop/ssl-server.xml
修改以下参数
<!-- SSL密钥库路径 -->
<property>
<name>ssl.server.keystore.location</name>
<value>/etc/security/keytab/keystore</value>
</property>
<!-- SSL密钥库密码 -->
<property>
<name>ssl.server.keystore.password</name>
<value>123456</value>
</property>
<!-- SSL可信任密钥库路径 -->
<property>
<name>ssl.server.truststore.location</name>
<value>/etc/security/keytab/keystore</value>
</property>
<!-- SSL密钥库中密钥的密码 -->
<property>
<name>ssl.server.keystore.keypassword</name>
<value>123456</value>
</property>
<!-- SSL可信任密钥库密码 -->
<property>
<name>ssl.server.truststore.password</name>
<value>123456</value>
</property>
- 分发ssl-server.xml文件
[root@hadoop102 ~]# xsync $HADOOP_HOME/etc/hadoop/ssl-server.xml
3.4、配置Yarn使用LinuxContainerExecutor
- 修改所有节点的
container-executor所有者和权限,要求其所有者为root,所有组为hadoop(启动NodeManger的yarn用户的所属组),权限为6050。其默认路径为$HADOOP_HOME/bin
[root@hadoop102 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/bin/container-executor
[root@hadoop102 ~]# chmod 6050 /opt/module/hadoop-3.1.3/bin/container-executor
[root@hadoop103 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/bin/container-executor
[root@hadoop103 ~]# chmod 6050 /opt/module/hadoop-3.1.3/bin/container-executor
[root@hadoop104 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/bin/container-executor
[root@hadoop104 ~]# chmod 6050 /opt/module/hadoop-3.1.3/bin/container-executor
- 修改所有节点的
container-executor.cfg文件的所有者和权限,要求该文件及其所有的上级目录的所有者均为root,所有组为hadoop(启动NodeManger的yarn用户的所属组),权限为400。其默认路径为$HADOOP_HOME/etc/hadoop
[root@hadoop102 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
[root@hadoop102 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop
[root@hadoop102 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc
[root@hadoop102 ~]# chown root:hadoop /opt/module/hadoop-3.1.3
[root@hadoop102 ~]# chown root:hadoop /opt/module
[root@hadoop102 ~]# chmod 400 /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
[root@hadoop103 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
[root@hadoop103 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop
[root@hadoop103 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc
[root@hadoop103 ~]# chown root:hadoop /opt/module/hadoop-3.1.3
[root@hadoop103 ~]# chown root:hadoop /opt/module
[root@hadoop103 ~]# chmod 400 /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
[root@hadoop104 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
[root@hadoop104 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop
[root@hadoop104 ~]# chown root:hadoop /opt/module/hadoop-3.1.3/etc
[root@hadoop104 ~]# chown root:hadoop /opt/module/hadoop-3.1.3
[root@hadoop104 ~]# chown root:hadoop /opt/module
[root@hadoop104 ~]# chmod 400 /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
- 修改
$HADOOP_HOME/etc/hadoop/container-executor.cfg
[root@hadoop102 ~]# vim $HADOOP_HOME/etc/hadoop/container-executor.cfg
内容如下
yarn.nodemanager.linux-container-executor.group=hadoop
banned.users=hdfs,yarn,mapred
min.user.id=1000
allowed.system.users=
feature.tc.enabled=false
- 修改
$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
[root@hadoop102 ~]# vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
增加以下内容
<!-- 配置Node Manager使用LinuxContainerExecutor管理Container -->
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<!-- 配置Node Manager的启动用户的所属组 -->
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>hadoop</value>
</property>
<!-- LinuxContainerExecutor脚本路径 -->
<property>
<name>yarn.nodemanager.linux-container-executor.path</name>
<value>/opt/module/hadoop-3.1.3/bin/container-executor</value>
</property>
- 分发
container-executor.cfg和yarn-site.xml文件
[root@hadoop102 ~]# xsync $HADOOP_HOME/etc/hadoop/container-executor.cfg
[root@hadoop102 ~]# xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
