MyBatis 工作原理
形式上的应用为:
UserMapper userMapper = MyBatisSessionFactory.getMapper(UserMapper.class);
List<User> userList = userMapper.selectByExample(example)
真正执行的操作为:
SqlSession session = MyBatisSessionFactory.getSession();
实体管理器,提供了最基本的CRUD 方法
List<Object> objectList =
session.selectList("com.yan.mapper.UserMapper.selectByExample", example);
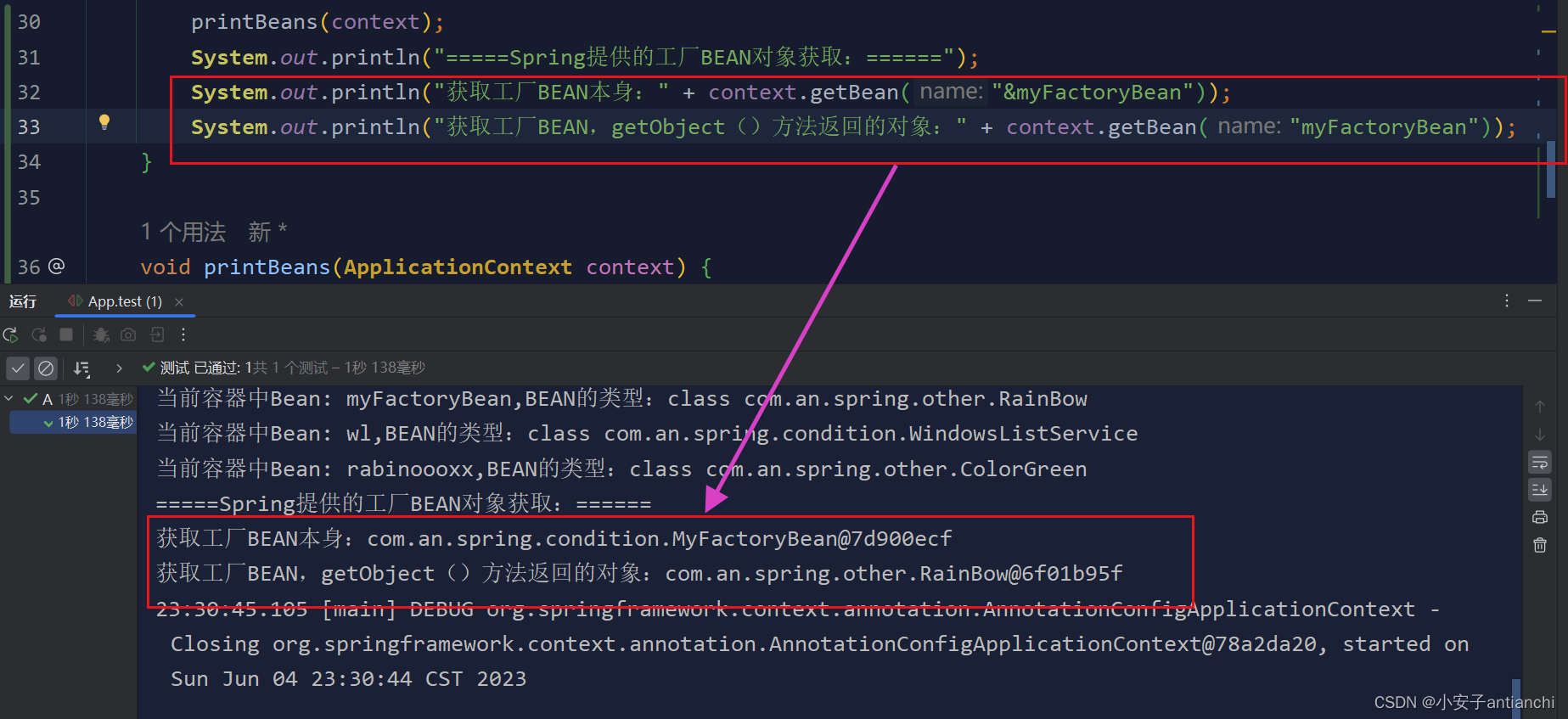
调用对应的 statementId,其中在映射元文件中 namespace 就是接口的全名 com.mapper.UserMapper,映射接口的名称后面是方法名称,对应的是 xml 中 SQL 语句的配置

1、SqlSessionFactoryBuilder 全局的对象。每个 MyBatis 的应用程序的入口是 SqlSessionFactoryBuilder。它的作用是通过 XML 配置文件创建 Configuration 对象,也可以在程序中自行创建,然后通过 build 方法创建SqlSessionFactory 对象。
2、SqlSessionFactory 全局的对象。每个基于 MyBatis 的应用都是以一个SqlSessionFactory 的实例为中心的。SqlSessionFactory 是由 SqlSessionFactoryBuilder 从 XML 配置文件或通过 Java 的方式构建出的实例,主要功能是创建 SqlSession 会话对象;SqlSessionFactory 对象必要的属性是 Configuration 对象;SqlSessionFactory
一旦被创建就应该在应用的运行期间一直存在,建议使用单例模式或者静态单例模式。一个 SqlSessionFactory对应配置文件中的一个环境 environment,如果要使用多个数据库就配置多个环境分别对应一个SqlSessionFactory。
3、SqlSession 作为 MyBatis 工作的主要顶层 API,表示和数据库交互的会话,完成必要数据库增删改查功能。SqlSession 通过调用 api 的 Statement ID 找到对应的 MappedStatement 对象。SqlSession 是一个接口,有 2个实现类,分别是 DefaultSqlSession 默认使用以及 SqlSessionManager;DefaultSqlSession 有两个必须配置的属性 Configuration 和 Executor,SqlSession 通过内部存放的执行器 Executor 来对数据进行 CRUD。由于不是线程安全的,所以 SqlSession 对象的作用域需限制方法内;每一次操作完数据库后都要调用 close 对其进行关闭,官方建议通过 try-finally 来保证总是关闭 SqlSession。
4、 Executor 是 MyBatis 执行器,是 MyBatis 调度的核心。Executor 对象在创建 Configuration 对象的时候创建,并且缓存在 Configuration 对象里。Executor 负责 SQL 语句的生成,调用 StatementHandler 访问数据库,查询缓存的维护;Executor 负责动态 SQL 的生成和查询缓存的维护,将 MappedStatement 对象进行解析,sql参数转化、动态 sql 拼接生成 jdbc Statement 对象。Executor 执行器接口有两个实现类,其中 BaseExecutor
有三个继承类分别是 BatchExecutor 重用语句并执行批量更新、ReuseExecutor 重用预处理语句 prepared、statement、SimpleExecutor 普通的执行器。
5、StatementHandler 封装了 JDBC Statement 操作,负责对 JDBCstatement 的操作,如设置参数、将 Statement结果集转换成 List 集合,是真正访问数据库的地方,并调用 ResultSetHandler 处理查询结果。
6、ParameterHandler 负责将用户传递的参数转换成 JDBC Statement 所需要的参数 ResultSetHandler 负责将JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合;处理查询结果。TypeHandler 负责 java 数据类型和 jdbc 数据类型之间的映射和转换
7、MappedStatement 是用来存放 SQL 映射文件中的信息包括 sql 语句,输入参数,输出参数等。一个 SQL节点对应一个 MappedStatement 对象。借助 MappedStatement 中的结果映射关系,将返回结果转化成HashMap、JavaBean 等存储结构并返回。
