文章目录
- 前言
- 一、Linux网络命名空间
- 1.1 linux网络命名空间
- 1.2 不同网络命名空间的通信
- 两个网络命名空间通信
- 多个网络命名空间通信
- 二、K8S Pod网络通信
- 2.1 Pod内部容器的网络通信
- 2.2 相同node: 不同pod间的网络通信
- 2.3 不同node: 不同pod间的网络通信
- 2.4 容器网络插件: Flannel扁平网络
- 三、Pod通过端口对外暴露服务
- 3.1 Pod通过端口对外暴露服务
- 方式1:hostNetwork: true模式
- 方式2:hostPort模式
- 方式3:NodePort模式
- 方式4:LoadBalancer模式
- 方式5:Ingress与Ingress Controller模式
- 3.2 五种端口
- 四、DNS解析
- 4.1 Pod的dns域名解析流程
- 4.2 如何为Pod创建dns记录
- 尾声
前言
之前对kubernetes网络通信的认识都比较摸棱两可,本文从linux网络空间开始循序渐进地整理kubernetes网络的知识脉络,意在彻底理解其网络通信原理。文中所用的图片均来源于网络,由于比较分散,就没有将参考文档一一列举出来。
一、Linux网络命名空间
1.1 linux网络命名空间
network namespace 是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己就在独立的网络中。对于每个 network namespace 来说,它会有自己独立的网卡、路由表、arp表、iptables 等和网络相关的资源。相关的主要命令如下:
ip netns add net1
ip netns show
ip netns exec net1 ip addr
1.2 不同网络命名空间的通信
两个网络命名空间通信
默认情况下,同一个网络命名空间网络可达,不同网络命名空间网络不可达。
为了实现不同 network namespace 之间的网络通信,linux提供了veth pair,可以将veth pair当做一对虚拟网卡,这对虚拟网卡连通着不同的网命名络空间。创建veth pair实现不同网络命名空间通信的步骤如下:
// 创建2个网络命名空间
[jettchen@k8s-master01 ~]$ sudo ip netns add net1
[jettchen@k8s-master01 ~]$ sudo ip netns add net2
// 创建veth pair
[jettchen@k8s-master01 ~]$ sudo ip link add name veth1 type veth peer name veth2
// 将veth pair的2个虚拟接口挪到新创建的2个网络命名空间中
[jettchen@k8s-master01 ~]$ sudo ip link set veth1 netns net1
[jettchen@k8s-master01 ~]$ sudo ip link set veth2 netns net2
// 启动虚拟接口,并给veth pair配置ip地址,注意这里2个虚拟接口的ip必须是同网段的
[jettchen@k8s-master01 ~]$ sudo ip netns exec net1 ip link set veth1 up
[jettchen@k8s-master01 ~]$ sudo ip netns exec net2 ip link set veth2 up
[jettchen@k8s-master01 ~]$ sudo ip netns exec net1 ip addr add 20.1.1.1/24 dev veth1
[jettchen@k8s-master01 ~]$ sudo ip netns exec net2 ip addr add 20.1.1.2/24 dev veth2
// veth pair接口配置的网络测试结果
[jettchen@k8s-master01 ~]$ sudo ip netns exec net1 ping -c 3 20.1.1.2
PING 20.1.1.2 (20.1.1.2) 56(84) bytes of data.