4、安全模式下启动Hadoop集群
4.1、修改特定本地路径权限
| 服务器地址 | 目录 | 用户:用户组 | 读写权限 |
|---|---|---|---|
| local | $HADOOP_LOG_DIR | hdfs:hadoop | drwxrwxr-x |
| local | dfs.namenode.name.dir | hdfs:hadoop | drwx------ |
| local | dfs.datanode.data.dir | hdfs:hadoop | drwx------ |
| local | dfs.namenode.checkpoint.dir | hdfs:hadoop | drwx------ |
| local | yarn.nodemanager.local-dirs | yarn:hadoop | drwxrwxr-x |
| local | yarn.nodemanager.log-dirs | yarn:hadoop | drwxrwxr-x |
$HADOOP_LOG_DIR(所有节点)
该变量位于hadoop-env.sh文件,默认值为${HADOOP_HOME}/logs
[root@hadoop102 ~]# chown hdfs:hadoop /opt/module/hadoop-3.1.3/logs/
[root@hadoop102 ~]# chmod 775 /opt/module/hadoop-3.1.3/logs/
[root@hadoop103 ~]# chown hdfs:hadoop /opt/module/hadoop-3.1.3/logs/
[root@hadoop103 ~]# chmod 775 /opt/module/hadoop-3.1.3/logs/
[root@hadoop104 ~]# chown hdfs:hadoop /opt/module/hadoop-3.1.3/logs/
[root@hadoop104 ~]# chmod 775 /opt/module/hadoop-3.1.3/logs/
- dfs.namenode.name.dir(NameNode节点)
该参数位于hdfs-site.xml文件,默认值为file://${hadoop.tmp.dir}/dfs/name
[root@hadoop102 ~]# chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/name/
[root@hadoop102 ~]# chmod 700 /opt/module/hadoop-3.1.3/data/dfs/name/
- dfs.datanode.data.dir(DataNode节点)
该参数为于hdfs-site.xml文件,默认值为file://${hadoop.tmp.dir}/dfs/data
[root@hadoop102 ~]# chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/data/
[root@hadoop102 ~]# chmod 700 /opt/module/hadoop-3.1.3/data/dfs/data/
[root@hadoop103 ~]# chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/data/
[root@hadoop103 ~]# chmod 700 /opt/module/hadoop-3.1.3/data/dfs/data/
[root@hadoop104 ~]# chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/data/
[root@hadoop104 ~]# chmod 700 /opt/module/hadoop-3.1.3/data/dfs/data/
- dfs.namenode.checkpoint.dir(SecondaryNameNode节点)
该参数位于hdfs-site.xml文件,默认值为file://${hadoop.tmp.dir}/dfs/namesecondary
[root@hadoop104 ~]# chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/namesecondary/
[root@hadoop104 ~]# chmod 700 /opt/module/hadoop-3.1.3/data/dfs/namesecondary/
- yarn.nodemanager.local-dirs(NodeManager节点)
该参数位于yarn-site.xml文件,默认值为file://${hadoop.tmp.dir}/nm-local-dir
[root@hadoop102 ~]# chown -R yarn:hadoop /opt/module/hadoop-3.1.3/data/nm-local-dir/
[root@hadoop102 ~]# chmod -R 775 /opt/module/hadoop-3.1.3/data/nm-local-dir/
[root@hadoop103 ~]# chown -R yarn:hadoop /opt/module/hadoop-3.1.3/data/nm-local-dir/
[root@hadoop103 ~]# chmod -R 775 /opt/module/hadoop-3.1.3/data/nm-local-dir/
[root@hadoop104 ~]# chown -R yarn:hadoop /opt/module/hadoop-3.1.3/data/nm-local-dir/
[root@hadoop104 ~]# chmod -R 775 /opt/module/hadoop-3.1.3/data/nm-local-dir/
- yarn.nodemanager.log-dirs(NodeManager节点)
该参数位于yarn-site.xml文件,默认值为$HADOOP_LOG_DIR/userlogs
[root@hadoop102 ~]# chown yarn:hadoop /opt/module/hadoop-3.1.3/logs/userlogs/
[root@hadoop102 ~]# chmod 775 /opt/module/hadoop-3.1.3/logs/userlogs/
[root@hadoop103 ~]# chown yarn:hadoop /opt/module/hadoop-3.1.3/logs/userlogs/
[root@hadoop103 ~]# chmod 775 /opt/module/hadoop-3.1.3/logs/userlogs/
[root@hadoop104 ~]# chown yarn:hadoop /opt/module/hadoop-3.1.3/logs/userlogs/
[root@hadoop104 ~]# chmod 775 /opt/module/hadoop-3.1.3/logs/userlogs/
4.2、启动HDFS
需要注意的是,启动不同服务时需要使用对应的用户
4.2.1、单点启动
- 启动NameNode
[root@hadoop102 ~]# sudo -i -u hdfs hdfs --daemon start namenode
- 启动DataNode
[root@hadoop102 ~]# sudo -i -u hdfs hdfs --daemon start datanode
[root@hadoop103 ~]# sudo -i -u hdfs hdfs --daemon start datanode
[root@hadoop104 ~]# sudo -i -u hdfs hdfs --daemon start datanode
- 启动SecondaryNameNode
[root@hadoop104 ~]# sudo -i -u hdfs hdfs --daemon start secondarynamenode
说明:
- -i:重新加载环境变量
- -u:以特定用户的身份执行后续命令
4.2.2、群起
- 在主节点(hadoop102)配置hdfs用户到所有节点的免密登录。
- 修改主节点(hadoop102)节点的
$HADOOP_HOME/sbin/start-dfs.sh脚本,在顶部增加以下环境变量。
[root@hadoop102 ~]# vim $HADOOP_HOME/sbin/start-dfs.sh
在顶部增加如下内容
HDFS_DATANODE_USER=hdfs
HDFS_NAMENODE_USER=hdfs
HDFS_SECONDARYNAMENODE_USER=hdfs
注:$HADOOP_HOME/sbin/stop-dfs.sh也需在顶部增加上述环境变量才可使用。
- 以root用户执行群起脚本,即可启动HDFS集群。
[root@hadoop102 ~]# start-dfs.sh
- 查看HFDS web页面,访问地址为
https://hadoop102:9871
4.3、修改HDFS特定路径访问权限
| 用户 | 路径 | 用户:用户组 | 读写权限 |
|---|---|---|---|
| hdfs | / | hdfs:hadoop | drwxr-xr-x |
| hdfs | /tmp | hdfs:hadoop | drwxrwxrwxt |
| hdfs | /user | hdfs:hadoop | drwxrwxr-x |
| hdfs | yarn.nodemanager.remote-app-log-dir | yarn:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.intermediate-done-dir | mapred:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.done-dir | mapred:hadoop | drwxrwx— |
说明:若上述路径不存在,需手动创建
- 创建hdfs/hadoop主体,执行以下命令并按照提示输入密码
[root@hadoop102 ~]# kadmin.local -q "addprinc hdfs/hadoop"
- 认证hdfs/hadoop主体,执行以下命令并按照提示输入密码
[root@hadoop102 ~]# kinit hdfs/hadoop
- 按照上述要求修改指定路径的所有者和权限
- 修改/、/tmp、/user路径
[root@hadoop102 ~]# hadoop fs -chown hdfs:hadoop / /tmp /user
[root@hadoop102 ~]# hadoop fs -chmod 755 /
[root@hadoop102 ~]# hadoop fs -chmod 1777 /tmp
[root@hadoop102 ~]# hadoop fs -chmod 775 /user
- 参数yarn.nodemanager.remote-app-log-dir位于yarn-site.xml文件,默认值/tmp/logs
[root@hadoop102 ~]# hadoop fs -chown yarn:hadoop /tmp/logs
[root@hadoop102 ~]# hadoop fs -chmod 1777 /tmp/logs
- 参数
mapreduce.jobhistory.intermediate-done-dir位于mapred-site.xml文件,默认值为/tmp/hadoop-yarn/staging/history/done_intermediate,需保证该路径的所有上级目录(除/tmp)的所有者均为mapred,所属组为hadoop,权限为770
[root@hadoop102 ~]# hadoop fs -chown -R mapred:hadoop /tmp/hadoop-yarn/staging/history/done_intermediate
[root@hadoop102 ~]# hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging/history/done_intermediate
[root@hadoop102 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/
[root@hadoop102 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/
[root@hadoop102 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/
[root@hadoop102 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/history/
[root@hadoop102 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/
[root@hadoop102 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/
- 参数
mapreduce.jobhistory.done-dir位于mapred-site.xml文件,默认值为/tmp/hadoop-yarn/staging/history/done,需保证该路径的所有上级目录(除/tmp)的所有者均为mapred,所属组为hadoop,权限为770
[root@hadoop102 ~]# hadoop fs -chown -R mapred:hadoop /tmp/hadoop-yarn/staging/history/done
[root@hadoop102 ~]# hadoop fs -chmod -R 750 /tmp/hadoop-yarn/staging/history/done
[root@hadoop102 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/
[root@hadoop102 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/
[root@hadoop102 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/
[root@hadoop102 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/history/
[root@hadoop102 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/
[root@hadoop102 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/
4.4、启动Yarn
- 单点启动,启动ResourceManager
[root@hadoop103 ~]# sudo -i -u yarn yarn --daemon start resourcemanager
启动NodeManager
[root@hadoop102 ~]# sudo -i -u yarn yarn --daemon start nodemanager
[root@hadoop103 ~]# sudo -i -u yarn yarn --daemon start nodemanager
[root@hadoop104 ~]# sudo -i -u yarn yarn --daemon start nodemanager
- 群起
- 在Yarn主节点(hadoop103)配置yarn用户到所有节点的免密登录。
- 修改主节点(hadoop103)的$HADOOP_HOME/sbin/start-yarn.sh,在顶部增加以下环境变量。
[root@hadoop103 ~]# vim $HADOOP_HOME/sbin/start-yarn.sh
在顶部增加如下内容
YARN_RESOURCEMANAGER_USER=yarn
YARN_NODEMANAGER_USER=yarn
注:stop-yarn.sh也需在顶部增加上述环境变量才可使用。
- 以root用户执行
$HADOOP_HOME/sbin/start-yarn.sh脚本即可启动yarn集群。
[root@hadoop103 ~]# start-yarn.sh
- 访问Yarn web页面,访问地址为
http://hadoop103:8088
4.5、启动HistoryServer
- 启动历史服务器
[root@hadoop102 ~]# sudo -i -u mapred mapred --daemon start historyserver
- 查看历史服务器web页面,访问地址为
http://hadoop102:19888