8、 SqlSource 负责根据用户传递的 parameterObject,动态地生成 SQL 语句,将信息封装到 BoundSql 对象中,并返回 BoundSql 表示动态生成的 SQL 语句以及相应的参数信息 Configuration,MyBatis 所有的配置信息都维持在 Configuration 对象之中
MyBatis 缓存
功能:mybatis 提供查询缓存,用于减轻数据压力,提高数据库性能。
一级缓存是 SqlSession 级别的缓存。在操作数据库时需要构造 sqlSession 对象,而在 sqlSession 对象中有一个数据结构 HashMap 用于存储缓存数据
二级缓存是 mapper 级别的缓存,多个 sqlSession 去操作同一个 Mapper 的 sql 语句,多个 sqlSession 可以共用二级缓存,二级缓存是可以横跨 sqlSession 的mybatis 自身缓存并不完美,不过除了使用 mybatis 自带的二级缓存,也可以使用自己实现的缓存或其他第三方的缓存方案创建适配器完全覆盖缓存行为。所以提供了使用自定义缓存的机会,可以选择使用自定义缓存
一级缓存
每当使用 MyBatis 开启一次和数据库的会话,MyBatis 会创建出一个 SqlSession 对象表示一次数据库会话。在对数据库的一次会话中,有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。为了解决这一问题,减少资源的浪费,MyBatis 会在表示会话SqlSession 对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如
果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
Role role1 = roleMapper.selectByPrimaryKey(1L);
MyBatisSessionFactory.getSession().clearCache();
Role role2 = roleMapper.selectByPrimaryKey(1L);
MyBatis 会在一次会话的 SqlSession 对象中创建一个本地缓存 local cache,对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则从数据库读取数据,将查询结果存入缓存并返回给用户

-
对于某个查询,根据 statementId、params、rowBounds 来构建一个 key 值,根据这个 key 值去缓存 Cache中取出对应的 key 值存储的缓存结果;
-
判断从 Cache 中根据特定的 key 值取的数据数据是否为空,即是否命中;
-
如果命中,则直接将缓存结果返回;
-
如果没命中,首先去数据库中查询数据,得到查询结果;然后将 key 和查询到的结果分别作为 key、value对存储到 Cache 中;最后将查询结果返回;
MyBatis 默认情况下只开启一级缓存,一级缓存只是相对于同一个 SqlSession 而言。
一级缓存:线程级别的缓存;本地缓存;SqlSession 级别的缓存;
二级缓存:全局范围的缓存;除过当前线程;SqlSession 能用外其他也可以使用
一级缓存总结
一级缓存:SqlSesion 级别的缓存;默认存在,不需要设置。机制:只要之前查询过的数据,mybatis 就会保存在一个缓存中 Map;下次获取直接从缓存中拿;当前 session有效
一级缓存失效的几种情况:
1、不同的 SqlSession 对应不同的一级缓存
2、同一个 SqlSession 但是查询条件不同
3、同一个 SqlSession 两次查询期间执行了任何一次增删改操作,mybatis 自动清缓存
4、同一个 SqlSession 两次查询期间手动清空了缓存 openSession.clearCache();
二级缓存
一个 SqlSession 对象会使用一个 Executor 对象来完成会话操作,MyBatis 的二级缓存机制的关键就是对这个Executor 对象做文章。如果用户配置了 cacheEnabled 为 true 时,那么在为 SqlSession 对象创建 Executor 对象时,会对 Executor 对象加上一个装饰者 CachingExecutor,这时 SqlSession 使用 CachingExecutor 对象来完成操作请求。CachingExecutor 对于查询请求,会先判断该查询请求在应用 namespace 级别的二级缓存中是否有缓存结果,如果有查询结果则直接返回缓存结果;如果缓存中没有,再交给真正的 Executor 对象来完成查询操作,之后 CachingExecutor 会将真正 Executor 返回的查询结果放置到缓存中,然后在返回给用户。
MyBatis 二级缓存的开启需要配置实现二级缓存,MyBatis 要求返回的 POJO 必须是可序列化的,也就是Serializable 接口,然后在映射 XML 文件配置开启。注意:不会出现一级缓存和二级缓存中有同一个数据。因为二级缓存是在一级缓存关闭之后才有的
在全局配置文件中开启二级缓存:
在具体的映射元文件中针对特定的 namespace 开启缓存:
触发将对象写入二级缓存的时机:SqlSession 对象的 close()方法
缓存命中率的统计:

RoleMapper roleMapper = MyBatisSessionFactory.getMapper(RoleMapper.class);
Role role1 = roleMapper.selectByPrimaryKey(1L);
System.out.println(role1);
MyBatisSessionFactory.closeSession(); //关闭和 roleMapper 相关联的 SqlSession 对象
//重新打开 SqlSession,则需要重新创建 RoleMapper 对象,否则报错
roleMapper = MyBatisSessionFactory.getMapper(RoleMapper.class);
Role role2 = roleMapper.selectByPrimaryKey(1L);
System.out.println(role1 + "-->" + role2);
本次执行的缓存命中率为 0.5,而且在整个执行过程中只执行了一次 SQL 语句

1、映射语句文件中的所有 select 语句将会被缓存,所有 insert、update 和 delete 语句会刷新缓存
2、缓存会使用 Least Recently Used 即 LRU 最近最少使用的算法来收回。
3、根据时间表,如 no Flush Interval 没有刷新间隔,缓存不会以任何时间顺序来刷新。
4、缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
5、缓存会被视为是 read/write 可读/可写的缓存,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
eviction 可用的收回策略有:
LRU 最近最少使用的:移除最长时间不被使用的对象。
FIFO 先进先出:按对象进入缓存的顺序来移除它们。
SOFT 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval 刷新间隔,单位为毫秒。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。size 引用数目。可以被设置为任意正整数,要记住缓存的对象数目和运行环境的可用内存资源数目。设置过大会导致内存溢出。默认值是 1024。
readOnly 只读。属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝,通过序列化。这会慢一些,但是安全,因此默认是 false。
自定义缓存
使用第三方缓存 Redis 等,需要实现 MyBatis 提供的接口 org.apache.ibatis.cache.Cache,实际上 Cache 最核心的实现其实就是一个 Map,将本次查询使用的特征值作为 key,将查询结果作为 value 存储到 Map 中。一般针对分布式缓存使用 Redis,如果要求不高使用 ehcache
自定义插件
物理分页可以考虑使用第三方插件实现。这个插件的实现原理就是自定义插件的原理
1、添加依赖:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.2</version>
</dependency>
对应官方网站 https://pagehelper.github.io/
2、在核心配置文件 mybatis-config.xml 中针对插件进行配置
<plugins> 注意具体的插件类定义是由 PageHelper 提供的,不需要重新定义
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/> 设置数据库方言,该参数指明要连接的是哪种关
系型数据库
<property name="reasonable" value="true"/> 分页参数合理化,如果 pageNum<1 会查询第一页,如
果 pageNum>pages 会查询最后一页
</plugin>
3、在业务实现类中调用 Mapper 执行查询操作。主要在调用 PageHelper.startPage 方法后执行查询操作之前,不应该包含其它修改操作
@Test
public void testCache1() {
RoleMapper rm=MyBatisSessionFactory.getMapper(RoleMapper.class);
//设置分页相关参数,设置完参数后应该执行的是查询操作
Page<Role> rolePage=PageHelper.startPage(20,2);
List<Role> roleList = rm.selectAll();
roleList.forEach(System.out::println);
System.out.println(rolePage);
}
pagehelper 工作原理:
一次请求就是一个线程,PageHelper.startPage(page 页码值,size 每页行数)中携带分页参数。分页参数会设置在 ThreadLocal 中。PageHelper 会在 mybatis 执行 sql 前进行拦截,从 ThreadLocal 中取出分页参数,修改当前执行的 sql 语句,添加分页 sql,最后执行了添加了分页的 sql 语句,实现分页查询插件工作原理Mybatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口的
插件,MyBatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4 种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler 的 invoke 方法,当然只会拦截那些指定需要拦截的方法。
编写插件:
实现 Mybatis 的 Interceptor 接口并复写 intercept 方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,最后在配置文件中配置编写的插件。
@Intercepts({
@Signature(type=StatementHandler.class, 确定要拦截的对象
method="prepare", 确定要拦截的方法
args={Connection.class})}) 拦截方法的参数
public class PageInterceptor implements Interceptor{
public Object intercept(Invocation invocation) throws Throwable { 代替拦截对象方法的内容,参数是责
任链对象
StatementHandler statementHandler = (StatementHandler)invocation.getTarget();
MetaObject metaObject = MetaObject.forObject(statementHandler, SystemMetaObject.DEFAULT_OBJECT_FACTORY, SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY, new DefaultReflectorFactory());
MappedStatement mappedStatement = (MappedStatement)
metaObject.getValue("delegate.mappedStatement");
String id = mappedStatement.getId();
if(id.matches(".+ByPage$")){
BoundSql boundSql = statementHandler.getBoundSql();
Map<String,Object> params = (Map<String,Object>)boundSql.getParameterObject();
PagePOJO page = (PagePOJO)params.get("page");
String sql = boundSql.getSql();
String countSql = "select count(*)from ("+sql+")a";
Connection connection = (Connection) invocation.getArgs()[0];
PreparedStatement countStatement = connection.prepareStatement(countSql);
ParameterHandler parameterHandler = (ParameterHandler)
metaObject.getValue("delegate.parameterHandler");
parameterHandler.setParameters(countStatement);
ResultSet rs = countStatement.executeQuery();
if(rs.next()) page.setTotalNumber(rs.getInt(1));
String pageSql = sql+" limit "+page.getStartIndex()+","+page.getTotalSelect();
metaObject.setValue("delegate.boundSql.sql", pageSql);}
return invocation.proceed(); } 如果当前代理的是一个非代理对象,那么它就回调真实拦截对象的
方法,如果不是它会调度下个插件代理对象的 invoke 方法
public Object plugin(Object target) { 生成对象的代理,这里常用的 mybatis 提供的 Plugin 类的 wrap 方
法,参数 target 被代理的对象
return Plugin.wrap(target, this); } 使用 mybatis 提供的 Plugin 类生成代理对象
设置初始化的属性值
public void setProperties(Properties properties) { } 获取插件配置的属性,在 mybatis 的配置文件里面去
配置,其中 properties 是 mybatis 配置的参数}
需要在 mybatis 配置文件里面配置才能够使用插件,请注意 plugins 元素的配置顺序配置错了系统就会报错
<plugins>
<plugin interceptor="com.yan.plugin.MyPlugin">
<property name="dbType" value="mysql"/>
</plugin>
</plugins>
自定义插件总结
1、能不用插件尽量不用插件,因为它将修改 mybatis 的底层设计。