64 bytes from 20.1.1.2: icmp_seq=1 ttl=64 time=0.033 ms
64 bytes from 20.1.1.2: icmp_seq=2 ttl=64 time=0.028 ms
64 bytes from 20.1.1.2: icmp_seq=3 ttl=64 time=0.033 ms
多个网络命名空间通信
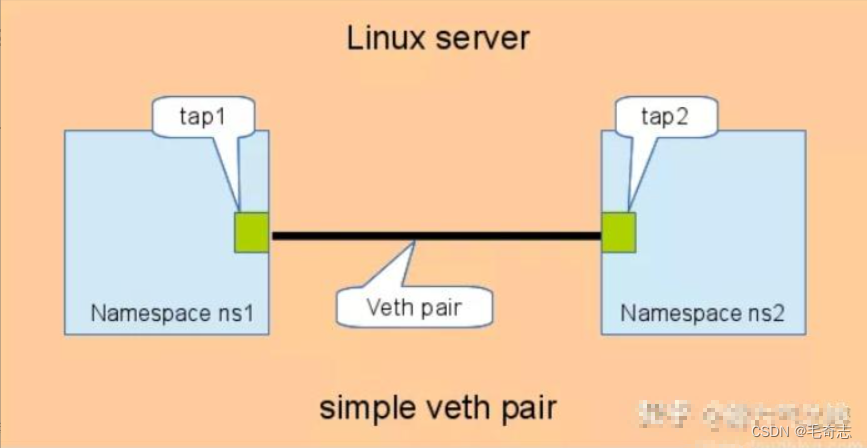
不同namespace之间,直接通过veth pair相连,如下所示。这种方式的缺点就是:当namespace很多时,要实现所有网络命名空间两两相通,需要的veth pair数量呈n^2趋势增长,总数量为n*(n - 1) / 2。
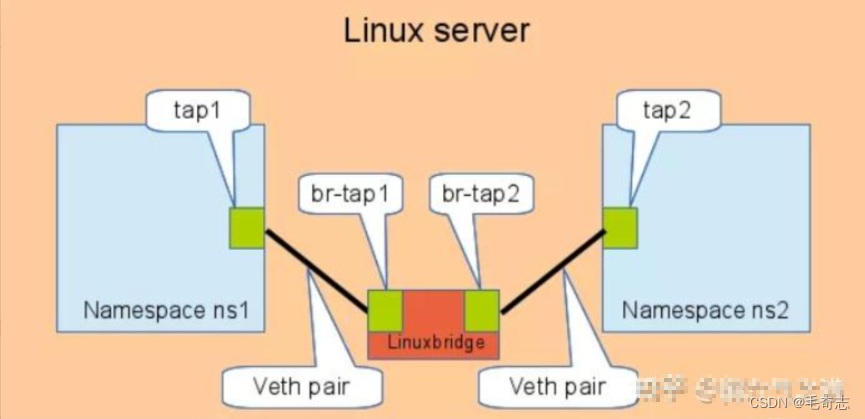
通过linux bridge,相当于用一个交换机中转两个 namespace 的流量,如下所示。这种方式就可以将veth pair的数量控制在n,n为网络命名空间的数量。就是说,n个网络命名空间构成一个圈的n个节点,只需要 n-1 条线段,就是 n-1 个 bridge 就可以让整个互通,不漏下任何一个网络命名空间,全部圈连起来。
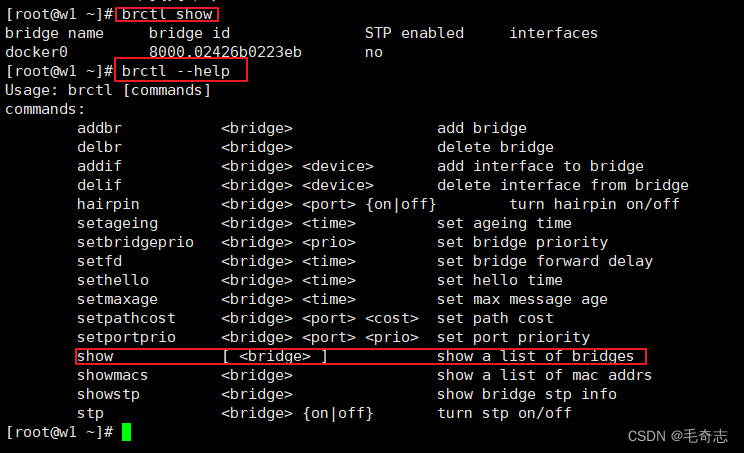
操作linux上的桥接可以使用 brctl 命令
brctl show
brctl --help
小结:不同网络命名空间,有两种关联方式 veth-pair 和 bridge
二、K8S Pod网络通信
2.1 Pod内部容器的网络通信
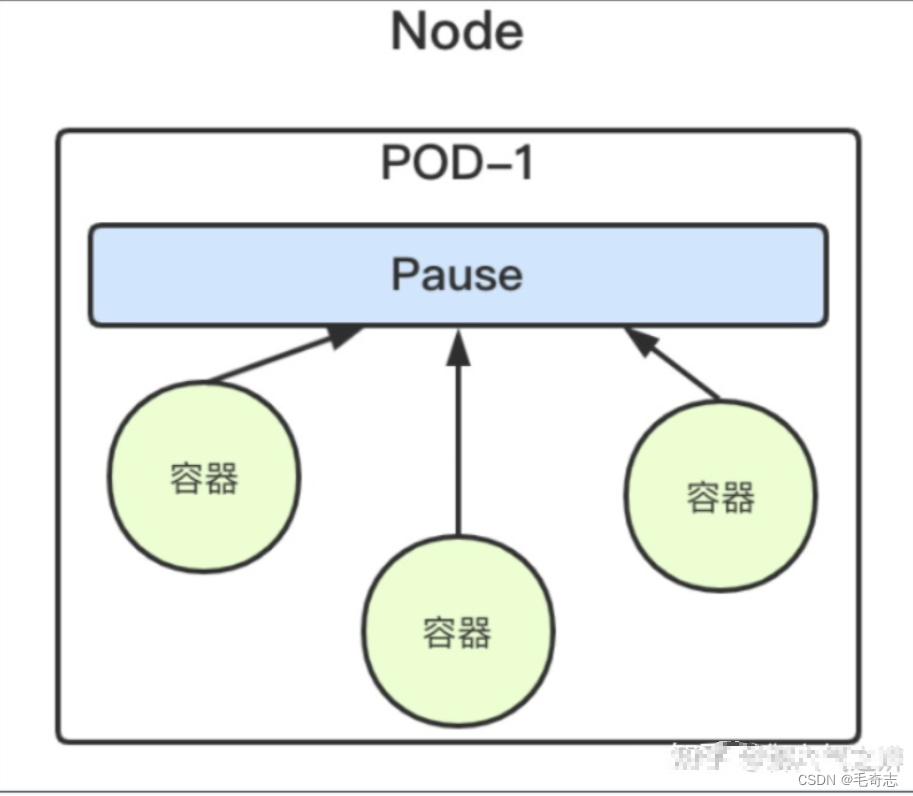
在 k8s中,每个 Pod 有一个 pause 容器,这个pause容器会创建独立的网络命名空间,在 Pod 内启动其他 Docker 容器的时候使用 –net=container 就可以让当前 Docker 容器加入到 Pod 拥有的网络命名空间(pause 容器)。由于Pod内的所有容器共享同一个网络空间,所以它们可以直接通过自身网络空间的loopback接口通信。这也是在规划 k8s 调度的时候,尽量把关系紧密的服务放到同一个 pod 内的原因,这样网络请求的耗时就可以忽略,因为容器之间的通信在一个网络空间内,就像 local 本地通信一样。
2.2 相同node: 不同pod间的网络通信
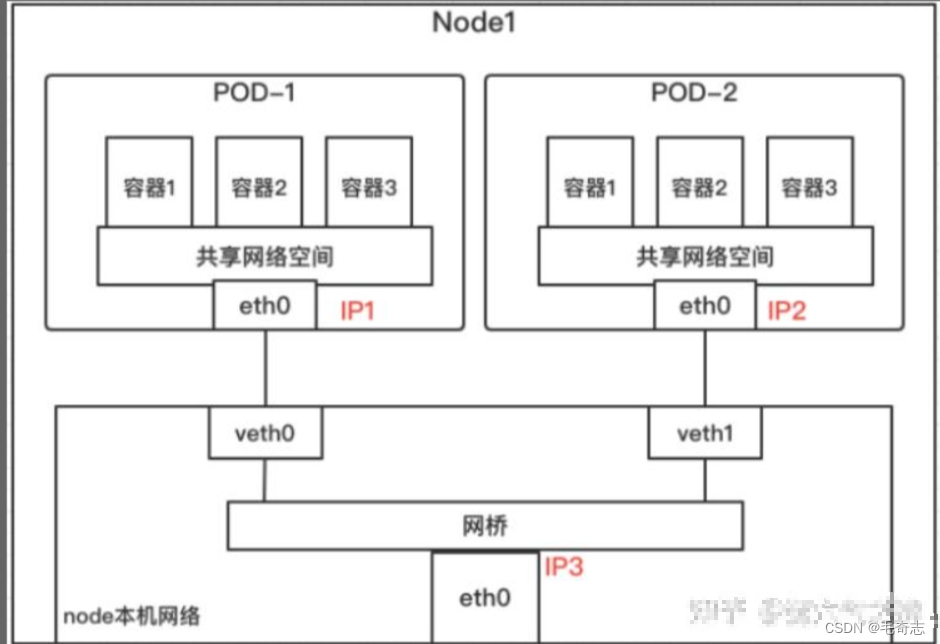
不同的Pod,其网络命名空间也就不同,因此这个时候的通信就相当于前面讲的不同网络空间的通信,如下所示。大致实现是:通过虚拟网桥与各个Pod间建立veth pair。各个Pod的IP是由虚拟网桥分配的,这些Pod都连在同一个网桥上,在同一个网段内,它们可以进行IP寻址和互通。
