regexp检查总是返回0(没有匹配)或者1(匹配)
一、CASE表达式
1.两种写法
①简单case表达式
case sex
when '1' then '男'
when '2' then '女'
else '其他'
end
②搜索case表达式
case
when sex = '1' then '男'
when sex = '2' then '女'
else '其他'
end
以上两种写法结果相同,但是简单case表达式写法简单能实现的事情有限。
注:当when子句判断符合条件时,剩余子句不再进行。类似于java的continue。
注:不写else子句也是可以的,但是当所有条件不满足时,会返回结果null。
对case转换前的列进行group by得不到正确结果,需要对group by 也进行相同的case转换。
可以给case转换后的列定义别名,对别名进行group by就简单些。因为group by比select先执行,所以这样写并不被允许,如在Oracle和Sql server中会出错,但是Mysql不会。这是因为mysql在执行时会先对select子句里的列进行扫描。
case表达式可以判断表达式,如使用between、like、<、>、还可以使用in、exists等嵌套查询子句。
3.使用
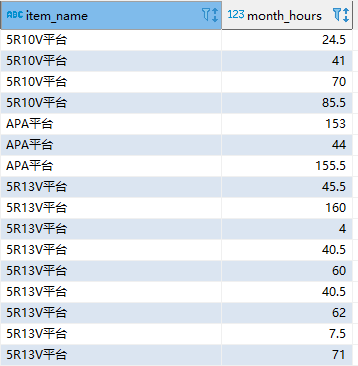
需求,同一个平台month_hours>= 24为饱和,否则为不饱和
需要统计这个平台饱和的数量和不饱和的数量
select
item_name,
sum(case when month_hours >= 24 then 1 end) as saturation,
sum(case when month_hours < 24 then 1 end) as no_saturation
from
t_user_item_hours_m
group by
item_code
二、自连接
1.在SQL里,只要给数据库表赋别名,即使是相同的表也会当作不同的表来处理。
2.当数据值中有null值时,不要使用in,应该使用exists
all实际是以多个and连接的省略写法,所以要注意null的情况
极值函数在统计时会把值为null的数据排除掉,极值函数如min,max
但是意义不同:
all:年龄比所以人都小
极值函数:年龄比最小的还小
极值函数对结果是空表会返回null
count以外的聚合函数对结果是空表会返回null
3.group by 是将一张表按照某列的不同值将表划分为一个个子集
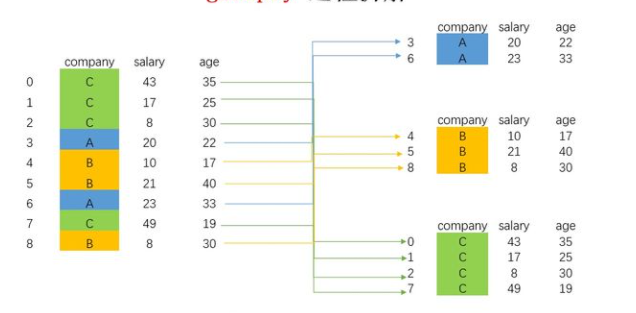
如图,根据company分组
4.count(*) ,count(列名)区别:
一个是性能的区别,另一个是count(*)可以用于null,而count(列名)会先排除null再统计。
5.union:会去重,重复记录是指查询中各个字段完全重复的记录
union all:不会去重,所以效率高
6.外连接

NULL表示未知,所以在和任何其他值进行匹配时候都是返还的未知,所以在连接查询的时候 ON 条件后返回的是两个表的该记录是否匹配,结果需要true or false,当遇到NULL值,返回的是未知,所以不会返回数据。这是在连接查询时候切记。
7.一对多
假设两张表,一张水果种类表,一张各大超市各种水果销量表,现在要求各种水果总销量
方法①:
先对水果销量表进行种类分组求销量和再外连接水果种类表。
但是这样性能是有一定影响的,先对水果销量表进行处理后生成的临时视图存储在内存中且没有主键索引,所以无法进行索引优化。
方法②:
水果种类和水果销量表中的水果种类数据其实是一对多的关系,所以可以先进行一对多外连接再进行分组查询。
一对一或一对多的两个集合,在进行连接操作后行数不会异常地增加。
8.数字不连续求小于它的最接近的数字
步骤:①求小于它的数字;②使用max函数
函数的重要性:max函数和min函数
三、视图和临时表
1.视图
从SQL的角度来看,视图就是一张表,存在表名、字段列。视图和实体表的区别就在与:是否保存了实际数据。
视图本身是一个不含任何数据的虚拟表,数据库中存放视图的定义(保存好的SELECT语句),而不存放视图对应的数据。
使用实体表创建视图后,实体表中的数据发生变化,视图查询出的数据就会发生变化。这是因为视图每次使用时,都会调用创建视图时的SQL查询语句,所有相当于每次使用都会更新视图。
视图不是表,视图是虚表。
2.创建视图
create [or replace] view view_name
As
select_statement //sql查询语句
视图的使用和普通表一样直接使用视图名即可。
3.删除视图
DROP VIEW view_name
4.临时表
临时表是一个保存了实际数据的表。
临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
5.创建临时表
CREATE TEMPORARY TABLE 临时表名 AS
select_statement //sql查询语句
当然,也可以用创建普通表的语句创建临时表,唯一区别就是要加上TEMPORARY 。
6.区别
视图可以一直存在。临时表存在于它被创建的整个数据库会话过程中,下次会话就不存在了。
视图只存在于单个查询当中,每次使用该视图名,其虚拟表就会根据现有的数据重新被创建。临时表不会主动更新。
视图效率一般,因为都是每次用的时候才会查,而临时表效率更好,缺点就是临时表数据可能是旧的。
在一个查询SQL里面只能使用一次临时表。临时表不方便。
例:
SELECT *
FROM test t1, test t2
WHERE t1.task_code = t2.task_code;
test是一个临时表,当在一个sql里使用多次test时会报错Can't reopen table: 'test'
7.with介绍
WITH语句的作用是创建一个或多个临时命名结果集,这些结果集可以被后续语句引用。
语法:
WITH cte_name (column_list) AS (
SELECT ...