2、插件生成的是层层代理对象的责任链模式,通过反射方法运行,性能不高,所以减少插件就能减少代理,从而提高系统的性能。
阿里规范
强制规则:
1、在表查询中一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:1) 增加查询分析器解析成本。2) 增减字段容易与 resultMap 配置不一致。
<sql id="Base_Column_List"> SQL 代码块,用于避免查询中出现*的问题
id, title
</sql>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select <include refid="Base_Column_List"/> from tb_roles
where id = #{id,jdbcType=BIGINT}
</select>
2、POJO 类的布尔属性不能加 is,而数据库字段必须加 is _,要求在 resultMap 中进行字段与属性之间的映射。说明:在中增加映射是必须的。在 MyBatis Generator 生成的代码中需要进行对应的修改。
private Boolean sex; 使用的是 Boolean,而不是 boolean
例如数据表中的 issex 不建议,建议定义为 is_sex
3、不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应也需要定义;反过来每个表也必然有一个与之对应。
说明:配置映射关系使字段与 DTO 类解耦,方便维护。
mybatis映射文件中有parameterType建议使用,不允许使用paramterMap;不使用resultClass或者resultType,建议使用 resultMap
<resultMap id="BaseResultMap" type="com.yan.entity.Role">
<id column="id" jdbcType="BIGINT" property="id"/>
<result column="title" jdbcType="VARCHAR" property="title"/>
</resultMap>
4、sql.xml 配置参数使用#{},param 不要使用${},此种方式容易出现 SQL 注入。
例如 getById(2),映射元文件中使用#和$两种的执行方式
select id,name from tb_users where id=#{id},执行时可以看到对应的 sql 语句为 select id,name from tb_users where id=?
select id,name from tb_users where id=${id},则执行时对应的 SQL语句为 select id,name from tb_users where id=2
5、iBATIS 自带的 queryForList(String statementName , int start , int size)不推荐使用。
说明:其实现方式是在数据库取到 statementName 对应的 SQL 语句的所有记录,再通过 subList 取 start和 size 的子集合。
6、不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。
说明:resultClass=Hashtable 会置入字段名和属性值,但是值的类型不可控。
Map<String,Object> selectByPrimaryKey(ID id);
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultType="map">
select <include refid="Base_Column_List"/> from tb_roles where id = #{id,jdbcType=BIGINT}
</select>
7、更新数据表记录时必须同时更新记录对应的 gmt _ modified 字段值为当前时间。
创建表时一般需要添加一些额外的列,例如 modified 记录当前行数据的修改时间
推荐不要写一个大而全的数据更新接口。传入为 POJO 类,不管是不是自己的目标更新字段,都进行 update table set c1=value1,c2=value2,c3=value3; 这是不对的。执行 SQL 时不要更新无改动的字段,一是易出错;二是效率低;三是增加 binlog 存储。
int insert(Map<String,Object> params);
insert into t a b l e N a m e ( {tableName}( tableName({columnsName}) values(…)
删除了反向映射中的 insert 方法,因为 insert 方法会插入所有列,但是报错动态插入 insertSelective
<insert id="insert" parameterType="com.yan.entity.Role">
insert into tb_roles (id, title) values (#{id,jdbcType=BIGINT},
#{title,jdbcType=VARCHAR})
</insert>
即使某个属性为 null,则会插入 null 值到对应的列,则默认值失效 default