2.3 不同node: 不同pod间的网络通信
Node1 中的 Pod1 与 Node2 的 Pod4 进行通信的流程:
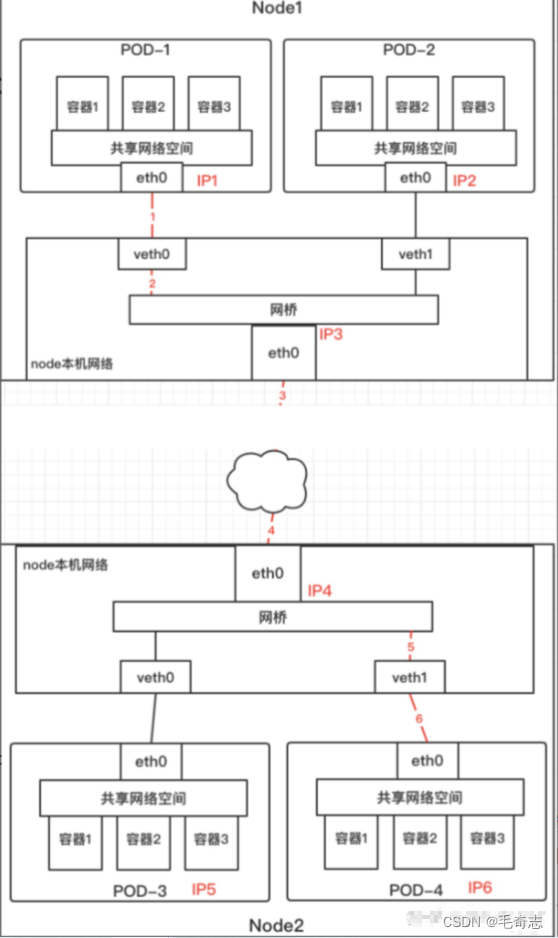
- 首先 Pod1 通过自己的以太网设备 eth0 把数据包发送到关联到 root 命名空间的 veth0 上。
- 然后数据包被 Node1 上的网桥设备接收到,网桥查找转发表发现找不到 Pod4 的 Mac 地址,则会把包转发到默认路由(root 命名空间的 eth0 设备)。
- 然后数据包经过 eth0 就离开了 Node1,被发送到网络。
- 数据包到达 Node2 后,首先会被 root 命名空间的 eth0 设备接收。
- 然后通过网桥把数据路由到虚拟设备 veth1,最终数据包会被流转到与 veth1 配对的另外一端(Pod4 的 eth0)。
2.4 容器网络插件: Flannel扁平网络
对于扁平网络,kubernetes本身没有具体实现,而是通过提供CNI接口供开源社区实现。这里介绍下CoreOS的Flannel在kubernetes上实现CNI的大致原理,如下所示。
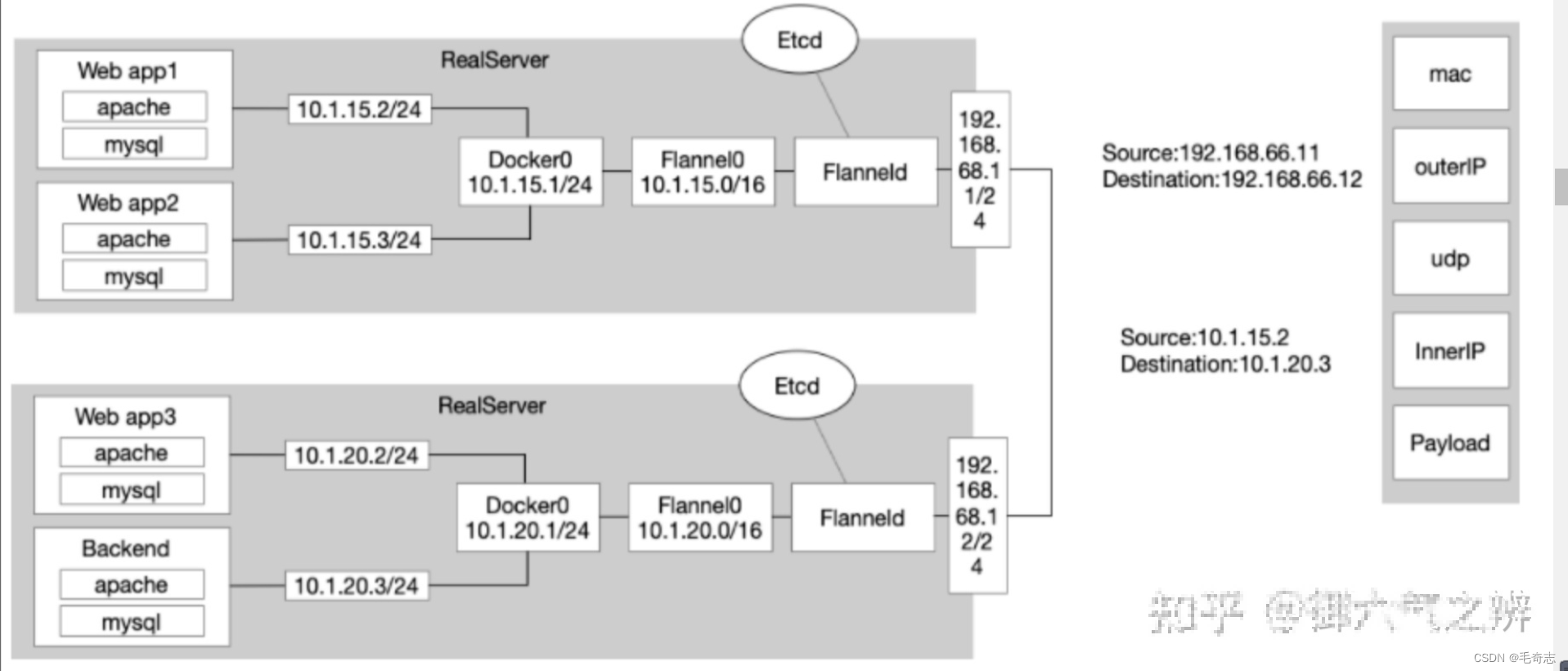
Flannel0作为overlay网络的设备,用来进行 数据报文的封包和解包。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
Flanneld作为agent进程运行在每个主机上,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有Pod的IP地址都将从中分配,这样就可以保证集群内各个Pod的IP是唯一的。同时Flanneld监听K8s集群的数据库etcd,为Flannel0设备提供封装数据时必要的mac、ip等网络数据信息。数据包的具体转发流程是:
- Pod中产生数据,根据Pod的路由信息,将数据发送到docker0网桥。
- docker0网桥根据节点的路由表,将数据发送到隧道设备Flannel0。
- Flannel0查看数据包的目的ip,从Flanneld获得对端隧道设备的必要信息,封装数据包。
- Flannel0将数据包发送到对端设备。对端节点的网卡接收到数据包,发现数据包为overlay数据包,解开外层封装,并发送内层封装到Flannel0设备。
- Flannel0设备查看数据包,根据路由表匹配,将数据发送给docker0网桥。
- docker0网桥匹配路由表,发送数据给网桥上对应的端口。
三、Pod通过端口对外暴露服务
3.1 Pod通过端口对外暴露服务
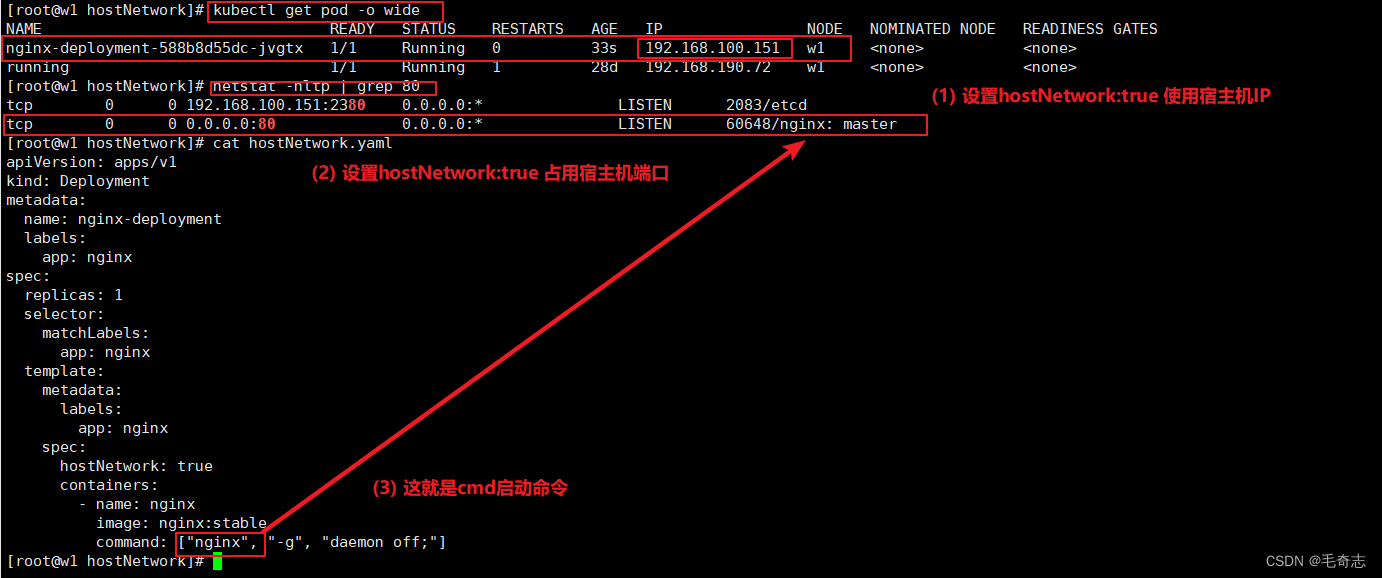
方式1:hostNetwork: true模式