)
SELECT ...
cte_name是临时命名结果集的名称,column_list是该结果集的列名列表,可以省略。WITH语句中使用的SELECT语句可以是任意有效的查询语句,包括聚合函数、联结等操作。
例:
with t1 as (
select
task_code,
task_name
from
veh_task vt)
select
*
from
t1
WITH 和 temporary 临时表的主要区别
作用范围:WITH 子句生成的临时表(Common Table Expression, CTE)仅在当前查询中有效,在查询执行后即会被销毁。而 temporary 临时表可供所有会话和用户使用,只有在会话或连接关闭后才会被销毁。
使用方式:使用 WITH 子句生成的临时表(CTE)可直接集成在 SQL 查询中,在逻辑上将其视为一个子查询。而 temporary 临时表则需要通过 CREATE TEMPORARY TABLE 语句显式创建,并在使用后通过 DROP TEMPORARY TABLE 语句显式销毁。
执行时机:CTE 是在执行查询之前计算的,而 temporary 临时表是在查询执行时创建的。
执行效率:由于 CTE 不需要在磁盘上创建物理表,因此其生成速度通常比 temporary 临时表更快。但在一些情况下,temporary 临时表也可以以流的方式进行处理,从而提高查询性能。
一个SQL里的重复使用:CTE可以,temporary 临时表不可以。
with t1 as (
select
task_code,
task_name
from
veh_task vt)
select
*
from
t1
inner join t1 as t2 on
t1.task_code = t2.task_code;
8.关于递归查询
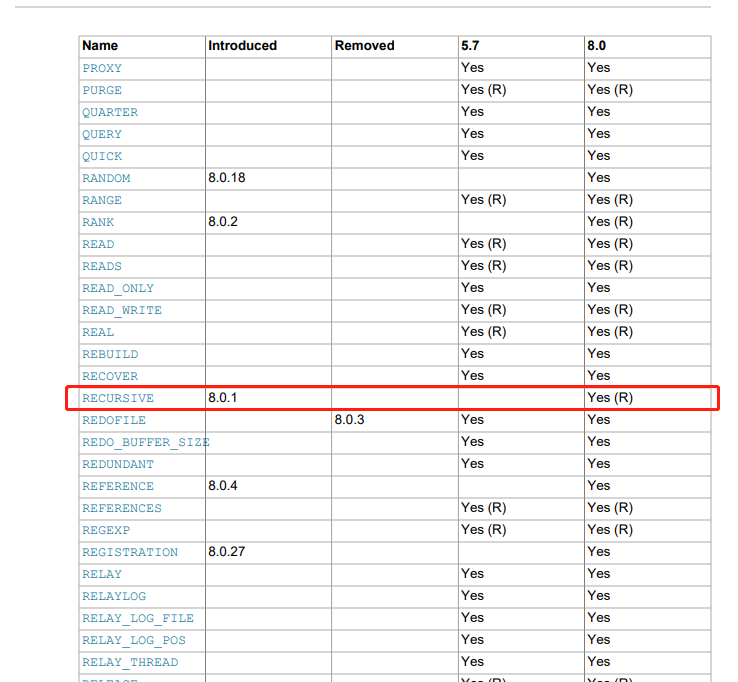
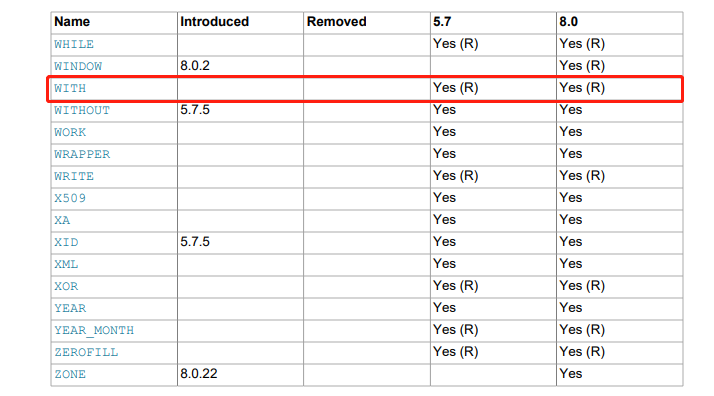
RECURSIVE是MySQL8.0以后引入的,用于在CTE中实现递归查询。当需要进行递归查询时,可以在WITH语句中使用RECURSIVE关键字,并使用UNION ALL语句来实现递归操作。
WITH RECURSIVE sub_depts(dept_id, dept_name) AS (
SELECT dept_id, dept_name
FROM sys_depart
WHERE dept_id = X
UNION ALL
SELECT sd.dept_id, sd.dept_name
FROM sub_depts sd
JOIN sys_depart d ON sd.dept_id = d.parent_id
)
SELECT dept_id, dept_name
FROM sub_depts;
MySQL8.0之前的递归: