序列化与反序列化深入理解
- 1 介绍
- 1.1 概述
- 1.2 序列化实现的需求
- 2 常用序列化实现
- 函数序列化
- 语言内置
- 开源序列化实现
- 3 各序列化实现比较
- 4 各序列化实现概述
- XML
- JSON
- Protobuf
- Java 内置
- TLV
- VLE(Variable Length Encoding)
- 5 flex & bison
- 5.1 介绍
- 应用
- 解释器
- IDL
- 介绍
- IDL编译器
- 参考
1 介绍
1.1 概述
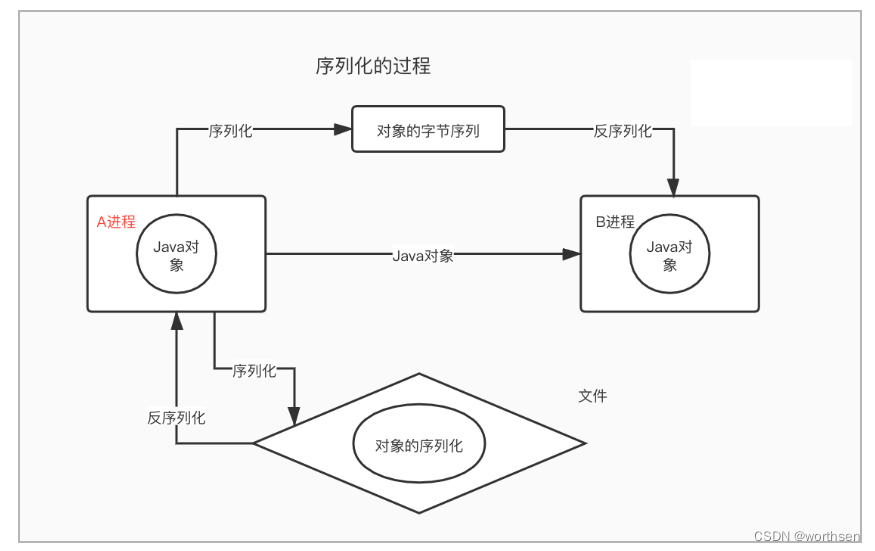
- 数据传输中,双方交互都需要对数据进行序列化和反序列化。也称为编码和解码。
- 网络传输中,传输数据的基本形式就是二进制流,也就是一段一段的1和0。数据读取形式是字节,也就是Byte。具体粘包拆包后,是按字符串、结构体、JSON还是protobuf等形势序列化,看程序设计。
- 结构化的数据与字节流之间的双向转换,将结构化数据转换成字节流的过程,称为序列化,反过来转换,就是反序列化。序列化的用途除了用于在网络上传输数据以外,另外一个重要用途是,将结构化数据保存在文件中。
- 序列化无处不在:
-
- CPU:数据被序列化成 little endian / big endian
-
- GPU:vertex buffer
-
- 内存:字节流
-
- 磁盘/网络:JSON,YAML,MessagePack,protobuf,FlatBuffer,,以及所有的网络协议

- 磁盘/网络:JSON,YAML,MessagePack,protobuf,FlatBuffer,,以及所有的网络协议
1.2 序列化实现的需求
- 可读性:序列化后的数据最好是易于人类阅读的;
- 复杂度:实现的复杂度是否足够低;
- 性能水平:性能包括两个方面,时间复杂度和空间复杂度。序列化和反序列化的速度越快越好;空间开销(Verbosity)和时间开销(Complexity)都越小越好。
- 信息密度:序列化后的信息密度越大越好,也就是说,同样的一个结构化数据,序列化之后占用的存储空间越小越好;
- 通用性:技术层面,序列化协议是否支持跨平台、跨语言;流行程度,是否被大量使用;
- 健壮性:是否稳定。
2 常用序列化实现
函数序列化
函数之间通过栈来交流:调用者把参数序列化到栈上,被调者将其反序列化出来。

语言内置
Java 和 Go 语言都内置了序列化实现。
Java 语言中提供的 Serializable 接口,此外还有 Android 提供的 Parcelable 接口。
开源序列化实现
Google 的 Protobuf、Kryo、Hessian 等;
此外,像 JSON、XML 这些标准的数据格式,也可以作为一种序列化实现来使用。
3 各序列化实现比较
| 序列化实现 | 优点 | 缺点 | 备注 |
|---|---|---|---|
| JSON | 可读性很好,使用简单 | 信息密度很低 | 文本 |
| XML | 可读性很好,使用简单 | 信息密度也很低 | 文本,XML 所产生序列化之后文件比JSON大 |
| SOAP | 可读性很好,使用简单 | 信息密度也很低 | 文本 |
| Kryo | 适用范围广,使用简单 | 信息密度稍高 | 二进制序列化 |
| Hessian | 适用范围广,使用简单 | 信息密度稍高 | 二进制序列化 |
| protobuf | 信息密度高 | 使用更复杂 | 二进制序列化,可伸缩性的数据类型 |
| java | 信息密度高 | 语言内置 | 二进制序列化,数据类型固定长度 |
| TLV(Type-Length-Value) | 信息密度较高,容易解析 | 自定义,通用差 | 二进制序列化 |
4 各序列化实现概述
XML
XML 是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点。
JSON
JSON 起源于弱类型语言 Javascript, 它的产生来自于一种称之为"Associative array"的概念,其本质是就是采用"Attribute-value"的方式来描述对象。实际上在 Javascript 和 PHP 等弱类型语言中,类的描述方式就是 Associative array。
这是因为 JSON 是上下文极其相关的,在上一个 token 解析完成之前,你无法解析下一个 token,所以效率慢。
Protobuf
- 序列化数据非常简洁,紧凑,与 XML 相比,其序列化之后的数据量约为 1/3 到 1/10。
- 解析速度非常快,比对应的 XML 快约 20-100 倍。
- 提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
- Protobuf 是非常高效的序列化协议。
- Protobuf 提供了可伸缩性的数据类型(int 1-5字节)。
Java 内置
Java是数据类型固定长度的序列化(int 4字节, long 8字节)。
TLV
TLV: TLV是指由数据的类型Tag,数据的长度Length,数据的值Value组成的结构体,几乎可以描任意数据类型,TLV的Value也可以是一个TLV结构,正因为这种嵌套的特性,可以让我们用来包装协议的实现。

VLE(Variable Length Encoding)
Variable Length Encoding(VLE):Type 的长度和 Length 的长度都是可变的,且最常用的我们用最小的比特位为其序列化。比如 protobuf 就采用了 VLE 的方式。
message Person {
string user_name = 1;
int64 favorite_number = 2;
string interests = 3;
}
因为 protobuf 定义的字段是可选的,所以这里光靠 TLV 还不够,还需要每个字段的 tag,这就是为什么 protobuf 需要为每个字段提供序号,并且序号不可重复:

5 flex & bison
5.1 介绍
Flex and bison就是lex and yacc的升级版。Lex 代表 Lexical Analyzar。Yacc 代表 Yet Another Compiler Compiler。
Flex和bison是两个用来生成程序的工具,它们生成的程序分别叫做词法分析器和语法分析器。

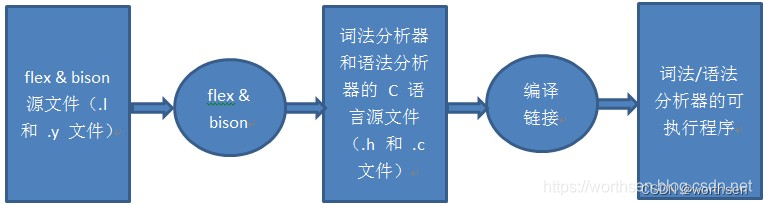
Flex生成的词法分析器将输入拆分成一个个记号(token),bison生成的语法分析器根据已有的规则,分析这些token的组合,是否符合语法规范。

应用
解释器
各行业使用的解释器,如有的协作机械臂图形编程中解释器
IDL
介绍
IDL的全称是Interface Definition Language,即接口定义语言(有时也叫作接口描述语言)。因为RPC通常是跨进程、跨机器、跨系统和跨语言的,IDL是用来解决这个问题的,它与语言无关,借助编译器将它翻译成不同的编程语言。
Google开源的ProtoBuf中的“.proto”文件就是一种IDL文件。
IDL编译器
IDL中定义接口、函数和数据等,需要在发送前编码成字节流,在收到后进行解码。比如将函数名、参数类型和参数值等编码成字节流,然后发送给对端,然后对端进行解码,还原成函数调用。ProtoBuf就是一个非常好的编解码工具。
- protobuf 中底层有用flex & bison
- opensplice DDS中底层有用flex & bison
- RTI DDS中底层有用flex & bison
- Fast DDS中底层有用flex & bison
参考
1、linux–Flex and Bison
2、12 序列化与反序列化:如何通过网络传输结构化的数据?
3、网络传输 | 序列化与反序列化
4、序列化与反序列化:通过网络传输结构化的数据
5、数据传输过程的序列化,你了解吗
6、Protocol Buffer序列化对比Java序列化
7、佛曰:大道至简,序列化之
8、JSON概述
9、网络通信–协议设计
10、数据交换协议–JSON、XML、YAML、TOML、TLV
11、转–全图文分析:如何利用Google的protobuf,来思考、设计、实现自己的RPC框架
12、机器人开发–DDS数据分发服务
13、linux–解释器
14、GOOD–【RPC】RPC的实现—未研读