这种网络模式 ,相当于 docker run --net=host,采用宿主机的网络命名空间。
第一,Pod 的ip 为 node 节点的ip;
第二,Pod的端口需要保持不与宿主机上的port 端口发生冲突。
第三,需要额外加上 dnsPolicy: ClusterFirstWithHost ,否则Pod无法解析servicename.ns

apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
hostNetwork: true
containers:
- name: nginx
image: nginx:stable
command: ["nginx", "-g", "daemon off;"]
[jettchen@k8s-master01 ~/pubgm/k8s]$ sudo ps aux| grep nginx
root 20126 0.0 0.0 10640 3512 ? Ss 10:17 0:00 nginx: master process nginx -g daemon off;
101 20138 0.0 0.0 11044 1524 ? S 10:17 0:00 nginx: worker process
101 20139 0.0 0.0 11044 1524 ? S 10:17 0:00 nginx: worker process
101 20140 0.0 0.0 11044 1524 ? S 10:17 0:00 nginx: worker process
101 20141 0.0 0.0 11044 1524 ? S 10:17 0:00 nginx: worker process
[jettchen@k8s-master01 ~/pubgm/k8s]$ sudo netstat -lpn| grep ":80 "
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 20126/nginx: master
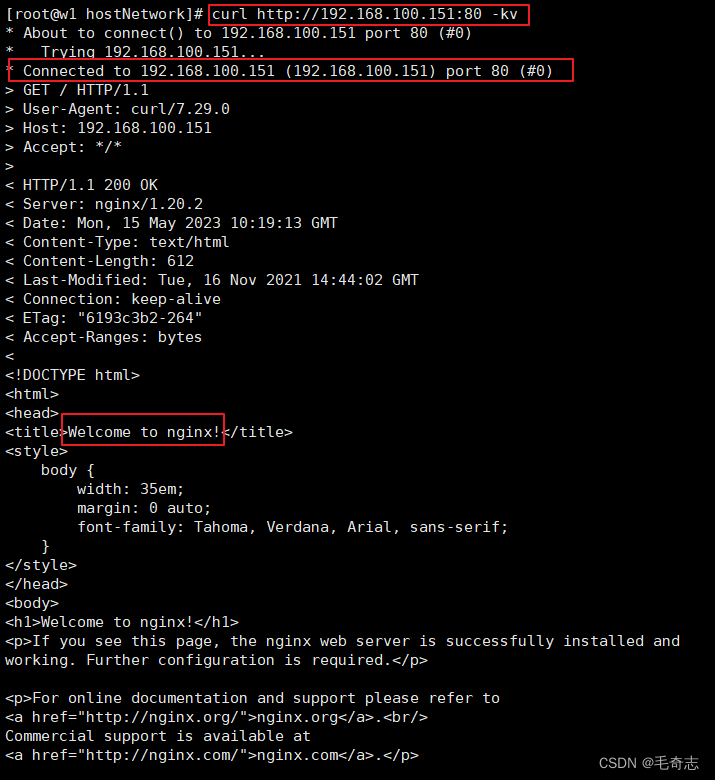
如上配置,可以直接通过curl {node_ip}/index.html访问nginx,并且由于Pod采用的是宿主机的网络命名空间,因此宿主机可以直接看到nginx master进程正在监听80端口。
方式2:hostPort模式
hostPort是将容器端口与宿主节点上的端口建立映射关系,这样用户就可以通过宿主机的 IP 加上来访问 Pod 了。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable
command: ["nginx", "-g", "daemon off;"]
ports:
- containerPort: 80
hostPort: 81
[jettchen@k8s-master01 ~/pubgm/k8s/tlog]$ kube get pod -o wide|grep nginx
nginx-deployment-ff549cb9d-5t4bp 1/1 Running 0 5m8s 10.244.0.40 k8s-master01 <none> <none>
[jettchen@k8s-master01 ~/pubgm/k8s/tlog]$ sudo iptables -L -nv -t nat| grep "10.244.0.40:80"
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:81 to:10.244.0.40:80
如上配置,既可以通过curl 10.244.0.40/index.html访问nginx,也可以通过curl {node_ip}:81/index.html访问nginx。可以看到iptables会添加一条DNAT规则,将宿主机的81端口映射到Pod的80端口。
方式3:NodePort模式
NodePort 在 Kubernetes 里是一个广泛应用的服务暴露方式。Kubernetes 中的 service 默认情况下都是使用的ClusterIP这种类型,这样的 service 会产生一个 ClusterIP,这个 IP 只能在集群内部访问,要想让外部能够直接访问 service,需要将 service type 修改为nodePort。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeSelector:
nginx: ok
containers:
- name: nginx
image: nginx:stable
command: ["nginx", "-g", "daemon off;"]
kind: Service
apiVersion: v1
metadata:
name: nginx-svc
spec:
type: NodePort
ports:
- port: 80
nodePort: 30001
selector:
name: nginx
[jettchen@k8s-master01 ~/pubgm/k8s]$ kube get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 176d <none>
nginx-svc NodePort 10.110.21.50 <none> 80:30001/TCP 26s app=nginx
[jettchen@k8s-master01 ~/pubgm/k8s]$ kube get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
clubproxy-deployment-55c958bf67-cg424 1/1 Running 0 11h 10.244.0.56 k8s-master01 <none> <none>
nginx-deployment-c9fd6b54f-bdr8l 1/1 Running 0 18s 10.244.0.58 k8s-master01 <none> <none>
[jettchen@k8s-master01 ~/pubgm/k8s]$ sudo netstat -lpn | grep 30001
tcp 0 0 0.0.0.0:30001 0.0.0.0:* LISTEN 15954/kube-proxy
如上配置,可以通过{pod_ip}/index.html、{cluster_ip}/index.html、{node_ip}:30001/index.html访问nginx。node节点上可以看到kube-proxy进程在监听30001端口,用于接收从主机网络进入的外部流量。最后,通过iptables规则将{node_ip}:30001映射到{pod_ip}:容器端口。
方式4:LoadBalancer模式
kind: Service
apiVersion: v1
metadata:
name: nginx-svc
spec:
type: LoadBalancer
ports:
- port: 80
nodePort: 30001
selector:
app: nginx
[jettchen@k8s-master01 ~/pubgm/k8s]$ kube get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 176d <none>
nginx-svc LoadBalancer 10.97.214.72 <pending> 80:30001/TCP 2m30s app=nginx
LoadBalancer只能在 service 上定义。这是公有云提供的负载均衡器,如果成功分配了EXTERNAL-IP(这是一个 VIP,是云供应商提供的负载均衡器 IP),则外部可以通过EXTERNAL-IP:30001来访问nginx。当然,此时也可以通过{pod_ip}/index.html、{cluster_ip}/index.html、{node_ip}:30001/index.html访问nginx。
方式5:Ingress与Ingress Controller模式
将 k8s 集群中服务暴露给集群外访问,最简单的方式莫过于使用 NodePort,定义 NodePort 类型的 Service 后,即可通过集群中任意节点的 IP 加 nodePort 指定的端口访问到 k8s 集群中的服务。但随着服务的增多,使用 NodePort 访问的问题也会逐渐显现出来:可用作 NodePort 的端口是一个有限的范围、不容易记忆、不好管理。可以在集群内部署一个 Nginx 服务,NodePort 暴露 Nginx 的端口,再由 Nginx 代理访问集群内的服务。在 k8s 中也有这样的一个资源,能够起到与这个 Nginx 类似的作用,即Ingress。Ingress的资源配置文件如下所示。这个 Ingress 资源表示www.tchua.top域名下的请求都会转发给名为myapp-svc,端口为80的服务。可以将 Ingress 狭义的理解为Nginx 中的配置文件nginx.conf。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-myapp
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: www.tchua.top
http:
paths:
- path: /
backend:
serviceName: myapp-svc
servicePort: 80
很显然,只有 Nginx 的配置文件,是起不到转发请求的作用的,必须还要有 Nginx 程序。同样,仅创建 Ingress 资源本身是没有任何作用的,还需要部署 Ingress Controller。Ingress Controller 的作用就相当于是 Nginx 服务,实际上,k8s 官方支持和维护的三个 Ingress Controller 里,就有基于 nginx 实现的 ingress-nginx,另外两个是 AWS 和 GCE。
不同类型的 Ingress Controller 对应的 Ingress 配置通常也是不同的,当集群中存在多于一个的 Ingress Controller 时,就需要为 Ingress 指定对应的 Controller 是哪个。Kubernetes 从1.18版本开始提供了一个 IngressClass资源,以此关联对应的 Ingress Controller。然后,在Ingress 资源文件中通过 spec.ingressClassName 属性用来指定对应的 IngressClass,进而由 IngressClass 关联到对应的 Ingress Controller。
除了可能会有多个不同类型的 Ingress Controller 之外,还可能存在多个相同类型的 Ingress Controller,比如部署了两个 Nginx Ingress Controller,一个负责处理外网访问,一个负责处理内网访问。此时也可以通过上面的方式,为每个 Controller 设定唯一的一个Ingress Class。
问题:ingress和ingress controller 有什么区别?
回答:ingress是配置规则,ingress controller 是一个 deployment ,使用 ingress 配置的规则,配置好自己的 service ,对外暴露端口。
3.2 五种端口
port、containerPort、nodePort、hostPort、targetPort的区别
- port是暴露在cluster ip上的端口,port提供了集群内部访问service的入口,即 clusterIP:port
- containerPort是在pod控制器中定义的、pod中的容器需要暴露的端口。
- nodePort 提供了集群外部访问 Service 的一种方式,外部可通过nodeIP:nodePort访问集群内的服务。
- hostPort是直接将宿主机的端口映射到容器端口,这样外部就可以通过宿主机的IP:hostPort访问Pod了。
- targetPort是pod上的端口,从port/nodePort上来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器。
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort // 配置NodePort,外部流量可访问k8s中的服务
ports:
- port: 30080 // 服务访问端口,集群内部访问的端口
targetPort: 80 // pod控制器中定义的端口(应用访问的端口)
nodePort: 30001 // NodePort,外部客户端访问的端口
selector:
name: nginx-pod
四、DNS解析
4.1 Pod的dns域名解析流程
在Pod内部,域名解析依赖配置文件/etc/resolv.conf。如下所示,Pod的dns服务器指向kube-dns这个service。
[jettchen@k8s-master01 ~/pubgm/k8s]$ kube get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 176d
[jettchen@k8s-master01 ~/pubgm/k8s]$ kube exec -it nginx-deployment-c9fd6b54f-bdr8l -- /bin/sh
# cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
Kubernetes中,域名的全称必须是 service-name.namespace.svc.cluster.local 这种模式,其中service-name字段值就是Kubernetes中 Service 的名称。比如我们执行curl svc-app命令的时候,会按配置文件中search配置项中的 svc-app.default.svc.cluster.local -> svc-app.svc.cluster.local -> svc-app.cluster.local 顺序解析域名,如果解析不到则将svc-app当作全域名再解析一遍。
ndots:5,表示:如果查询的域名包含的点 ‘.’,不到5个,那dns解析的时候会先走search配置项流程,解析不到再走全域名解析。如果你查询的域名包含点数大于等于5,那么dns解析的时候先走全域名解析,解析不到才走search配置项流程。
有一种可以绕过search配置项流程的办法是:输入的service-name以 ‘.’ 结尾,比如svc-app.。
4.2 如何为Pod创建dns记录
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeSelector:
nginx: ok
hostname: nginx-host
subdomain: nginx-subdomain
containers:
- name: nginx
image: nginx:stable
command: ["nginx", "-g", "daemon off;"]
kind: Service
apiVersion: v1
metadata:
name: nginx-subdomain
spec:
type: ClusterIP
ports:
- port: 80
name: nginx
selector:
app: nginx
当Pod配置hostname和subdomain,并且service的metadata.name的字段值与Pod的subdomain一致的时候,此时就不仅会针对service生成一条dns记录,还会针对Pod生成一条dns记录。结果如下:
[jettchen@k8s-master01 ~/pubgm/k8s/clubproxy]$ kube get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-5f6778cf77-7sv8p 1/1 Running 0 15h 10.244.0.68 k8s-master01 <none> <none>
[jettchen@k8s-master01 ~/pubgm/k8s/clubproxy]$ kube get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx-subdomain ClusterIP 10.97.33.219 <none> 80/TCP 15h app=nginx
// 10.96.0.10为kube-dns这个service的cluster_ip
[jettchen@k8s-master01 ~/pubgm/k8s/clubproxy]$ nslookup nginx-host.nginx-subdomain.default.svc.cluster.local 10.96.0.10
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: nginx-host.nginx-subdomain.default.svc.cluster.local
Address: 10.244.0.68
[jettchen@k8s-master01 ~/pubgm/k8s/clubproxy]$ nslookup nginx-subdomain.default.svc.cluster.local 10.96.0.10
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: nginx-subdomain.default.svc.cluster.local
Address: 10.97.33.219
另外,如果service配置成Headless Service,那么对于service的dns域名解析,会直接解析到Pod的ip。
尾声
全文分为四个部分:
(1) Linux网络命名空间,包括veth-pair和桥接
(2) K8S Pod网络通信
(3) K8S 服务暴露
(4) K8S DNS解析
参考资料:循序渐进地学习kubernetes网络